简易模板#
1
2
3
4
5
6
7
8
9
10
11
| import requests
from bs4 import BeautifulSoup
meHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
url = ""
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('utf-8')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all()
|
单封家书【译文】内容获取#
目标网站:http://ewenyan.com/articles/zgfjs/1.html
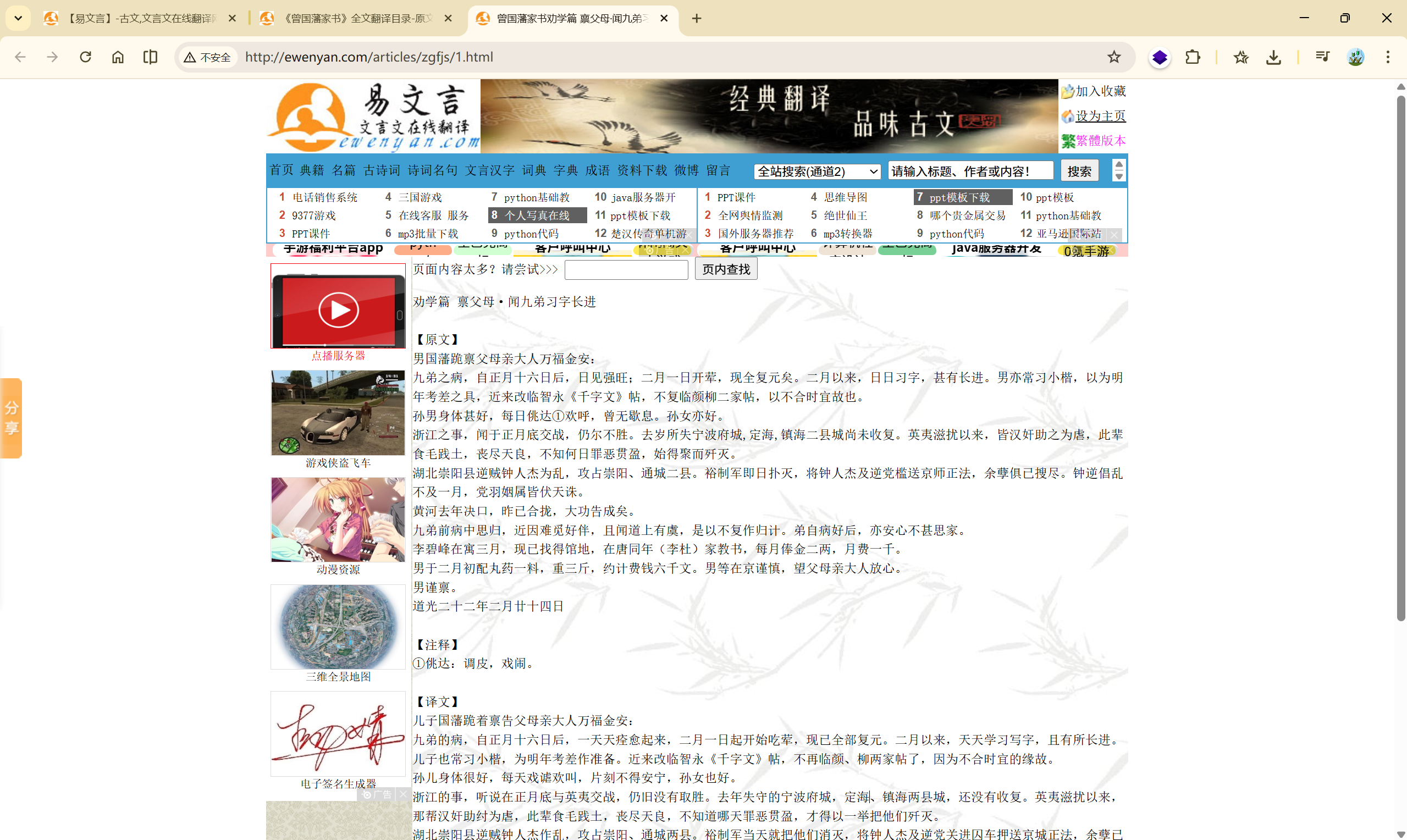
待爬取数据分析#
确认编码:
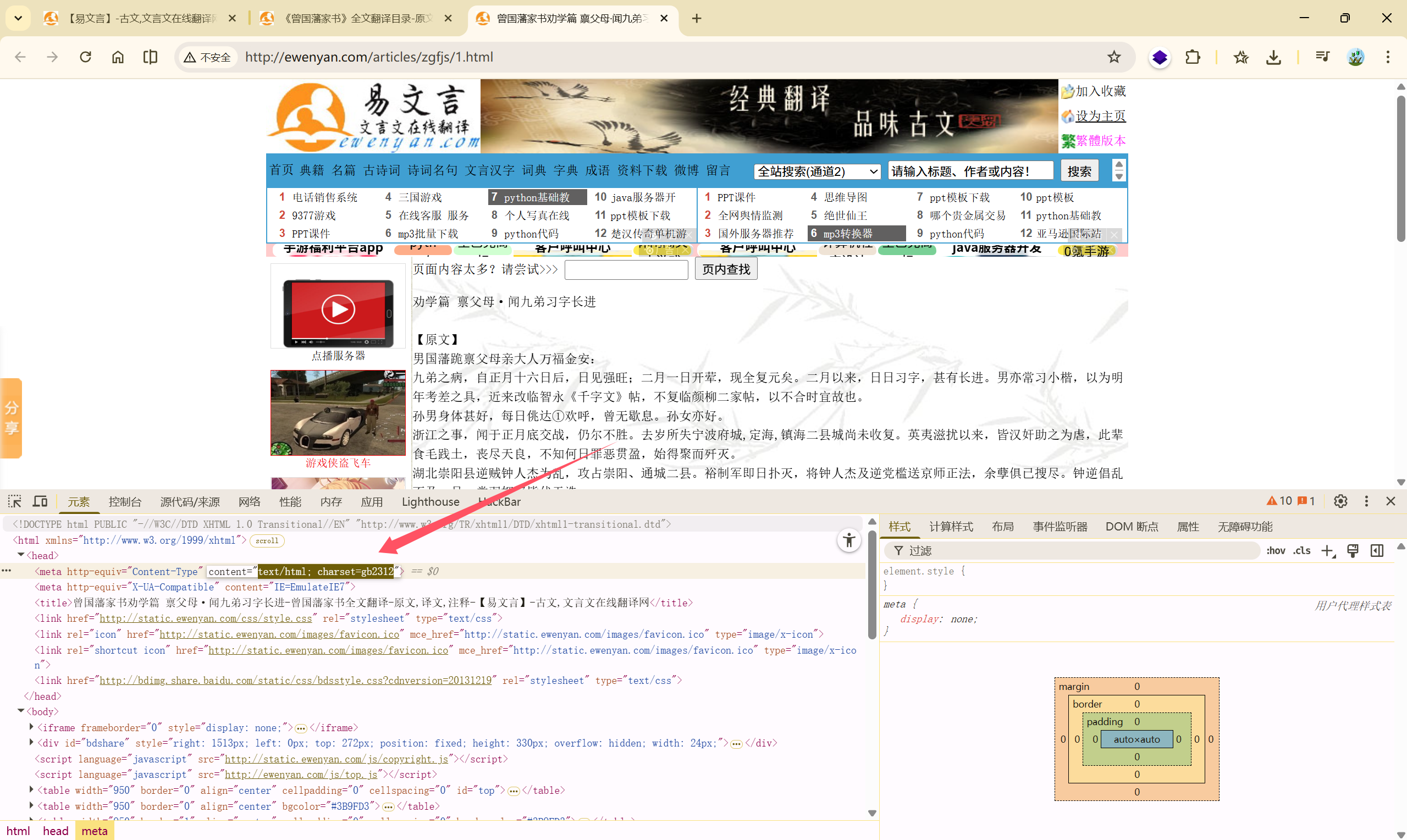
因为此网站的文章数据全部放在<p>标签内,并且页面布局都是以<table>标签来布局的。
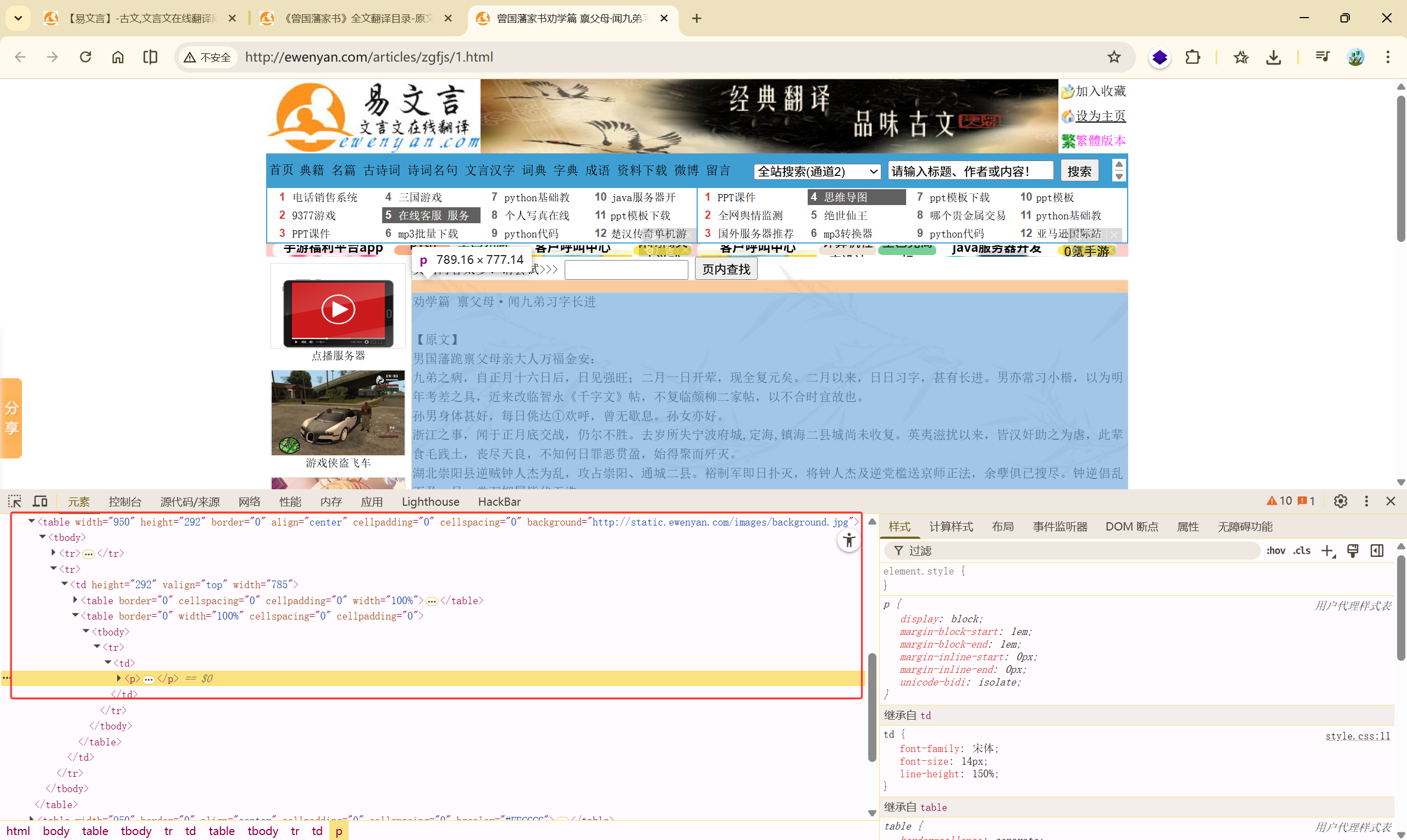
所以先把所有的<table>标签抓取下来,然后按对应顺序爬取文章。
可以确认爬取数据的位置为第四个<table>标签
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')
print(t)
indx = 0
for i in t:
print(i)
print(indx)
indx += 1
getOne(url)
|

完善代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3]
print(t)
getOne(url)
|
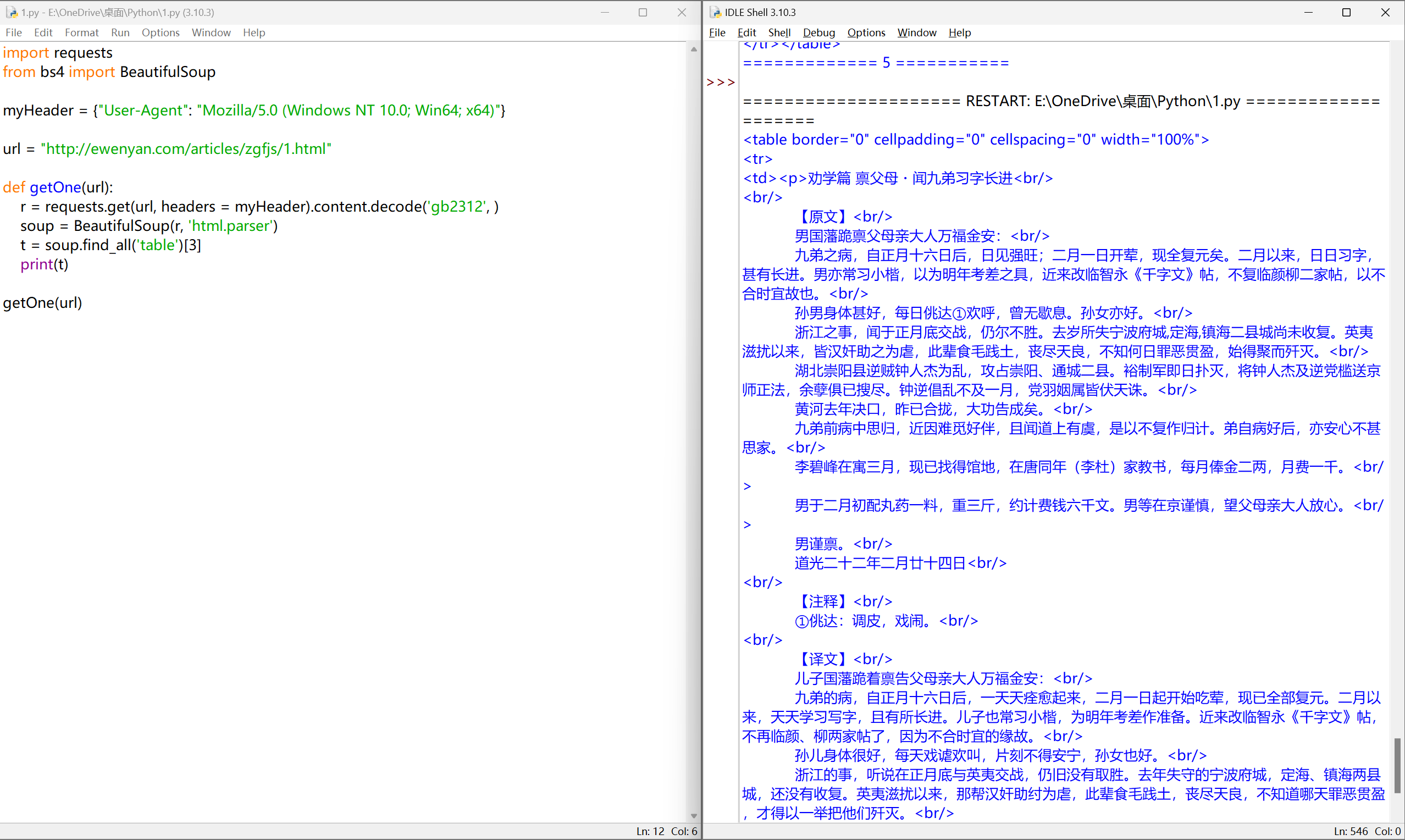
提取文本#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
print(t)
getOne(url)
|
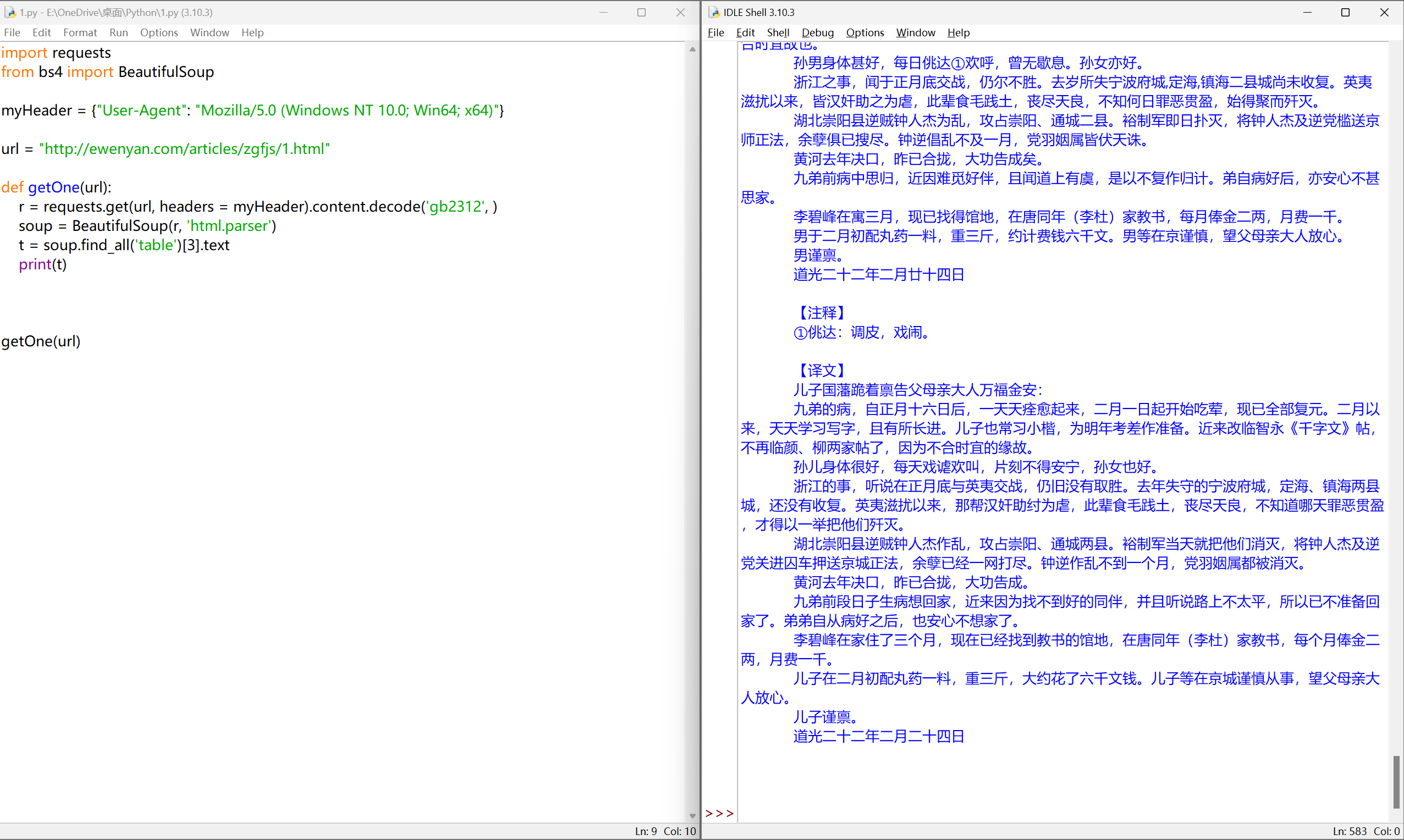
完善代码-爬取单封家书的译文#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
print(getOne(url))
|
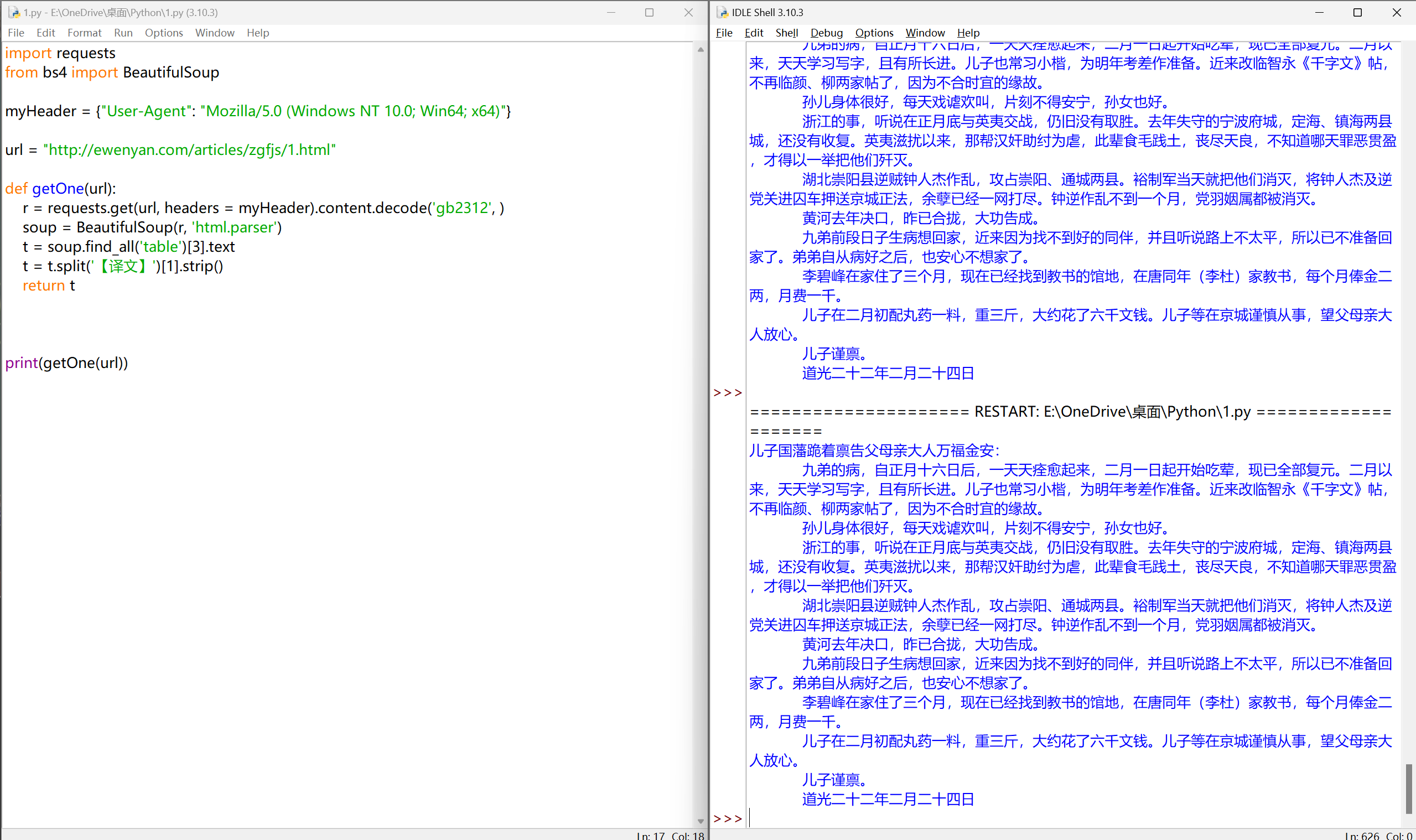
目录页#
数据分析#
http://ewenyan.com/contents/more/zgfjs.html
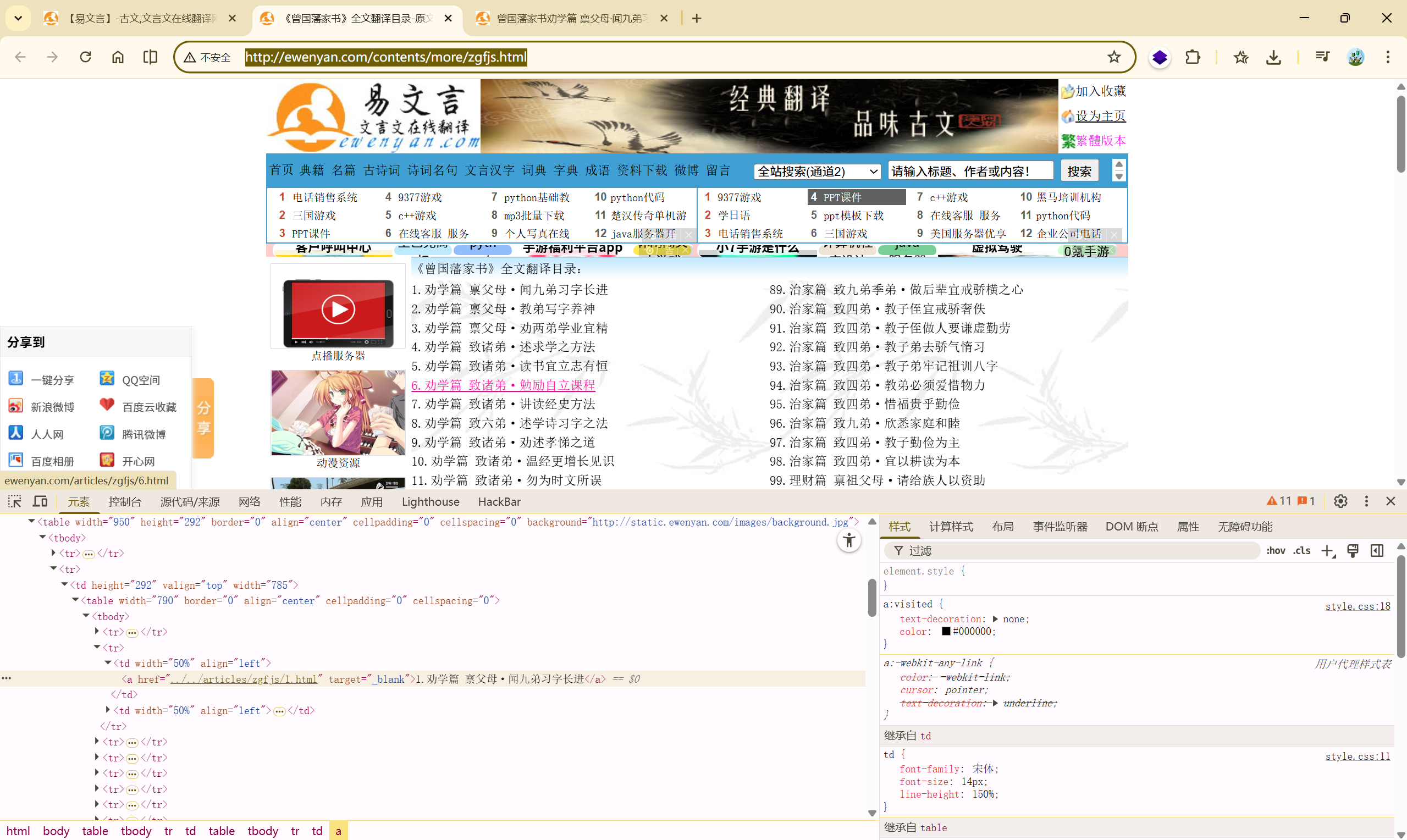
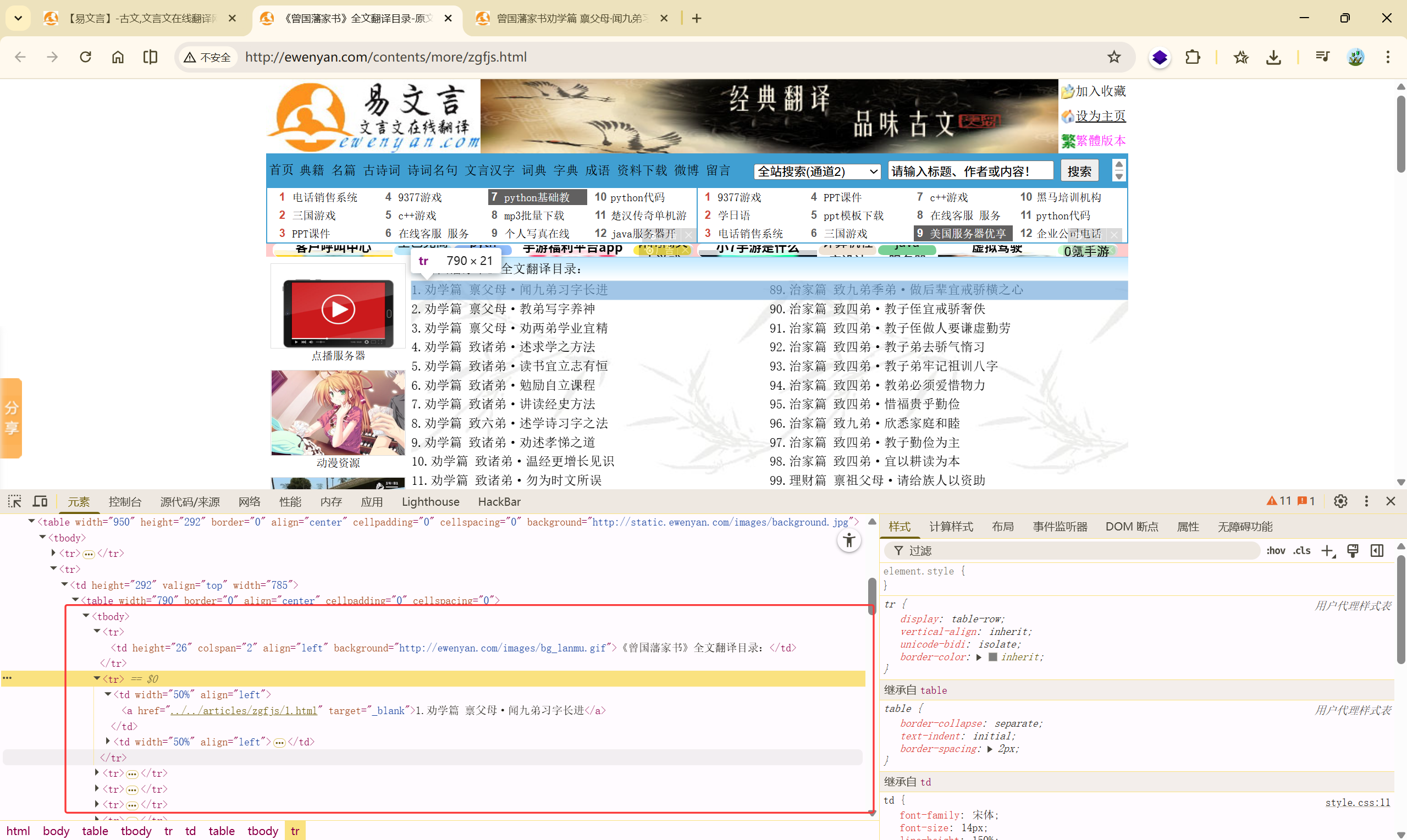
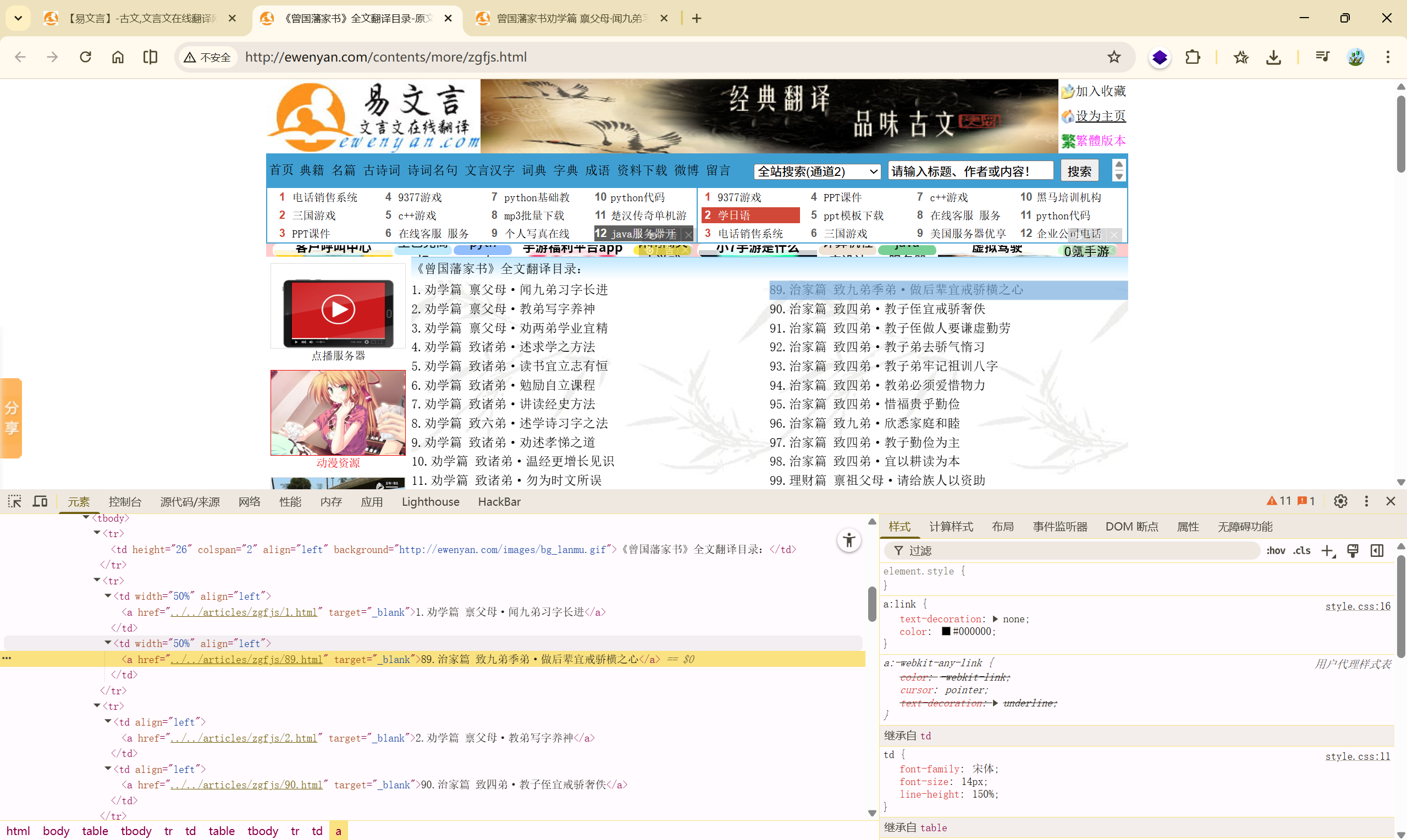
确定爬取的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')
print(t)
getAll(url)
|
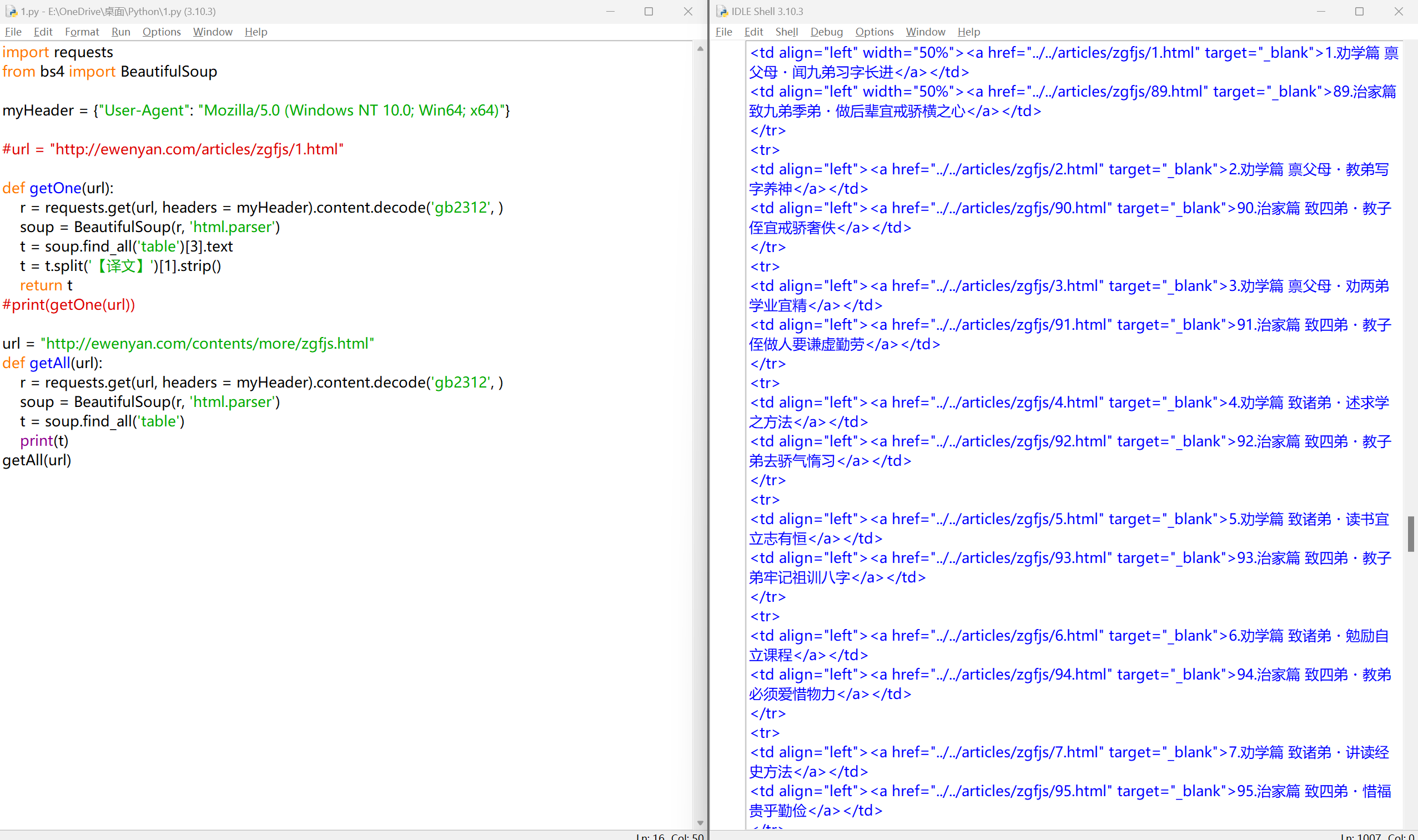
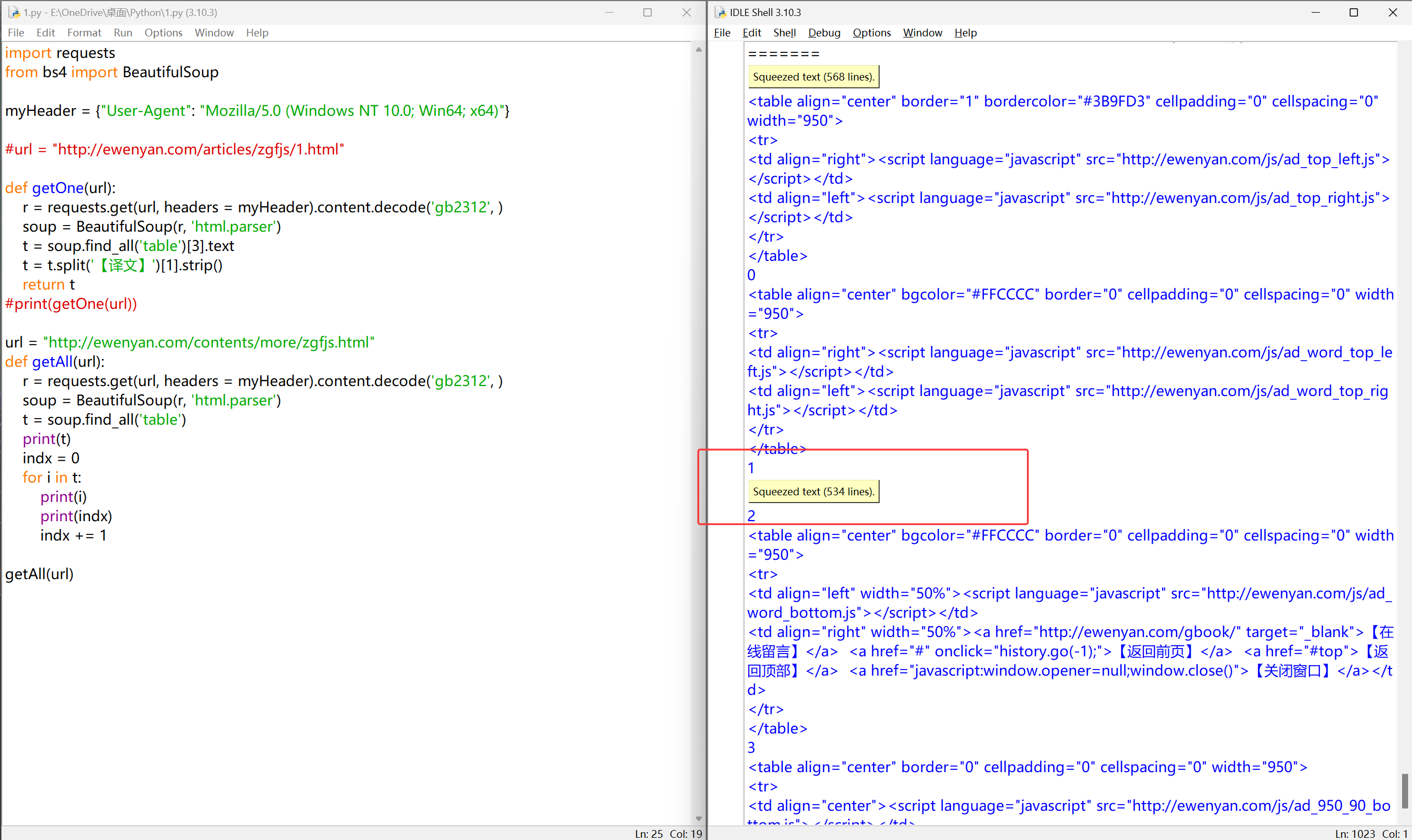
爬取所有<a>标签
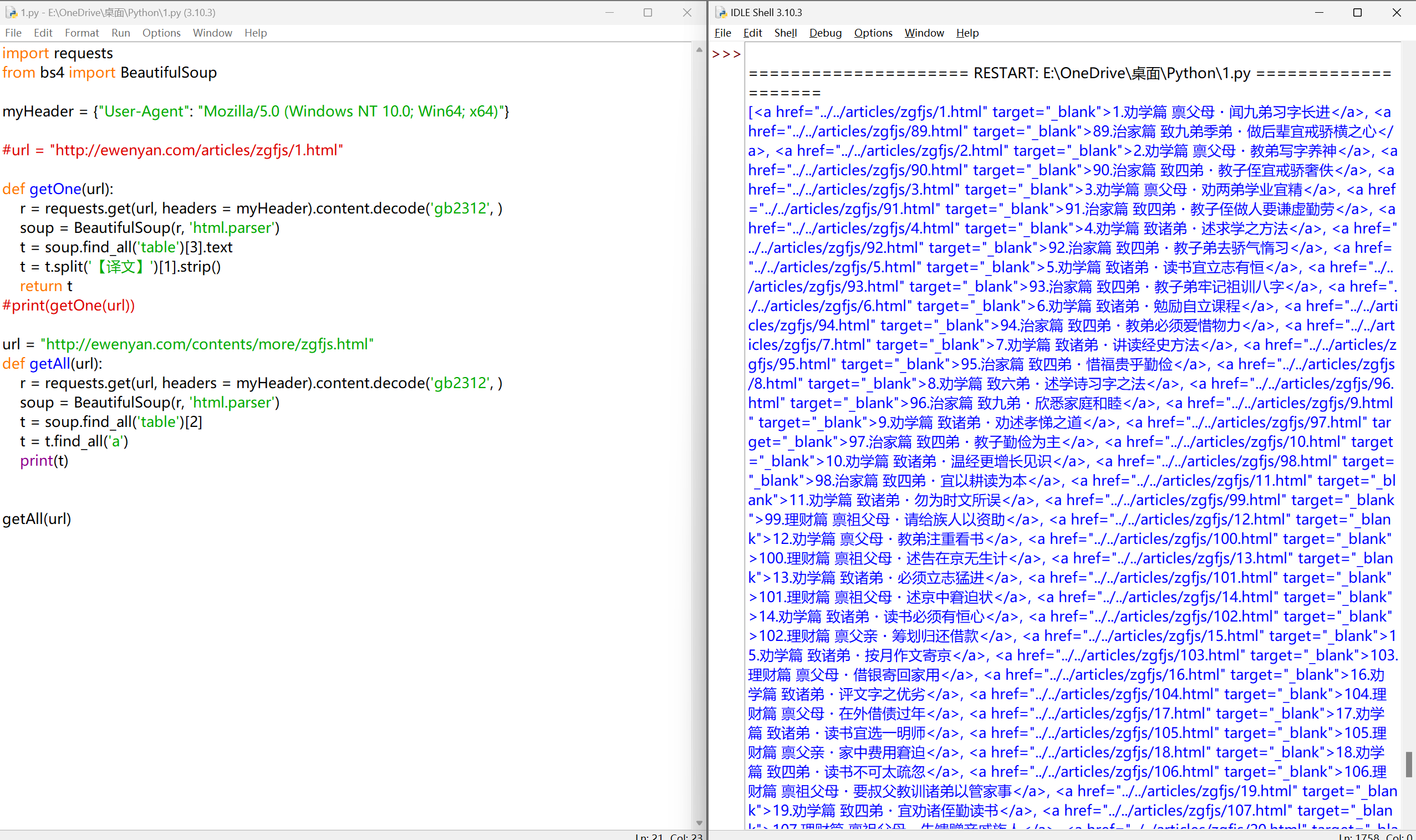
分析链接:#
1
2
3
4
| ../../articles/zgfjs/89.html
http://ewenyan.com/articles/zgfjs/1.html
我们要使用 'http://ewenyan.com/' 去替换 '../../'
|
替换链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
print(t)
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
print(title, link)
getAll(url)
|
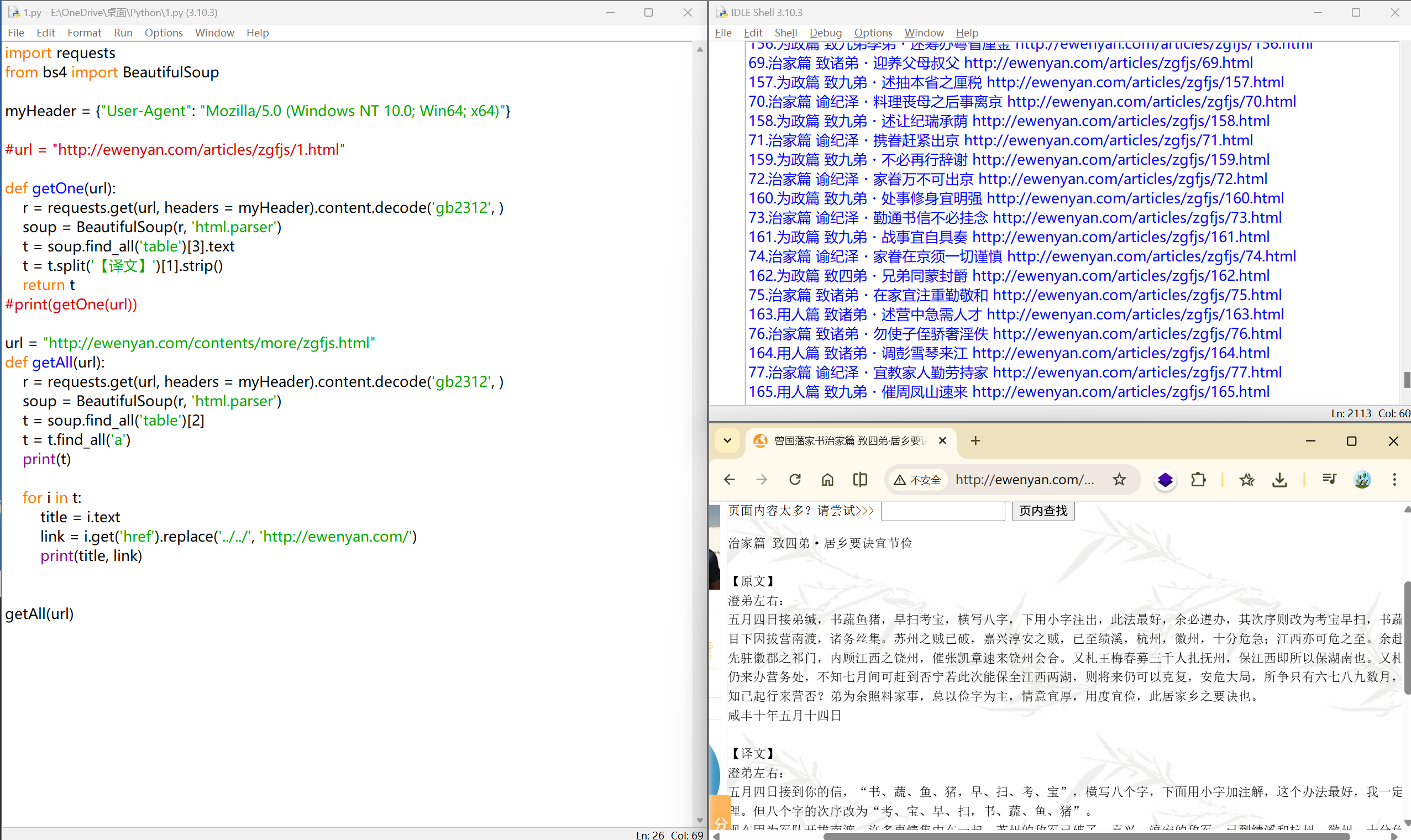
排序问题#
使用数组列表将数据进行存放
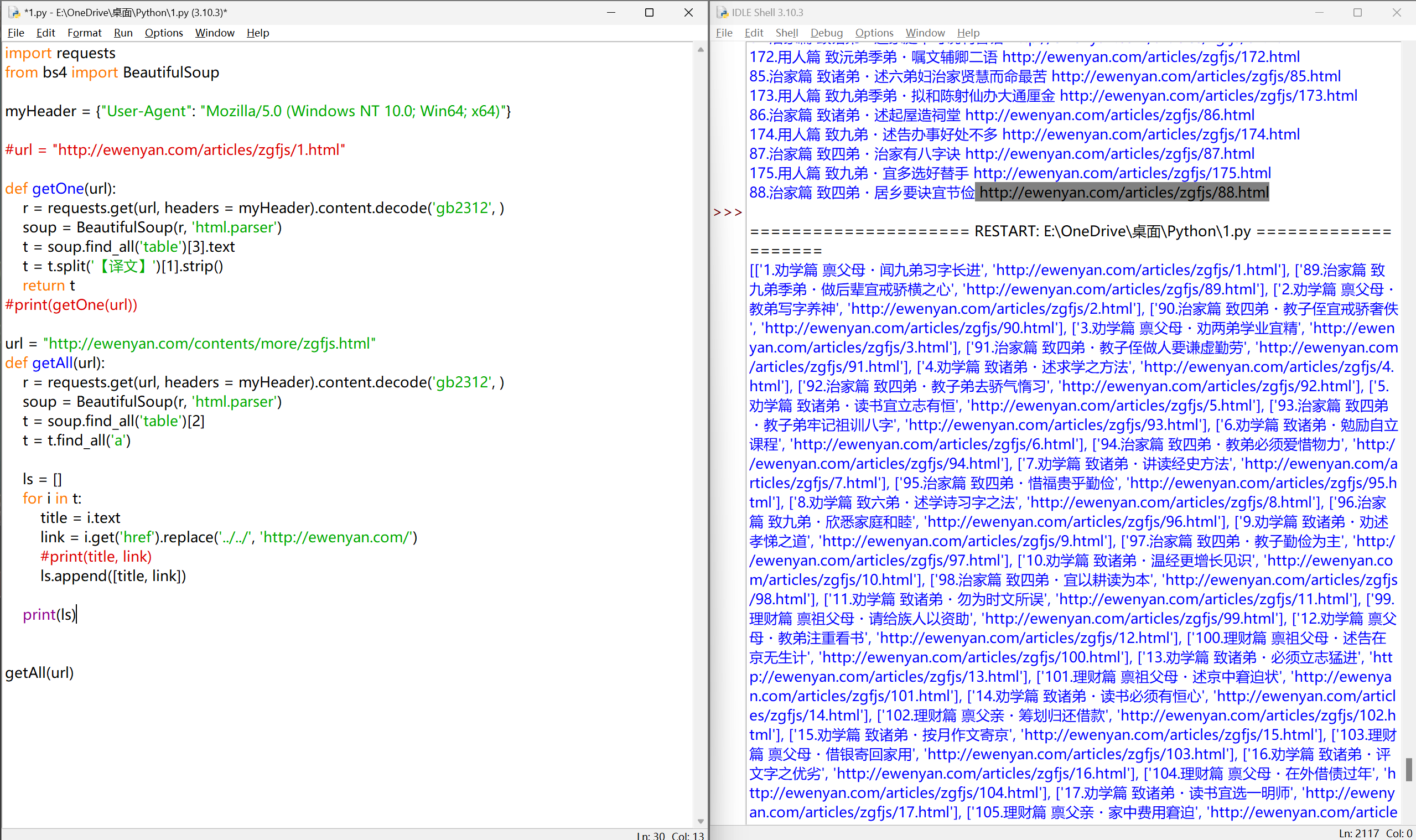
解决排序问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
ls = []
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
#print(title, link)
indx = int(title.split('.')[0])
ls.append([indx, title, link])
ls.sort()
print(ls)
getAll(url)
|
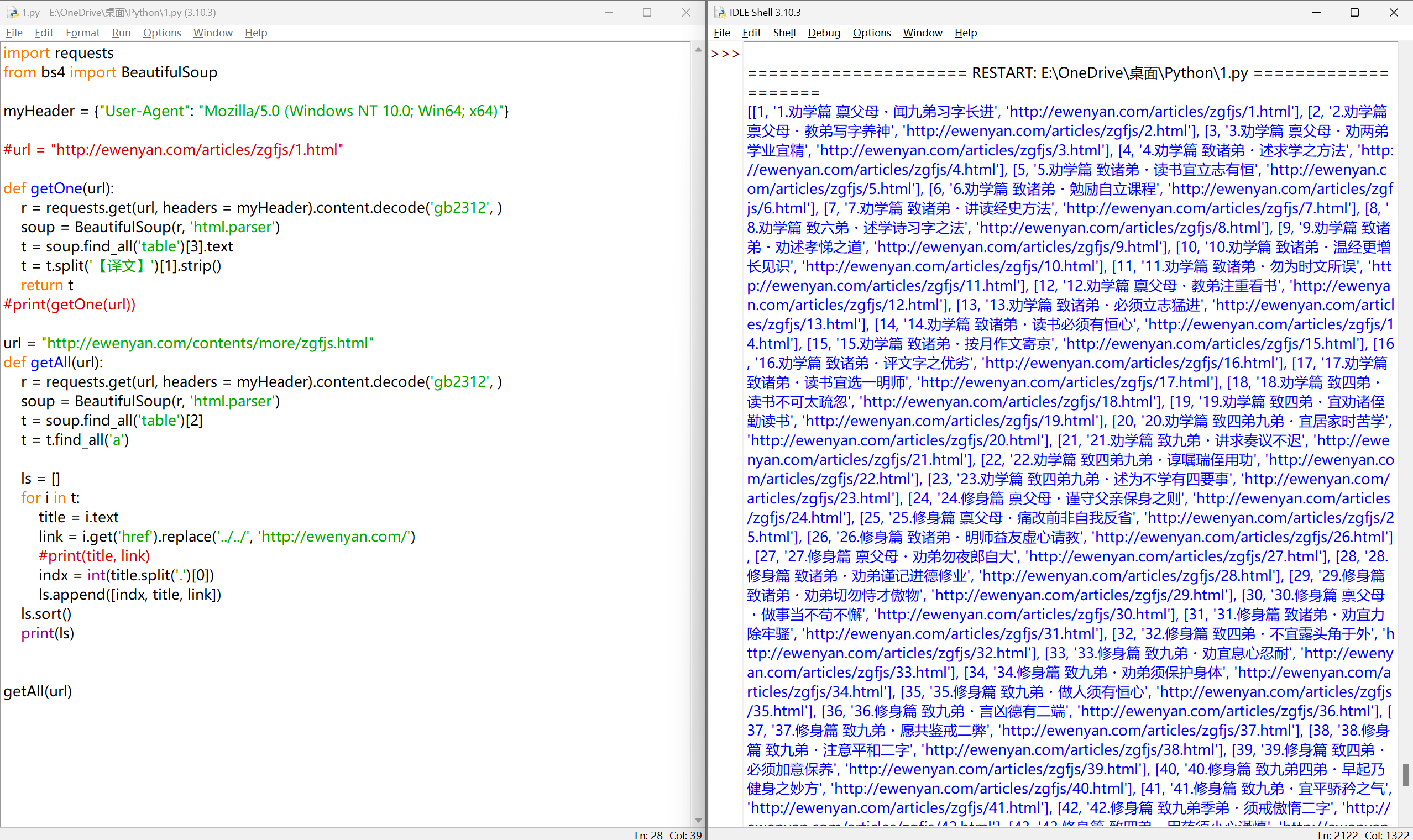
家书内容存入文件#
问题一:编码#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312', )
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
ls = []
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
#print(title, link)
indx = int(title.split('.')[0])
ls.append([indx, title, link])
ls.sort()
return ls
lst = getAll(url)
for each in lst:
f = open('曾国藩家书.txt', 'a')
title = each[1]
print(title)
f.write(title)
f.write(getOne(each[2]))
f.close()
|
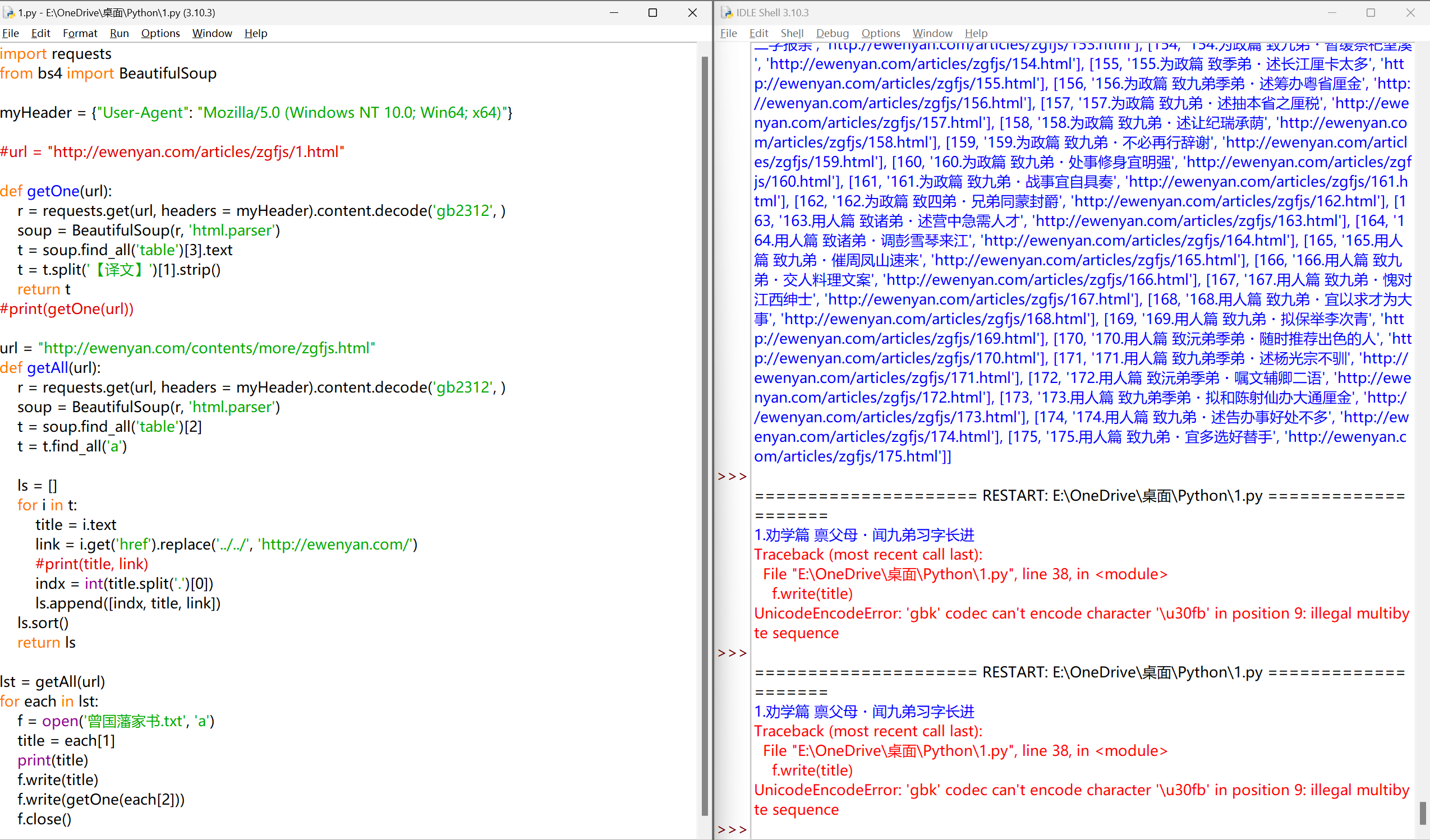
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
ls = []
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
#print(title, link)
indx = int(title.split('.')[0])
ls.append([indx, title, link])
ls.sort()
return ls
lst = getAll(url)
# with语句,自动关闭文件,更安全
with open('曾国藩家书.txt', 'a', encoding='utf-8') as f:
for each in lst:
title = each[1]
print(title)
f.write(title)
content = getOne(each[2])
f.write(content)
|
问题二:写入文件时的异常#
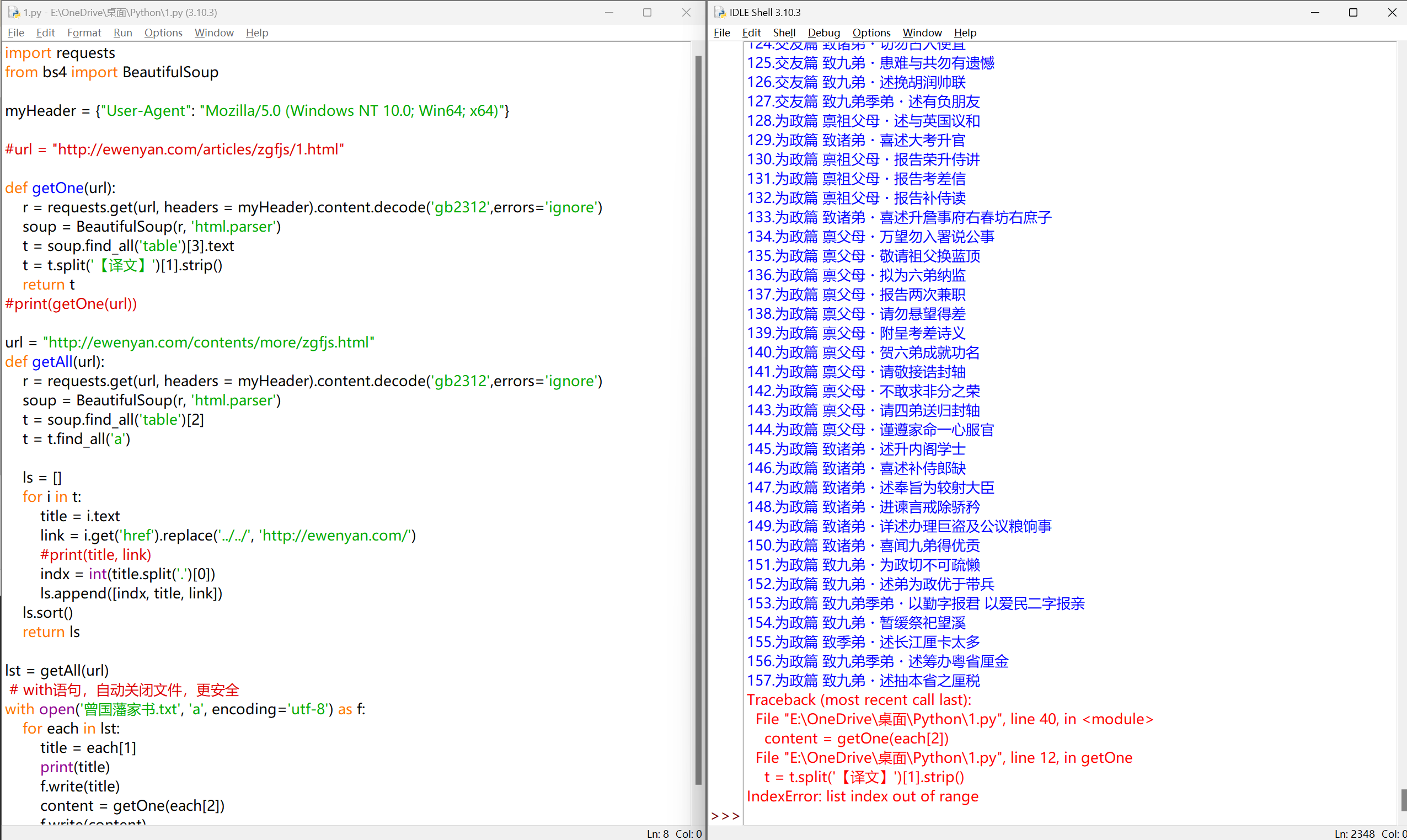
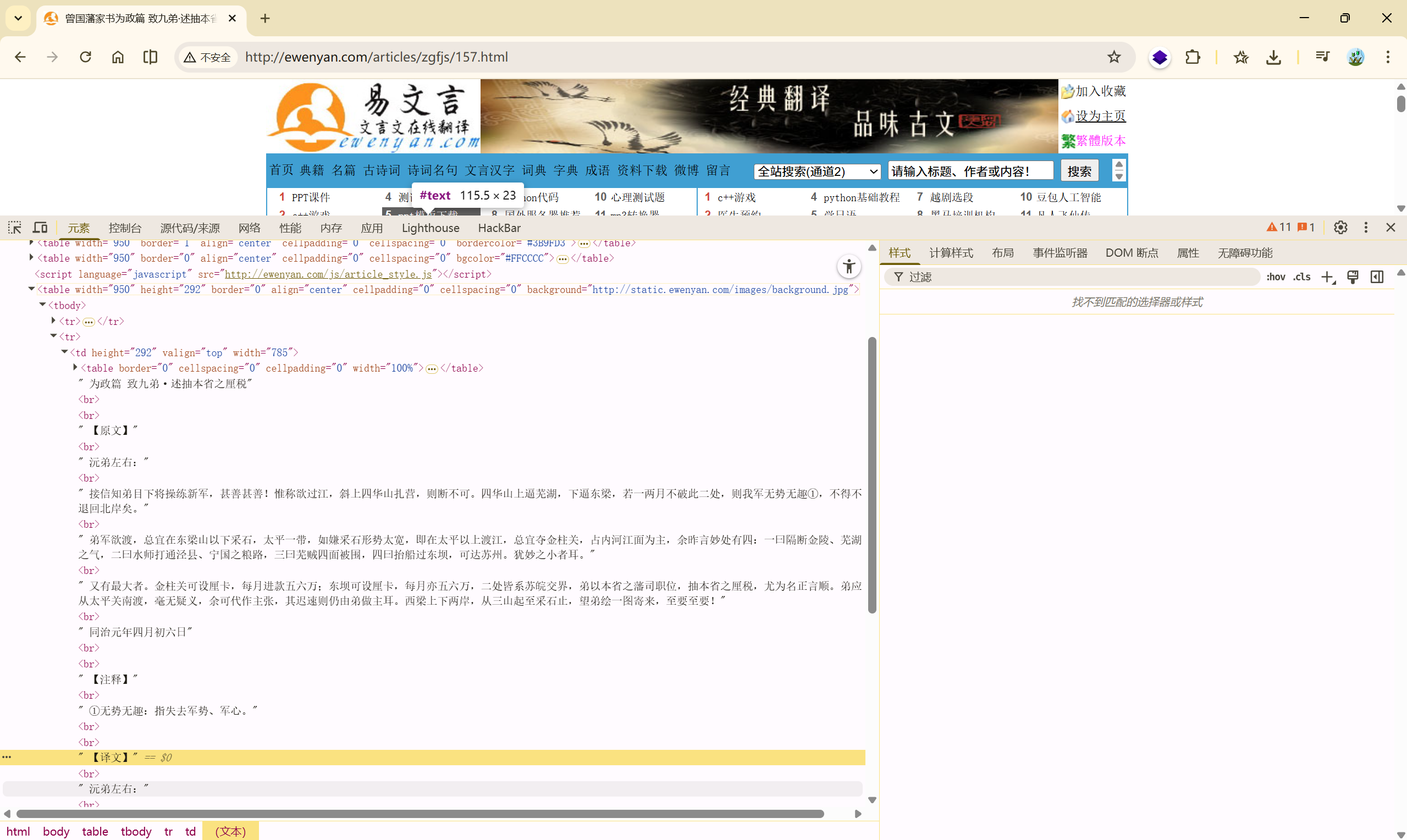
从网页源码能看到,这一篇其实是有「【译文】」的,大概率是**网页解析时获取的文本中,「【译文】」前后有多余字符(如空格、换行),或者解析到了广告内容,导致拆分异常**
添加异常处理#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
ls = []
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
#print(title, link)
indx = int(title.split('.')[0])
ls.append([indx, title, link])
ls.sort()
return ls
lst = getAll(url)
# with语句,自动关闭文件,更安全
with open('曾国藩家书.txt', 'a', encoding='utf-8') as f:
for each in lst:
try:
title = each[1]
print(title)
f.write(title)
content = getOne(each[2])
f.write(content)
except:
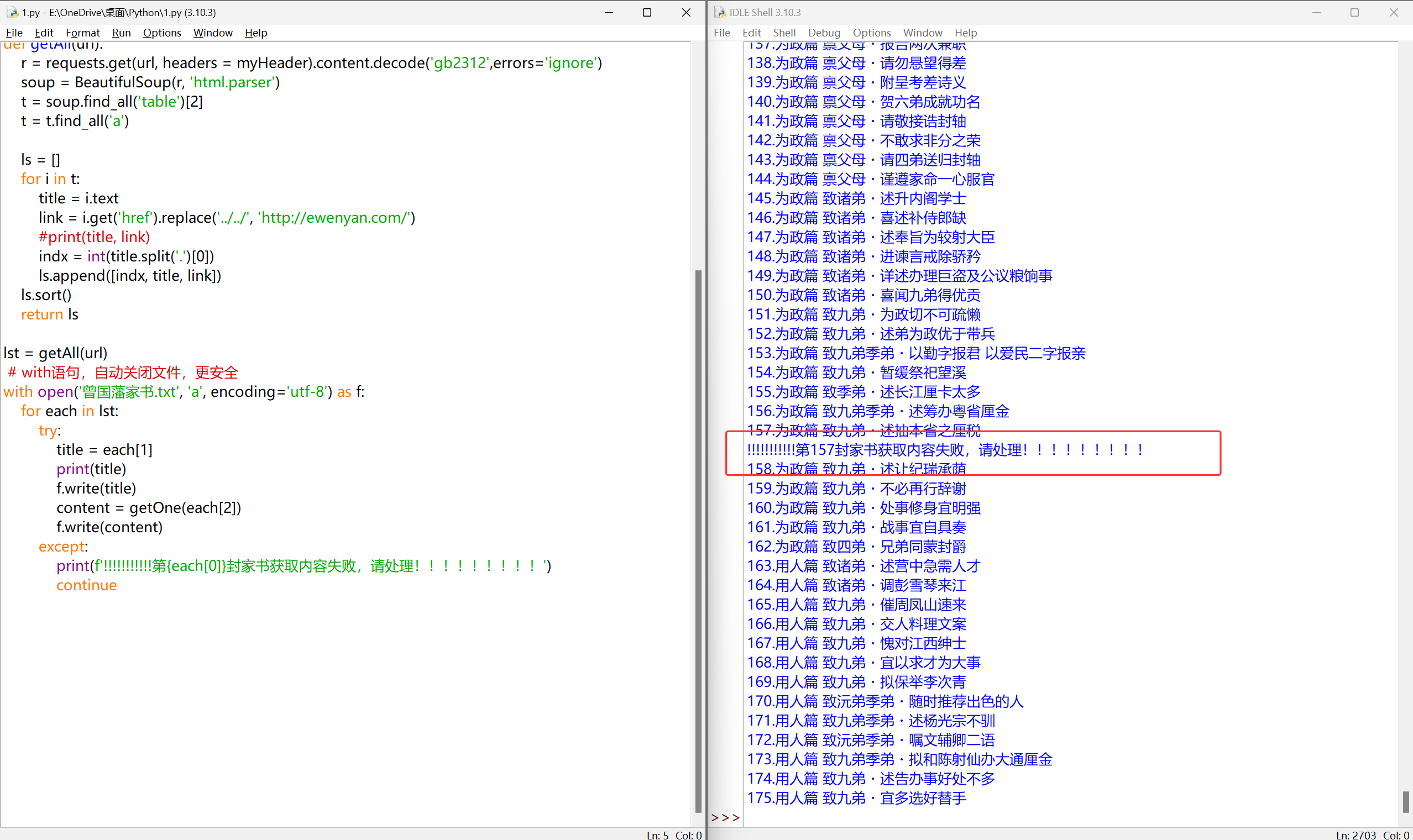
print(f'!!!!!!!!!!!第{each[0]}封家书获取内容失败,请处理!!!!!!!!!')
continue
|
完整代码#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import requests
from bs4 import BeautifulSoup
myHeader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
#url = "http://ewenyan.com/articles/zgfjs/1.html"
def getOne(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[3].text
t = t.split('【译文】')[1].strip()
return t
#print(getOne(url))
url = "http://ewenyan.com/contents/more/zgfjs.html"
def getAll(url):
r = requests.get(url, headers = myHeader).content.decode('gb2312',errors='ignore')
soup = BeautifulSoup(r, 'html.parser')
t = soup.find_all('table')[2]
t = t.find_all('a')
ls = []
for i in t:
title = i.text
link = i.get('href').replace('../../', 'http://ewenyan.com/')
#print(title, link)
indx = int(title.split('.')[0])
ls.append([indx, title, link])
ls.sort()
return ls
lst = getAll(url)
for each in lst:
try:
with open('曾国藩家书.txt', 'a', encoding='utf-8') as f:
title = each[1]
print(title)
f.write(title)
content = getOne(each[2])
f.write(content)
except:
print(f'!!!!!!!!!!!第{each[0]封家书获取内容失败,请处理!!!!!!!!!')
continue
|