Beautiful Soup 库入门#
官网:https://www.crummy.com/software/BeautifulSoup/
You didn’t write that awful page. You’re just trying to get some data out of it. Beautiful Soup is here to help. Since 2004, it’s been saving programmers hours or days of work on quick-turnaround screen scraping projects.
Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping. Three features make it powerful:
- Beautiful Soup provides a few simple methods and Pythonic idioms for navigating, searching, and modifying a parse tree: a toolkit for dissecting a document and extracting what you need. It doesn’t take much code to write an application
- Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8. You don’t have to think about encodings, unless the document doesn’t specify an encoding and Beautiful Soup can’t detect one. Then you just have to specify the original encoding.
- Beautiful Soup sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility.
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. You can tell it “Find all the links”, or “Find all the links of class externalLink”, or “Find all the links whose urls match “foo.com”, or “Find the table heading that’s got bold text, then give me that text."
Valuable data that was once locked up in poorly-designed websites is now within your reach. Projects that would have taken hours take only minutes with Beautiful Soup.
Interested?
你并没有编写那个糟糕的页面,你只是想从中提取一些数据。Beautiful Soup 就是为此而生的。自2004年以来,它已经帮助程序员在快速周转的网页抓取项目中节省了数小时乃至数天的时间。
Beautiful Soup 是一个专为快速项目如网页抓取设计的 Python 库。它的强大之处在于三个特点:
- Beautiful Soup 提供了一些简单的方法和 Python 风格的习惯用法来导航、搜索以及修改解析树:这是一套用于拆解文档并提取所需信息的工具包。编写应用程序不需要太多代码。
- Beautiful Soup 会自动将输入文档转换成 Unicode,并将输出文档转换成 UTF-8 格式。除非文档没有指定编码且 Beautiful Soup 无法检测到,否则你不必考虑编码问题。在这种情况下,你只需要指定原始编码即可。
- Beautiful Soup 基于流行的 Python 解析器如 lxml 和 html5lib 构建,允许你尝试不同的解析策略或是在速度与灵活性之间进行权衡。
Beautiful Soup 可以解析任何你给它的内容,并为你处理树遍历的工作。你可以告诉它“找到所有的链接”,或者“找到所有类名为 externalLink 的链接”,或者“找到 URL 匹配 ‘foo.com’ 的所有链接”,或者“找到包含粗体文本的表格标题,然后给我该文本。”
那些曾经被锁定在设计不佳网站中的宝贵数据现在变得触手可及。使用 Beautiful Soup,原本需要花费数小时完成的项目现在只需几分钟即可搞定。
感兴趣吗?
Beautiful Soup 库的安装#
pip install beautifulsoup4
1
2
3
4
5
6
| <html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
|
使用实例#
1
2
3
4
5
6
7
8
9
10
| import requests
r = requests.get("https://python123.io/ws/demo.html")
r.text
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
print(soup.prettify())
|
Beautiful Soup 库的基本元素#
Beautiful Soup 库的理解#
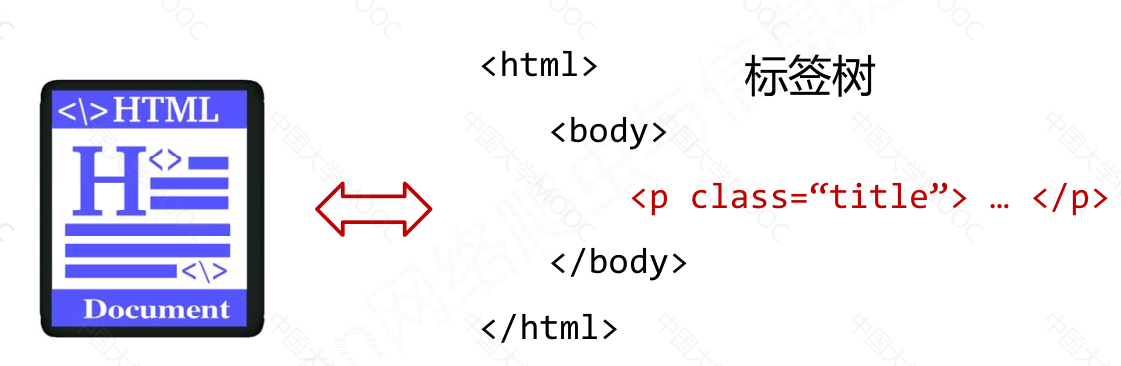
Beautiful Soup 库是解析、遍历、维护”标签树“的功能库
<p class="title">...</p>
<p>...</p>: 标签 Tagp: 名称 Nameclass=...: 属性 Attributes
Beautiful Soup 库的引用#
from bs4 import BeautifulSoup
import bs4
BeautifulSoup 类#

1
2
3
| from bs4 import BeautifulSoup
soup = BeautifulSoup("<html>data</html>", "html.parser")
soup2 = BeautifulSoup(open("D://demo.html"), "html.parser")
|
BeautifulSoup 对应一个 HTML/XML 文档的全部内容
Beautiful Soup 库解析器#
soup = BeautifulSoup('<html>data</html>', 'html.parser')

BeautifulSoup 类的基本元素#

Tag 标签#
任何存在于 HTML 语法中的标签都可以用**soup.<tag>**访问获得,当 HTML 文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个
1
2
3
4
5
6
7
8
9
10
11
| from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
soup.title
<title>This is a python demo page</title>
tag = soup.a
tag
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
|
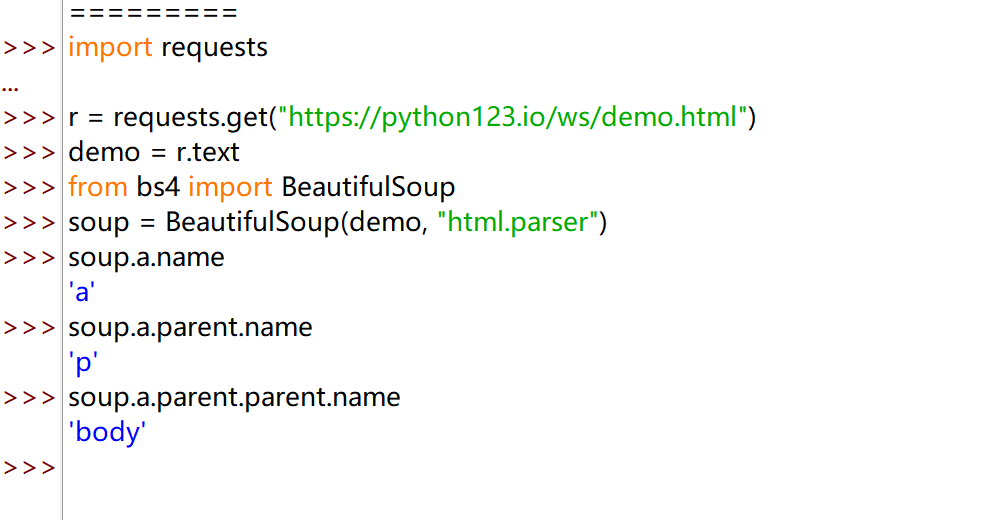
Tag 的 Name(名字)#
每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型
1
2
3
4
5
6
7
8
9
10
11
12
| import requests
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
soup.a.name
'a'
soup.a.parent.name
'p'
soup.a.parent.parent.name
'body'
|
Tag 的 attrs(属性)#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import requests
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
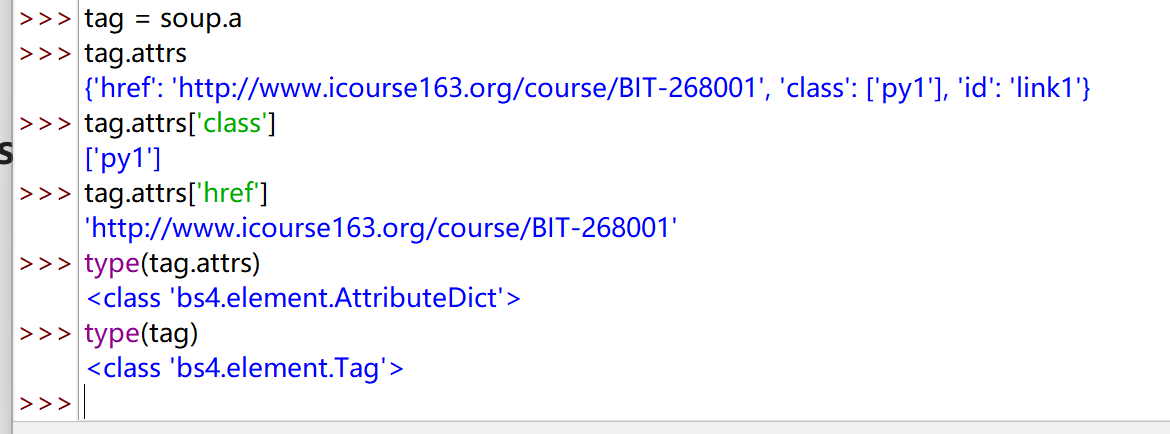
tag = soup.a
tag.attrs
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
tag.attrs['class']
['py1']
tag.attrs['href']
'http://www.icourse163.org/course/BIT-268001'
type(tag.attrs)
<class 'bs4.element.AttributeDict'>
type(tag)
<class 'bs4.element.Tag'>
|
Tag 的 NavigableString#
NavigableString 可以跨越多个层次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import requests
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
soup.a
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
soup.a.string
'Basic Python'
soup.p
<p class="title"><b>The demo python introduces several python courses.</b></p>
soup.p.string
'The demo python introduces several python courses.'
type(soup.p.string)
<class 'bs4.element.NavigableString'>
|

Comment 是一种特殊类型
1
2
3
4
5
6
7
8
9
10
11
12
13
| newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>", "html.parser")
newsoup.b.string
'This is a comment'
type(newsoup.b.string)
<class 'bs4.element.Comment'>
newsoup.p.string
'This is not a comment'
type(newsoup.p.string)
<class 'bs4.element.NavigableString'>
|

基于 bs4 库的 HTML 内容遍历方法#
HTML 基本格式#

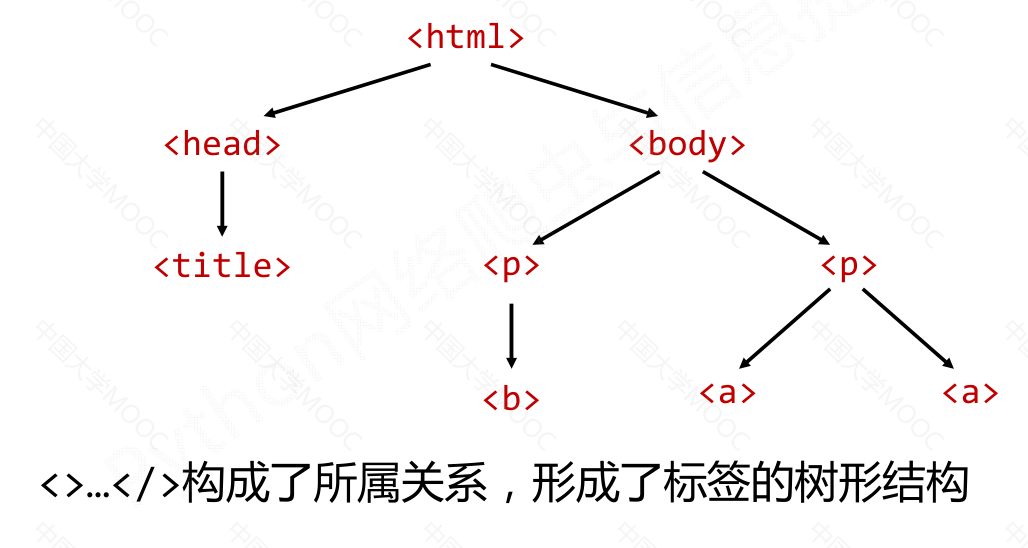
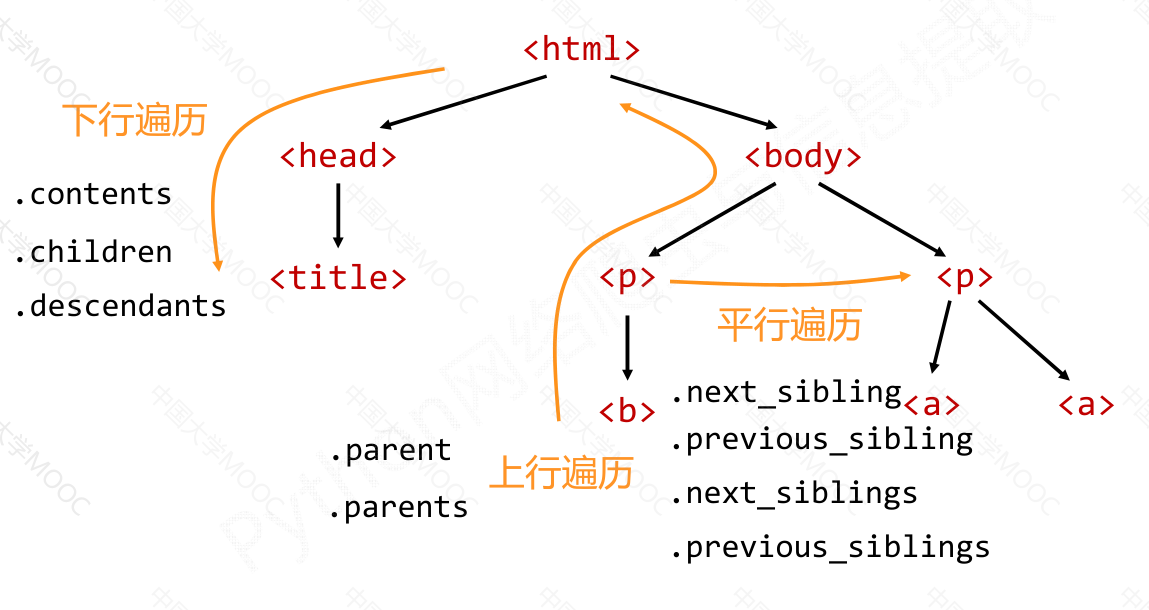
标签树的下行遍历#
BeautifulSoup 类型是标签树的根节点

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import requests
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
soup = BeautifulSoup(demo, "html.parser")
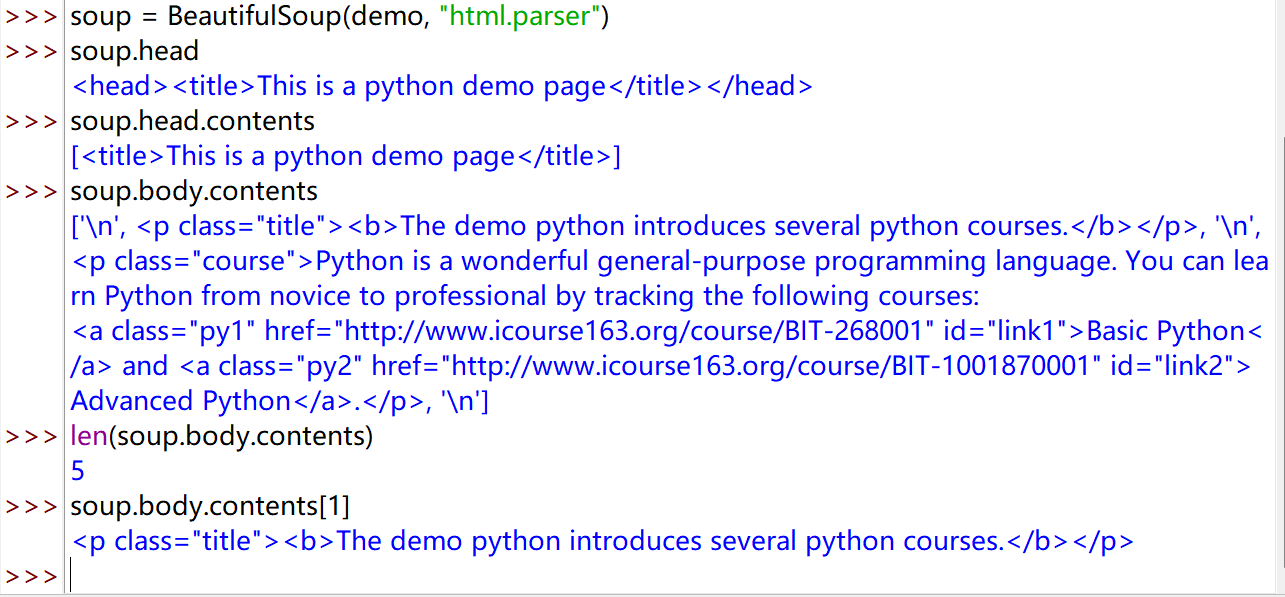
soup.head
<head><title>This is a python demo page</title></head>
soup.head.contents
[<title>This is a python demo page</title>]
soup.body.contents
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
len(soup.body.contents)
5
soup.body.contents[1]
<p class="title"><b>The demo python introduces several python courses.</b></p>
|
遍历儿子节点
1
2
| for child in soup.body.children:
print(child)
|
遍历子孙节点
1
2
| for child in soup.body.descendants:
print(child)
|
标签树的上行遍历#

1
2
3
4
5
6
7
8
9
10
11
12
13
14
| soup = BeautifulSoup(demo,"html.parser")
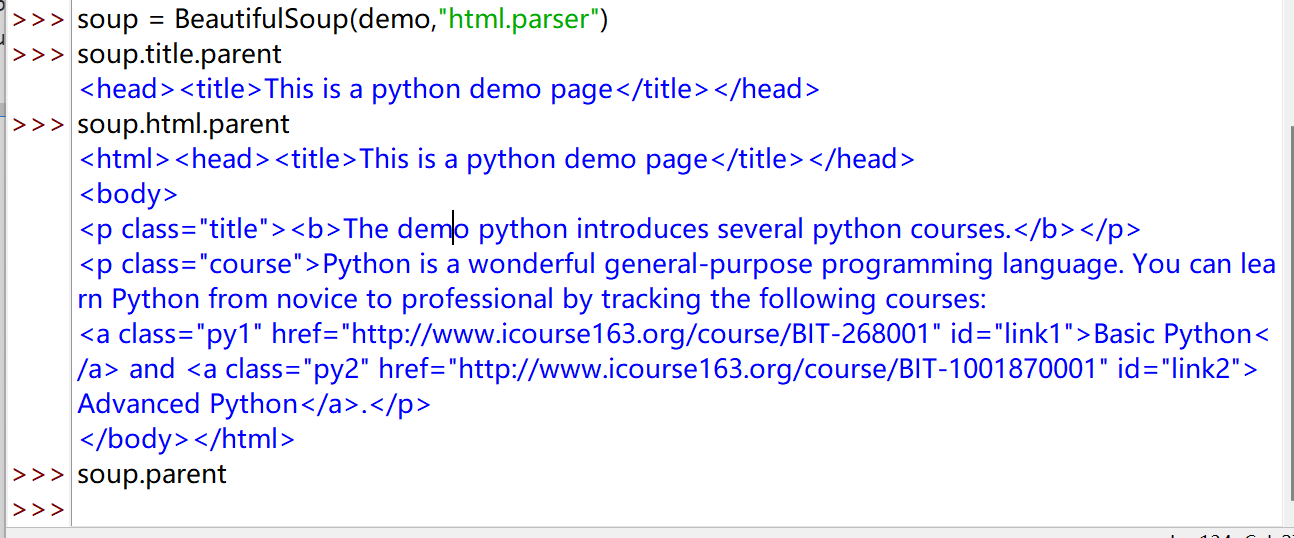
soup.title.parent
<head><title>This is a python demo page</title></head>
soup.html.parent
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
soup.parent
|
遍历所有先辈节点,包括 soup 本身,所以要区别判断
1
2
3
4
5
6
7
8
9
10
11
| for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]
|

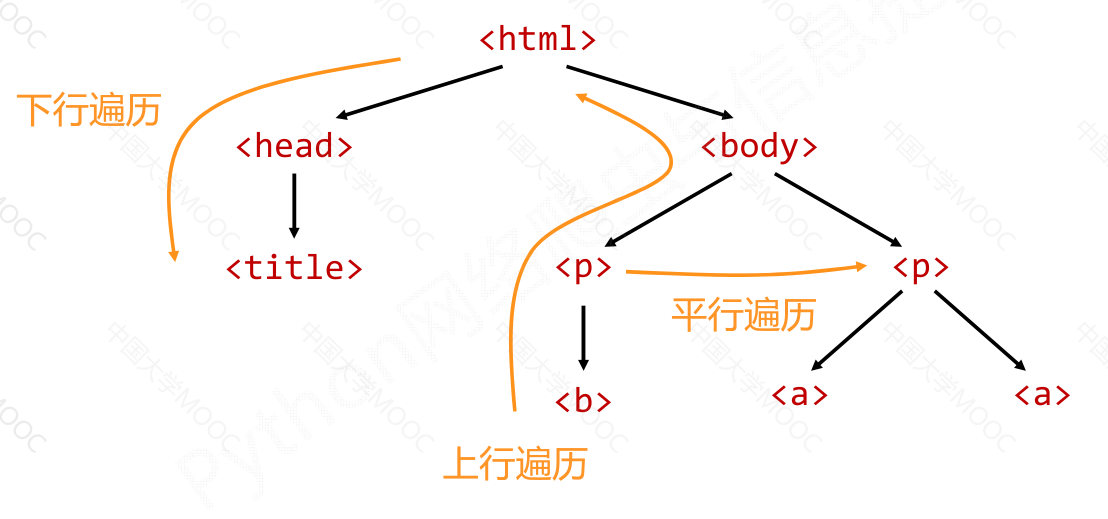
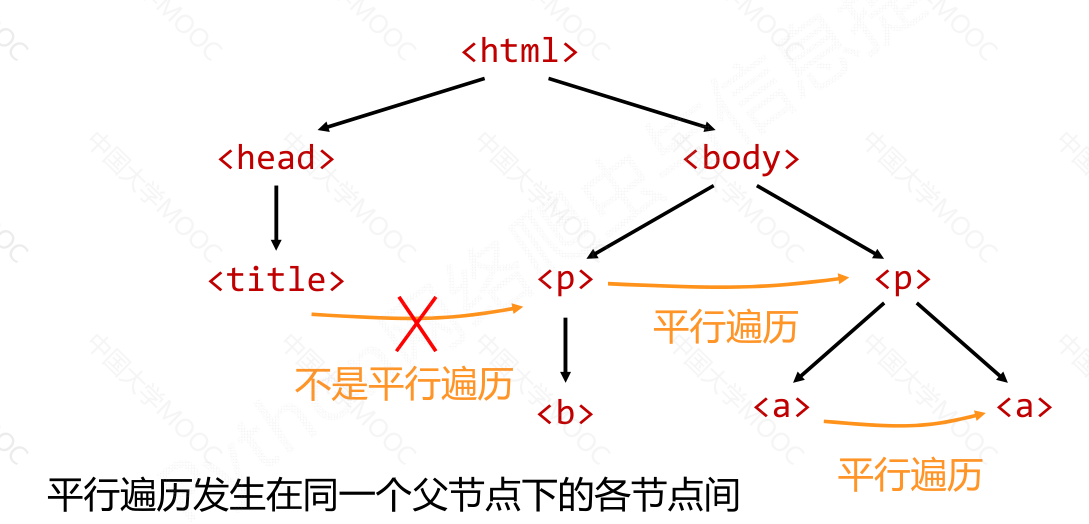
标签树的平行遍历#

1
2
3
4
5
6
7
8
9
10
11
12
13
14
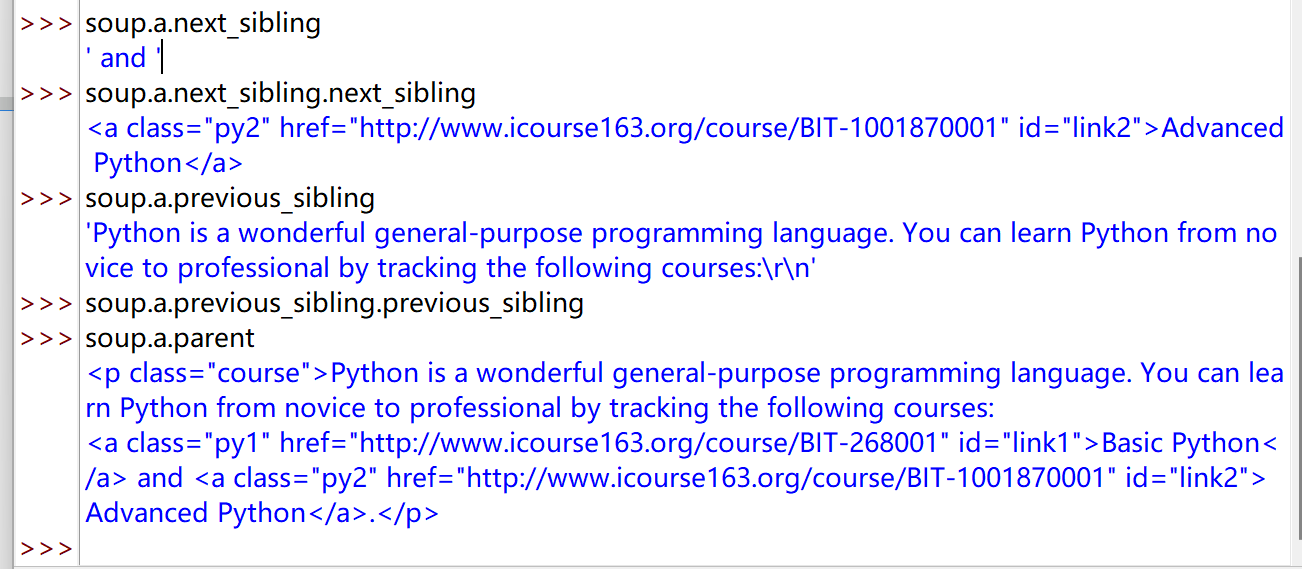
| soup.a.next_sibling
' and '
soup.a.next_sibling.next_sibling
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
soup.a.previous_sibling
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n'
soup.a.previous_sibling.previous_sibling
soup.a.parent
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
|
遍历后续节点
1
2
| for sibling in soup.a.next_sibling:
print(sibling)
|
遍历前续节点
1
2
| for sibling in soup.a.previous_sibling:
print(sibling)
|
基于 bs4 库的 HTML 格式输出#
bs4 库的prettify()方法#
.prettify()为 HTML 文本<> 及其内容增加更加'\n'
.prettify()可用于标签,方法:<tag>.prettify()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
from bs4 import BeaytifulSoup
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
from bs4 import BeaytifulSoup
ImportError: cannot import name 'BeaytifulSoup' from 'bs4' (C:\Users\SZZY\AppData\Local\Programs\Python\Python310\lib\site-packages\bs4\__init__.py)
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
soup.prettify()
'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p class="title">\n <b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p class="course">\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n </a>\n and\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>\n'
|

1
| print(soup.a.preffity())
|

bs4 库的编码#
bs4 库将任何 HTML 输入都变成 utf-8 编码
Python 3.x 默认支持编码是 utf-8,解析无障碍
1
2
3
4
5
6
7
8
9
10
| soup = BeautifulSoup("<p>中文</p>", "html.parser")
soup.p.string
'中文'
print(soup.p.prettify())
<p>
中文
</p>
soup = BeautifulSoup("<p>中文</p>", "html.parser")
|

