1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
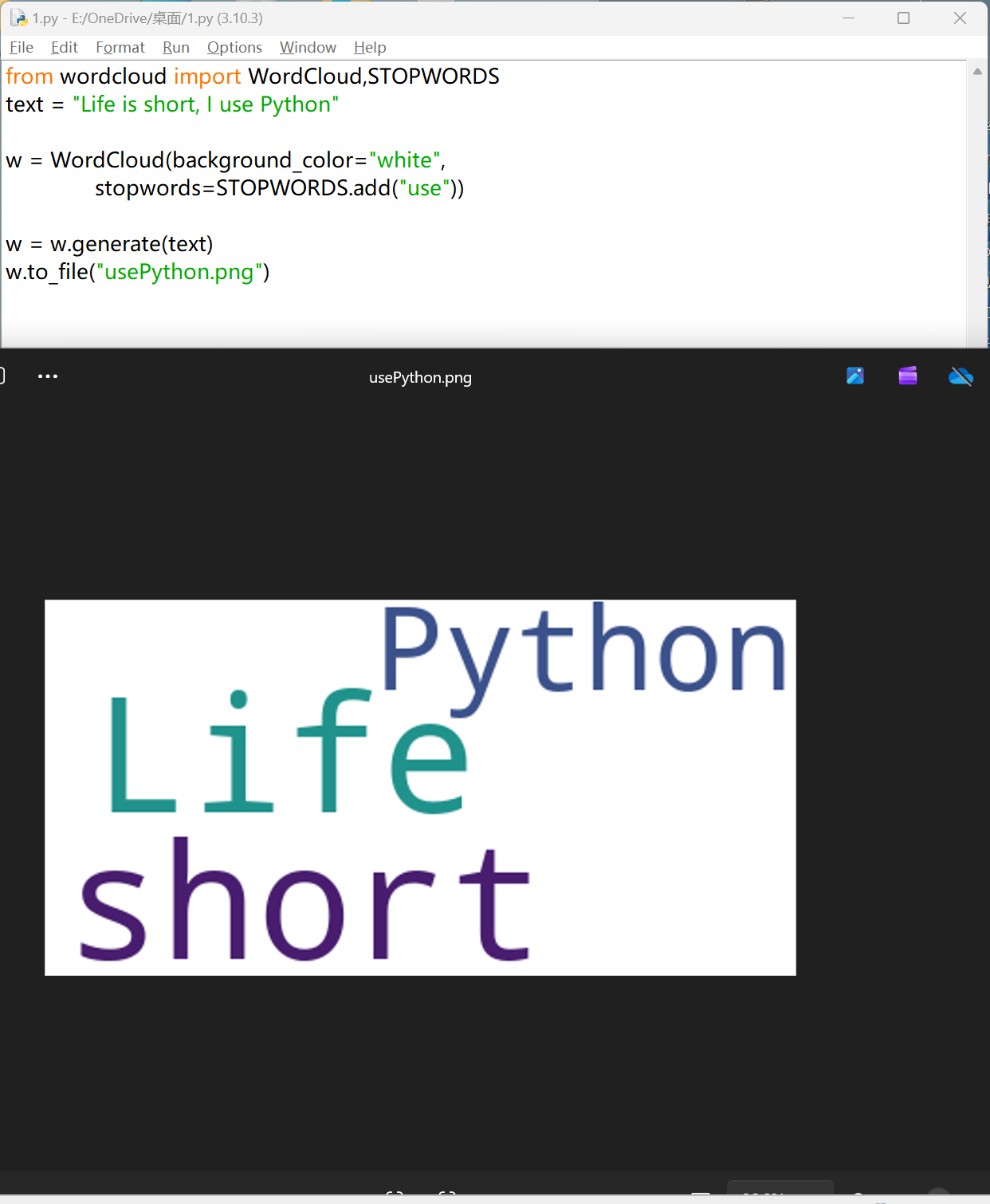
| from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# ========================
# 1. 读取英文小说文件
# ========================
with open(
"Harry Potter and The Half Blood Prince.txt",
"r",
encoding="utf-8",
errors="ignore"
) as file:
txt = file.read().lower()
# ========================
# 2. 文本清洗(英文标点)
# ========================
for ch in '~!@#$%^&*()_+`-=|{}:"><[]\\;,./?\'':
txt = txt.replace(ch, " ")
# ========================
# 3. 英文分词
# ========================
words = txt.split()
# ========================
# 4. 停用词(英文)
# ========================
stopwords = {
# 冠词
"the", "a", "an",
# 介词
"in", "on", "at", "by", "for", "with", "from", "to", "into", "out", "of", "about", "above", "below", "before", "after", "between", "among", "through", "during", "over", "around", "down",
# 连词
"and", "but", "or", "so", "because", "since", "while", "if", "though", "although", "as", "than",
# 代词
"i", "me", "my", "mine", "you", "your", "yours", "he", "him", "his", "she", "her", "hers", "it", "its", "we", "us", "our", "ours", "they", "them", "their", "theirs", "this", "that", "these", "those", "who", "whom", "whose", "which", "what",
# 助动词/系动词
"am", "is", "are", "was", "were", "be", "been", "being", "have", "has", "had", "having", "do", "does", "did", "doing",
# 情态动词
"can", "could", "will", "would", "shall", "should", "may", "might", "must",
# 副词/功能词
"here", "there", "now", "then", "when", "where", "why", "how", "always", "never", "often", "sometimes", "just", "only", "very", "too", "quite", "rather", "well", "again",
# 量词/填充词
"all", "some", "any", "no", "none", "many", "much", "few", "little", "several", "one", "two", "three", "more",
# 否定词
"not", "no", "never",
# 常见动词/口语词
"know", "like", "think", "see", "got", "get", "go", "went",
# 哈利波特文本高频无意义叙事词
"said", "asked", "replied", "looked", "looking", "look", "back", "once", "right", "off"
}
# ========================
# 5. 词频统计
# ========================
counts = {}
for word in words:
word = word.strip()
if not word or word in stopwords or len(word) <= 2:
continue
counts[word] = counts.get(word, 0) + 1
# ========================
# 6. 输出 Top20
# ========================
items = sorted(counts.items(), key=lambda x: x[1], reverse=True)
print("Top 20 Words:")
for word, count in items[:20]:
print(f"{word:<15} {count:>5}")
# ========================
# 8. 生成词云
# ========================
wc = WordCloud(
width=1000,
height=800,
background_color="white",
max_words=200,
contour_width=2,
contour_color="red",
collocations=False
)
wc.generate_from_frequencies(counts)
# ========================
# 9. 保存 + 显示
# ========================
wc.to_file("HarryPotter_Heart_WordCloud.png")
plt.imshow(wc)
plt.axis("off")
plt.show()
|