Scrapy 爬虫框架介绍#
官网:https://www.scrapy.org/
文档:https://docs.scrapy.net.cn/en/latest/
快速功能强大的网络爬虫框架
Scrapy 的安装#
pip install scrapy
scrapy -h
Scrapy 爬虫框架结构#
Scrapy不是一个函数功能库,而是一个爬虫框架。
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
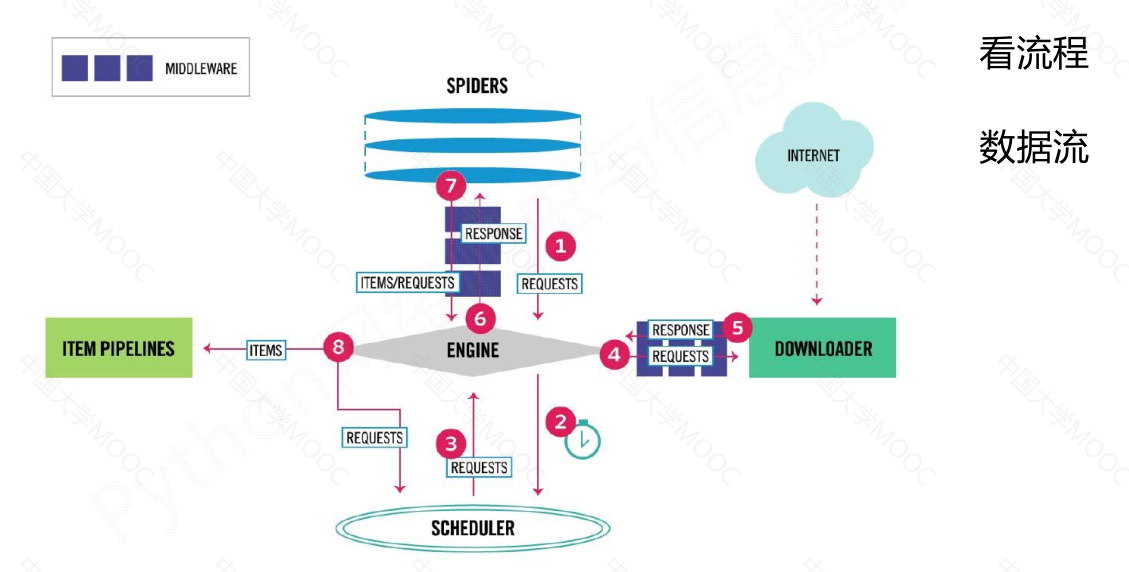
Scrapy 爬虫框架解析#
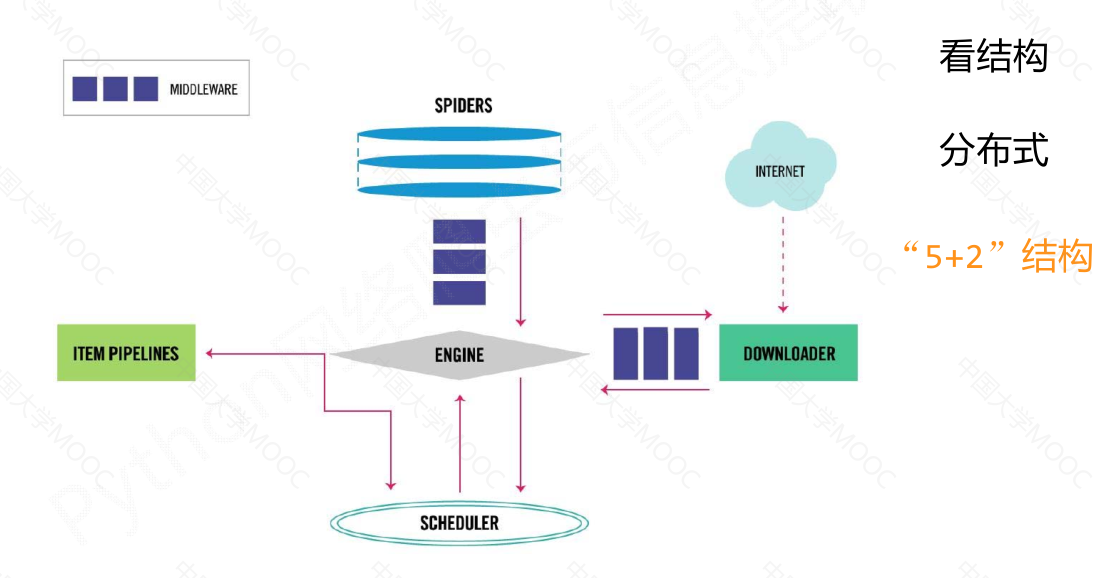
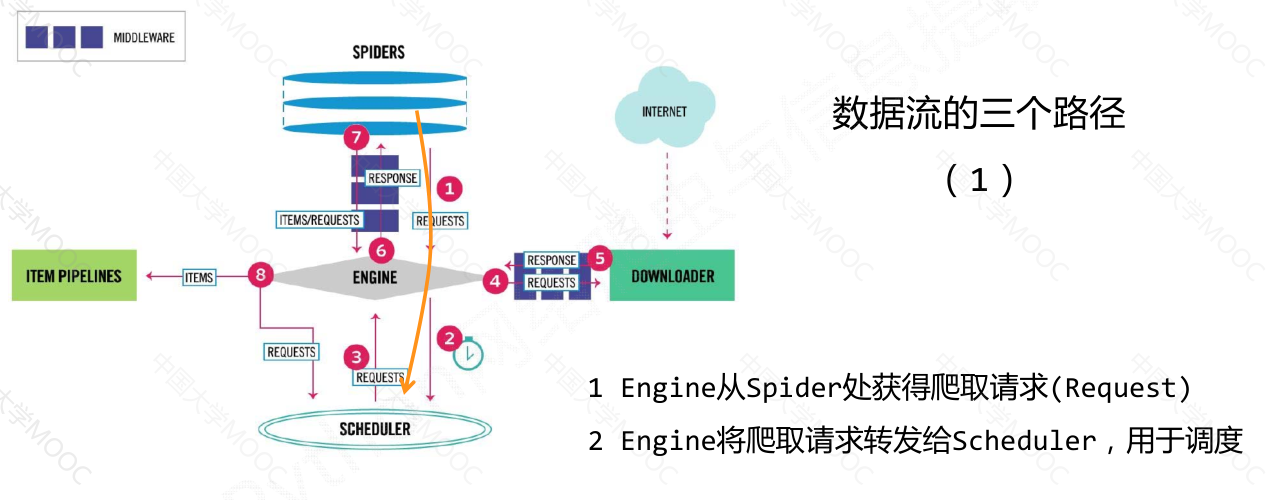
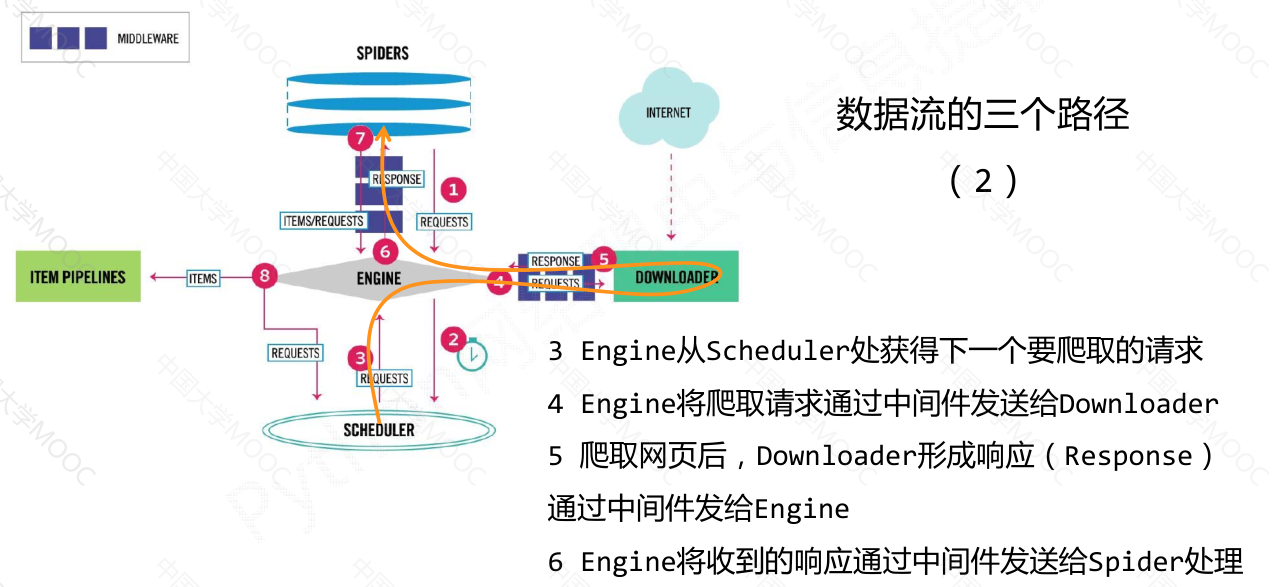
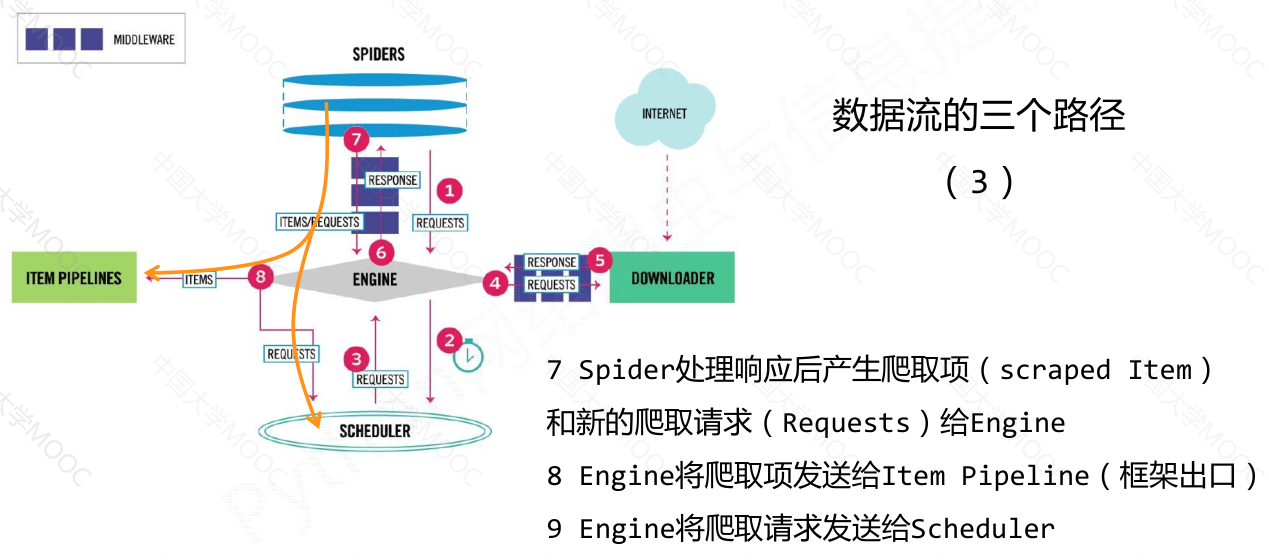
数据流的三个路径#
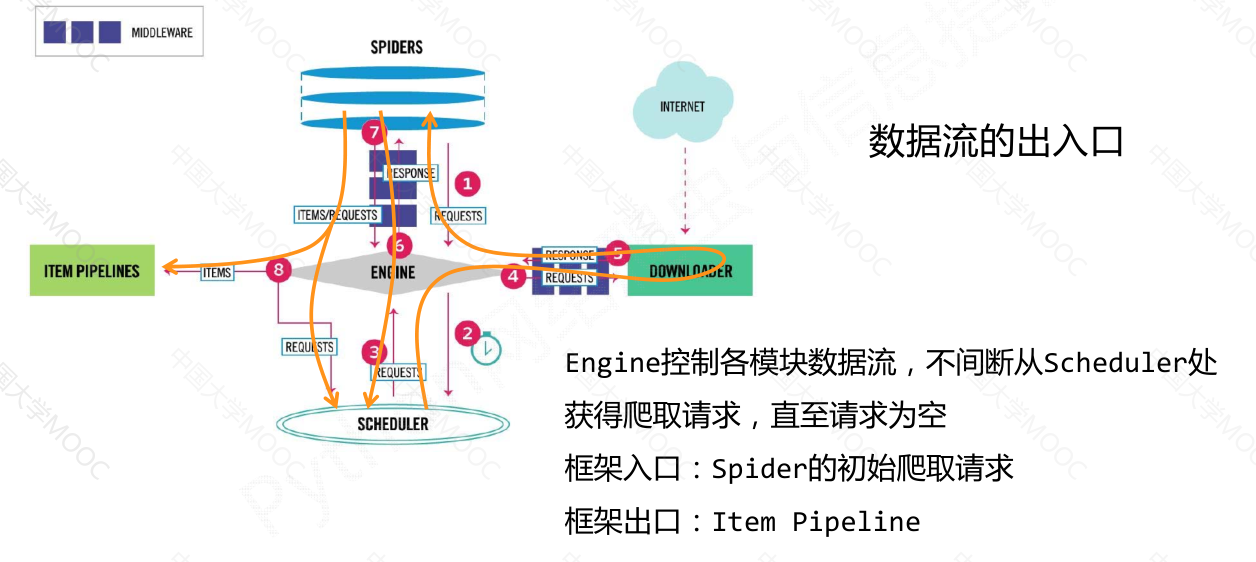
数据流的出入口#
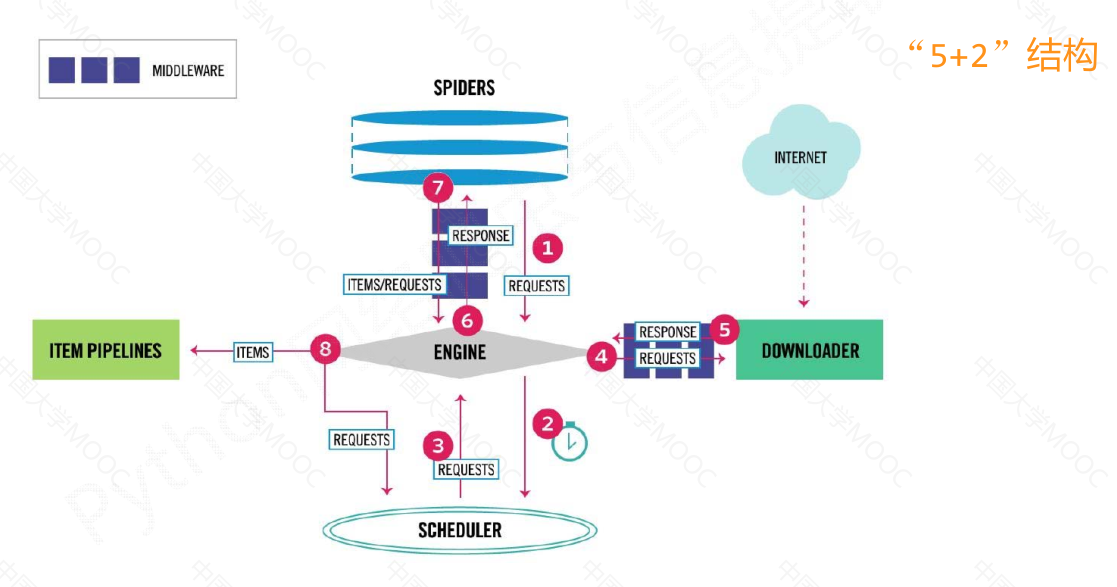
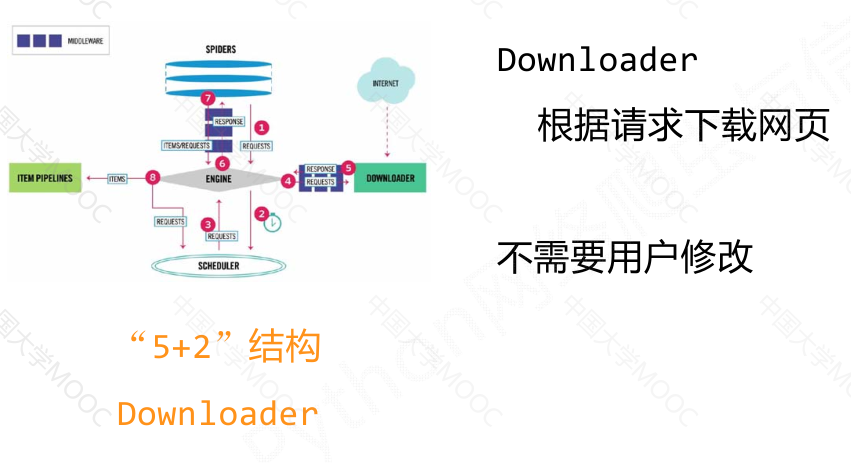
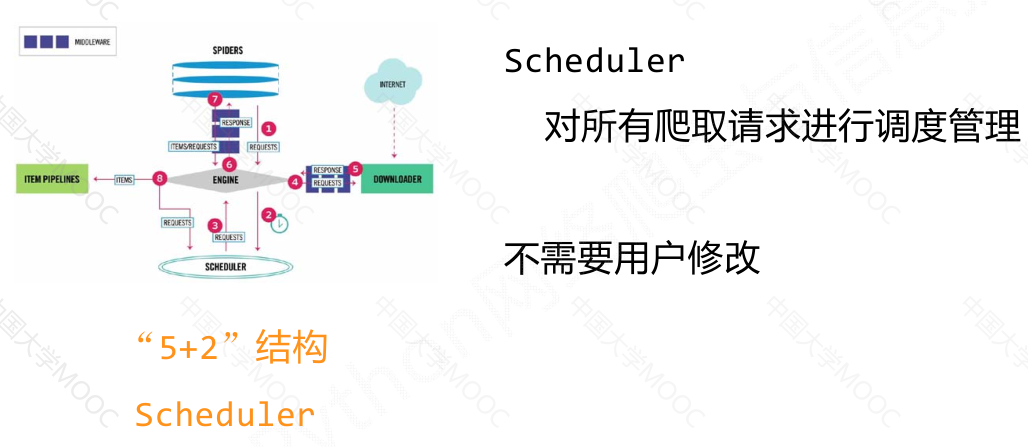
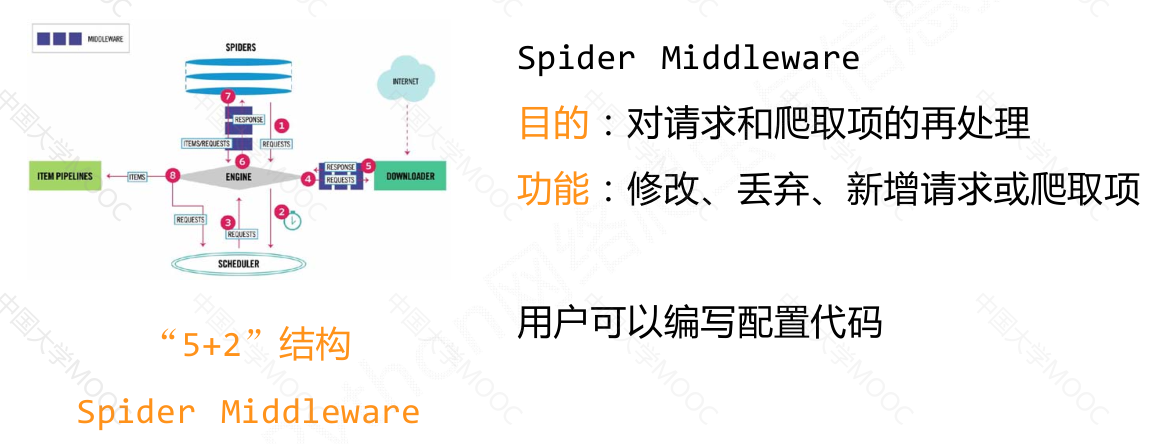
“5 + 2"结构#
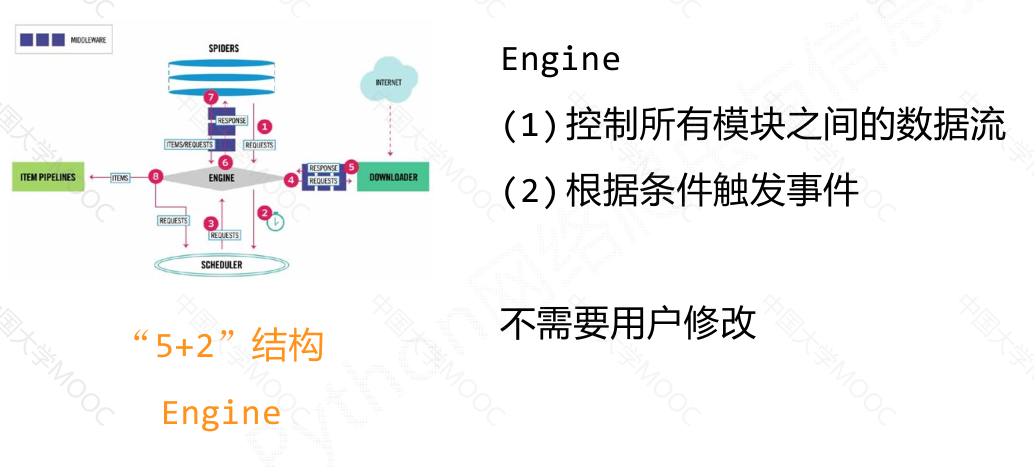


小结:#
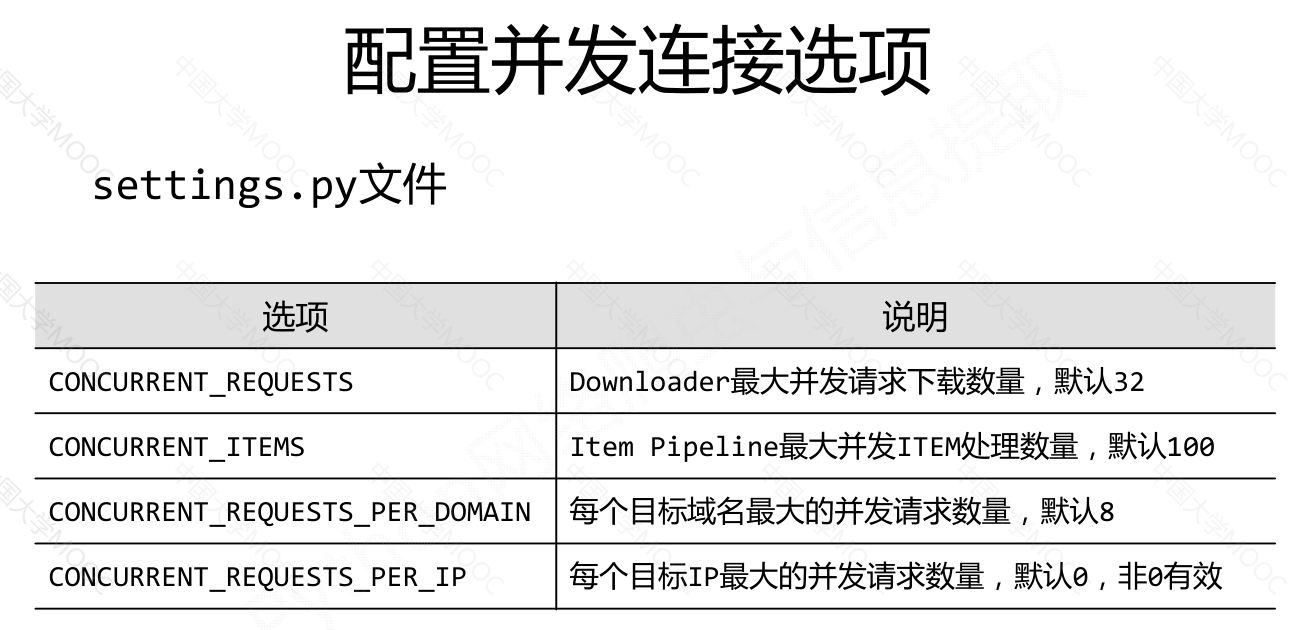
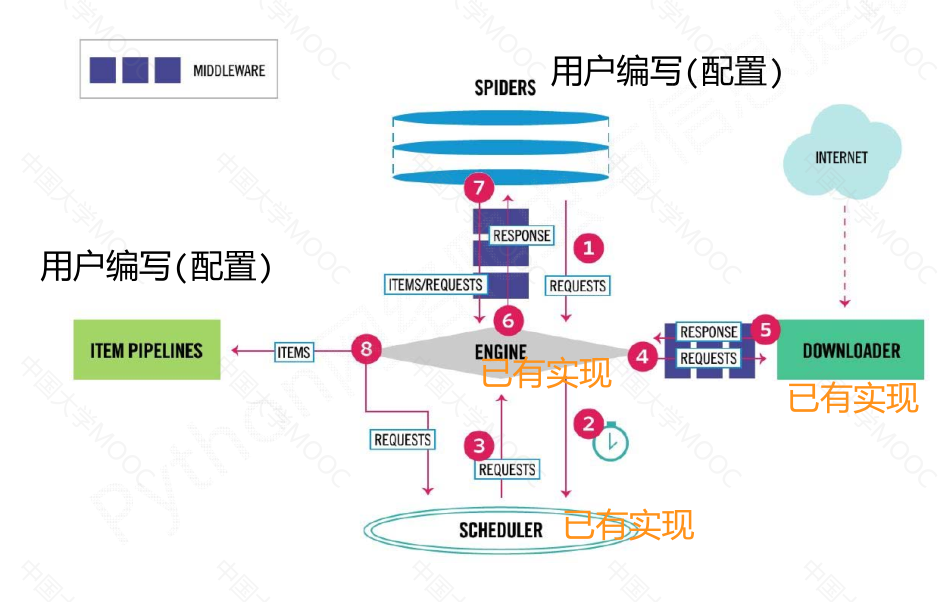
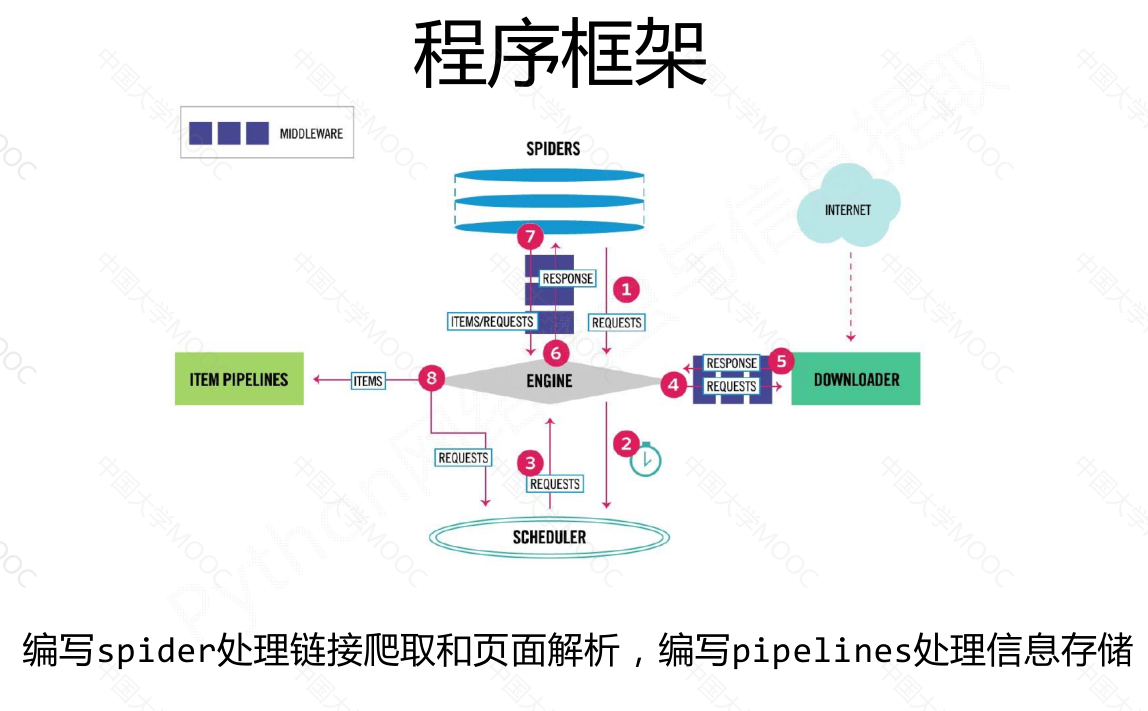
Scrapy 爬虫框架是一个包含5个主要模块和2个中间键的框架。其中,
engine模块是整个框架的核心,控制所有模块之间的数据流;
downloader模块负责根据用户提供的请求下载网页;
scheduler模块对爬取请求进行调度管理;
spider模块解析下载器返回的响应,产生爬取项和额外的爬取请求;
item pipelines模块以流水线的方式处理爬取项,对数据进行清理、检验、查重等操作。
用户主要需要编写spider模块和item pipelines模块的相关代码,可以通过中间键对请求、响应和爬取项进行操作和配置。
requests 库和 Scrapy 爬虫的比较#
相同点:#
两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
两者可用性都好,文档丰富,入门简单
两者都没有处理js、提交表单、应对验证码等功能(可扩展)
不同点:#

选用哪个技术路线开发爬虫呢?#
非常小的需求,requests库
不太小的需求,Scrapy框架
定制程度很高的需求(不考虑规模),自搭框架,requests > Scrapy
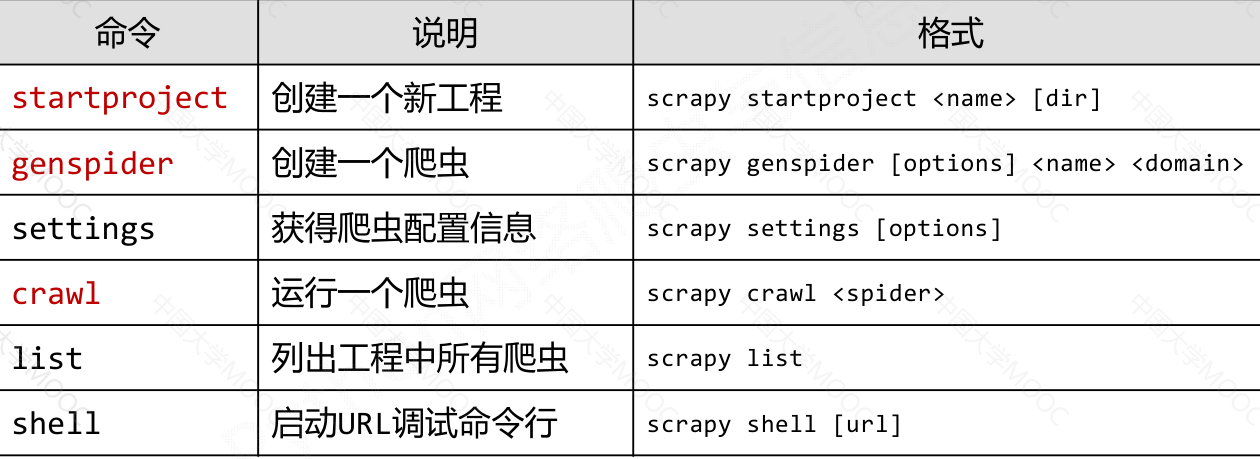
Scrapy 爬虫的常用命令#
Scrapy 是为持续运行设计的专业爬虫框架,提供操作的 Scrapy 命令行
Scrapy 命令行格式#
>scrapy <command> [options] [args]
常用命令#
Scrapy 爬虫的使用#
应用Scrapy爬虫框架主要是编写配置型代码
第一个实例#
步骤1:建立一个Scrapy爬虫工程#
选取一个目录(D:\pycodes\),然后执行如下命令:
scrapy startproject python123demo
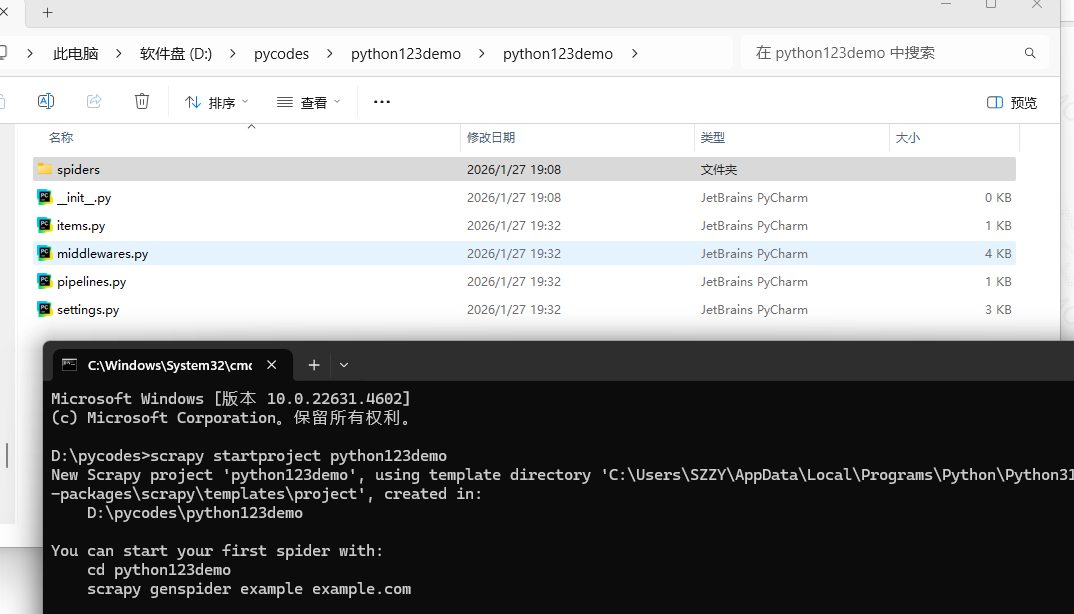
生成的工程目录:


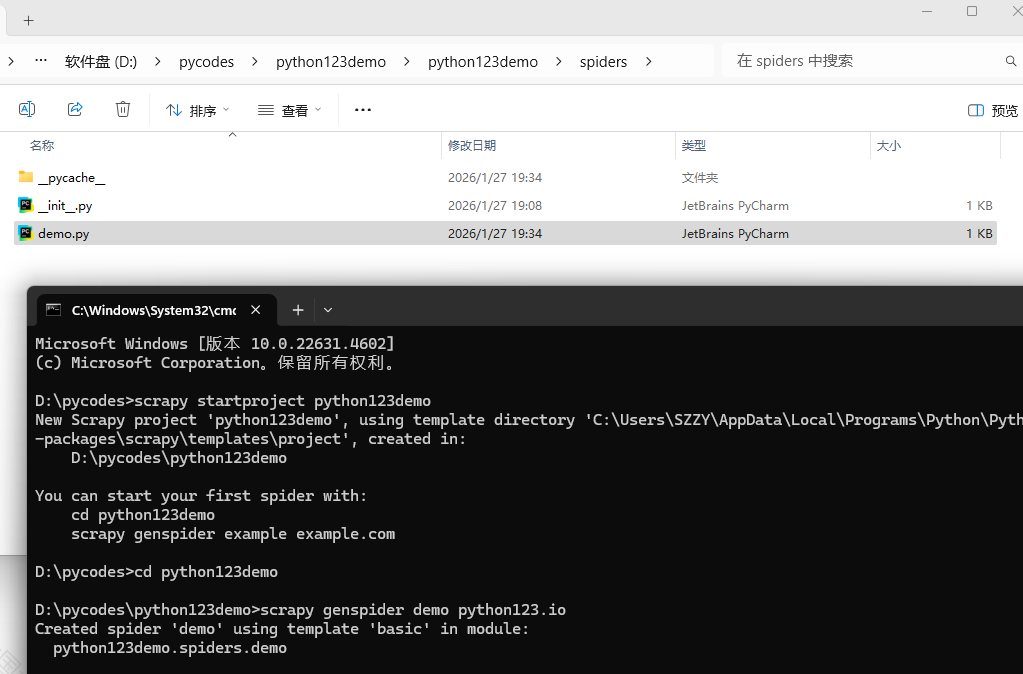
步骤2:在工程中产生一个Scrapy爬虫#
进入工程目录(D:\pycodes\python123demo),然后执行如下命令:
scrapy genspider demo python123.io
该命令作用:
(1) 生成一个名称为demo的spider
(2) 在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成

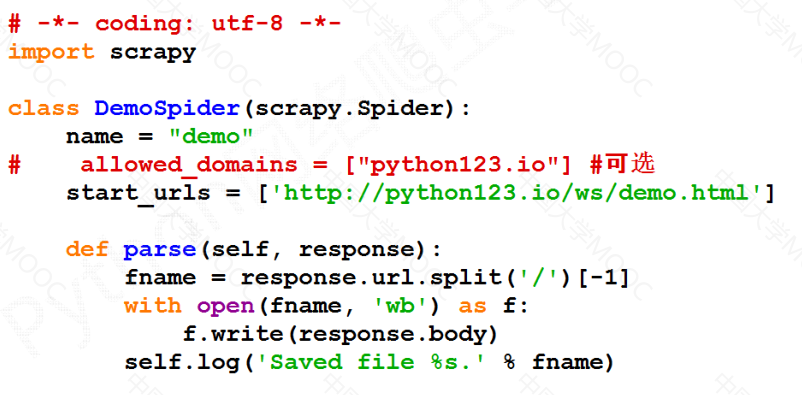
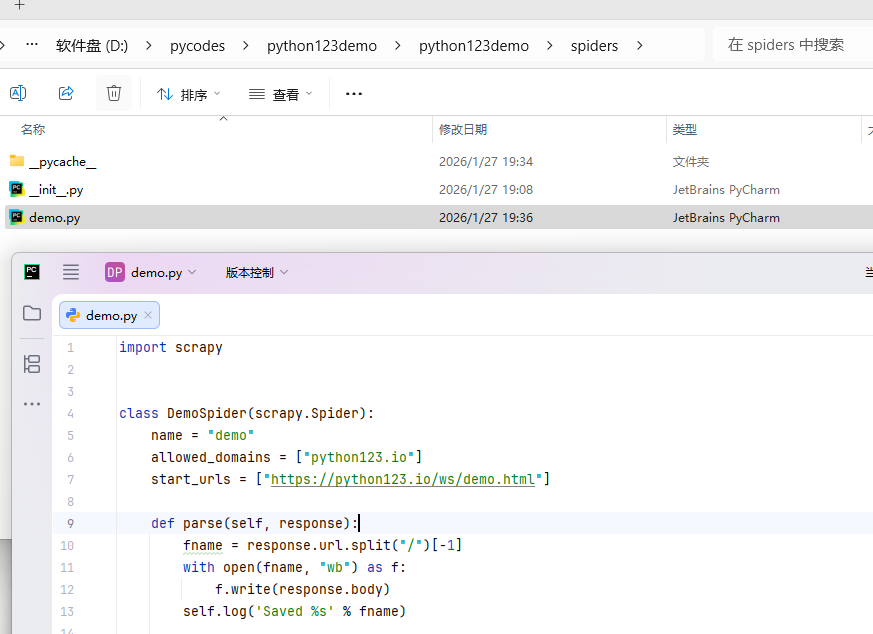
步骤3:配置产生的spider爬虫#
配置:(1)初始URL地址
(2)获取页面后的解析方式
1
2
3
4
5
6
7
8
9
10
11
12
13
| import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
allowed_domains = ["python123.io"]
start_urls = ["https://python123.io/ws/demo.html"]
def parse(self, response):
fname = response.url.split("/")[-1]
with open(fname, "wb") as f:
f.write(response.body)
self.log('Saved %s' % fname)
|
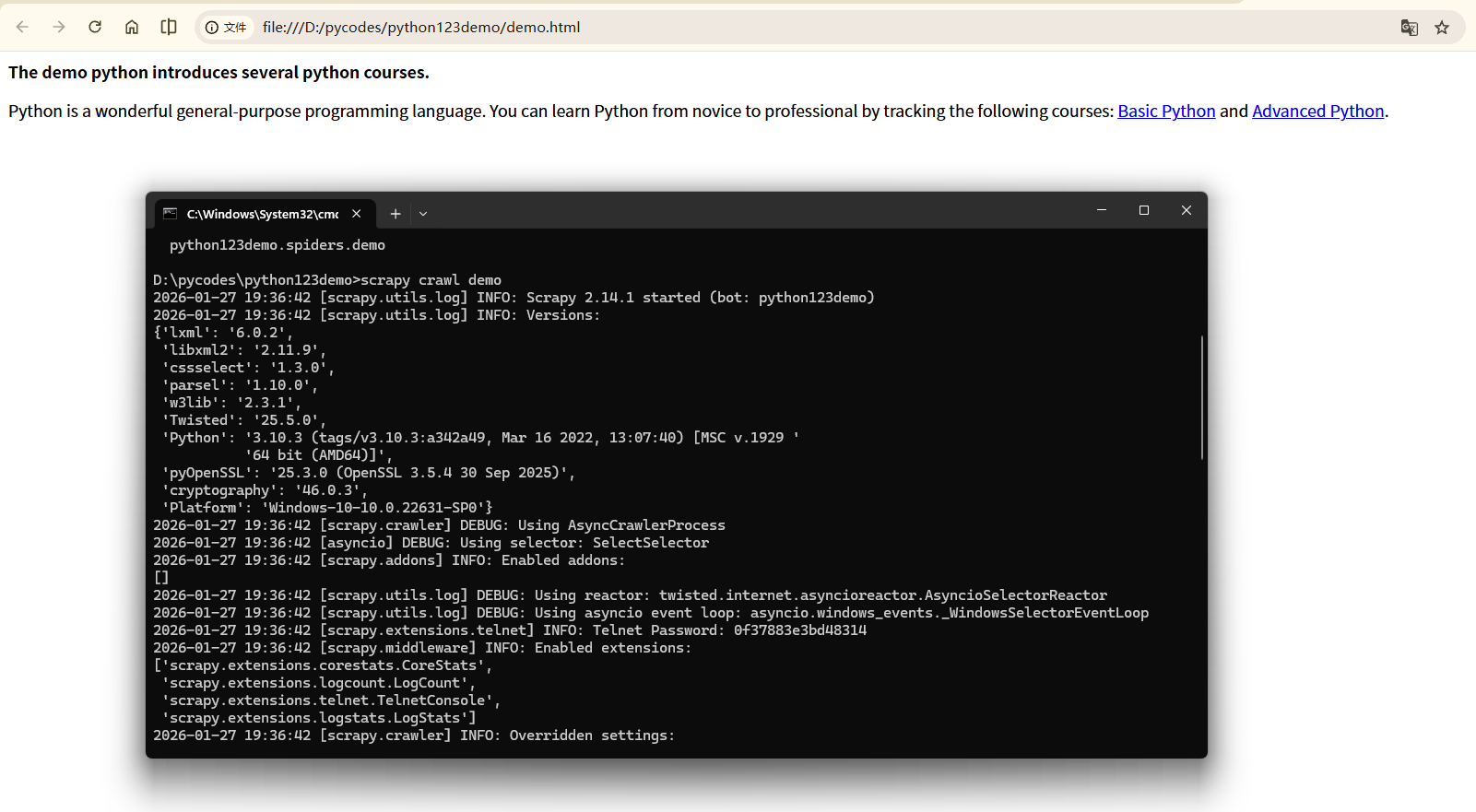
步骤4:运行爬虫,获取网页#
在命令行下,执行如下命令:
scrapy crawl demo
demo爬虫被执行,捕获页面存储在demo.html
yield 关键字的使用#
yield 关键字#

生成器每调用一次在 yield 位置产生一个值,直到函数执行结束
1
2
3
4
5
6
7
8
9
10
| def gen(n):
for i in range(n):
yield i**2
for i in gen(5):
print(i, " ", end="")
0 1 4 9 16
|

为什么要有生成器?#


改进 demo.py#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
def start_requests(self):
urls = [
"https://python123.io/ws/demo.html",
]
#把 URL 交给 Scrapy 的调度器,让 Scrapy 去“异步下载页面,并在下载完成后自动调用 parse 处理结果”。
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
fname = response.url.split("/")[-1]
with open(fname, "wb") as f:
f.write(response.body)
self.log('Saved %s' % fname)
|
yield scrapy.Request()
是 Scrapy 爬虫的 入口
负责把 URL 提交给调度器
下载完成后自动调用回调函数处理响应
Scrapy 爬虫的使用步骤#
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
Scrapy 爬虫的数据类型#
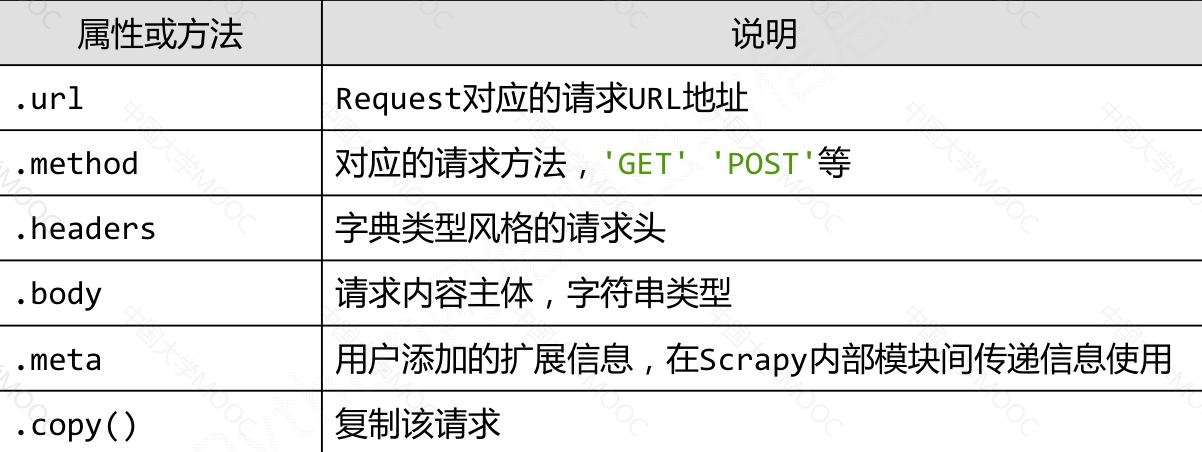
Request类#
class scrapy.http.Request()
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行
Response类#
class scrapy.http.Response()
Response对象表示一个HTTP响应
由Downloader生成,由Spider处理

Item类#
class scrapy.item.Item()
Item 对象表示一个从 HTML 页面中提取的信息内容
由 Spider 生成,由 Item Pipeline 处理
Item 类似字典类型,可以按照字典类型操作
Scrapy 爬虫提取信息的方法#
Scrapy爬虫支持多种HTML信息提取方法:
• Beautiful Soup
• lxml
• re
• XPath Selector
• CSS Selector
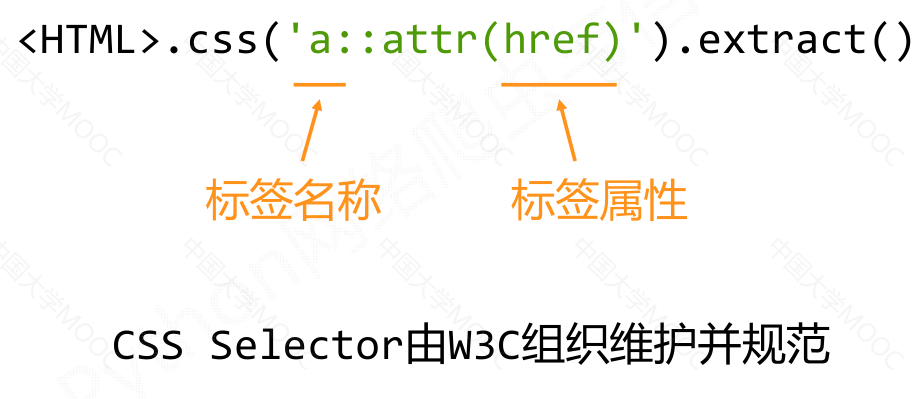
CSS Selector 的基本使用#
<HTML>.css('a::attr(href)').extract()
实例:“股票数据 Scrapy 爬虫”#


步骤1:建立工程和Spider模板
步骤2:编写Spider
步骤3:编写ITEM Pipelines
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
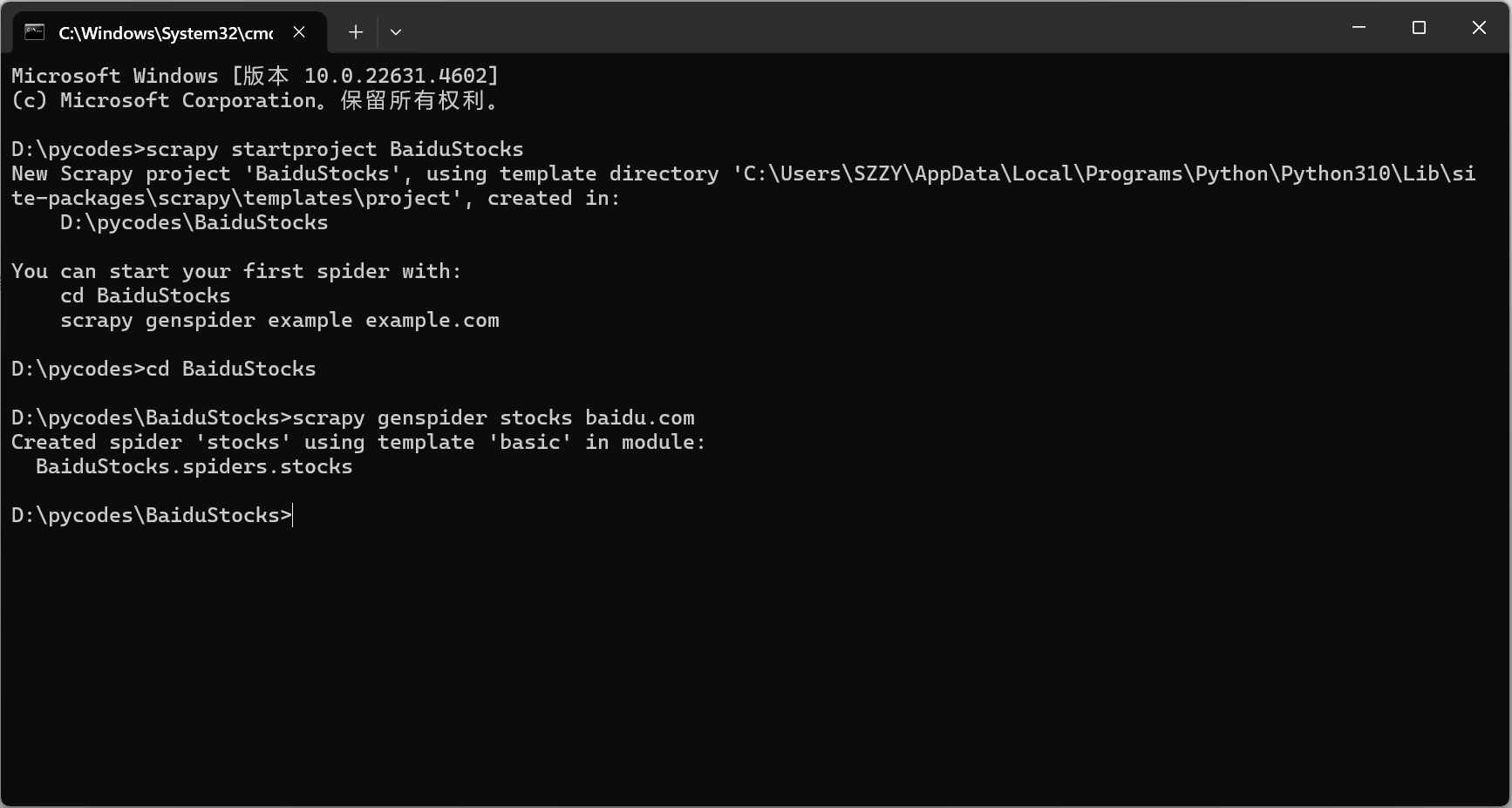
| D:\pycodes>scrapy startproject BaiduStocks
New Scrapy project 'BaiduStocks', using template directory 'C:\Users\SZZY\AppData\Local\Programs\Python\Python310\Lib\site-packages\scrapy\templates\project', created in:
D:\pycodes\BaiduStocks
You can start your first spider with:
cd BaiduStocks
scrapy genspider example example.com
D:\pycodes>cd BaiduStocks
D:\pycodes\BaiduStocks>scrapy genspider stocks baidu.com
Created spider 'stocks' using template 'basic' in module:
BaiduStocks.spiders.stocks
D:\pycodes\BaiduStocks>
|
stocks.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['http://quote.eastmoney.com/stocklist.html']
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*<\dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'>.*<\dt>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key] = val
infoDict.update(
{
'股票名称': re.findall('\s.*\(', name)[0].split()[0] + re.findall('\>.*\<', name)[0][1:-1]
}
)
yield infoDict
|
pipeline.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from itemadapter import ItemAdapter
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaiduStocksPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStocks.txt','w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + "\n"
self.f.write(str(item))
except:
pass
return item
|
setting.py