PubMed 单篇文献基本信息获取#
https://pubmed.ncbi.nlm.nih.gov/33883728/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import requests
from lxml import etree
url = "https://pubmed.ncbi.nlm.nih.gov/33883728/"
r = requests.get(url).text
html = etree.HTML(r)
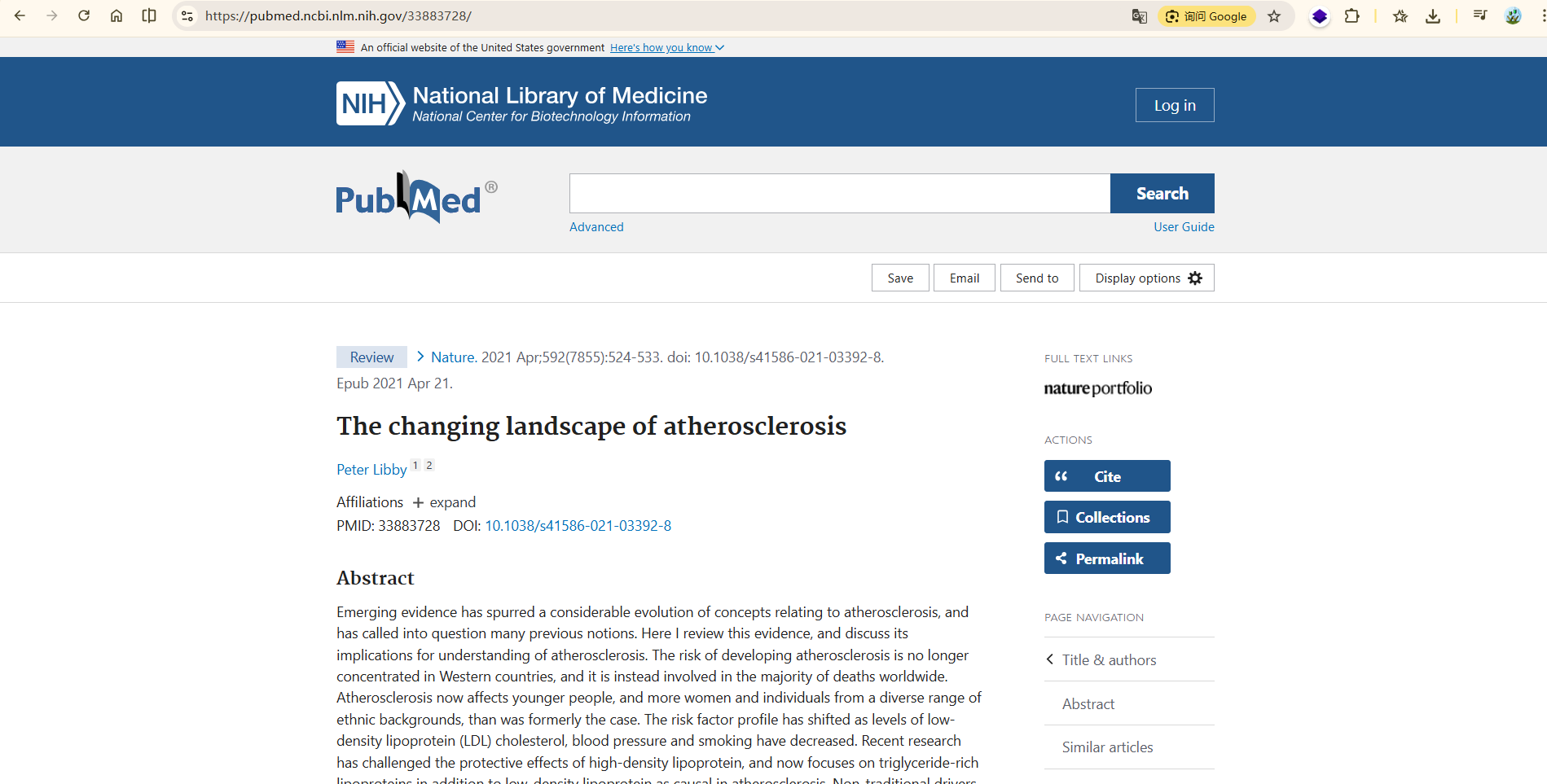
title = html.xpath('//*[@id="full-view-heading"]/h1/text()')[0].strip()
print(title)
authors = html.xpath('//*[@id="full-view-heading"]/div[2]/div/div/span/a/text()')
authors = ','.join(authors)
print(authors)
pmID = html.xpath('//*[@id="full-view-identifiers"]/li[1]/span/strong/text()')[0]
print(pmID)
mag = html.xpath('//*[@id="full-view-journal-trigger"]/text()')[0].strip()
print(mag)
info = html.xpath('//*[@id="full-view-heading"]/div[1]/div[2]/span[2]/text()')[0].split(';')
year = info[0][:4]
info = info[1]
print(info)
print(year)
abstract = html.xpath('//*[@id="eng-abstract"]/p/text()')[0].strip()
print(abstract)
try:
kw = html.xpath('/html/body/div[5]/main/div[2]/p/text()')[1].strip()
print(kw)
except:
pass
|
PubMed 多篇文献基本信息获取#
文章对应链接的获取#
在搜索页中,默认为十篇,先爬取一篇文章的链接
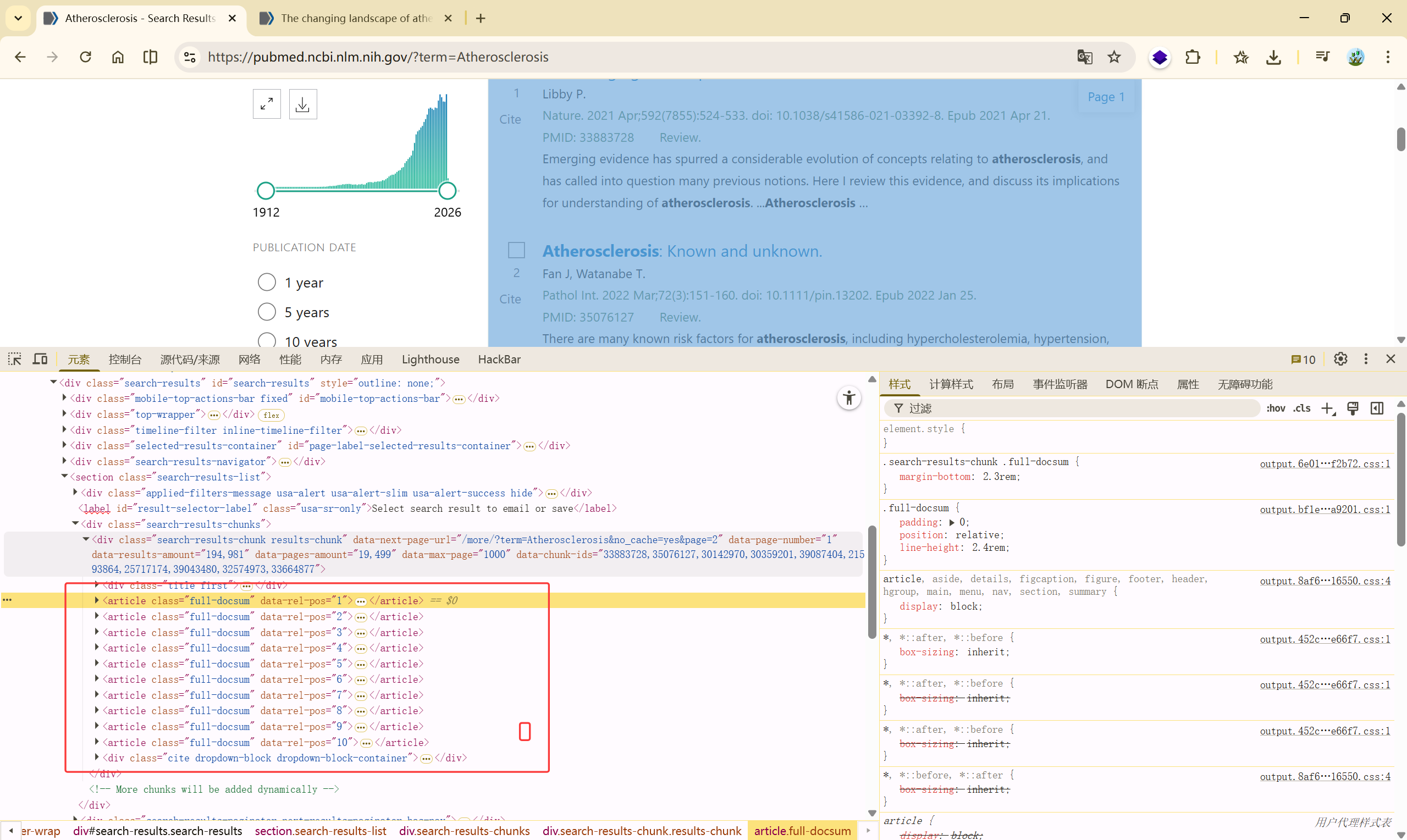
复制 Xpath ://*[@id="search-results"]/section/div[2]/div/article[1]/div[2]/div[1]/a
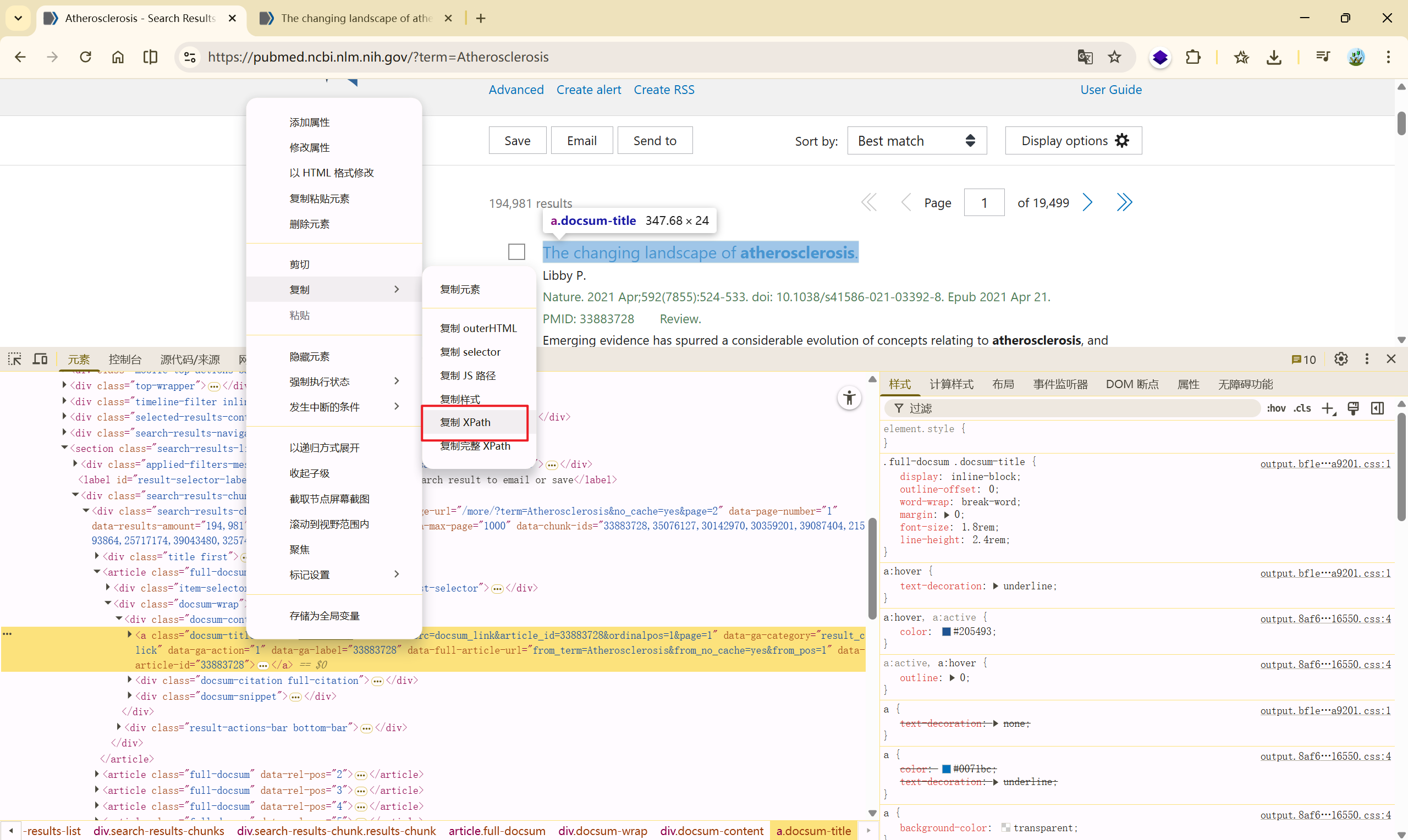
根据验证的跳转文章链接为:[https://pubmed.ncbi.nlm.nih.gov/33883728/](https://pubmed.ncbi.nlm.nih.gov/33883728/),可以确定,Xpath 中的href属性是我们需要的,
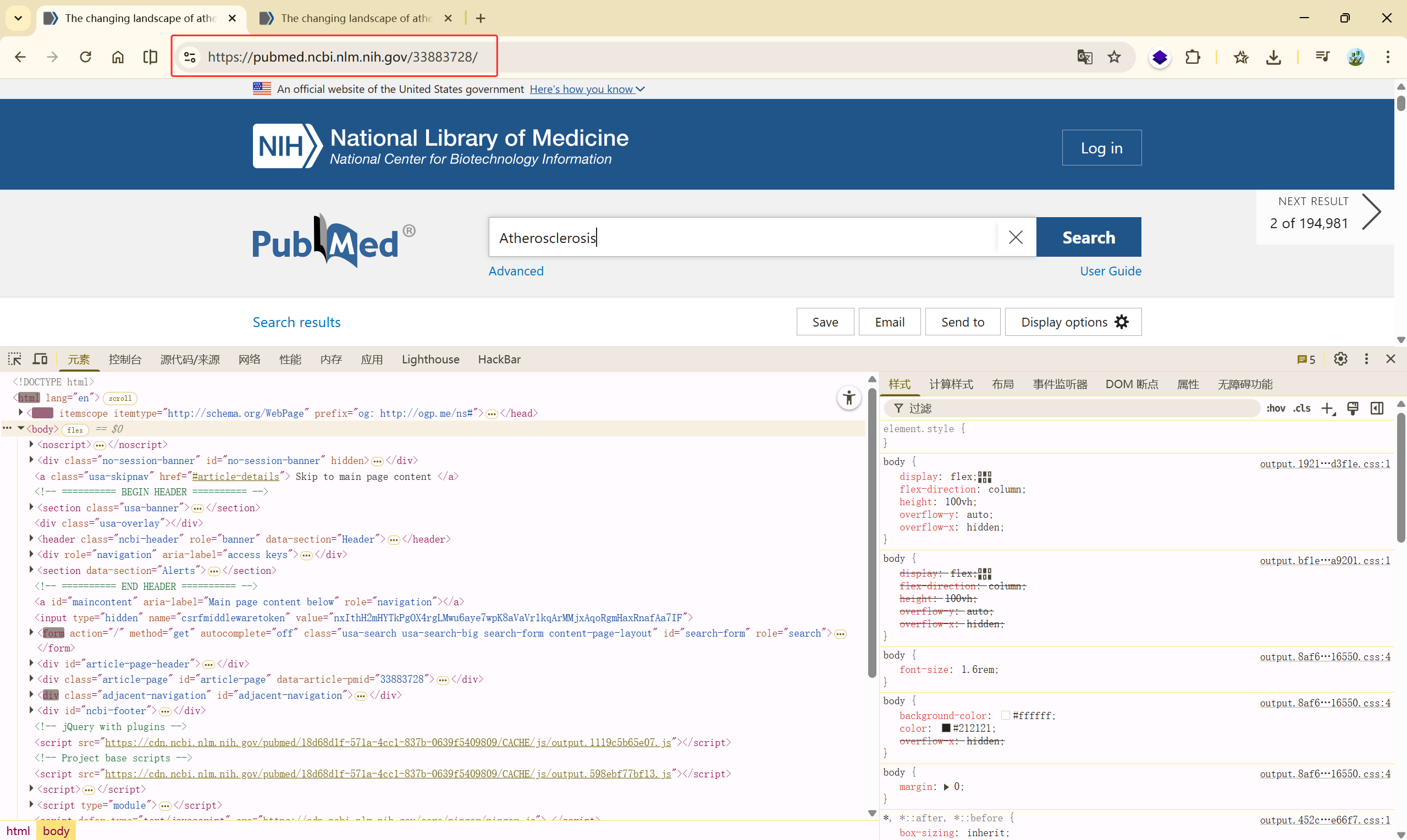
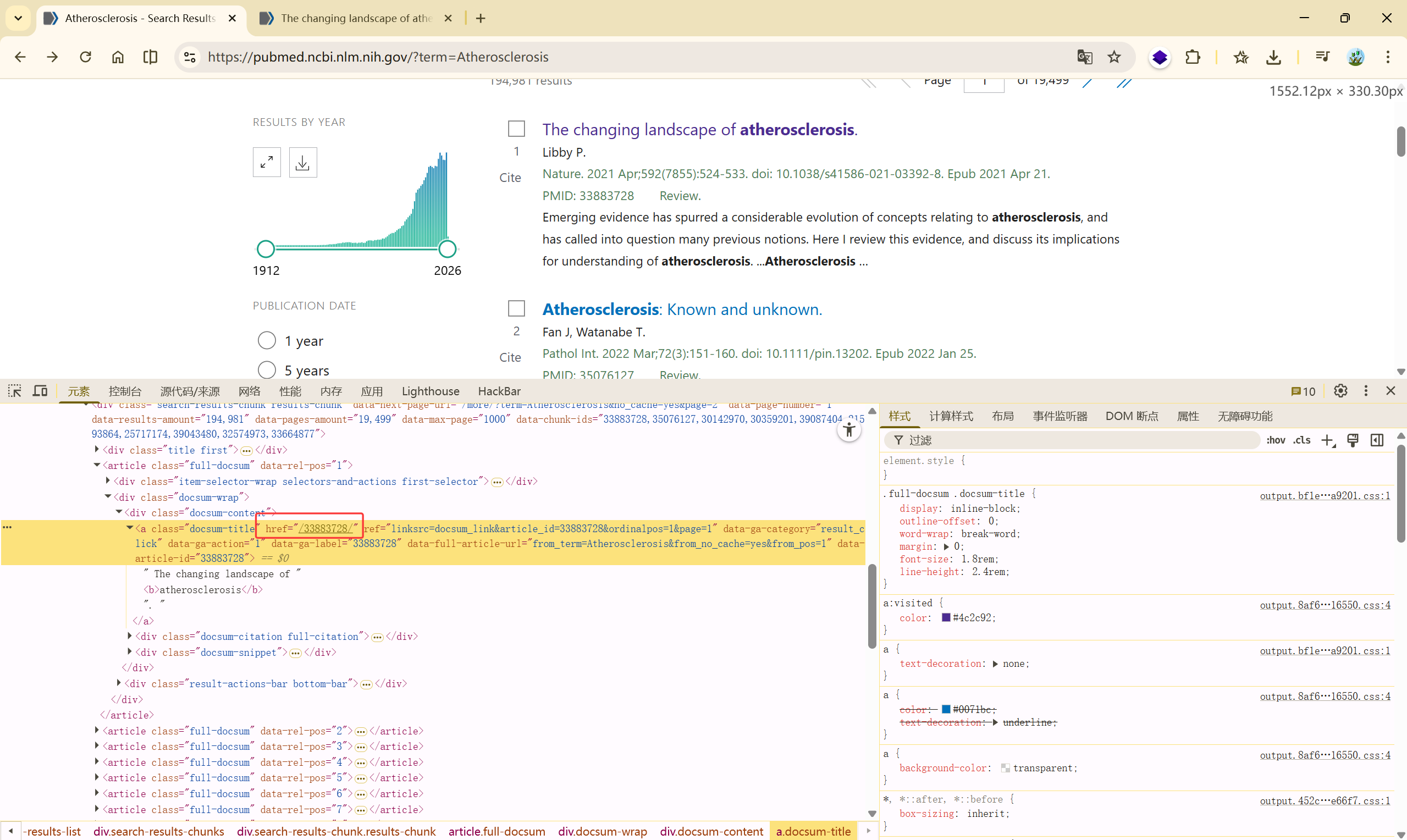
那么获取链接的代码:
1
| link = html.xpath('//*[@id="search-results"]/section/div[2]/div/article[1]/div[2]/div[1]/a/@href')
|
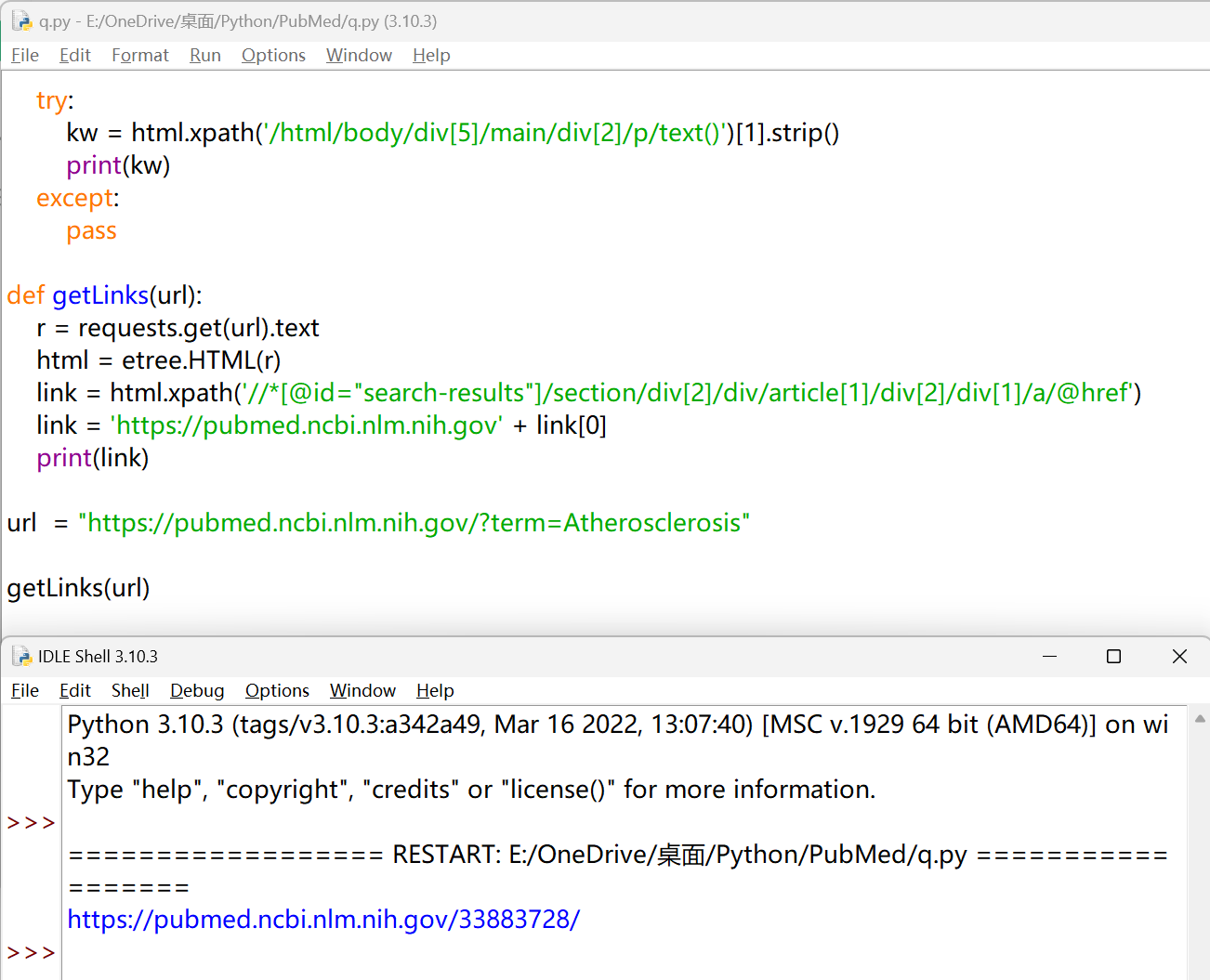
接下来就要想如何利用循环将这一页的 10 篇文章的链接获取到?
1、2、3 篇文章对应的 Xpath:
1
2
3
| //*[@id="search-results"]/section/div[2]/div/article[1]/div[2]/div[1]/a
//*[@id="search-results"]/section/div[2]/div/article[2]/div[2]/div[1]/a
//*[@id="search-results"]/section/div[2]/div/article[3]/div[2]/div[1]/a
|
可以发现,发生变化的是 article[]
1
2
3
4
| for num in range(1,11):
link = html.xpath(f'//*[@id="search-results"]/section/div[2]/div/article[{num}]/div[2]/div[1]/a/@href')
link = 'https://pubmed.ncbi.nlm.nih.gov' + link[0]
print(link)
|
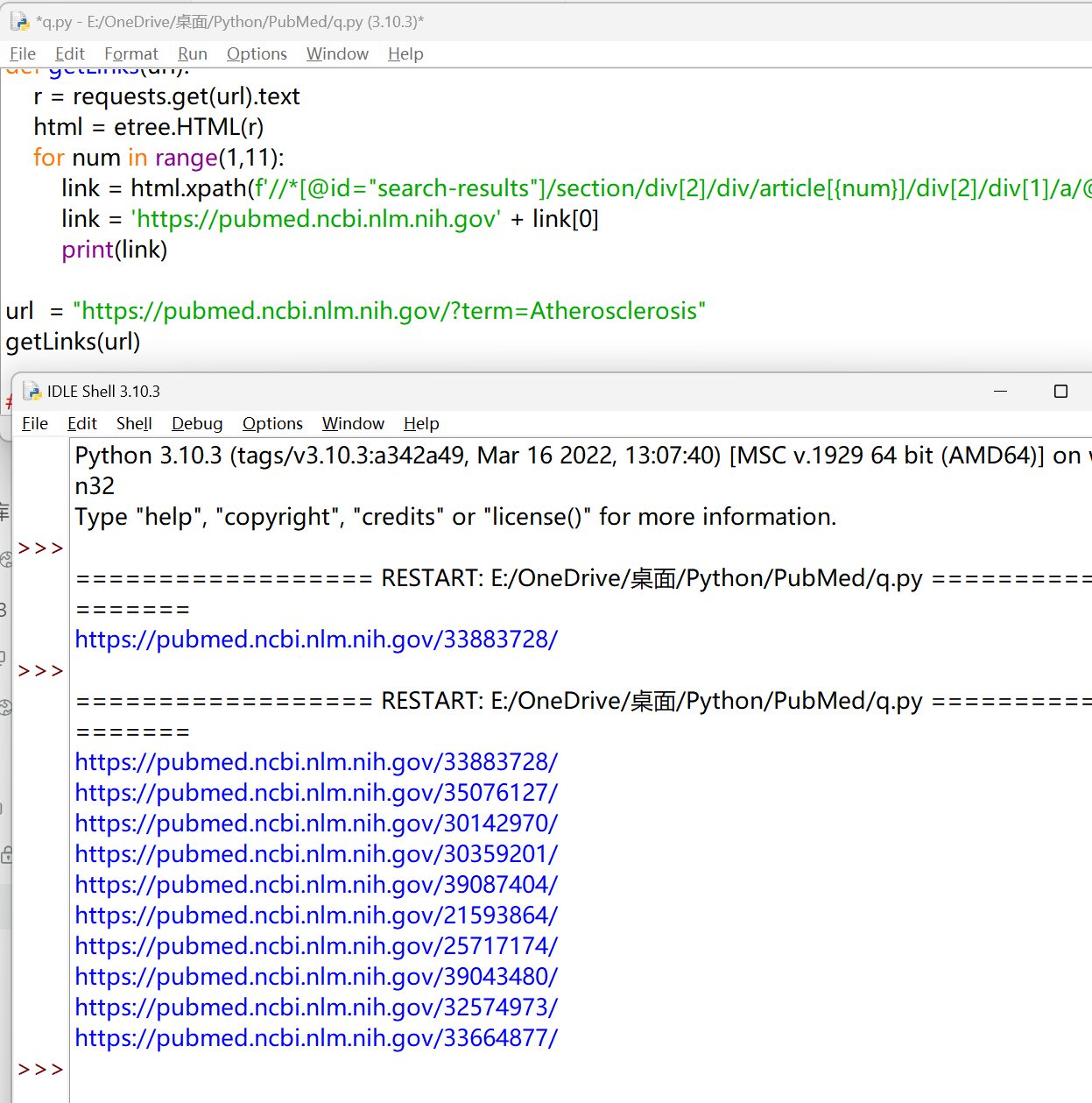
完整代码:#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import requests
from lxml import etree
#url = "https://pubmed.ncbi.nlm.nih.gov/33883728/"
def getSigleParperInfo(url):
r = requests.get(url).text
html = etree.HTML(r)
title = html.xpath('//*[@id="full-view-heading"]/h1/text()')[0].strip()
print(title)
authors = html.xpath('//*[@id="full-view-heading"]/div[2]/div/div/span/a/text()')
authors = ','.join(authors)
print(authors)
pmID = html.xpath('//*[@id="full-view-identifiers"]/li[1]/span/strong/text()')[0]
print(pmID)
mag = html.xpath('//*[@id="full-view-journal-trigger"]/text()')[0].strip()
print(mag)
info = html.xpath('//*[@id="full-view-heading"]/div[1]/div[2]/span[2]/text()')[0].split(';')
year = info[0][:4]
info = info[1]
print(info)
print(year)
try:
abstract = html.xpath('//*[@id="eng-abstract"]/p/text()')[0].strip()
print(abstract)
except:
pass
try:
kw = html.xpath('/html/body/div[5]/main/div[2]/p/text()')[1].strip()
print(kw)
except:
pass
def getLinks(url):
r = requests.get(url).text
html = etree.HTML(r)
for num in range(1,11):
link = html.xpath(f'//*[@id="search-results"]/section/div[2]/div/article[{num}]/div[2]/div[1]/a/@href')
link = 'https://pubmed.ncbi.nlm.nih.gov' + link[0]
print(link)
getSigleParperInfo(link)
print('\n\n==================\n\n')
url = "https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis"
getLinks(url)
#目录页链接
#"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=2"
#"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=3"
|
针对遇到的一些问题,进行了修正:#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import requests
from lxml import etree
#url = "https://pubmed.ncbi.nlm.nih.gov/33883728/"
def getSigleParperInfo(url):
r = requests.get(url).text
html = etree.HTML(r)
title = html.xpath('//*[@id="full-view-heading"]/h1/text()')[0].strip()
print(title)
authors = html.xpath('//*[@id="full-view-heading"]/div[2]/div/div/span/a/text()')
authors = ','.join(authors)
print(authors)
pmID = html.xpath('//*[@id="full-view-identifiers"]/li[1]/span/strong/text()')[0]
print(pmID)
mag = html.xpath('//*[@id="full-view-journal-trigger"]/text()')[0].strip()
print(mag)
info_list = html.xpath('//*[@id="full-view-heading"]/div[1]/div[2]/span[2]/text()')
# 先检查XPath是否返回了结果
if info_list:
info_text = info_list[0].strip()
info_parts = info_text.split(';')
year = info_parts[0][:4] if info_parts else ""
info = info_parts[1] if len(info_parts) > 1 else ""
print(info)
print(year)
try:
abstract = html.xpath('//*[@id="eng-abstract"]/p/text()')[0].strip()
print(abstract)
except:
pass
try:
kw = html.xpath('/html/body/div[5]/main/div[2]/p/text()')[1].strip()
print(kw)
except:
pass
def getLinks(url):
r = requests.get(url).text
html = etree.HTML(r)
for num in range(1,11):
link = html.xpath(f'//*[@id="search-results"]/section/div[2]/div/article[{num}]/div[2]/div[1]/a/@href')
link = 'https://pubmed.ncbi.nlm.nih.gov' + link[0]
print(link)
getSigleParperInfo(link)
print('\n\n==================\n\n')
url = "https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis"
getLinks(url)
#目录页链接
#"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=2"
#"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=3"
|
翻页获取多篇文献信息#
记录链接:
1
2
3
| https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis
https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=2
https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=3
|
并且[https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=1](https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page=1)可以打开第一页
1
2
3
4
|
for pageNum in range(1, 11):
url = f"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page={pageNum}"
getLinks(url)
|
完整代码#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import requests
from lxml import etree
#url = "https://pubmed.ncbi.nlm.nih.gov/33883728/"
def getSigleParperInfo(url):
r = requests.get(url).text
html = etree.HTML(r)
title = html.xpath('//*[@id="full-view-heading"]/h1/text()')[0].strip()
print(title)
authors = html.xpath('//*[@id="full-view-heading"]/div[2]/div/div/span/a/text()')
authors = ','.join(authors)
#print(authors)
pmID = html.xpath('//*[@id="full-view-identifiers"]/li[1]/span/strong/text()')[0]
#print(pmID)
mag = html.xpath('//*[@id="full-view-journal-trigger"]/text()')[0].strip()
#print(mag)
info_list = html.xpath('//*[@id="full-view-heading"]/div[1]/div[2]/span[2]/text()')
if info_list:
info_text = info_list[0].strip()
info_parts = info_text.split(';')
year = info_parts[0][:4] if info_parts else ""
info = info_parts[1] if len(info_parts) > 1 else ""
#print(info)
#print(year)
try:
abstract = html.xpath('//*[@id="eng-abstract"]/p/text()')[0].strip()
#print(abstract)
except:
pass
try:
kw = html.xpath('/html/body/div[5]/main/div[2]/p/text()')[1].strip()
#print(kw)
except:
pass
def getLinks(url):
r = requests.get(url).text
html = etree.HTML(r)
for num in range(1,11):
link = html.xpath(f'//*[@id="search-results"]/section/div[2]/div/article[{num}]/div[2]/div[1]/a/@href')
link = 'https://pubmed.ncbi.nlm.nih.gov' + link[0]
print(link)
getSigleParperInfo(link)
print('\n\n==================\n\n')
for pageNum in range(1, 11):
url = f"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page={pageNum}"
getLinks(url)
|

使用 pandas 处理数据#
https://pandas.pydata.org/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| import requests
from lxml import etree
import pandas as pd
columns = ['Title', 'Authors', 'pmID','Mag', 'Info', 'Year', 'Abstract', 'Keywords']
papersInfo = []
def getSigleParperInfo(url):
siglePaperInfo = []
r = requests.get(url).text
html = etree.HTML(r)
title = html.xpath('//*[@id="full-view-heading"]/h1/text()')[0].strip()
siglePaperInfo.append(title)
authors = html.xpath('//*[@id="full-view-heading"]/div[2]/div/div/span/a/text()')
authors = ','.join(authors)
siglePaperInfo.append(authors)
pmID = html.xpath('//*[@id="full-view-identifiers"]/li[1]/span/strong/text()')[0]
siglePaperInfo.append(pmID)
mag = html.xpath('//*[@id="full-view-journal-trigger"]/text()')[0].strip()
siglePaperInfo.append(mag)
info_list = html.xpath('//*[@id="full-view-heading"]/div[1]/div[2]/span[2]/text()')
if info_list:
info_text = info_list[0].strip()
info_parts = info_text.split(';')
year = info_parts[0][:4] if info_parts else ""
info = info_parts[1] if len(info_parts) > 1 else ""
siglePaperInfo.append(info)
siglePaperInfo.append(year)
# 初始化摘要和关键词为空字符串
abstract = ""
kw = ""
try:
abstract = html.xpath('//*[@id="eng-abstract"]/p/text()')[0].strip()
except:
pass
try:
kw = html.xpath('/html/body/div[5]/main/div[2]/p/text()')[1].strip()
except:
pass
# 确保添加摘要和关键词
siglePaperInfo.append(abstract)
siglePaperInfo.append(kw)
print(f"文章元素数量: {len(siglePaperInfo)}")
print(siglePaperInfo)
papersInfo.append(siglePaperInfo)
def getLinks(url):
r = requests.get(url).text
html = etree.HTML(r)
for num in range(1,11):
link = html.xpath(f'//*[@id="search-results"]/section/div[2]/div/article[{num}]/div[2]/div[1]/a/@href')
link = 'https://pubmed.ncbi.nlm.nih.gov' + link[0]
print(link)
getSigleParperInfo(link)
print('\n\n==================\n\n')
for pageNum in range(1, 3):
url = f"https://pubmed.ncbi.nlm.nih.gov/?term=Atherosclerosis&page={pageNum}"
getLinks(url)
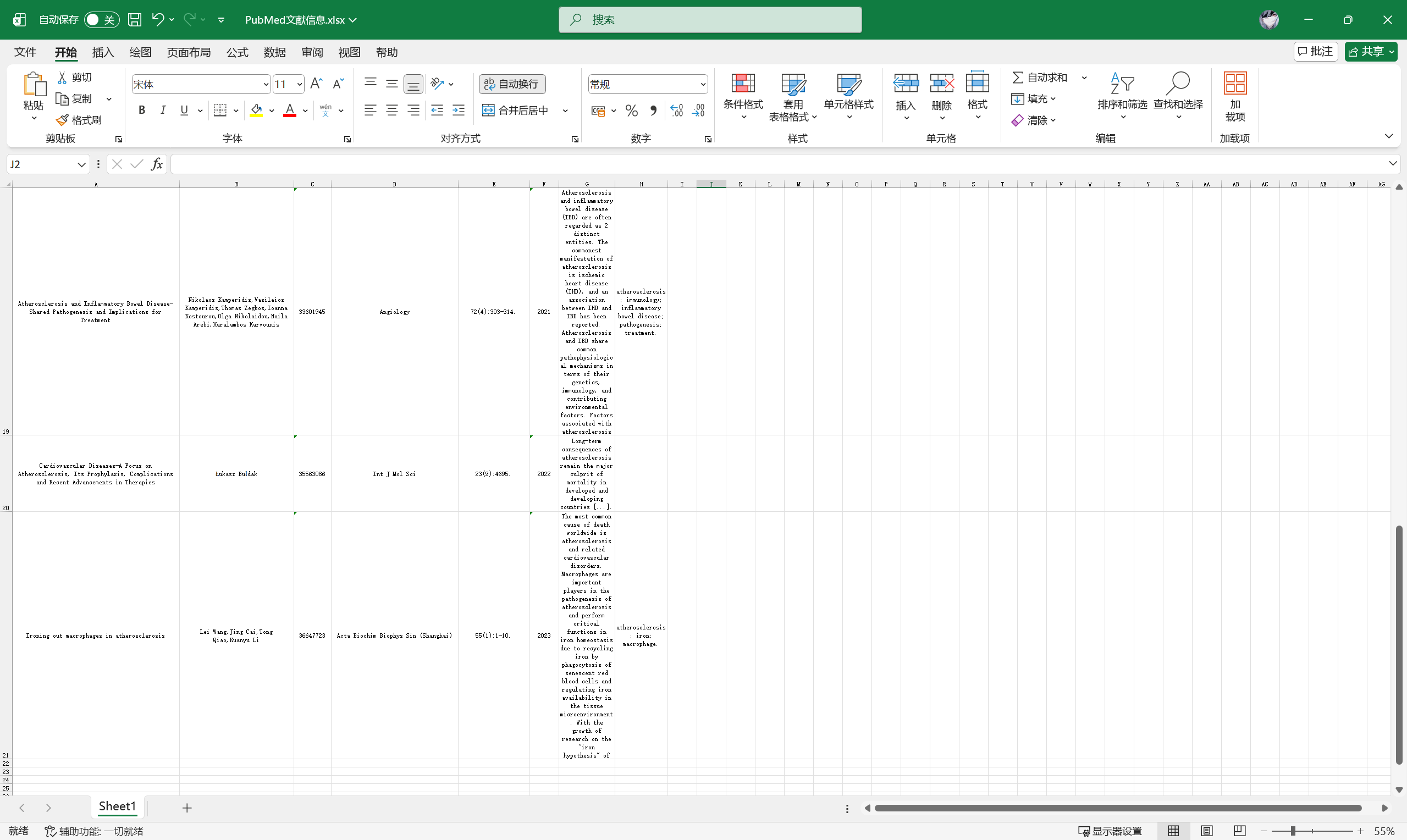
df1 = pd.DataFrame(papersInfo, columns = columns)
df1.to_excel("PubMed文献信息.xlsx", index = False)
|